

With origins from the world of “Submarine ‘Dolphin’ Qualification” questions, an “Oolie” is a difficult question to answer, or the knowledge or fact needed to answer such a question, that may or may not pertain to one's duties but tests one's knowledge of a system or process to the limit.
 The Coveted "Dolphin" Pin
The Coveted "Dolphin" PinIntroduction
Contrary to what many of us have been taught, there actually is a way to perform T-SQL INSERTs that DO follow the Fill Factor!
What we've been taught is that, under normal conditions, (from MS Docs and the emphasis is mine) “The FILLFACTOR setting applies ONLY when the index is CREATED or REBUILT. The Database Engine does NOT dynamically keep the specified percentage of empty space in the pages.” - CREATE INDEX (https://docs.microsoft.com/en-us/sql/t-sql/statements/create-index-transact-sql)
For example and again, under normal conditions, if a Clustered Index is based on a unique, “ever increasing” key (such as a column with the IDENTITY property) and if the length of the rows isn’t too long, the pages will be filled to nearly 100% full during an INSERT no matter what the “Assigned” Fill Factor of the Clustered Index is.
However, under certain very strict but simple, easy to impart, and commonly used conditions, a special type of multi-row first INSERT can result in an “Effective” Fill Factor identical to that of the Clustered Index as surely as if the Clustered Index where just rebuilt. This is because the data is inserted as a part of an “offline index build”. In other words, the rows are inserted as a part of an intrinsic CREATE INDEX.
This article is about what those conditions need to be and provides the readily consumable code for anyone to verifiably prove this mostly unknown fact in a consistent and repeatable manner. It also suggests some possible uses for this undocumented phenomenon.
Common Code to Setup the Tests
Just to keep things really simple, both sections of this code need to be executed before the upcoming “Normal” test and then again before the “Special” test. Doing so guarantees the following;
- It guarantees that there is no mutual interference between the tests.
- It guarantees the Transaction Log File is absolutely cleared.
- It keeps the log file relatively small.
- It keeps things really simple. There are other methods to do all the above but require slightly more complexity.
- Above all, the setup for each of the two tests is absolutely identical and without any inconsistencies.
Because most people run their databases in the FULL recovery model, we need to use the FULL Recovery Model for the test code in this article. To actually get a database into a real FULL Recovery Model, we have to do a FULL backup on top of making sure that the FULL Recovery Model is active.
Since this is just a test/demonstration, we don’t want to dedicate any disk space to backup files nor do we want to be bothered later with having to find the files and drop them. With that idea in mind, we’re going to backup to the “NUL” device, which is one form of the proverbial “Bit Bucket”. In other words, the backups won’t appear anywhere, but they’ll register as if they had.
Code to Create the Test Database
Just so we can control absolutely everything in our test environment, we’ll build a special database to do our testing in. The following code creates the database, sets the FULL Recovery Model, and does the FULL backup to the NUL device.
--===== Environmental Presets
SET NOCOUNT ON
;
--===== Make sure that we're not using in the database we want to drop
USE master
;
--===== Check to see if the test database already exists.
-- If it does, issue a warning, wait for 20 seconds to give the
-- operator a chance to stop the run, and then drop the database
-- if the operator doesn't stop the run.
IF DB_ID('SomeTestDB') IS NOT NULL --select DB_ID('SomeTestDB')
BEGIN
--===== Issue the warning on both possible displays.
-- This message will appear in the GRID if its enabled and on the
-- messages tab, if not.
--====================================================================
SELECT [***** WARNING! ***** WARNING! ***** WARNING! *****] =
'***** WARNING! ***** WARNING! ***** WARNING! *****'
UNION ALL
SELECT ' THIS CODE WILL DROP THE [SomeTestDB] DATABASE!'
UNION ALL
SELECT ' YOU HAVE 20 SECONDS TO STOP THIS CODE'
UNION ALL
SELECT ' BEFORE THE DATABASE IS DROPPED!!'
UNION ALL
SELECT '***** WARNING! ***** WARNING! ***** WARNING! *****'
;
--===== Force materialization/display of the warning message.
