

Problem
A few weeks back, I got a chance to work on a legacy application for one of my old clients. They had this desktop application setup that used SQL views to display the data and aggregations while Stored Procedures were used to directly interact with the databases. The application had a module that focused on Time Keeping for all the users. Each user was also assigned to a Team. The logged hours were recorded in a separate table WorkLog. The database that I was working on was designed long ago and also was poorly designed.
As you can see in the diagram below (Fig 1), one user can be assigned to one or more than one team. Also, one team can contain one or more than one user. Having said that, it means that in the Users table there can be duplicate entries for UserKey and Name for each Team they are assigned to. The WorkLog table, on the other hand, has a one-to-many (or none) relation with the Users table that uses the UserKey to relate to it. This means there might be records in the Users table that have no related records in the WorkLog table. But, for every record in the WorkLog table, there must be one record in the Users table.
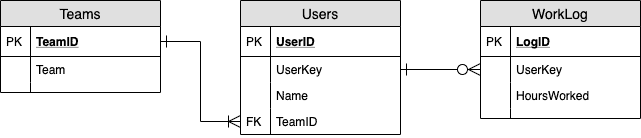
In this example, I'll replicate the original relational table structure, but with dummy values. There are three tables:
- Users - Used to store all users' information along with the team to which they are assigned (Fig 2.1).
- Teams - Used to store the Teams' names (Fig 2.1).
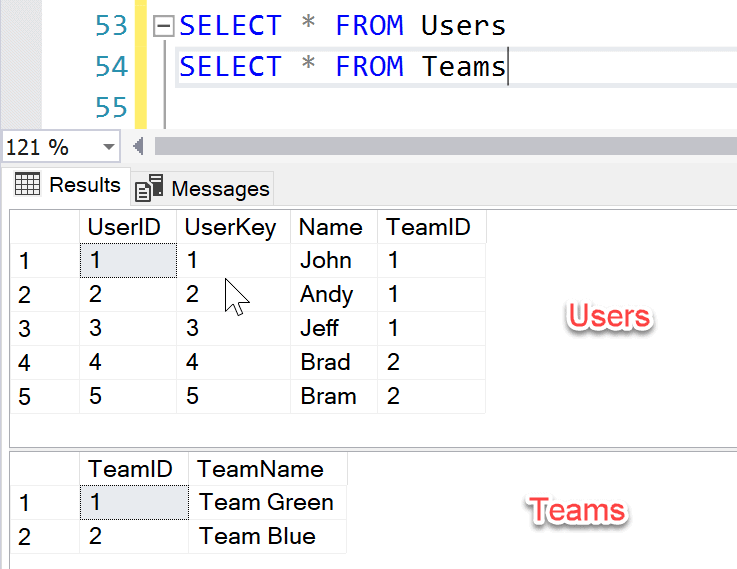
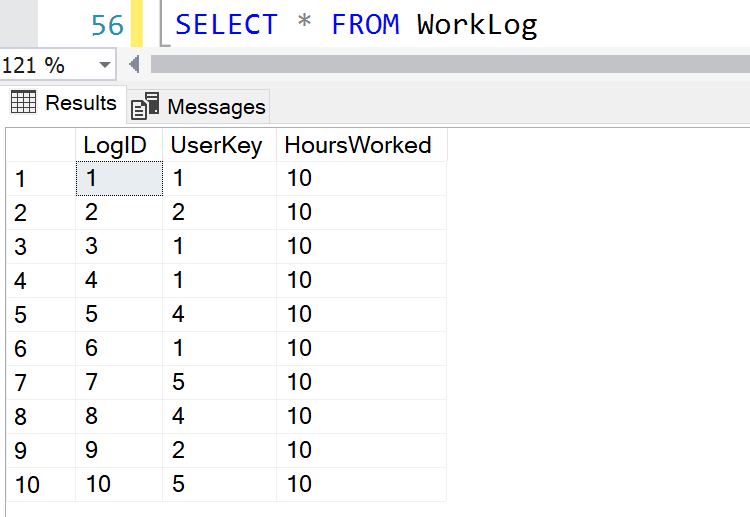
- WorkLog - Used to log hours by each user (Fig 2.2).
