

Recently I was talking with someone that was wondering what the value was of writing unit tests. They were concerned that trying to write tests was a large effort and that they might not catch all bugs, so why write the test? It's a common viewpoint that I hear from many customers who are trying to implement Database DevOps and want to write better software. Just like concepts like Continuous Integration and Continuous Delivery can be intimidating, so can writing unit tests.
My thoughts are that writing the unit tests is not that hard, or that much of an effort, but it does take a little investment in time. There are some skills to learn in how to write tests, as well as knowledge on what patterns are useful as well as what types of things to test. To demonstrate this, I'll take a fairly simple query and show how to structure a test, as well as where the test can help us write better code.
Running Totals
One of the places where a T-SQL query can be cumbersome is in writing a running total. This isn't hard for experienced T-SQL developers, but it can be easy to make a mistake. I'm going to use a quick example that Kathi Kellenberger, our Simple Talk Editor, wrote about on her blog. Here's an older style running total query.
SELECT
CustomerID,
OrderDate,
CustomerRunningTotal =
(
SELECT CustomerRunningTotal = SUM(TotalDue)
FROM Sales.SalesOrderHeader
WHERE
CustomerID = A.CustomerID
AND OrderDate <= A.OrderDate
)
FROM Sales.SalesOrderHeader AS A
ORDER BY
A.CustomerID,
A.OrderDate;This produces a bunch of results from the AdventureWorks database. If you look at the bottom, this has 31,465 rows. Does anyone validate this? No, most people would grab a quick subset and check a customer or two. That might be OK, but in this case, it's a bug (as Kathi points out).

Ignoring the bug, there are better ways to write this, and in a 2012+ environment, the window functions are a great way to rewrite this. Now, I could just experiment and write a query, trying to structure it to get the same results. Of course, I'd probably just check the first 2 or 3 customers and see if the totals are correct. That might work, but it's error prone. I might miss some edge case, which is a common occurrence.
Instead, let's write a test.
Building the Test
I won't go into the tsqlt installation or how things work, but assume you have this set up. Let's start to structure a simple test to look at our code. The basic format of a unit test is
- Assemble an environment
- Act on some Data
- Assert a truth
To do this, we'll create a new test class and a basic outline of the test. Here's the basic template I use (with the names filled in).
EXEC tsqlt.NewTestClass @ClassName = N'ztsqltests' -- nvarchar(max)
GO
CREATE PROCEDURE [ztsqltests].[test running total query on Sales Order Header]
AS
BEGIN
--------------------------------------------
----- Assemble
--------------------------------------------
DECLARE @expected INT
, @actual INT
--------------------------------------------
----- Act
--------------------------------------------
--------------------------------------------
----- Assert
--------------------------------------------
EXEC tsqlt.AssertEquals @Expected = @expected,
@Actual = @actual,
@Message = N'Incorrect result'
END
GO
Now I'll fill out each section, and show how simple this can be.
Assemble
The assemble section is where I get the data set up and compute the expected results. In this case, I need to set up data in the Sales.SalesOrderHeader table. Since I'm only querying a few fields in the table, I only need data for those tables.
The structure for setup is to use tsql.faketable to make an exact copy of the table(s) I'm testing. Only one in this case, so I'll use this code:
--------------------------------------------
----- Assemble
--------------------------------------------
EXEC tsqlt.FakeTable
@TableName = N'SalesOrderHeader',
@SchemaName = N'Sales'
INSERT Sales.SalesOrderHeader
(
OrderDate,
CustomerID,
TotalDue
)
VALUES
( '2005-07-22', 11000, 3756.989),
( '2007-07-22', 11000, 2587.8769),
( '2007-11-04', 11000, 2770.2682)In this case, I actually queried the table and used the values for this customer and these fields. In general, I don't like doing this. First, these are difficult numbers to work with, and really don't provide any value over 100,200,300 for sales. Second, this potentially can be sensitive information, and I try to avoid this in dev/test. So, let me modify this to add just a set of fake data.