RAISERROR('',0,0) WITH NOWAIT
;
--===== Wait for 20 seconds to give the operator a chance to
-- canceldropping the database.
WAITFOR DELAY '00:00:20'
;
--===== At this point, the operator has not stopped the run.
-- Drop the database;
EXEC msdb.dbo.sp_delete_database_backuphistory
@database_name = N'SomeTestDB'
;
ALTER DATABASE SomeTestDB
SET SINGLE_USER WITH ROLLBACK IMMEDIATE
;
DROP DATABASE SomeTestDB
;
END
;
GO
--====================================================================
-- Create the test database
-- Remember that such a simple creation will create the database
-- in whatever directories are the default directories for MDF
-- and LDF storage. Change the code below if the files for
-- this database need to be stored somewhere else.
--====================================================================
--===== Create the database.
CREATE DATABASE SomeTestDB
;
--===== Set the database to FULL Recovery Model.
ALTER DATABASE SomeTestDB SET RECOVERY FULL WITH NO_WAIT
;
--===== Take a backup (to the BitBucket) to ensure the test database
-- is in the FULL Recovery Model.
BACKUP DATABASE SomeTestDB TO DISK = 'NUL'
;
GOCode to Create the Test Table
This code creates the test table with a Unique, “Ever Increasing” (IDENTITY column), Clustered Index as described in the “Introduction” section of this article. Note that the Clustered Index has an “Assigned” FILLFACTOR of 70%.
--===== Use the new test database for the following code.
USE SomeTestDB
GO
--====================================================================
-- If the test table already exists, drop it.
--====================================================================
IF OBJECT_ID('dbo.SomeTestTable','U') IS NOT NULL
DROP TABLE dbo.SomeTestTable;
GO
--====================================================================
-- Create the test table with a Fill Factor of 70 on the CI.
--====================================================================
CREATE TABLE dbo.SomeTestTable
(
RowNum INT IDENTITY(1,1)
,SomeDT DATETIME
,SomeINT INT
CONSTRAINT PK_SomeTestTable
PRIMARY KEY CLUSTERED (RowNum)
WITH (FILLFACTOR = 70)
)
;
GOThe “Normal” Test
This “Normal” test will demonstrate and confirm what MS Docs said about the FILLFACTOR setting.
We’re not going to do all the proofs possible. There are just too many permutations to cover in an article of this nature. We’re only going to do simple proofs for two things that are related to the claim that that the title of this article makes;
- Doing a first INSERT into a new table having a Unique, “Ever Increasing”, Clustered Index with a Fill Factor of 70%.
- Doing a secondary INSERT on the same table, which will already have rows in it after the first INSERT.
Code to Do the “Normal” Test
This code will do the two multi-row inserts and measure the page density (“Effective” Fill Factor) after each INSERT using sys.dm_db_index_physical_stats (the same tool used to check for fragmentation).
--===== Use the new test database for the following code.
USE SomeTestDB
GO
--====================================================================
-- Populate the test table in 2 batches of 100,000 each.
-- Report the page density after each batch.
-- The code for each insert is absolutely identical.
--====================================================================
--===== First batch of INSERTs
INSERT INTO dbo.SomeTestTable
(SomeDT,SomeINT)
SELECT TOP (100000)
SomeDate = RAND(CHECKSUM(NEWID()))
* DATEDIFF(dd,'2000','2020')
+ DATEADD(dd,0,'2000')
,SomeInt = ABS(CHECKSUM(NEWID())%100)+1
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
SELECT PageDensity = avg_page_space_used_in_percent
,RowCnt = record_count
FROM sys.dm_db_index_physical_stats
(DB_ID(),OBJECT_ID('dbo.SomeTestTable','U'),1,NULL,'SAMPLED')
;
----------------------------------------------------------------------
--===== Second batch of INSERTs
INSERT INTO dbo.SomeTestTable
(SomeDT,SomeINT)
SELECT TOP (100000)
SomeDate = RAND(CHECKSUM(NEWID()))
* DATEDIFF(dd,'2000','2020')
+ DATEADD(dd,0,'2000')
,SomeInt = ABS(CHECKSUM(NEWID())%100)+1
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
SELECT PageDensity = avg_page_space_used_in_percent
,RowCnt = record_count
FROM sys.dm_db_index_physical_stats
(DB_ID(),OBJECT_ID('dbo.SomeTestTable','U'),1,NULL,'SAMPLED')
;
GOResults
Here are the results from the “Normal” test. There are no surprises here. It looks like the MS Docs are exactly correct. The Fill Factor of 70% was ignored by both INSERTs and the pages were filled to as close as 100% as the row sizes would allow for both INSERTs.