You can replicate this use case by executing the script below.
CREATE TABLE Teams (
TeamID INT NOT NULL IDENTITY
,TeamName VARCHAR(50) NOT NULL
,CONSTRAINT PK_Teams PRIMARY KEY (TeamID)
)
GO
CREATE TABLE Users (
UserID INT NOT NULL IDENTITY
,UserKey INT NOT NULL
,NameVARCHAR(50) NOT NULL
,TeamID INT NOT NULL
,CONSTRAINT PK_Users PRIMARY KEY (UserID)
,CONSTRAINT FK_Users_Teams FOREIGN KEY (TeamID) REFERENCES Teams(TeamID)
)
GO
CREATE TABLE WorkLog(
LogID INT NOT NULL IDENTITY
,UserKey INT NOT NULL
,HoursWorked INT NOT NULL
,CONSTRAINT PK_WorkLog PRIMARY KEY (LogID)
)
GO
INSERT INTO Teams(TeamName) VALUES
('Team Green'),
('Team Blue')
GO
INSERT INTO Users (UserKey,Name,TeamID) VALUES
(1,'John',1),
(2,'Andy',1),
(3,'Jeff',1),
(4,'Brad',2),
(5,'Bram',2)
GO
INSERT INTO WorkLog (UserKey,HoursWorked) VALUES
(1,10),
(2,10),
(1,10),
(1,10),
(4,10),
(1,10),
(5,10),
(4,10),
(2,10),
(5,10)
GO
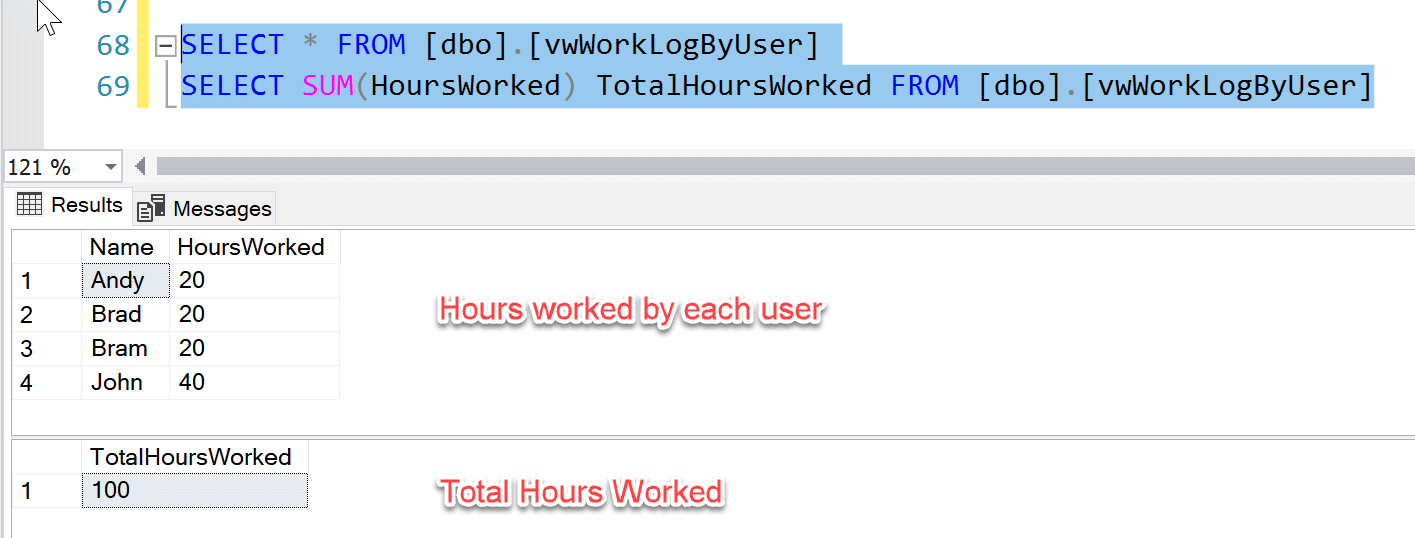
