

Overview
Microsoft SQL Server 2012 introduced a feature called data classification, which allows you to mark certain columns with labels, indicating that these columns contain sensitive or special-handling data. For instance, you may want to mark a column containing credit card numbers as "confidential", or sales numbers as "management only".
The problem is that you can mark these columns all you want, but it won't have any immediate effect. SQL Server does not actually change its behavior with these labels: it's up to you to actually do whatever you need to do in your applications.
Let's see how data classification works, and how we can make it come to life with Gallium Data, a free database proxy.
Creating data classification
Data classifications can be created in SQL Server either with Transact SQL commands, or with a graphical tool. For instance you can annotate the first_name and last_name columns of a customers table with:
add sensitivity classification to demo.customers.first_name, demo.customers.last_name with ( label='Confidential', information_type='Personal', rank=critical )
You can do the same thing using graphical tools such as Microsoft's SQL Server Management Studio:
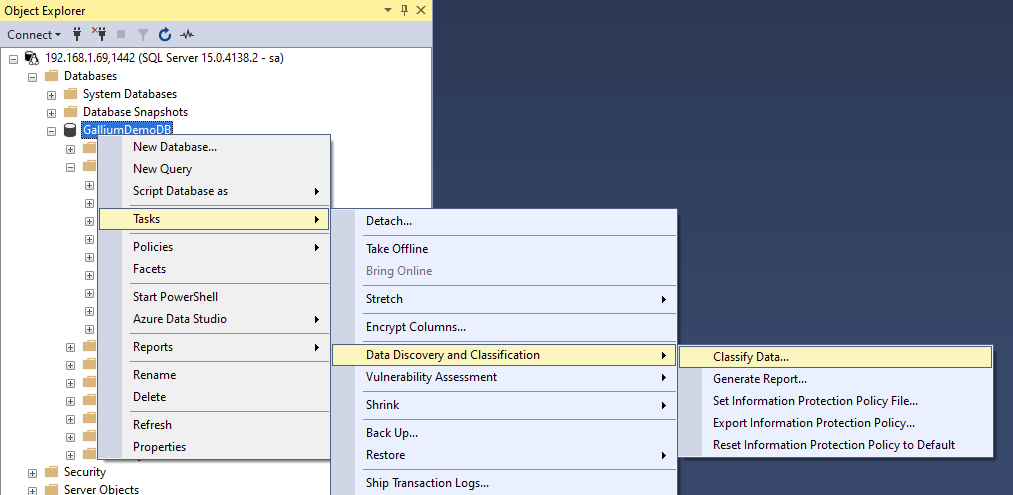
This allows you to set the classification of whatever columns you want. You can see this in the image below:
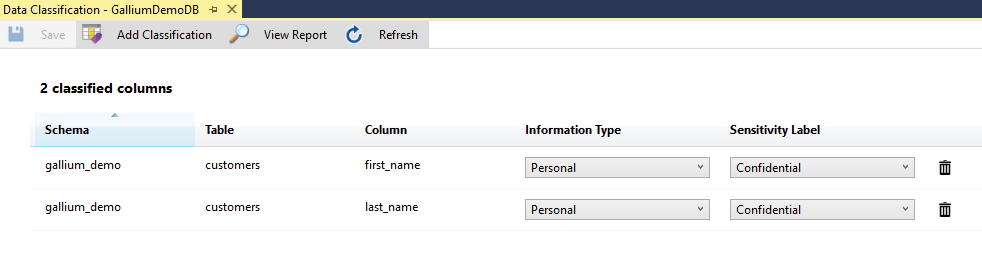
That's all fine and dandy, but as mentioned before, these classifications have no effect unless your applications take them into consideration.
How does data classification work?
When your database client executes a SQL command that returns a data set, such as select * from demo.customers, the response from SQL Server contains some metadata about the data being returned, including the names of the columns, their data types, sizes, and so on.
