

Introduction
Amazon Relational Database Service (RDS) allows us quickly deploy databases without worrying about underlying infrastructure. These pleasant words that have thrilled the business world and trickled through the industry. AWS, Azure, OCI and other cloud service providers all have these DBaaS offerings. Economies of scale implies that adopting cloud should be inexpensive. In practice, however, we find that this is not always the case for existing, non-cloud-native, large enterprises. One must take into account quite a few aspects before deploying/migrating a database in the cloud. This article explores some of those considerations. We also demonstrate how decisions can be made while deploying a single SQL Server Database using Amazon RDS.
10 Considerations for RDS
In the context of this article and based on both research and our experience, here are a few elements one must consider when deploying databases in the cloud:
- Overall Cost
- Data Residency
- Data Size
- Backup and Recovery
- Data Retention
- Data Life Cycle
- Data Analytics
- Data Access
- Data Security
- Data Privacy
Let’s break these down one after the other.
Total Cost of Ownership
The low cost of cloud services and the OPEX model were key selling points when Amazon Web Services (AWS) pioneered the model cloud computing paradigm. This "low cost" was sold to startups mostly. They didn't have to make heavy investments in IT infrastructure on-premises when launching new products. AWS gave many startups the advantage they needed to get started with their business and scale along the way. Most of the startups who leveraged cloud computing in the early days were fintech companies which offered scalable products to the masses such as payment gateways. It was profitable to start small, scale and remain in the cloud - the product paid its own rent. This is slightly different for large enterprises.
In my view, the workload being moved to the cloud should be good enough to pay its own rent. For large enterprises who waste resources on-premises, cloud computing has tendency of exposing the wasteful practices in graphic detail. Suddenly every bit of storage has to be paid for (pun intended!). And as you scale or provision, the money just keeps showing up in your face thanks to Amazon Cost Explorer and other tools made available for visualizing the costs of assets deployed in the cloud. In addition, infrastructure must been sized optimally for the purpose it is being provisioned.
The cost of cloud computing may seem attractive in the short term. Careful planning is necessary to remain in the cloud for the long hall. Paula Rooney in a July 2022 article in CIO.com explores this topic in further detail. The inadequacy of traditional cost-control mechanisms used on-premises, the need to modernize before migrating and the potential hidden costs are all highlighted.
Data Residency
Some regulators are very concerned about where their citizens' data sits. The haziness of definitions in the information technology world makes it easy in some jurisdictions to fool regulators. Is there an efficient way for regulators to determine where data sits and where services are being delivered from? Big question. As an organization, is important to carefully understand the regulator’s requirements and align. This avoids sanctions but one must also take the organization's interests and operating model into account.
For example, some multi-nationals operate a centralized business model meaning they deliver services from a single location to their customers across boundaries. Navigating the regulatory requirements on data residency might mean classifying your data appropriately so you can determine which solutions are allowed to be hosted in country and which are not. You might also want to explore solutions that help you keep a copy of data in-country in cases where the regulator does not mind where the data is so long as they have local access to the copy.
While Africa contributes very little to cloud computing revenue globally, (see this article), many African nations are insisting on keeping their data within reach. This is a dilemma for many advancing organizations jumping on the digital transformation bandwagon. Thought leaders like Jim Marous of the Financial Brand and Michael Tang of Deloitte are all for Cloud Banking but there seems to be little focus on these data residency concerns from African nations.
Data Size
The size of databases you are dealing with will impact the time required to migrate, the migration method as well as the costs you will eventually incur in the cloud in terms of storage. Cloud service providers offer several options for migrating data into RDS. This is the case particularly for companies like Microsoft and Oracle, which are veterans in the data management space.
However, thorough testing of the chosen approach is important to ensure migrations can be done within timelines and without data loss. This article from Stream Sets touches on essential considerations for migration data. Similar articles by Appinventiv and Spiceworks touch on cloud migration best practices in general.
Backup and Recovery
Most cloud service providers have native solutions for backup and recovery. In my view, these solutions were originally designed for the startup in mind – the need to restore data in case of data loss. This pattern shows up in the default retention policies that come with this backup mechanisms. For enterprises however, such as banks, there are other reasons for taking backups asides form the need to recover from failures. One such reason is regulatory reporting at a specific point in time such as the previous day, the previous month, the previous year or even a specific financial position. In such scenarios, the live database does not need to be overwritten and the retention must cater for more than seven days. This demands a different solution.
