

tl;dr
The title says it all.
Prologue
One of the keys to my personal learning is that, very early in my database career, I taught myself how to make lot’s of rows of Random Constrained Data in a comparatively short time. With the help of a few good folks over time, the method has been tweaked and improved for performance.
It used to be sufficient to generate a million rows of test data to prove some point, especially where performance in code is concerned. With today’s machines, though, it’s gotten to the point were 100 million rows almost seems inadequate.
One of the tricks I also learned has to do with “Minimal Logging”. The test tables are fairly large and building a HEAP and then adding a Clustered Index basically doubles the size of the required test database. Since I include such test data generation code in my articles and presentations, I have to worry about what my code does to other people’s machines. They might not have the space for such a wasteful doubling of the size of the test database. Building a new table with a Clustered Index and then populating the table with test data in a “Minimally Logged” fashion has been a savior there and has also reduced the amount of time it takes to build test tables in a repeatable fashion.
I was reworking on an old presentation to use a 100 million row test table, whose ultimate size was more than 52GB. I typically use some version of the fnTally function (one is included in the attached ZIP file) as a high-performance “Pseudo-Cursor” to build the rows and this time was no exception.
I got all done with everything but SQL Server 2022 had just come out a couple of months prior and so I decided to test the new, long overdue, GENERATE_SERIES() function. I was (and still am) amazed at the speed at which it performs and so I tried it in the code that generates the 100 million row test table in a “Minimally Logged” fashion
Lordy! If you do a lot of such test table creation and it needs to be “Minimally Logged”, stay away from the GENERATE_SERIES() function!!!
This article provides an example of what can happen to you and your machine if you don’t.
An Overview of “Minimal Logging”
There are a ton of references about “Minimal Logging” in the official Microsoft documentation.
- https://learn.microsoft.com/en-US/sql/relational-databases/logs/the-transaction-log-sql-server#MinimallyLogged
- https://learn.microsoft.com/en-US/sql/t-sql/statements/insert-transact-sql#using-insert-intoselect-to-bulk-import-data-with-minimal-logging-and-parallelism
- https://learn.microsoft.com/en-us/sql/relational-databases/import-export/prerequisites-for-minimal-logging-in-bulk-import
And, there’s a raft of documents for versions prior to 2016 that speak of Trace Flag 610 and a bunch of other things. Those things haven't been necessary since 2016 but you'll still run across them.
Basically, the words “Minimal Logging” describe themselves. For INSERT/SELECT, writes to the transaction log in SQL Server can be seriously reduced and performance can be seriously improved, as well.
For creating test tables using INSERT/SELECT, like the code contained in this article, there are some simple rules that need to followed to achieve "Minimal Logging". Since you’ll normally want a Clustered Index on your test table, we’ll limit the rules to just creating and populating a "Clustered Table" (a table with a Clustered Index as opposed to a HEAP, which has no Clustered Index).
- The database must be in either the BULK_LOGGED or SIMPLE Recovery Model.
- The rowstore table exists, is empty (new) or freshly TRUNCATEd (DELETE won’t do it), and has only a Clustered Index. No Non-Clustered Indexes may be present.
- The INSERT INTO must have the WITH (TABLOCK) hint.
- The data being inserted into the table must be in the same order expected by the Clustered Index keys. ALWAYS include an ORDER BY to do so. It the optimizer makes the determination that an ORDER BY is not necessary for “Minimal Logging”, it will automatically be excluded from the Execution Plan.
- This next hint is totally undocumented. I found out about it the hard way. If the code that is populating the table has ANY @variables in it, you MUST include an OPTION (RECOMPILE) or you probably won’t get minimal logging. Like the ORDER BY, I just automatically include it whether the code contains variables or not just so I don’t have to remember to look.
These rules also apply to code you may have in production if “Minimal Logging” is important there. Don’t forget that TempDB is always in the SIMPLE Recovery Model. If you need to make a Temp Table with a Clustered Index, these rules will help performance a lot while saving some serious resources in TempDB.
What’s in the ZIP file
There are two files in the "MinLogTest.zip" ZIP file attached to this article in the Resources section near the end of this article…
0100 - Create the MinLogTest database.sql
This file contains the code to drop and recreate the MinLogTest database. You'll need to check and, probably, change the directory paths for the MDF and LDF file to work in your environment. Once that's done, it should be executed prior to each of the two tests we’ll run. It also auto-magically builds a copy of one of the many renditions for the dbo.fnTally function into the new MinLogTest database.
Please see the warning at the top of the code that tells you that you need to change the path for both the MDF and LDF files before running the code.
0200 - Run the test for Minimal Logging.sql
The code in this file will be executed to run both “Minimal Logging” tests but as separate runs. For the “Minimally Logged” fnTally test, just run the code as is. For the GENERATE_SERIES() test, look for “TODO” in the code. Uncomment the FROM clause for GENERATE_SERIES() and comment out the FROM clause for the fnTally function. Run script 0100 from above and then run the now modified script 0200.
