

Introduction
Azure Synapse Analytics, previously known as Azure SQL Data Warehouse, is a widely utilized platform for storing large volumes of data, thanks to its Massively Parallel Processing (MPP) architecture. This article aims to provide a practical approach for efficiently loading high-volume data into Synapse, leveraging parallel processing techniques, and storing the data in Synapse tables for optimal performance.
Azure Synapse is a Massively Parallel Processing (MPP) database that leverages multiple CPUs running in parallel to execute a single program. In this article, we will explore an approach for managing high-volume data in Synapse tables using dynamic partitioning techniques to optimize performance and scalability.
Loading the data from an external source
To load data into Synapse, we will use the COPY INTO command. This command is fully parallelized, scales according to the cluster's compute resources, and does not require control permissions. To use it, you simply execute the COPY INTO command, specifying a pre-configured file format.

The COPY INTO command retrieves data from all files within a specified folder, including its subfolders. It performs efficiently when the data is split across multiple files. There are no restrictions on the number or size of the files being loaded, allowing for flexible and scalable data ingestion.
In this case, we choose Parquet files as the source because they are inherently partitioned. When we refer to "Parquet files," we are actually talking about multiple physical files, each representing a partition, so there's no need for further splitting. Parquet files are compressed, dictionary-encoded, and use a columnar storage format, making them highly efficient for parallel loading and processing. This structure aligns well with the parallel processing capabilities of Azure Synapse, enabling faster and more scalable data ingestion.
Given the advantages of Parquet, we typically use Spark or an external tool to create parquet files when loading data into a table. While this introduces an additional step in the process, for high-volume data, Parquet is preferred over other formats like direct tables or CSV.
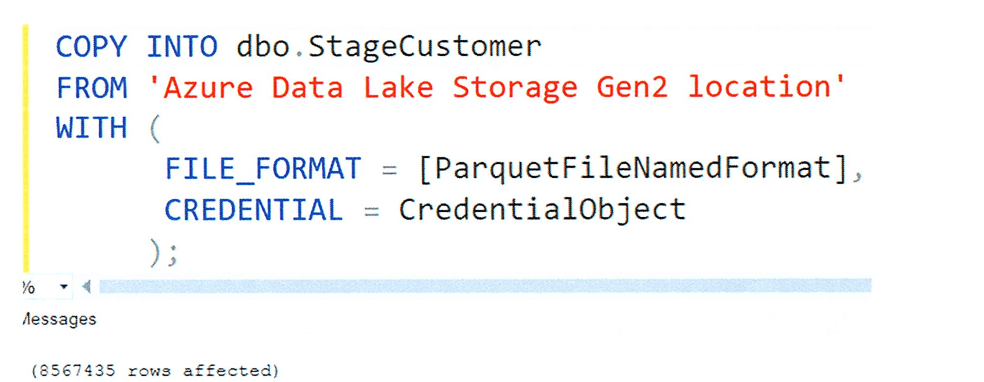
The data is loaded into Synapse from Azure Data Lake Storage (Gen2), although it also supports standard Blob storage locations. In the scenario described, the table has already been created. However, if the table doesn't exist, the COPY INTO command can still be executed by using the AUTO_CREATE_TABLE=ON option, which allows Synapse to automatically create the table during the load process. Since the COPY INTO command is fully parallelized, the data load is completed quickly, taking full advantage of the scalability and performance of the Synapse platform.
Fact table load with Dynamic Partitioning
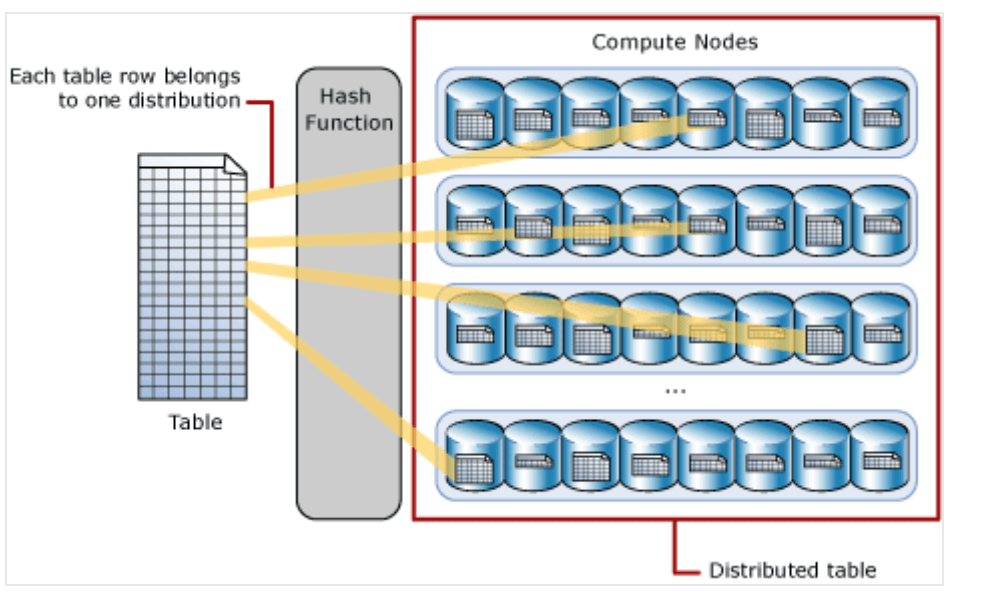
The next step is to load the data into a fact table in Synapse. In Synapse, tables are distributed across 60 distributions, making them appear as a single table, but in reality, the data is spread across multiple nodes. The distribution of rows is managed using either a hash or round-robin algorithm. This means that when you create a table in Synapse Analytics, the data is automatically partitioned across 60 distributions, partitioning further divides your data.