Another consideration in terms of back is how to manage backup sets in the long term. What happens if the organization decides to discontinue its relationship with the cloud service provider? Those back sets must be preserved in such a manner that they will be useable on the destination platform. The plan on how to migrate older backup sets must be clear.
Data Retention
Data management professionals often must make decisions about how much data to keep online. This is typically determined by the business and regulatory requirements. Keeping data online means the data is immediately available within the application. Keeping it offline means the data is in a backup set outside the system. Sometimes mechanisms for retaining the required data are part of the application design, e.g. the Active-Active solution for ACI’s Postilion. In other cases, application owners have to rely on data engineers to design and build mechanisms for data retention at the data layer.
Depending on its design, an application’s core tables would be responsible for a large chunk of the size thus of concern in terms of data retention. For example, a payment application might have a transaction table as the largest table. Decisions must be made as to how far back the transactions need to be viewed within such an application. Traditionally such retention can be achieved using table partitioning, stretched databases (SQL Server) and so forth. These technical solutions are used to implement decisions defined in retention policies.
Data Life Cycle
The moment decisions are made about what data needs to be retained within the system, the life cycle of data must be determined and how such a cycle is implemented. Data is captured within the application; some is retained online and some retained within back set. For every backup taken – daily, weekly, monthly, yearly – decisions must be made about how long such data needs to be kept. Depending on how long the data needs to be kept, decisions then have to be made about where such long term, cold data might be kept.
Cloud Service Providers typically provide options for what kind of storage is used to store hot, warm and cold data. In AWS, on might have day-old backup sets initially on S3 buckets, have them moved to Glacier for archiving with a configuration that automatically deletes them after the agreed offline retention period. In most Sub-Saharan African banks for example, data must be kept for up to 10 years. This can becoming quite expensive if not kept on archival storage. A cloud programme must include decisions about how the data life cycle will be managed using the desired CSP’s offerings.
Data Analytics
When we hear the phrase “Data is the new gold” we must realize that this often referred to potential value. Actual value typical arises from making sense of the data through analytics. If your organization already has a platform for analytics, you have to decide whether you want to aggregate data from cloud sources to your existing platform or adoption a data platform in the cloud. You must consider your geographic location relative to your CSP’s data centres, the rate of growth of your data, the data capabilities you would want to develop and more.
Your on-prem data warehouse’s geographic location impacts how efficient your ETL or ELT jobs will be. If you are in sub-Saharan Africa, you might be better off using cloud-based data platform for analytics the moment you choose to move databases to the cloud. Latency between your databases and an on-premises data warehouse will have impact on your ETL or ELT jobs. Using cloud-based analytics also affords you the opportunity to quickly adjust to growing data without tedious storage procurement processes.
Data Access
Some organizations still need to give selected staffers direct access to production databases for troubleshooting, support and ad-hoc analytics. When such databases are in-premises the risk of allowing communication to the database is lower. Once the database is in the cloud, one might be tempted to open access to the public in the name of making it easy for staff to do their work from anywhere. Quite dangerous.
It is preferred to use firewall rules to restrict access to only IP Addresses from your corporate network. AWS makes this easy by providing virtual firewalls called Security Groups. These days, CSPs also provide browser-based client tools for people who need to work with databases directly. This may address data access security concerns if the tools are launched from within the cloud service provider's console.
Data Security
Security is a huge subject these days and many innovative organizations are coming up with solutions that are better aligned with cloud computing. One of such solutions is Secure Access Service Edge (SASE), which is the “convergence of wide area networking, or WAN, and network security services like CASB, FWaaS and Zero Trust, into a single, cloud-delivered service model” according to Palo-Alto Networks.
In moving databases to the cloud, we must think about encryption at rest (Transparent Data Encryption (TDE)?) and in transit (Transport Layer Security (TLS)?). We must think about ransomware, password policies, packages and more. MTI College gives an overview of cloud security in this article. Cato Networks also outlines the key elements of SASE in this article.
Data Privacy
Data privacy is receiving more and more focus as part of the data protection triad – Traditional Data Protection, Data Security and Data Privacy. Data Privacy is focused on personal data and confidential data. For the most part the concern from a design decision perspective is to align with relevant regulatory requirements on personal and confidential data. The location of you preferred CSP’s data centres might impact your decision in terms of aligning with data privacy laws. Baker McKenzie's summary of data privacy laws in Africa is a good reference.
