

Introduction
High availability simply means that the service you are delivering to your customers is “up” most of the time. Availability is measured as a percentage of uptime versus downtime. Most attempts at achieving high availability from an infrastructure perspective is done by introducing redundancy, component redundancy. This means having multiple “copies” of the components that are put together to realize the service.
High Availability for Legacy Architecture Patterns
In the typical layered architecture pattern, this would mean two or more web servers behind a load balancer, two or more application servers, and a clustered database. The exact methods used to realize high availability at the various layers depend on what technologies one is dealing with. In addition, depending on the desired level of availability, organizations spend varying amounts of money to hit the mark since each additional component means additional costs.
Simple three-tier applications would have web servers at the presentation layer, made highly available by implementing load balancing. Application servers running .NET packaged as Windows services could achieve high availability with Windows Failover Clustering. For Oracle databases, a Real Application Cluster (RAC) would have to be implemented to achieve redundancy at the data layer. So, the main idea in all three cases is to have multiple components and a way in which the backup can be brought online (preferably automatically) when the primary fails.
In each on-premises data centre, these redundant components are deployed on separate racks which are supported by independent sources of power. The idea of redundancy is further extended in on-premises scenarios by building more than one data centre, which are copies of each other. Using data replication technologies, data, and configurations are synced across these data centres.
High Availability for Modern Architecture Patterns
The emergence of containerization, orchestration, microservices, and other modern constructs contributed to greater sophistication in the evolution of high availability approaches. Distributed databases at the data layer have also added to this mix. It is no longer a case of having two servers at each layer. The idea is now ensuring that services are not monolithic, and that “failovers” are always automatic. In the world of containers and microservices, a “failover” doesn’t mean starting a service on another server, it means creating a new “server”. This "server" is called a container and it runs a service that does only one thing (typically) – a microservice. So, while the points of failure have been increased by orders of magnitude in this containerization pattern, the possibility of complete service outage is remote.
High Availability in the Public Cloud
Most mature cloud service providers have thought through high availability and disaster recovery extensively. These concepts are foundational to the whole concept of cloud computing. And they are a significant attraction for organizations looking to adopt cloud computing. The key concepts that pop up in the public cloud related to high availability and disaster recovery are summarized for three key cloud service providers in the following table:
| S/No. | Concept | Amazon Web Services | Microsoft Azure | Oracle Cloud |
| 1. | Rack | N/A | N/A | Fault Domain |
| 2. | Data Centre(s) | Availability Zone | Availability Zone | Availability Domain |
| 3. | Geography | Region | Region | Region |
Obviously, these concepts here border on ensuring that components are duplicated and deployed in separate locations and facilities. This ensures that a component failure at whatever level does not result in complete service outage. Mechanisms such as load balancing and clustering are in place to abstract the individual components from the consumer of these services.
What Are Availability Zones?
Cloud Service Providers organize data centres in specific locations/buildings, which are analogous to data centres in the on-premises world. An availability zone can comprise one or more buildings with independent power, cooling, etc. Within such a building or set of buildings, the physical infrastructure required to deliver cloud services are hosted. The availability zones are designed in such a way that clients can provision resources in the availability zones as replicas.
Availability Zones (AZs) are designed to be isolated from each other so that a failure at one AZ does not affect any other. High bandwidth, low latency links between AZs provide the backbone on which replication is dependent. This configuration ensures that failovers are fast and do not lead to loss of data. Oracle Cloud Infrastructure refers to Availability Zones as Availability Domains and further divides them to Fault Domains. Fault domains are analogous to data centre racks in an on-premises data centre.
What Are Regions?
In cloud computing, regions are geographical locations where public cloud service providers have deployed infrastructure. Most CSPs make the geographical locations of their regions public. This helps organizations decide which locations is most appropriate for them to deploy services in view of latency concerns as well as data residency requirements. In cloud computing, regions are typically used to achieve disaster recovery in the cloud by deploying a complete copy of services deployed in one region in an alternate region. If there is ever a complete outage in one CSP region, an organization can involve DR and bring services online in the standby region. Availability zones are sufficient for the availability needs of most organizations since complete region failures are rare.
| S/No | Cloud Service Provider | Landscape |
| 1. | Amazon Web Services | AWS Regions |
| 2. | Oracle Cloud Infrastructure | Oracle Cloud Regions |
| 3. | Microsoft Azure | Azure Regions |
| 4. | Overview | Overview from Atomia |
{kind=link}
Microsoft extends the concept of regions as a disaster recovery mechanism by implementing a concept referred to as Regional Pairs by default. The idea is that if an organization wishes to implement disaster recovery using regions, Microsoft identifies a specific region as a partner to the originally selected primary region. This will likely ensure that the capabilities selected by the organization in the primary region are also available in the standby region.