--------------------------------------------
----- Assemble
--------------------------------------------
EXEC tsqlt.FakeTable
@TableName = N'SalesOrderHeader',
@SchemaName = N'Sales'
INSERT Sales.SalesOrderHeader
(
OrderDate,
CustomerID,
TotalDue
)
VALUES
( '2005-07-22', 100, 100),
( '2007-07-22', 100, 200),
( '2007-11-04', 100, 300),
( '2007-07-22', 200, 200),
( '2007-08-22', 200, 200),
( '2007-09-22', 300, 200),
( '2007-10-22', 300, 200),
( '2008-05-22', 300, 200),
( '2008-07-22', 300, 200)
As I write tests, I'll actually save this test data in a SQL Prompt Snippet, or in a quick template that's in our VCS repo so other developers can have a set of data for this table. We can grow/alter this over time to use in tests. Usually I find lots of repeating data sets used in different tests, so I like to keep them around.
Note that I've just guessed with some scenarios. I have 3 rows for 1 customer, 2 for another, 4 for another with dates that span years and months. I can add to this over time, or as I find holes in my set. We'll see this later.
Now let's set up the results. We can quickly calculate the results we expect, but we need a place to put them. One easy way to do this is with a temp table. I could use a table variable or a real table in my test schema, but I'll just use a temp table here that is structured like the result set. The code looks like this:
CREATE TABLE #expected (
CustomerID INT
, OrderDate DATETIME
, CustomerRunningTotal MONEY);
INSERT #expected
(
CustomerID,
OrderDate,
CustomerRunningTotal
)
VALUES
(100, '2005-07-22', 100),
(100, '2007-07-22', 300),
(100, '2007-11-04', 600),
(200, '2007-07-22', 200),
(200, '2007-08-22', 400),
(300, '2007-09-22', 200),
(300, '2007-10-22', 400),
(300, '2008-05-22', 600),
(300, '2008-07-22', 800)
SELECT *
INTO #actual
FROM #expected AS e
WHERE 1 = 0
Note that I quickly calculate the running total. I can do this with easy numbers. Using the CTRL+ALT or SHIFT+ALT makes it easy to copy things across rows.
The last thing I do is create a place to store the results of my query. This is really it, and let's move on.
Act
The Act section is where I want to exercise my code. I could put a query in here, with an INSERT statement. That would be this:
--------------------------------------------
----- Act
--------------------------------------------
INSERT #actual
SELECT
CustomerID,
OrderDate,
CustomerRunningTotal =
(
SELECT CustomerRunningTotal = SUM(TotalDue)
FROM Sales.SalesOrderHeader
WHERE
CustomerID = A.CustomerID
AND OrderDate <= A.OrderDate
)
FROM Sales.SalesOrderHeader AS A
ORDER BY
A.CustomerID,
A.OrderDate;
I don't like doing this as I now need to maintain the query in two places. One nice thing about unit testing is it encourages developers to use stored procedures, just like they'd want methods used in C# or Java. So, let's change this:
CREATE PROCEDURE GetSalesOrderHeaderRunningTotal
AS
SELECT
CustomerID,
OrderDate,
CustomerRunningTotal =
(
SELECT CustomerRunningTotal = SUM(TotalDue)
FROM Sales.SalesOrderHeader
WHERE
CustomerID = A.CustomerID
AND OrderDate <= A.OrderDate
)
FROM Sales.SalesOrderHeader AS A
ORDER BY
A.CustomerID,
A.OrderDate;
Now, I can alter my test to say:
-------------------------------------------- ----- Act -------------------------------------------- INSERT #actual EXEC GetSalesOrderHeaderRunningTotal
I could leave the query here, or just make it a dummy proc that I use for testing and don't deploy. Of course, if I do deploy it, maybe I can get people to start calling that rather than using embedded SQL.
That's it for Act. Just call your code here and store the results.
Assert
The last section is where we assert some truth. I won't go into what assertions mean in computer science, but they are useful. In this case, I just want to assert that my actual results are equal to my expected results. In this case, I can use the tsqlt.assertequalstable to compare two tables.
--------------------------------------------
----- Assert
--------------------------------------------
EXEC tsqlt.AssertEqualsTable
@Expected = N'#expected',
@Actual = N'#actual',
@Message = N'Incorrect Results'
That's it.