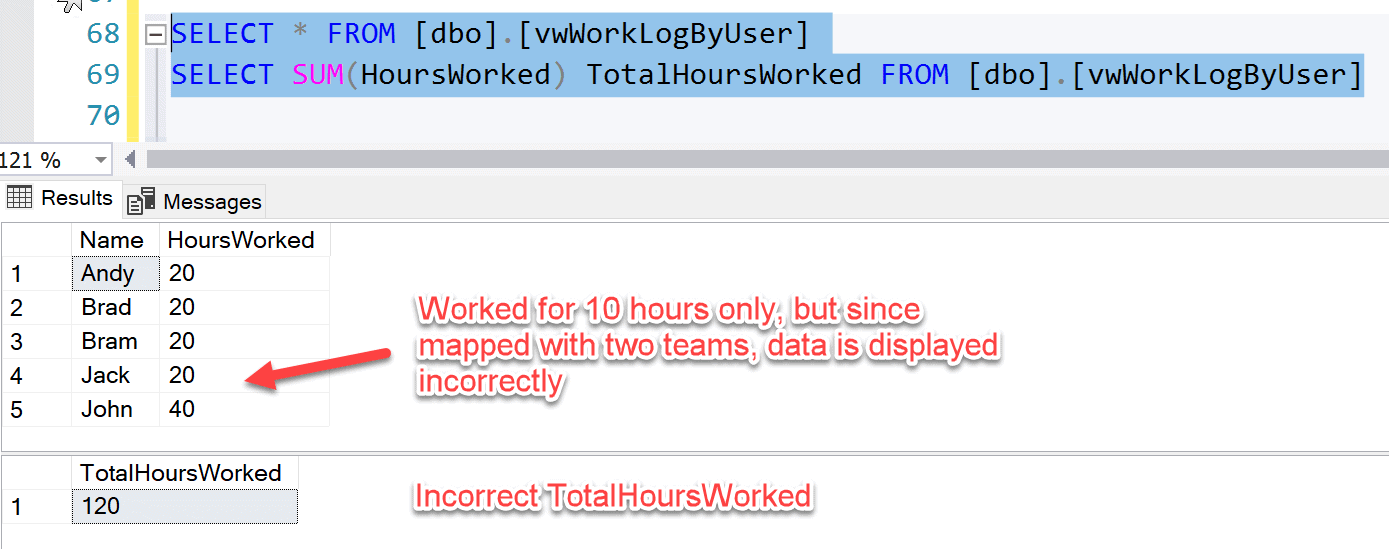
The view used by the application is vwWorkLogByUser. There is also TotalHoursWorked = 100, which is an overall calculation of hours logged by all the users (Fig 3).
The View Definition is found below (Fig 4):
CREATE VIEW [dbo].[vwWorkLogByUser] AS SELECT us.Name ,SUM(wl.HoursWorked) HoursWorked FROM Users us INNER JOIN WorkLog wl ON wl.UserKey = us.UserKey GROUP BY us.Name GO
So far so good. The system worked as expected, and there were no data issues with this setup. However, a new requirement to be able to assign a single user to multiple teams was added. In other words, it was necessary to onboard a shared resource, who will be working for both the teams.
Guarding the existing architecture, we had to add this new user in the Users table but with 2 teams (since he was allocated to both the teams). For example, the user "Jack" is added two times with two different TeamID s (Fig 5).
