

Overview
As we all know, data security is a never-ending battle. Every day, we hear of new data breaches. It's a hard problem, and there is no single solution, other than a defense in depth. Let's look at one of those defenses for databases: query control.
Query control is a simple idea: most applications access their database(s) in a fairly predictable way. We can therefore record the requests from these applications during a period of time (like during testing). We'll call this the recording phase. Once we're satisfied that we've seen all the request types we're likely to see, we can lock down the application by rejecting any requests we haven't seen before. We'll call this the enforcement phase, which is normally used during production.
This guarantees that, no matter what happens, the application will never be able to do anything in the database that it hasn't done before. This is not a panacea, but it's a good defense. Obviously, this approach is possible only for applications that do, in fact, issue a finite number of query types, but that includes many, perhaps even most applications.
In this article, we'll go over the general architecture and concepts. If you're not afraid to get your hands a little bit dirty, you can then try the step-by-step tutorial showing how to try this on your own machine - all it requires is Docker.
Benefits
Query control has a number of benefits:
- it's easy to put in place, since it doesn't require any changes to the database(s) or the applications
- it can be applied selectively to some applications and not others, or only for some users
- it can mitigate the damage if an application gets compromised
- it can help with compliance, since we literally know every request that will be allowed to run
- it can protect us from SQL injections (and other injections -- this concept is not limited to SQL)
- it will allow us to quickly detect a change in the behavior of the applications, which can be a sign of mischief
This is not an original idea: there are some (very expensive) products that do this type of thing, but we can roll our own, at no cost, using off-the-shelf components.
Architecture
To do query control, we need two new components:
- a database proxy, which will intercept requests on their way to the database, and either record them (recording phase), or verify that they are authorized (enforcement phase). Here we'll use Gallium Data, a free database proxy
- a database, to keep all the recorded requests
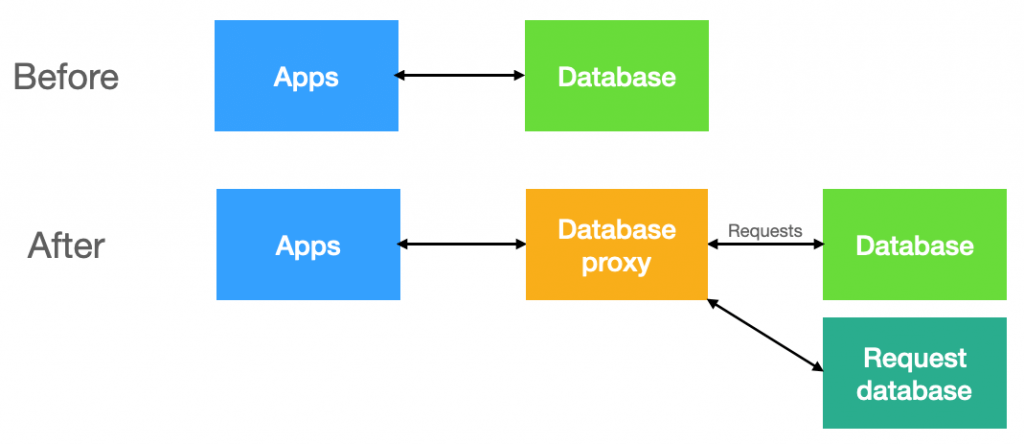
Level 1: minimalist
The simplest system we can put together is:
- a query filter in the proxy (Gallium Data) to intercept requests and record them in the request database - this is the recording filter
- another query filter in Gallium Data to verify that the request is present in the request database - this is the enforcing filter
The queries will be stored in the world's simplest table:
create schema qres;
create table qres.query
(
query nvarchar(max)
)though the request database doesn't have to be relational: something like Redis or MongoDB would work equally well.
The recording filter in Gallium Data will simply store each request in the query table if it's not already there. This can be done with just a few lines of code (see the hands-on tutorial if you want to see that code).
With that filter in place, we'll need to exercise the client application(s) to issue all the requests we expect. This could take anywhere from a few minutes to a few weeks, depending on the complexity of the application.
Once that's done, we'll have a number of requests recorded in the query table. That number can vary widely, from just a few for simple applications, to many thousands (or more) for larger applications.
We can then deactivate the recording filter and activate the enforcement filter. It will receive requests, look in the query table to see if the request is known, and reject the request if it doesn't find it (it could also ignore it, flag it, etc...). Again, this is easily done in a query filter in just a few lines of code.
That's it! We now have a running query control system, and we can easily switch between recording mode and enforcing mode by enabling one filter and disabling the other.
For some applications, this may actually be sufficient. But many applications will require more.
Level 2: more flexibility
Some applications need more flexibility because they don't always use prepared statements. It's not unusual to get hard-coded values in SQL commands, such as:
select * from mydb.customers where name2 like 'Adam%' or status = 99 select * from mydb.customers where name2 like 'Bru%' or status = 63 select * from mydb.customers where name2 like 'Ch%' or status = 8 etc...
We all know that this is not optimal, and that a prepared statement:
select * from mydb.customers where name2 like ? or status = ?
would usually be preferable, but the world is an imperfect place, and changing the application is often difficult and expensive.
The solution is actually simple: we just need to normalize SQL queries, which turns out to be fairly easy (for details, see part 2 of the hands-on tutorial). Again, it just takes a few lines of code (3, to be exact) to turn a SQL statement like:
select * from mydb.customers where name2 like 'Adam%' or status = 99
into:
SELECT * FROM MYDB.CUSTOMERS WHERE NAME2 LIKE <STR> OR STATUS = <NUM>
Now all these queries will be matched by just one record in the query table. Much better!
Level 3: parameter checking
In many situations, it makes sense to restrict the value of parameters for some prepared statements and stored procedures. This is particularly true for some system stored procedures like sp_executesql, but that applies to your own stored procedures too.
The simplest way to store the allowed values for parameters is either as strings or as regular expressions. We'll need to expand our table, of course:
create table qres.query
(
query nvarchar(max),
param1 nvarchar(max),
param2 nvarchar(max),
param3 nvarchar(max),
etc...
)The valid values for the parameters can be stored as one value, or a few values (maybe separated by commas), or a range (e.g. 1-100), or a regular expression... You get the idea. When a parameter is out-of-bounds, our filter can choose to reject the request with an error, or change the parameter value.
In many cases, it will be possible to programmatically derive the allowable range for parameters as the requests are recorded, or their minimum and maximum length. If desired, you can also specify parameter ranges manually, of course.
And beyond
There are many more things we could do at this point:
- we don't necessarily have to reject unknown queries -- we could flag them and track them instead
- we could keep track of how many times each query gets executed
- we could rate-limit each query so that it can only be executed so many times within a given time period
- we could keep track of how long each request takes, and use that information to limit the number of invocations
- we could restrict each request based on its origin, the user sending it, the time of day, and whatever makes sense
- we could speed up the lookup of queries using a hash (shown in the tutorial)
What else can you think of?
Conclusion
Query control can be a valuable and fairly easy addition to your data protection infrastructure. If your applications are good candidates, you can probably try it out in minimal time. There is a warm, fuzzy feeling when you lock down an application and know that, no matter what happens, hackers will have a tougher time exploiting it for nefarious purposes.
To really get a feel for how query control works, you can go though the hands-on tutorial and see it running on your own machine, where you can tweak it or extend it -- all you need is Docker installed and running.
Beyond query control, I hope you got a sense that using a proxy in front of your database(s) opens up all kinds of new possibilities, without making any changes to your applications or your databases. A proxy can be a great fulcrum to control and change how your systems work.