Executing the Test
Now we want to see if our test works. We'll compile the code and get a new test class and a test. Once this is done, I could use SQL Test to execute this, but many of you may not have the Redgate SQL Toolbelt, so I'll use code. Here is how the execution works:
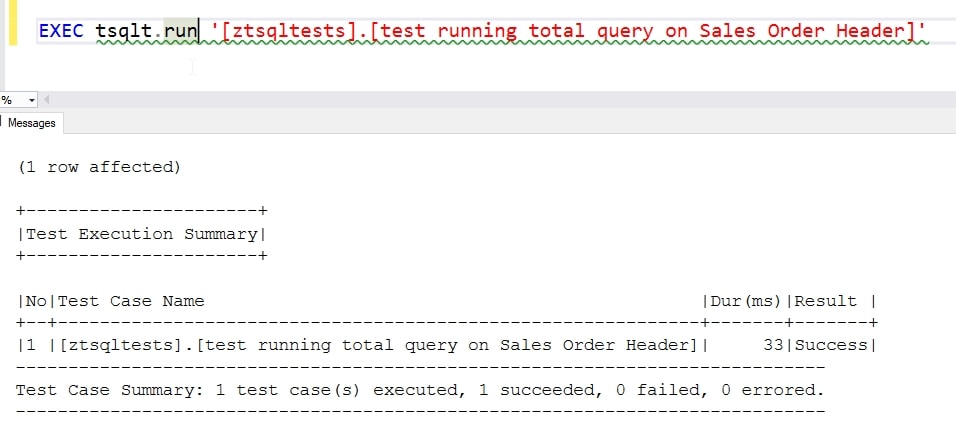
I use the tsqlt.run (or runall) procedure to call my test. This works, so everything is fine.
Or is it?
The Bug
If you read Kathi's article, you'll see there's a bug here. If there are two orders on the same day, this doesn't work well. In this case, the code doesn't properly account for this. My code doesn't find it because I didn't really consider this as a test case. However, what I can do is now add more data to account for this case. I'll alter my Assemble section like this for the test data:
INSERT Sales.SalesOrderHeader
(
OrderDate,
CustomerID,
TotalDue
)
VALUES
( '2005-07-22', 100, 100),
( '2007-07-22', 100, 200),
( '2007-11-04', 100, 300),
( '2007-07-22', 200, 200),
( '2007-08-22', 200, 200),
( '2007-09-22', 300, 200),
( '2007-10-22', 300, 200),
( '2008-05-22', 300, 200),
( '2008-07-22', 300, 200),
( '2010-01-02', 400, 200),
( '2010-02-02', 400, 300),
( '2010-02-02', 400, 400),
( '2010-03-02', 400, 200)I'll also then alter my results to show:
CREATE TABLE #expected (
CustomerID INT
, OrderDate DATETIME
, CustomerRunningTotal MONEY);
INSERT #expected
(
CustomerID,
OrderDate,
CustomerRunningTotal
)
VALUES
(100, '2005-07-22', 100),
(100, '2007-07-22', 300),
(100, '2007-11-04', 600),
(200, '2007-07-22', 200),
(200, '2007-08-22', 400),
(300, '2007-09-22', 200),
(300, '2007-10-22', 400),
(300, '2008-05-22', 600),
(300, '2008-07-22', 800),
(400, '2010-01-02', 200),
(400, '2010-02-02', 500),
(400, '2010-02-02', 900),
(400, '2010-03-02', 1100)
This has gotten me to think through the problem, and then calculate the result. Now that it's in the test, I can run it. As expected, this won't work. The test output shows me the issue:
[ztsqltests].[test running total query on Sales Order Header] failed: (Failure) Incorrect Results Unexpected/missing resultset rows! |_m_|CustomerID|OrderDate |CustomerRunningTotal| +---+----------+-----------------------+--------------------+ |< |400 |2010-02-02 00:00:00.000|500.0000 | |= |400 |2010-02-02 00:00:00.000|900.0000 | |= |400 |2010-03-02 00:00:00.000|1100.0000 | |= |100 |2005-07-22 00:00:00.000|100.0000 | |= |100 |2007-07-22 00:00:00.000|300.0000 | |= |100 |2007-11-04 00:00:00.000|600.0000 | |= |200 |2007-07-22 00:00:00.000|200.0000 | |= |200 |2007-08-22 00:00:00.000|400.0000 | |= |300 |2007-09-22 00:00:00.000|200.0000 | |= |300 |2007-10-22 00:00:00.000|400.0000 | |= |300 |2008-05-22 00:00:00.000|600.0000 | |= |300 |2008-07-22 00:00:00.000|800.0000 | |= |400 |2010-01-02 00:00:00.000|200.0000 | |> |400 |2010-02-02 00:00:00.000|900.0000 |
The way I read this is that anything with an equals sign (=) in the first column matches the results between the expected and actual tables. Anything with a greater than (>) is only in the actual table. A less than (<) would be something in the expected table. As we can see here, my actual results have a row different than I have in my expected results.