INSERT INTO Users (UserKey,Name,TeamID) VALUES (6,'Jack',1), (6,'Jack',2) GO
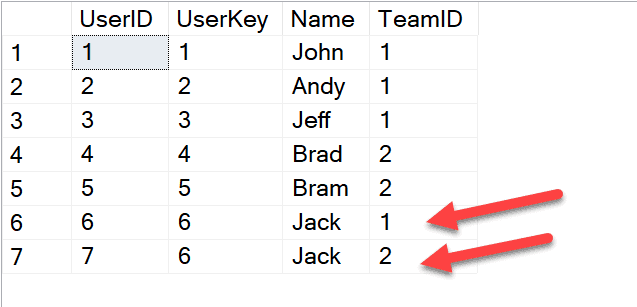
Jack has worked for 10 hours, and his logs are also recorded in the WorkLog table as expected (Fig 6).
INSERT INTO WorkLog (UserKey,HoursWorked) VALUES (6,10) GO

However, when the view is called to display the work log for each user, there is a data glitch. The logged hours for Jack turns out to be 20 hours, and that is not correct (Fig 7). The reason for this is due to the fact that there are two records in the Users table for Jack, and the work log is calculated for both the records.
In addition to this, the TotalHoursWorked = 120 calculations also started displaying incorrect figures for the same reason (Fig 7).
Solution
As already mentioned earlier, the application was quite an old one and we did not have much control in altering the database architecture, so we opted for this solution.
Instead of modifying the existing code, we just added a separate view vwWorkLogByUserAdjusted that will subtract the excess hours that is being displayed in the original view. These new adjusted values are being added to the original data using a UNION, such that the aggregated count returns the exact match. The steps are detailed below and also in Fig 8.