The output of each run displays both the Start and End MDF and LDF file sizes. The normal run time duration indicator in SSMS will be your “stop watch”.
Here’s the snippet of code that does the table population. This is where (look for "TODO" in the file code) you need to make the changes for the FROM clause for the second test. This is just proof to you that nothing else in the code changed.
--===== Variables to control dates and number of rows in the test table.
DECLARE @StartDT DATETIME = '2010'
,@EndDT DATETIME = '2020'
,@Rows INT = 100000000;
DECLARE @Days INT = DATEDIFF(dd,@StartDT,@EndDT)
;
--===== Populate the test table using "Minimal Logging".
INSERT INTO dbo.BigTable WITH (TABLOCK) -- TABLOCK required for minimal loggimg
(ProductID, Amount, Quantity, TransDT)
SELECT ProductID = CHAR(ABS(CHECKSUM(NEWID())%2)+65)
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
+ CHAR(ABS(CHECKSUM(NEWID())%2)+65)
,Amount = RAND(CHECKSUM(NEWID()))*100
,Quantity = ABS(CHECKSUM(NEWID())%50)+1
,TransDT = RAND(CHECKSUM(NEWID()))*@Days+@StartDT
--FROM GENERATE_SERIES(1,@Rows) --TODO uncomment one or the other FROM clause for different test.
FROM dbo.fnTally(1,@Rows) --TODO uncomment one or the other FROM clause for different test.
ORDER BY TransDT,ProductID -- Inserts must be in same order as Clustered Index.
OPTION (RECOMPILE) -- Undocumented but essential for minimal logging when variables are used.
;Also notice in the code that all the “simple rules” for “Minimal Logging” have been followed.
Test Instruction Summary:
- After making changes to the file paths for the MDF and LDF files, run the modified Script 0100 - Create the MinLogTest database.sql.
- Run Script 0200 - Run the test for Minimal Logging.sql as is. At the end of the run, note the start and end MDF and LDF file sizes and also note the duration usually located in the lower right hand corner of SSMS.
- Rerun Script 0100 - Create the MinLogTest database.sql to reset for the next test.
- Make the modifications to the FROM clauses in script 0200 - Run the test for Minimal Logging.sql as noted in the previous section and run the script. At the end of the run, note the start and end MDF and LDF file sizes and also note the duration usually located in the lower right hand corner of SSMS. Note that this run is going to take a whole lot longer than the previous run, so be patient.
- Manually delete the MinLogTest database when you've completed testing.
The Results:
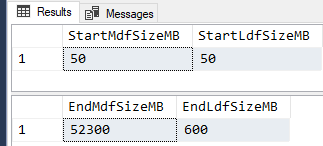
For both tests, the starting size of both the MDF and LDF files is 50 MB each. Here are the results of the fnTally (first run) test and the duration was 00:02:53. Look how tiny the ending LDF file size is! Only 600MB!
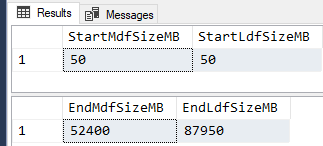
Here are the results from GENERATE_SERIES() (second run after code mods). The LDF file grew to a whopping 87.950 GB! That’s almost 68% larger than the MDF file AND it took 00:14:35 to run. That’s more than 4 times longer that when “Minimal Logging” came into play in the previous test.
Note that your times will likely vary simply because your machine is likely different than the laptop I ran the code on.
Regardless, this test proves that the new GENERATE_SERIES() function cancels out attempts to achieve "Minimal Logging".
Epilogue
Way back in 2008, Erland Sommarskog added a “Connect” item requesting the functionality that the new GENERATE_SERIES() function in SQL Server 2022 provides. It took an incredibly long time to become a reality but, as of 2022, it’s finally here! And, as I and others have observed in separate testing of the function, it’s a marvel of performance and it’s easy to use.
As we’ve just proven, though, it has a serious limitation for people that build a lot of test data… It totally negates even a perfect “Minimal Logging” setup. So, don’t throw away your fnTally function or Itzik Ben-Gan’s GetNums function just yet. If yours is based on a Recursive CTE or While Loop, then, yes… it’s time to get rid of it. ??
Speaking of testing, give your QA and UAT folks a virtual hug. Their job is to try to break your code and they’re pretty good at it. They’ve saved my keister more than once and I’ve learned how to write better code by working with them instead of taking their findings personal. My hat is off to anyone that tests code for a living! Please DO keep saving our butts!
Thanks for listening, folks.
--Jeff Moden
© Copyright - Jeff Moden, 18 August 2023, All Rights Reserved