Example - Amazon RDS for SQL Server
Cloud Service Providers make it very easy for us to deploy assets in the cloud. So easy in fact that often we do not think carefully about the consequences of our decisions. So far we have examined ten key considerations that must be taken into account when adopting a CSP as the preferred location for your databases. In this section, we shall create a Microsoft SQL Server RDS instance and mention along the way our rationale for making the choices we made.
Ours is a very simple use case for deploying a database on Amazon RDS for the purpose of demonstrating SQL Server concepts - specifically T-SQL. In essence, we want a low-cost, light, efficient database that has all the features necessary for writing T-SQL and nothing more. We do not need to manage the underlying infrastructure for this database and we are not storing any sensitive data. There is also no need to preserve data from this data in backup sets. We shall walk through the simple steps for launching this RDS instance and the options we choose based on this background.
Getting Started
We start by establishing a connection to Amazon Web Services using our root account or IAM user. To open the RDS console, we use the search bar shown in Figure. If you have done this before, you will find this entry in the recently visited section. Click RDS to open the RDS console. First we establish a few reasons we are choosing RDS (See Figure 1):
- We want to reduce the overhead associated with managing the database environment
- Our use case is simple, we do not need any sophisticated instance-level configurations
 Figure 1: Login to AWS Console
Figure 1: Login to AWS Console
Create Database
Click the Create Database button. This opens a wizard that guides us through database creation options. Figure 2 hones in on the button showing you have the option of creating this database from a backup.
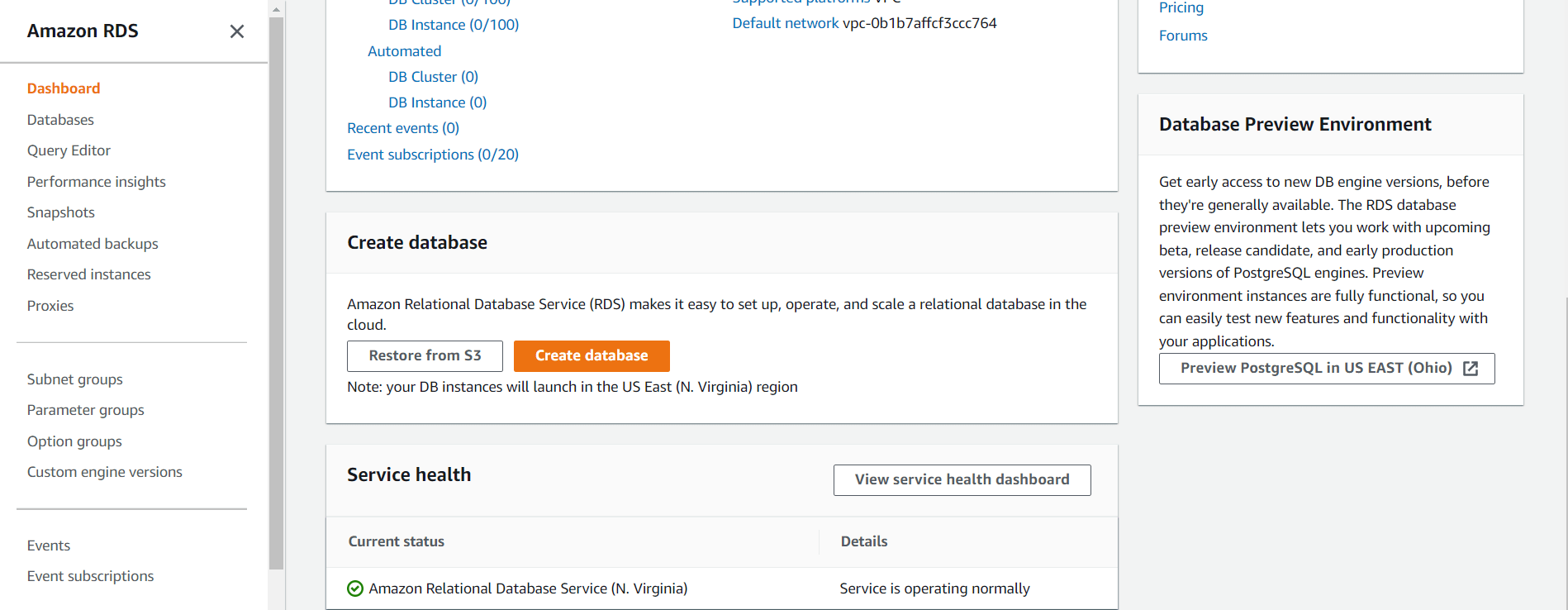 Figure 2: Create Amazon RDS Database
Figure 2: Create Amazon RDS Database
 Figure 3: Create Database (Zoom in)
Figure 3: Create Database (Zoom in)We choose the Standard Create option because we are interested in selecting all the configuration options. The Easy Create option is a good alternative based on our use case but we want to show the steps.