- Fetch all those users who are assigned to more than 1 team.
- A = Get the count of the teams they are assigned to.
- B = Subtract 1 from A.
- C = Fetch the actual hour worked by the user
- AdjustedHours = -( B * C)

The script for this adjusted view is provided below.
CREATE VIEW [dbo].[vwWorkLogByUserAdjusted] AS SELECT us.Name ,SUM(wl.HoursWorked) HoursWorked FROM Users us INNER JOIN WorkLog wl ON wl.UserKey = us.UserKey GROUP BY us.Name UNION SELECT us.Name ,-(AdjustedUsers.UserCount - 1) * (SUM(wl.HoursWorked)/AdjustedUsers.UserCount) HoursWorked FROM Users us INNER JOIN WorkLog wl ON wl.UserKey = us.UserKey CROSS APPLY ( SELECT UserKey ,COUNT(UserKey) UserCount FROM Users WHERE Users.UserKey = us.UserKey GROUP BY UserKey HAVING COUNT(UserID)>1 ) AdjustedUsers GROUP BY us.Name,AdjustedUsers.UserCount
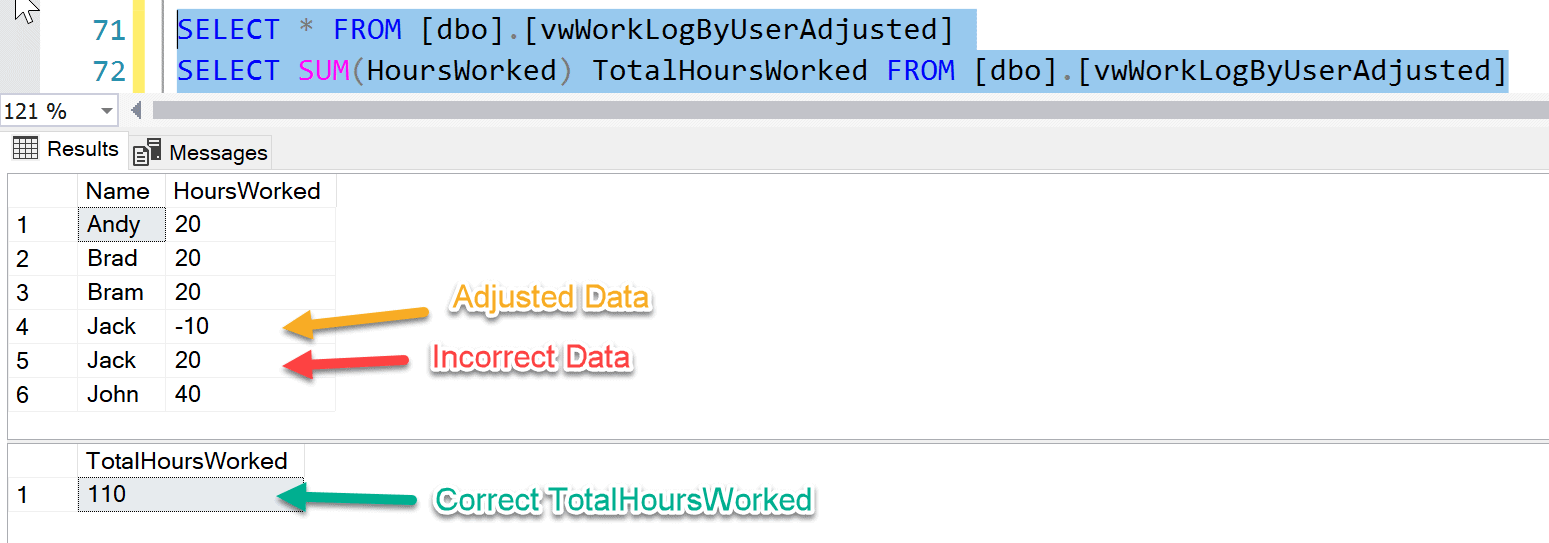
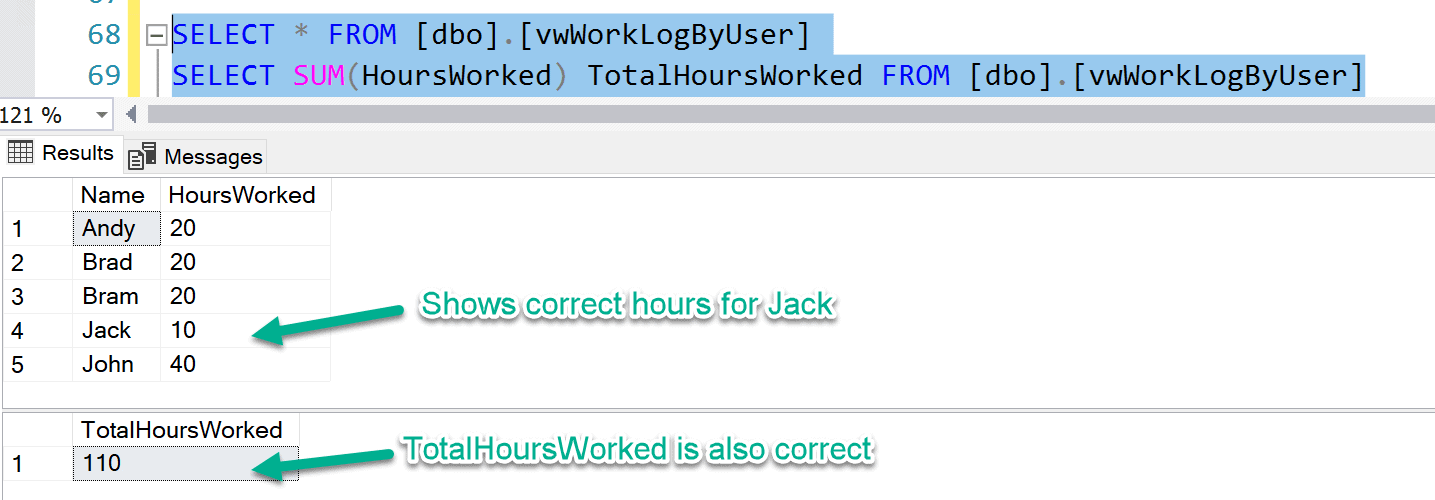
Now, when we query this new view, the result set returns an extra row for "Jack", but notice that the value for HoursWorked is "-10". Also, the value for TotalHoursWorked is also "110" which is correct (Fig 9).