If your client supports it (and some SQL Server drivers don't, like Node and Python, or older drivers), this metadata can also include the classification for the data. For instance, the fact that column customers.first_name has information type "Personal" with sensitivity "Confidential".
But that's as far as SQL Server goes -- it's up to the database client to then do something with that information. So there are four main problems here:
- This data classification business seems pretty academic since it has no effect on how the data is handled by the database
- The data classification information is not even available to some clients, because their database drivers do not support it
- Even if the database driver supports it, the applications still need to include some special handling to reflect the meaning of the data classification
- Even if your applications handle data classification properly, the data is still sent over the wire, which may be a problem if these applications are running in an untrusted environment (e.g. user machines)
Making data classification actually do something
Using Gallium Data, we can easily change the traffic between database clients and database servers so that the data classifications actually do have an effect, without changing the database or the clients. The database clients simply connect to the proxy instead of connecting directly to the database:

and the proxy can change the network traffic based on user-defined logic.
Basic enforcement
Let's say you've decided that data classification is a nifty feature that would enhance your application, but you don't want to (or cannot) change that application. After all, it takes a non-trivial amount of work to make these changes, and it may not even be an option if your database driver does not support this feature, or if it's a third-party application.
Gallium Data has a special filter that can ensure that data classification metadata is accessible to your proxy logic even if your application does not support it. With that in place, it's then easy to create a response filter with two lines of JavaScript:
if (context.packet.columnHasSensitivity("first_name", "Confidential")) {
pkt.first_name = "<hidden>";
}This will show or hide the values of the first_name column depending on whether it's marked as Confidential or not. Obviously, we can make this much more flexible depending on whatever factors are relevant.
Dynamic enforcement
Eagle-eyed readers have no doubt noticed that the name of the first_name column was embedded in the filter code. That may be OK in many situations, but we can do better -- we can simply use the result set metadata and make this much more flexible:
let pkt = context.packet;
for (let meta of pkt.columnMetadata) {
if (pkt.columnHasSensitivity(meta.columnName, "Confidential")) {
pkt[meta.columnName] = "<hidden>";
}
}This will now work with any textual column, and we could make it work with any column by setting the value to null instead of a string.
A more complete example
One of the beauties of working with a database proxy is that you can change many aspects of the database behavior in one fell swoop. For instance, we could imagine a database with many tables and columns containing confidential data, for which we have two requirements:
- if a row contains a numeric column marked as "Private" with a value greater than 1000, then hide the entire row
- if a row contains a numeric column marked as "Private" with a value between 200 and 1000, then hide the value of that column and, if the row also has a column named "title", add *** to that title to make it stand out.
This can be done with a simple response filter:
let pkt = context.packet;
for (let meta of pkt.columnMetadata) {
if (pkt.columnHasSensitivity(meta.columnName, "Private") &&
meta.typeInfo.typeName === 'numeric') {
if (pkt[meta.columnName] > 1000) {
pkt.remove();
}
else if (pkt[meta.columnName] > 200) {
pkt[meta.columnName] = null;
if (pkt.title) {
pkt.title += " ***";
}
}
}
}This is obviously an arbitrary example, but you get the gist: this doesn't have to be done one column at a time, and can be driven by the data, the metadata and whatever other factors are relevant - the user's IP address, the day of the week, etc...
Conclusion: bringing data classification to life
SQL Server's data classification is an interesting idea that has not fulfilled its potential. Of course, it's difficult, if not impossible, to anticipate all the possible uses of data classification, but making it entirely the responsibility of the applications seems like a cop-out. Surely there could be some cross-linkage with data masking, for instance, or with the permission system. Instead, data classification is purely informational, for instance in server audits, but does not influence the behavior of the database.
Gallium Data is a good way to bring that potential to fruition, with minimal effort. If you want to try it out for yourself, there is a step-by-step tutorial that will show you how to do all of this on your own machine.
P.S.
If you're intrigued, you may be interested to see how Gallium Data can also help with row-level security, or data masking to control data access, and how Gallium Data can easily restrict queries based on prior behavior.