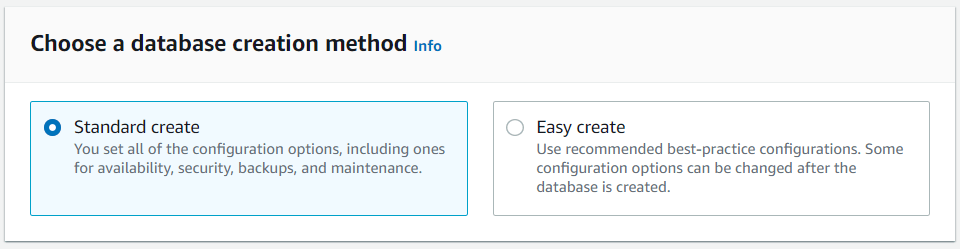 Figure 4: Standard Database Create Option
Figure 4: Standard Database Create OptionEngine Options
We choose the SQL Server engine (Express Edition) again because our use case is simple. There is a serious need to manage costs and we are focused on using this instance for demonstrating basic T-SQL code. We do not want to manage patching and we do not need operating system access though we like very much the latest edition of SQL Server.
 Figure 5: Choosing the SQL Server Engine
Figure 5: Choosing the SQL Server EngineFigure 6 shows our choice of Amazon RDS with no need for customization as well as the choice to use Express Edition. Using express Edition means we cut of license costs since our use case is simply for demonstration of T-SQL. SQL Server Express edition allows us create databases up to 10GB in size which is more than enough for our purposes.
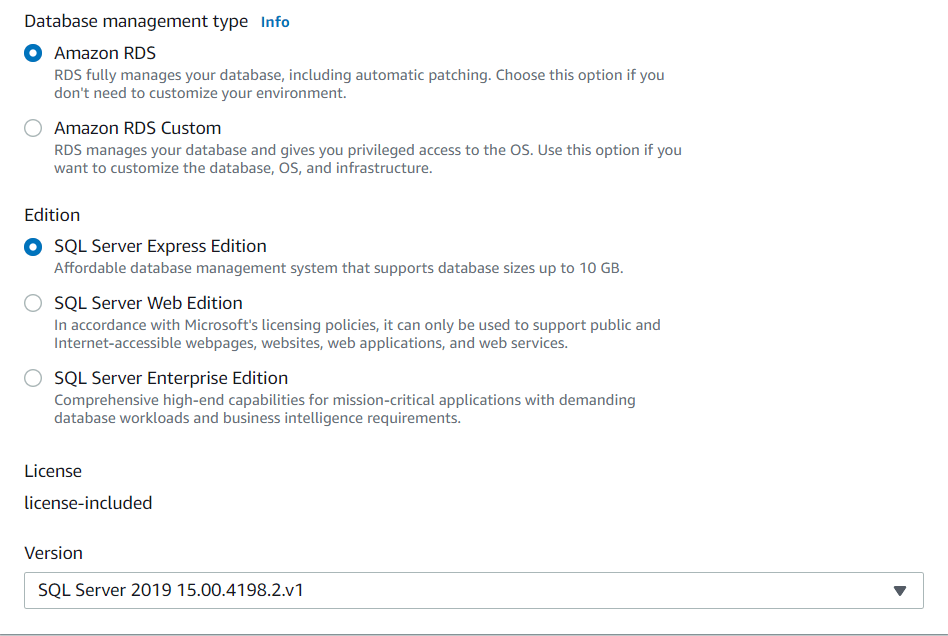 Figure 6: Database Management Type & SQL Server Edition
Figure 6: Database Management Type & SQL Server EditionEngine Options
Our instance are set based on our preferences. Again we choose an instance class that aligns with our consideration of cost and fitness for purpose - our instance class is a T3 Small (See Figure 8). Review AWS documentation to learn more about Amazon RDS instance classes.