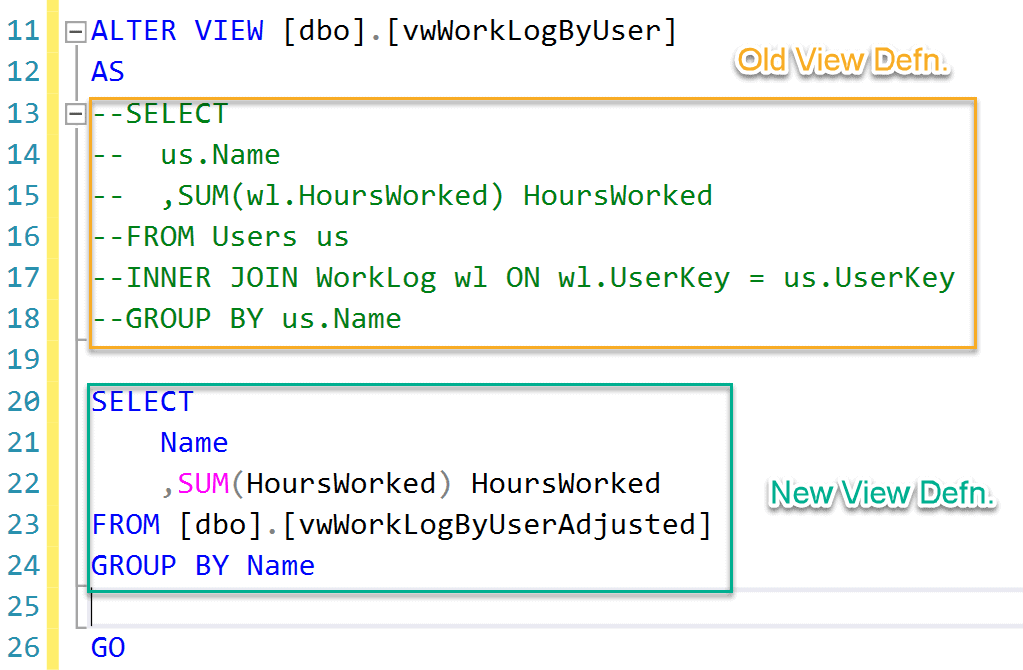
Now, we turned up to the original view and just modified the definition to fetch data from the adjusted view instead of the original underlying tables. The original code is commented and the new code refers to the adjusted view (Fig 10).
ALTER VIEW [dbo].[vwWorkLogByUser] AS --SELECT --us.Name --,SUM(wl.HoursWorked) HoursWorked --FROM Users us --INNER JOIN WorkLog wl ON wl.UserKey = us.UserKey --GROUP BY us.Name SELECT Name ,SUM(HoursWorked) HoursWorked FROM [dbo].[vwWorkLogByUserAdjusted] GROUP BY Name GO
The results from the original view is now correct as below (Fig 11).
Takeaway
This article describes one way to handle aggregated calculations in a dataset when poor database design causes inaccurate results. This technique could also be used for many-to-many relationships. While denormalizing data, it is extremely important that the aggregated measures are correctly built-up such that there is no inflation of the measured values.
- Read more about how to denormalize data with a many-to-many relationship
- Learn about Aggregate Functions in SQL
I think there are several other ways to tackle this scenario, and this might not be the most optimized one. However, I'd like to hear more from the community about the possible advantages/drawbacks of this implementation and open for other suggestions as well.