A hash-distributed table distributes table rows across the Compute nodes by using a deterministic hash function to assign each row to one distribution. Hash distribution improves query performance, particularly on large fact tables. The hash function we use here is an inbuilt function available in Synapse, specified during table creation by CREATE TABLE script. Each time data is inserted into the table, the hash function is triggered, which in turn determines the distribution where the row will be stored.
For optimal compression and performance of clustered columnstore indexes in Synapse, it is recommended to have a minimum of 1 million rows per distribution and partition. If you partition your table into 10 partitions, your table should have at least 600 million rows (60 distributions × 10 partitions × 1 million rows) to fully leverage the benefits of a clustered columnstore index. This ensures that the data is adequately distributed and compressed, which improves query performance by reducing I/O and speeding up data retrieval. For tables that do not have 600 million rows, it is better to avoid using the partitioning option. This ensures that the table remains a distributed table with the default 60 partitions.In that case, the PARTITION command is not necessary in the following create table script.
By default, dedicated SQL pool creates a clustered columnstore and clustered columnstore tables are usually the best choice for large tables.
Here we choose a hash distributed partitioned table. The partition should be a dynamic partition, and the partitioning process runs once a month and to create a new partition there should always be an empty partition exists. A query that applies a filter to partitioned data can limit the scan to only the qualifying partitions. This method of filtering can avoid a full table scan and only scan a smaller subset of data.
Creating a table with too many partitions or empty partitions can hurt performance under some circumstances and especially true for clustered column store tables.
Here, the TransactionID is used to distribute the data, while PartDate serves as the partition column. The PartDate is derived by transforming the TransactionTime into a date and replacing the day with the first day of the month. For example, 2023-08-26 18:37:40 is converted to 20230801 as the PartDate. When creating the table, we specify a number of partitions such that, after the initial load, we are certain that at least one partition will remain empty.In this case 20231101 will be empty after the initial load.
CREATE TABLE Sales.CustomerTransactions ( TransactionID BIGINT NOT NULL ,CustomerID BIGINT NOT NULL ,StoreID INT NOT NULL ,TransactionTime DATETIME NOT NULL ,SalePrice DECIMAL(10,2) NULL ,SaleQty INT NULL ,PartDate INT NOT NULL ) WITH (DISTRIBUTION = HASH(TransactionID), CLUSTURED COLUMNSTORE INDEX, PARTITION (PartDate RANGE LEFT FOR VALUES (20230801,20230901,20231001,20231101)
Table partitions and records in each partition after the initial load.
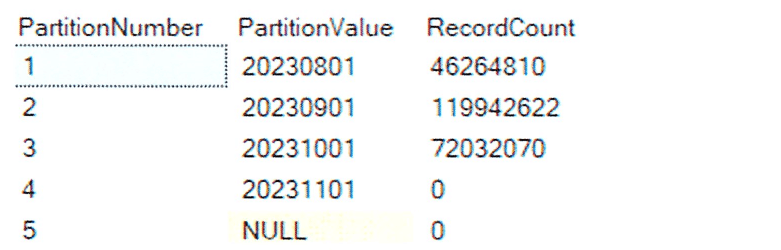
A table is created with predefined initial partitions, and every month, a new partition will be added to accommodate the incoming data.
The following ALTER TABLE command should be executed from a stored procedure, which can be scheduled to run during the last week of each month.
To add a new monthly partition for December 2023(20231201) , you need to ensure that an empty partition for 20231101 (November 2023) already exists. This process should be executed during the last week of October or just before the November data load.
CREATE PROCEDURE Sales.CreatePartitions AS BEGIN ALTER TABLE Sales.CustomerTransactions SPLIT RANGE (20231201); END
The table partition status once a new partition is created by executing the stored procedure.
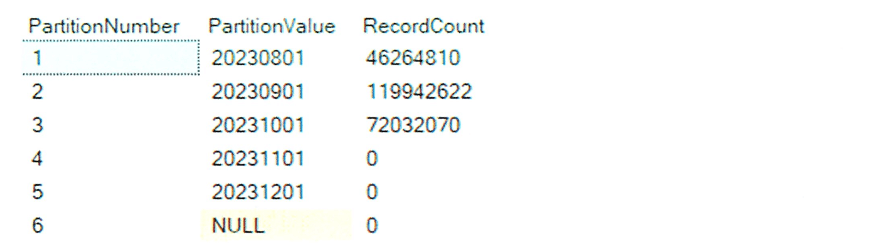
The load strategy we will implement is a "delete and insert" approach. This process will be executed via a stored procedure, and upon completion of the load, we will verify the row counts across each distribution to ensure the operation was successful.