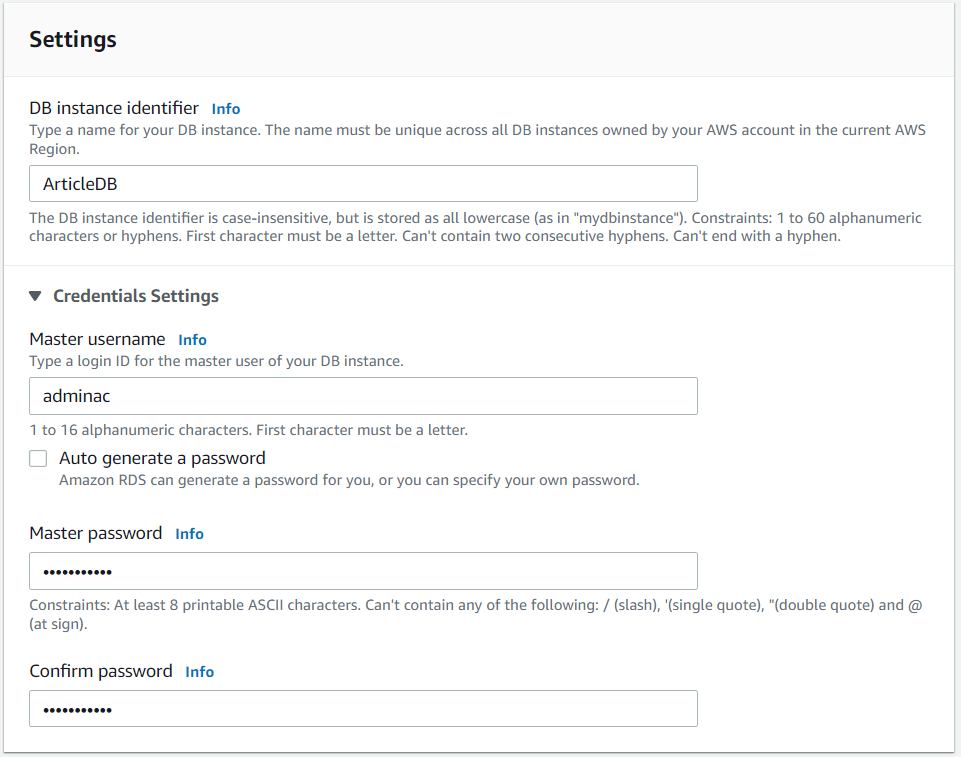 Figure 7: Database Name and Credentials
Figure 7: Database Name and Credentials
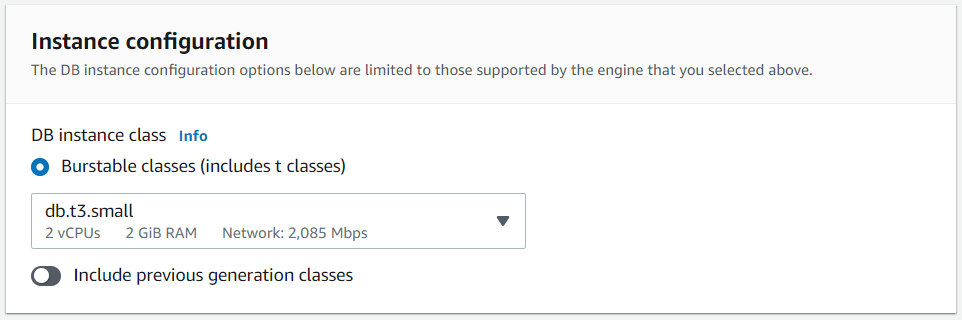 Figure 8: T3 Small Instance Class
Figure 8: T3 Small Instance ClassStorage, Networking & Security
We do not need significant storage for our purpose either so we choose 20GB. There is no need for storage auto-scaling so we should have unchecked that at that time of taking the screenshot of Figure 9.