Refactoring
I don't want to go through all of the ways to write a running total, but I'll assume that I decide to make this easier with the window functions and the OVER clause. If I write this query in my procedure, the test still fails:
CREATE OR ALTER PROCEDURE GetSalesOrderHeaderRunningTotal
AS
SELECT
soh.CustomerID,
soh.OrderDate,
CustomerRunningTotal = SUM(soh.TotalDue) OVER (PARTITION BY soh.CustomerID
ORDER BY soh.OrderDate
)
FROM Sales.SalesOrderHeader AS soh;However, if I properly frame the query, by adding the ROWS clause, this code passes the test:
CREATE OR ALTER PROCEDURE GetSalesOrderHeaderRunningTotal
AS
SELECT
soh.CustomerID,
soh.OrderDate,
CustomerRunningTotal = SUM(soh.TotalDue) OVER (PARTITION BY soh.CustomerID
ORDER BY soh.OrderDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
FROM Sales.SalesOrderHeader AS soh;Re-running the test with that last code looks like this:
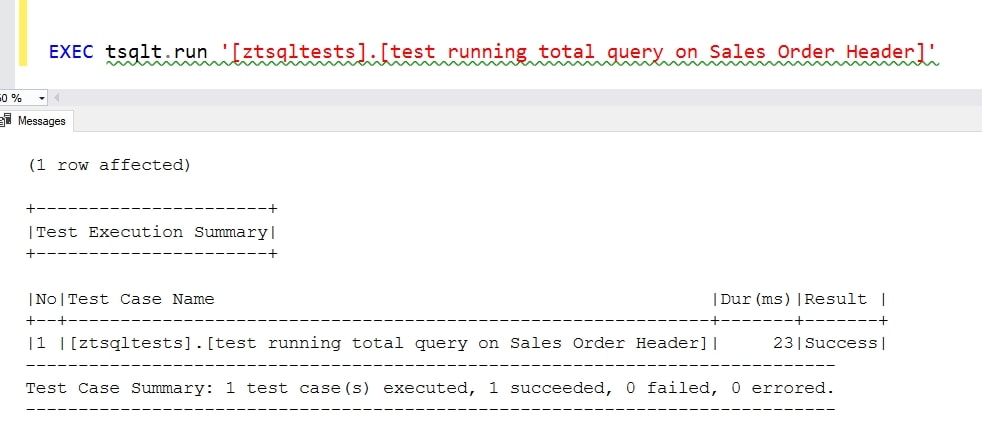
Summary
This might seem like a lot of effort, but stop and think about the time you'd spend querying the table for the source data, calculating results, then repeating that for different customers. After the bug, would you then test all cases or just the customer with the edge case if you refactored the code? Would you possibly introduce a regression? Imagine switching from older T-SQL to the window clause. Are you sure you've got the partition, ordering, and framing correct?
Humans make mistakes, and we can mis-read results. A test allows an automated process to evaluate things that I might make a mistake on. The test is also repeatable, so every time I change the query I can re-run the test. More importantly, an automated process such as Continuous Integration can run all the tests to be sure I haven't broken anything else that might depend on this code.
It's not that simple, and certainly I can make a mistake in my calculations of the expected results. That's one reason I like to keep the values simple, so that I can check the calculations easily. Or someone else can. Maybe most importantly for me, this documents what I think as the developer, right or wrong. In the future, we might find I mis-interpreted the specification, but at least we know that. I can also show a business person this case and have them be sure I've calculated things correctly.
Testing is an effort, and this might seem hard, but this entire article took me about 30 minutes to write. The code for the test was about 5 minutes. That's because I've practiced, I know the pattern for structuring the test, and I kept the data simple. If I find other edge cases or issues, I can make another test or add data to this test, depending on the particulars. I also converted this to a stored procedure, which might not be appropriate in your environment, but as I said, I could just keep that as a dummy procedure to test code and not deploy it.
Testing isn't that much more effort than the manual evaluation and guessing we do now for many of our complex queries. Once you practice a big and keep some templates/snippets around, I'd argue it's even quicker to build an automated test than do a manual one.
Testing is also an art to learn what to test and how. I advocate you starting to just test code you touch for bugs. Not all new code, but refactoring old code. Then decide what to test and where. I don't test existing code, I test new code, and just build up a set over time. This isn't perfect, and it doesn't catch every issue, but it does help ensure you don't regress and make the same mistakes over and over.