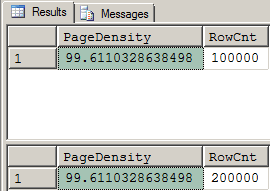 Figure 1: Page Density Results After "Normal" Inserts
Figure 1: Page Density Results After "Normal" InsertsThis also means that we would have to REBUILD the Clustered Index to get our 70% Fill Factor to come into play and so, to say it again, the MS Docs are absolutely correct… for “normal” conditions.
The “Special” Test
To summarize this section, we’re going to do everything we did in the first test, starting with dropping and creating the test database so that we don’t have to deal with the old log data that we generated in the previous test and to keep things absolutely consistent. You’ll need to run that common code first.
Then we’re going to drop (even though we don’t need to because we dropped/rebuilt the whole DB, in this case) and rebuild the test table with exactly the same code we used before. The Clustered Index will still have an “Assigned” FILLFACTOR of 70%. Again, you need to run that common code before running this test.
Then, we’ll do the two multi-row INSERTS, as we did before, but the code for each INSERT will have a very slight modification in it to setup the “Special Conditions”. And, as before, we’ll also measure the page density after each insert to see what’s happening.
Code to Do the “Special” Test
Just as a reminder, we’re in the FULL Recovery Model and we previously did a backup to guarantee it. As another reminder, the code is nearly identical to the previous test but it does have one small change for each insert; WITH(TABLOCK) has been added to the table being inserted into.
RAISERROR ('
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
NOTICE! BEFORE RUNNING THIS TEST, RUN THE "CREATE TEST DATABASE"
AND THE "CREATE TEST TABLE" SECTIONS AGAIN!
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
',0,0) WITH NOWAIT
;
--===== Use the new test database for the following code.
USE SomeTestDB
GO
--====================================================================
-- Populate the test table in 2 batches of 100,000 each.
-- Report the page density after each batch.
-- The code for each insert is nearly identical to the previous
-- test code but WITH(TABLOCK) has been added to each INSERT.
--====================================================================
--===== First batch of INSERTs
INSERT INTO dbo.SomeTestTable WITH(TABLOCK)
(SomeDT,SomeINT)
SELECT TOP (100000)
SomeDate = RAND(CHECKSUM(NEWID()))
* DATEDIFF(dd,'2000','2020')
+ DATEADD(dd,0,'2000')
,SomeInt = ABS(CHECKSUM(NEWID())%100)+1
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
SELECT PageDensity = avg_page_space_used_in_percent
,RowCnt = record_count
FROM sys.dm_db_index_physical_stats
(DB_ID(),OBJECT_ID('dbo.SomeTestTable','U'),1,NULL,'SAMPLED')
;
----------------------------------------------------------------------
--===== Second batch of INSERTs
INSERT INTO dbo.SomeTestTable WITH(TABLOCK)
(SomeDT,SomeINT)
SELECT TOP (100000)
SomeDate = RAND(CHECKSUM(NEWID()))
* DATEDIFF(dd,'2000','2020')
+ DATEADD(dd,0,'2000')
,SomeInt = ABS(CHECKSUM(NEWID())%100)+1
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
SELECT PageDensity = avg_page_space_used_in_percent
,RowCnt = record_count
FROM sys.dm_db_index_physical_stats
(DB_ID(),OBJECT_ID('dbo.SomeTestTable','U'),1,NULL,'SAMPLED')
;
GORESULTS
Here are the results from that test. SURPRISE!!!