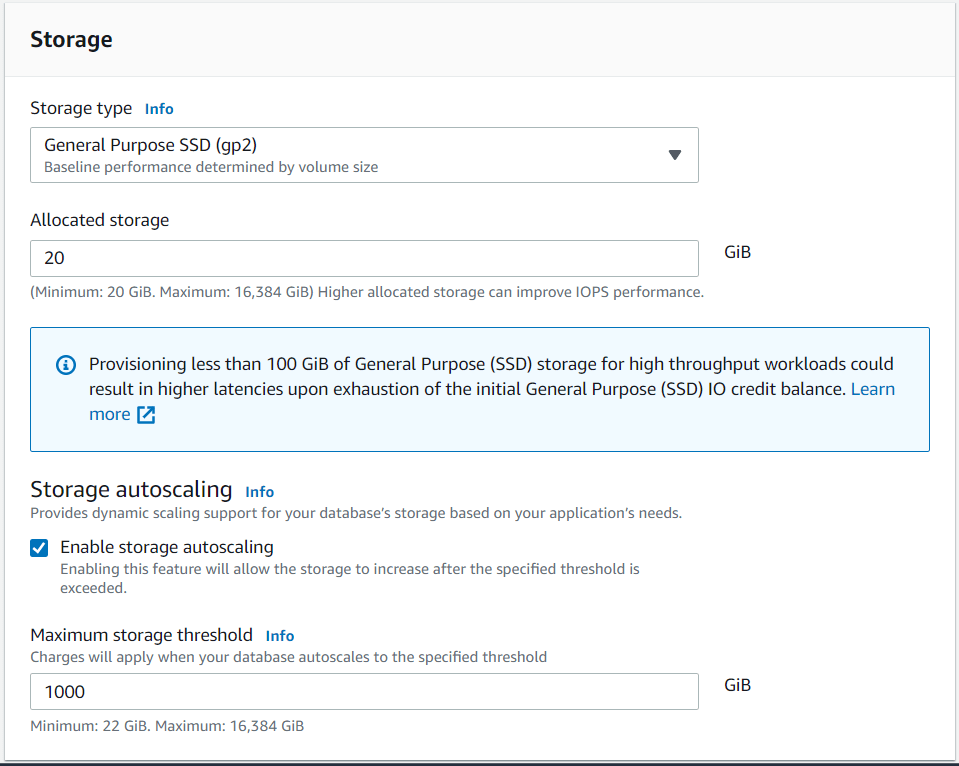 Figure 9: Storage Options
Figure 9: Storage OptionsAWS provides an array of connectivity options including the immediate setup of an EC2 instance which connects to the new database. We want to keep our configuration simple at this time so we choose not to do this. The default VPC is retained for this reason (See Figure 10).
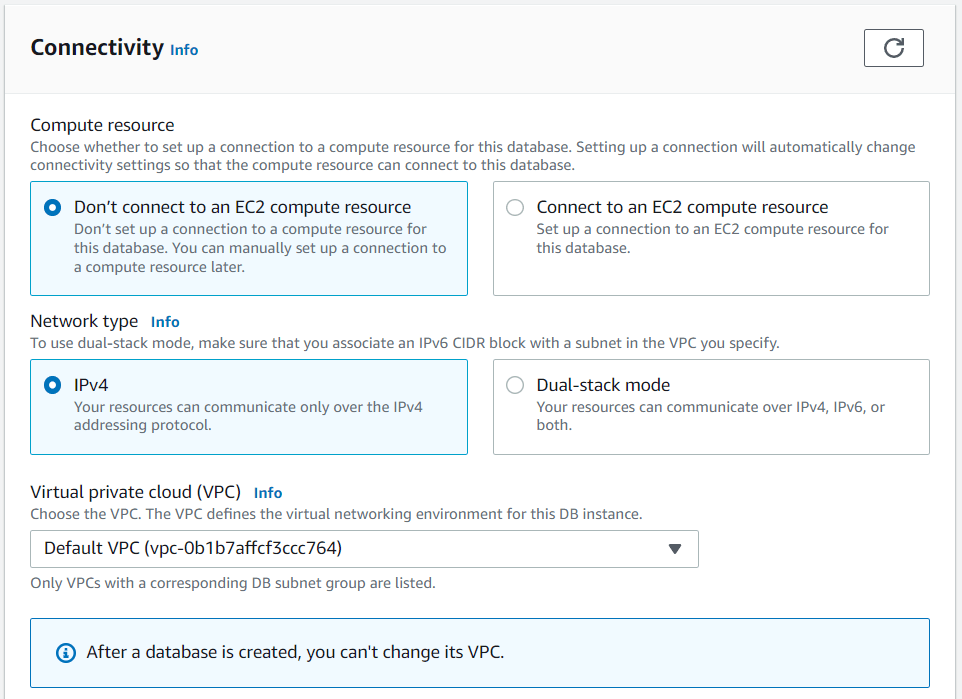 Figure 10: Connectivity Options
Figure 10: Connectivity OptionsIn the next window, we choose to create a new VPC Security group just for fun. In a larger setup, it would be useful to have security groups defined by the kind of workload they are expected to secure. We choose not to select a preferred availability zone again for only simplicity reasons.