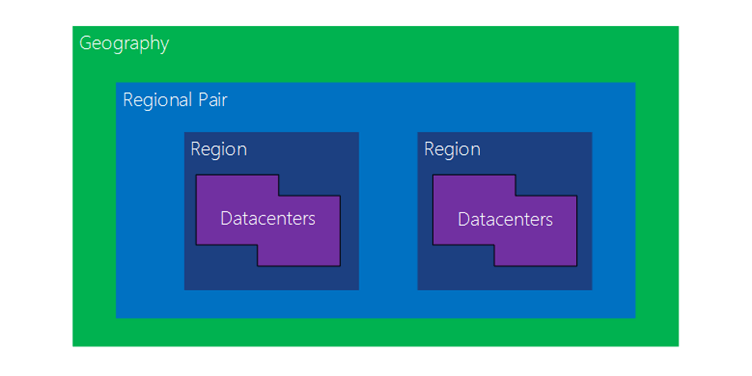
Figure 1: Regional Pairs in Microsoft Azure (Source: Microsoft)
Leveraging High Availability Offerings in the Public Cloud
Figure 2 shows a simple way to achieve high availability in the public cloud for a legacy application with a three-tier layered architecture. Migrating such a configuration from on-premises to cloud can be thought of as a lift and shift approach to cloud computing. First of all, the virtual machines used as web and application servers are implemented in the cloud as instances (Infrastructure as a Service) and deployed in their respective network zones. Second, the presentation layer which exposes the service to the internet is in a separate subnet from the business logic layer and both layers sit on either side of a firewall. The data layer also sits in its own subnet. Network segmentation can be achieved in the public cloud using virtual firewalls (typically referred to as Security Groups or Security Lists), Network ACLs or even as entirely separate Virtual Private Clouds.
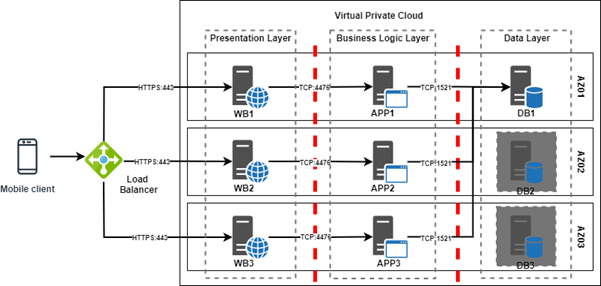
Figure 2: Simple Three-Tiered Application in the Cloud
Virtual Private Cloud
A Virtual Private Cloud is a virtual data centre belonging to a single entity. It is virtual because while all assets in the “data centre” belong to a single organization typically, the actual physical locations of the assets are abstracted. For example, as mentioned earlier, the Availability Zones 01 to 03 in Figure 2 are actually in different physical locations but can be managed from a single web-based interface made available by the cloud service provider.
A typical transaction from a client such as a mobile app would hit the load balancer (through a URL). This traffic would then be distributed across the three web servers depending on the load balancing configuration. Each web server talks to an application server which in turn talks to the database. In the case of the data layer, it is likely that only one instance will be open at any point in time. Relational databases are designed to have only one instance is in read-write mode at a time. However, CSPs provide mechanisms for automatic failover under the hood.
Failure Scenarios
We shall now explored the failure scenarios associated with the diagram shown in Figure 2. If Availability Group 01 fails, WB1 would be unavailable but this will be transparent to the client since WB2 and WB3 will continue passing traffic. APP2 and APP3 will still be operational, and a failover will occur in the data layer thus one of the other database instances taking over the primary role. Failures in any of the other two availability zones would also result in similar events transparent to the client.
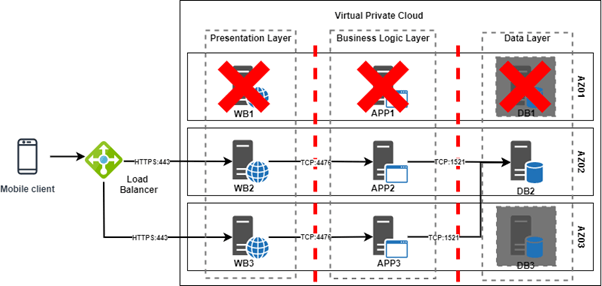
Figure 3: Failure Scenario for a Simple Three-Tier Application
Conclusion
The dominant cloud service providers already have established and very reliable architectures for achieving high availability. Organizations that embark on cloud migration programmes have the responsibility of understanding these technologies and developing/migrating their services in a way that they are highly available in the cloud. This article describes the implementation of high availability in the cloud for a three-tier application. In more sophisticate scenarios, applications will need to be refactored to take advantage of modern architecture patterns such as microservices. When building new applications, it makes sense to build them as cloud native solutions that are designed with high availability in mind.