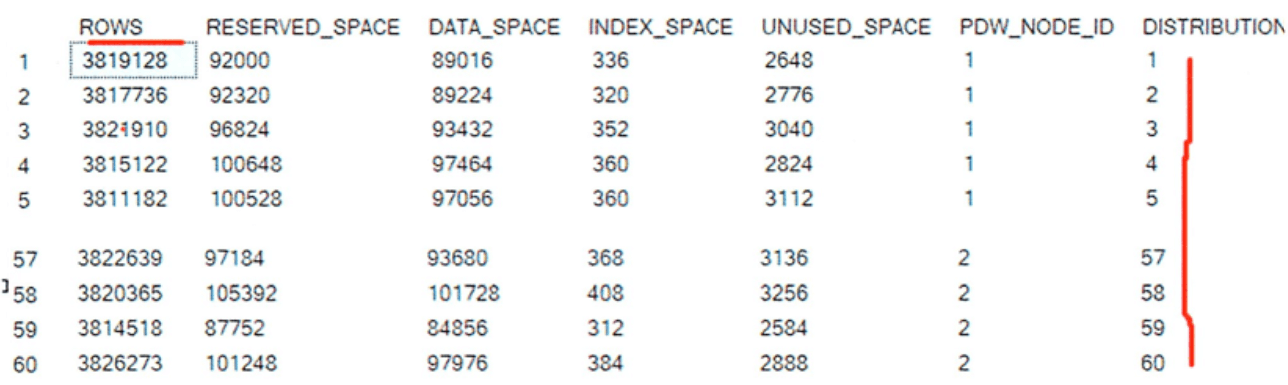
Below is the row count for each of the sixty distributions in the CustomerTransactions table, which can be retrieved using the DBCC command. The row count and the distribution numbers are highlighted in red below.
DBCC PDW_SHOWSPACEUSED (Sales.CustomerTransactions);
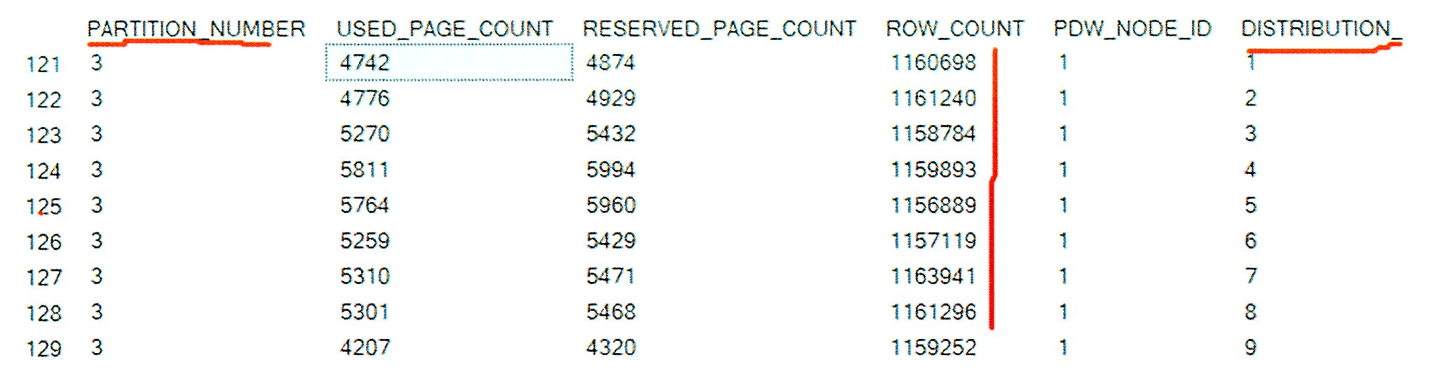
The query to retrieve the row count for each distribution and partition combination ensures that there are at least 1 million rows per partition for optimal performance. The result of this query will show 360 rows, corresponding to the total number of partitions (6 partitions, including the NULL partition, multiplied by 60 distributions). This ensures that data is evenly distributed and that each partition contains a sufficient volume of data for efficient query performance.
DBCC PDW_SHOWPARTITIONSTATS (Sales.CustomerTransactions);
Below is a partial result of all 360 rows. The partition number, row count, and distribution are highlighted, showing the number of rows per distribution and partition.
Conclusion
By utilizing the COPY INTO command for data ingestion, we can fully harness the parallelism of Azure Synapse Analytics, ensuring a more efficient loading process. Furthermore, with the fact table designed using dynamic partitioning based on data volume, the performance of analytics queries on the fact table is optimized.