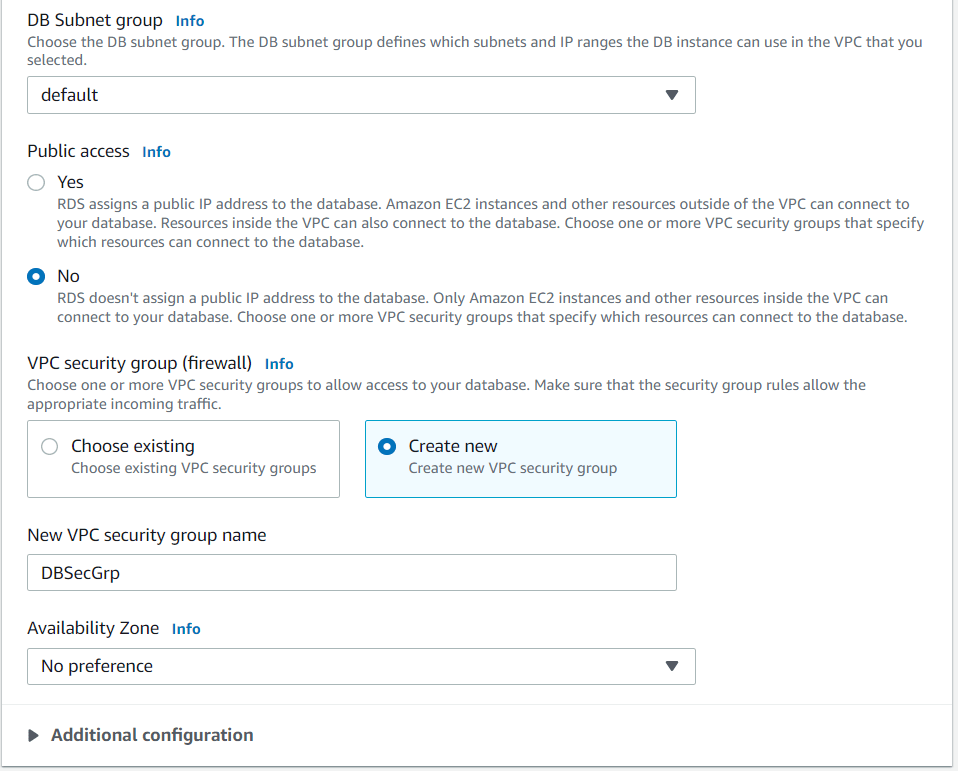 Figure 11: Subnet and Security Groups
Figure 11: Subnet and Security GroupsAs much as we would love to, we exclude the use of Windows Authentication in order to keep things simple.
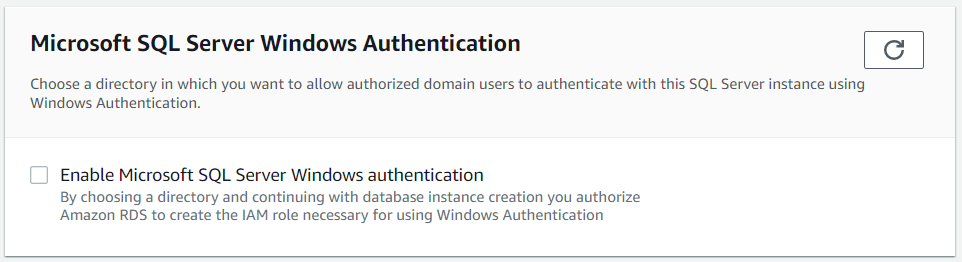 Figure 12: Windows Authentication
Figure 12: Windows AuthenticationMonitoring
Our monitoring option are the default selections.