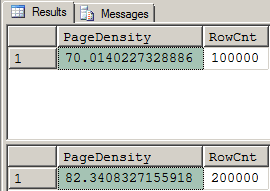 Figure 2: Page Density Results After "Special" Inserts
Figure 2: Page Density Results After "Special" InsertsAs you can clearly see, the first INSERT appears to have actually and dynamically observed and followed the Fill Factor. What about the second one? It didn’t. It actually went back to an “Effective” Fill Factor of nearly 100% but, because the table already had a bunch of rows that were only filled to 70% (which is what the Fill Factor of the Clustered Index is), the average page density panned out at 82%. The 82% is lower than the expected average of (70%+100%)/2 = 85% but that’s due to another “Oolie” that I’ll write about in the future.
We still need to know... How on this good Green Earth are the results from that first INSERT possible? The first INSERT resulted in a page density of 70% meaning that the 70% Fill Factor on this table appears to have been observed and used by the INSERT. Is the information in the MS Docs about the FILLFACTOR being applied “ONLY when an index is CREATED or REBUILT” actually wrong?
No. It’s not wrong. It’s absolutely correct. In the presence of the WITH(TABLOCK) “hint” (“directive”, really), the Clustered Index in the first INSERT is actually “built” as a part of the transaction that the first INSERT lives in. Let’s prove it.
Proof that an Index BUILD is Present in the First Insert
When I first ran into this phenomenon, I had no idea why it was happening. My luck was with me though. A couple of weeks prior to all this testing, I started following small series of articles by Paul White on the subject of “Minimal Logging”, which was something else I was working on. Right about the time I ran into this FillFactor “feature”, Paul posted the article at the following link and, even though he hadn’t run into the first INSERT following the FillFactor, the answer as to why it worked was staring me in the face.
https://sqlperformance.com/2019/05/sql-performance/minimal-logging-empty-clustered
So why does it happen? Let's see!
Code to Examine the Transaction Log File (Analysis Code)
Because the database was dropped and rebuilt for this later test, none of the first test exists in the log file. Only the log entries from the second “Special” test are currently in the log file. With that in mind, let’s see if there’s any evidence of an index build in the log at all and, if any exists, where they are in relationship to the two inserts we did.
Here’s the code to check the log.
--===== Code to find an index rebuild in the transaction log
-- and when it occurred in relationship to the INSERTs.
SELECT [Current LSN]
,[Transaction Name]
FROM sys.fn_dblog(NULL,NULL)
WHERE [Transaction Name] LIKE '%index%'
OR [Transaction Name] LIKE '%INSERT%'
ORDER BY [Current LSN]
;Results
Here are the results of that code. The log file clearly shows that an “offline index build” occurred as a part of the first INSERT but not as a part or even after the second INSERT simply because you can’t build the same index twice on the same table. That’s why the first INSERT appeared to follow the FILLFACTOR of the Clustered Index and the second INSERT did not.
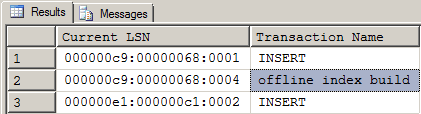 Figure 3: Transaction Log Results Show Why the Fill Factor Was Followed After the First Insert
Figure 3: Transaction Log Results Show Why the Fill Factor Was Followed After the First InsertAll of this occurs because of the use of the WITH(TABLOCK) hint (directive, really) and some of the changes MS made in 2008 to help with “Minimal Logging” for INSERT/SELECT. It doesn’t, however, happen only when we’re actually setup to do “Minimal Logging”. It happens in all Recovery Models, even the FULL Recovery Model and we just proved that.
Required Conditions to Make It Work
Here are the conditions, so far, that the table and Clustered Index must be in for this to happen. I say “so far” because this is all new to me and there could be more conditions that I simply haven’t tested for, yet.
- Obviously, the table must have a Clustered Index. The Clustered Index may be a composite index and the data-type of the leading column doesn’t seem to matter. This has also been tested with random GUIDs and the “offline index build” still occurred.
- The table must have ONLY a Clustered Index. It will not work if a Non-Clustered Index is on the table.
- The table must be empty. This only works on the first INSERT, regardless of its size.
- An existing table may be TRUNCATEd but the TRUNCATE must be done in a separate batch. If the TRUNCATE is done in the same batch, the post INSERT “offline index build” will not occur because the table isn’t empty at run time. The use of Dynamic SQL to execute a TRUNCATE in the same stored procedure also does NOT work.
- Dropping and creating the table in the same batch as the first INSERT DOES work.
- DELETEing all rows does not work.
- It doesn’t matter which Recovery Model is used.
- If needed, OPTION(MAXDOP 1) does NOT prevent the first INSERT from working like the “Special Test”.
For more information on the changes made in 2008, please refer to Paul White’s mini-series of articles on “Minimal Logging” at the URL I posted above. Please also search for “offline index build” in his article for a brief but concise bit of information as to why the “offline index build” occurs when WITH(TABLOCK) is used and only when it is used. If I read it correctly, the “offline index build” is what is actually inserting the rows on the first INSERT.
As a bit of a sidebar, most of the requirements stated for the first INSERT to execute the “offline index build” are also the same requirements to get “Minimal Logging” to work even though, especially being in the FULL Recovery Model, we’re not trying to get “Minimal Logging” to work.
Possible Uses
There are a few possible uses for this behavior.
First, a Very Necessary Disclaimer
Before the “Undocumented/Unsupported Feature Police” try to Pork Chop me (an inside joke for the denizens of SSC), do realize that this is a totally undocumented and unsupported feature that can change at any time. That being said, it started working in at least SQL Server 2008 (I’ve not tried it in 2005) and it worked for me in all versions up to and including SQL Server 2016 but there's no guarantee that an SP or CU or new version won't take it out.
Quickly Build Test Data and the Clustered Index at the Same Time
One possible use of the “Oolie” method covered in this article is to help during testing (this is where I discovered the phenomenon quite by accident) . It’s a well known fact that it’s much faster to create a test table with the correct Clustered Index and then insert the required test data (especially in the SIMPLE or BULK LOGGED Recovery Models) than it is to use SELECT/INTO to create the HEAP and then build the Clustered Index. That fact that the first INSERT (using WITH(TABLOCK)) will auto-magically use the FILLFACTOR of the Clustered Index as a part of the transaction for the first INSERT is a huge bonus for testing purposes.
ETL and Imports
It could also be used when populating a table with a Clustered Index from external sources (I’ve not specifically tested with something like BULK INSERT but think “ETL” here) where you want a less than a 100% FILLFACTOR to prevent page splits when you’re prepping data for its final target. Again, there’s that warning about not using such an unsupported feature for production.
Win Bets – Retire Early
I suspect that not too many people know about this SQL “Oolie”. Test the code on the machine of your choice to make absolutely sure that it works for you and during the next discussion about Clustered Indexes, bet anyone that says you can’t make an INSERT follow an already “Assigned” Fill Factor on an empty Clustered Index. 😀
Just make sure that you know the scenario. If some other negating condition exists other than the ones that have already been listed in this article, even at the server level, you don’t want to make the bet because I’m not going to help you pay off the bet debt. I will be happy, though, to take 20% of the cut on any bets that you win! 😉
Conclusion
While it’s still true that the FILLFACTOR is applied only during index creation or rebuilds, we did prove that the first INSERT to a Clustered Index will respect and follow the FILLFACTOR assigned to the Clustered Index because of an inseparable “offline index build” if the right conditions are met.
I can’t speak for you but I’ve been working with SQL Server since 1996 or so and I’ve never seen anything quite like this before. It truly is an SQL “Oolie”.
Thanks for listening folks.
© Copyright by Jeff Moden - 07 July 2019 - All Rights Reserved