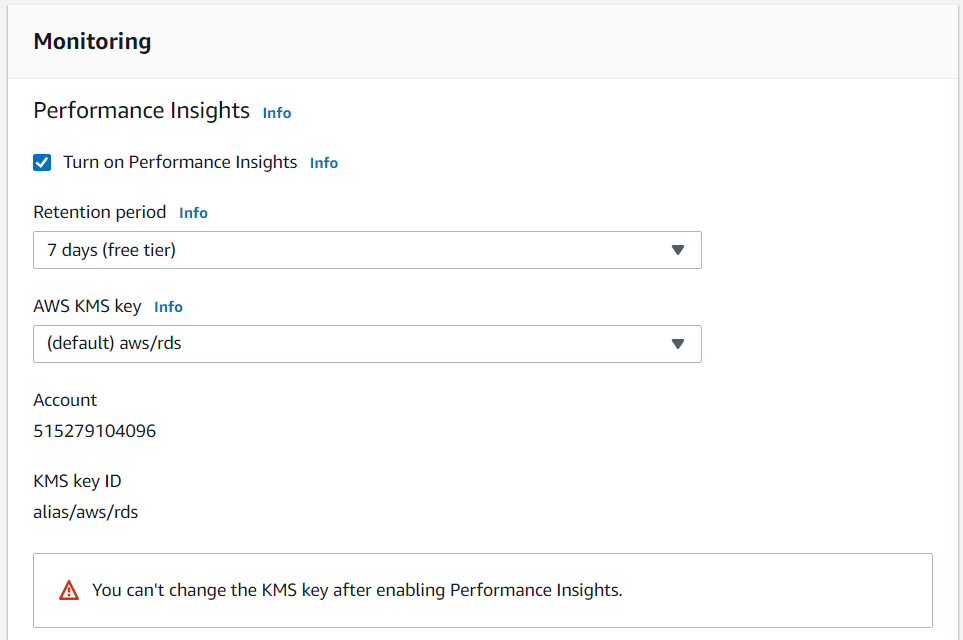 Figure 13: Standard Monitoring
Figure 13: Standard Monitoring
 Figure 14: Enhanced Monitoring
Figure 14: Enhanced MonitoringCost Summary
At the end of the configuration AWS shows me additional configuration options and a summary of estimated monthly costs. In this section, the goal is to ensure this total figure is as low as possible.
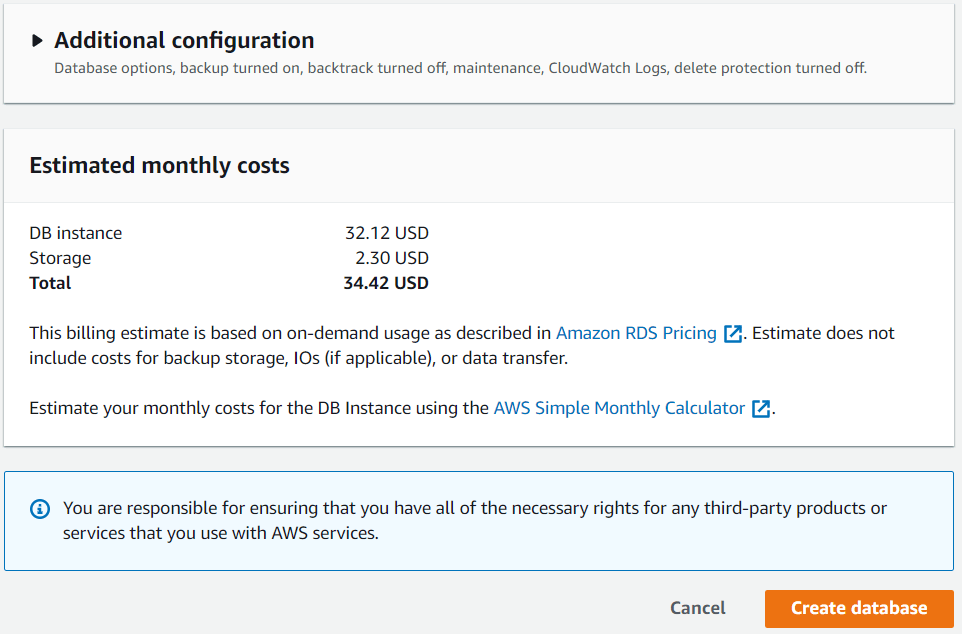 Figure 15: Cost Summary
Figure 15: Cost Summary
Conclusion
In this article, we have looked at the key elements architects and engineers must evaluate when creating or deploying databases in the cloud. We then looked at a simple example of creating a cost-effective SQL Server database using Amazon RDS. Our key concerns in this deployment were low cost, fitness for purpose and simplicity. Taking the principles from this article will be useful in both small scale and enterprise scale adoption of cloud computing in general and database deployment specifically.