

Introduction to SQL Window Functions
In today's data-driven world, SQL (Structured Query Language) stands as a cornerstone for managing and manipulating database systems. A core component of SQL's power and flexibility lies in its window functions, a category of functions that perform calculations across sets of rows related to the current row.
Imagine you're looking at your data through a sliding window, and based on the position and size of this window, you perform calculations or transformations on your data. That's essentially what SQL window functions do. They handle tasks like the computation of running totals, averages, or rankings, which are challenging to perform using standard SQL commands.
One of the most robust tools in the window functions toolbox is the ranking function, specifically the DENSE_RANK() function. This function is a godsend for data analysts, allowing us to rank different rows of data without any gaps. Whether you're diving into sales figures, website traffic data, or even a simple list of student test scores, DENSE_RANK()is indispensable.
In this article, we'll delve into the inner workings of DENSE_RANK(), juxtaposing it with its close siblings RANK() and ROW_NUMBER(), and showcasing how to avoid common pitfalls that might trip you up in your SQL journey. Ready to level up your data analysis skills? Let's dive in.
Understanding the Role of Ranking Functions in SQL
Ranking functions in SQL are a subset of window functions that assign a unique rank to each row within a result set. These rank values correspond to a specific order, determined by the ORDER BY clause within the function. Ranking functions are a mainstay of SQL, used extensively in data analysis for diverse tasks, such as finding the top salesperson, identifying the best-performing web page, or determining the highest-grossing film for a particular year.
There are three principal ranking functions in SQL, namely RANK(), ROW_NUMBER(), and DENSE_RANK(). Each of these functions operates slightly differently, but they all serve the common purpose of ranking data based on specified conditions. RANK() and DENSE_RANK() functions have similar behavior in that they assign the same rank to rows with identical values. The crucial difference lies in how they handle the subsequent rank. RANK() skips the next rank whereas DENSE_RANK() does not.
On the other hand, the ROW_NUMBER() function assigns a unique row number to each row disregarding whether the order by column values are identical. While RANK(), DENSE_RANK(), and ROW_NUMBER() might seem interchangeable at a glance but understanding their nuances is pivotal to effective data analysis in SQL. The choice between these functions can significantly impact your results and the insights derived from your data.
Understanding SQL's ranking functions’ behavior and their tactical application can take your data analysis skills from basic to advanced. With these functions, you can unlock deeper insights and make more informed decisions. In the next segment, we'll dive deeper into the DENSE_RANK() function, expanding our exploration of its syntax and practical usage in SQL.
What is DENSE_RANK() in SQL?
DENSE_RANK() is a potent ranking function in SQL that assigns a unique rank value within a specified partition. In crux, DENSE_RANK() gives non-gap rankings for your data, meaning each unique value is given a distinct rank, and identical values receive the same rank. Unlike its counterpart RANK(), DENSE_RANK() does not skip any ranks if there is a tie between the values.
To break it down, let's visualize a scenario where you have a dataset of student scores, and three students have secured the same score, say, 85 marks. Using RANK(), all three students will receive a rank of 1, but the next best score will be ranked 4, skipping ranks 2 and 3. However, DENSE_RANK() handles this differently. It will assign a rank of 1 to all three students, and the next best score will receive a rank of 2, ensuring there is no gap in the ranking.
CREATE TABLE StudentScores (
ID INT PRIMARY KEY,
StudentName VARCHAR(100) NOT NULL,
Score INT NOT NULL
);
INSERT INTO StudentScores (ID, StudentName, Score) VALUES (1, 'Alice', 85);
INSERT INTO StudentScores (ID, StudentName, Score) VALUES (2, 'Bob', 85);
INSERT INTO StudentScores (ID, StudentName, Score) VALUES (3, 'Charlie', 85);
INSERT INTO StudentScores (ID, StudentName, Score) VALUES (4, 'Diana', 83);
Imagine a scenario where we want to rank the students based on their scores, but do not want any ties in the ranking. The RANK() function assigns a unique rank to each row and skips ranks if there are duplicates.
SELECT
StudentName,
Score,
RANK() OVER (ORDER BY Score DESC) AS Rank
FROM StudentScores;
On the other hand, in the second sample query, we use DENSE_RANK() function which also assigns ranks to rows but does not skip any ranks even if there are ties. This means that if two students have the same score, they will both get the same rank, and then the next student will get a rank lower than theirs.
SELECT
StudentName,
Score,
DENSE_RANK() OVER (ORDER BY Score DESC) AS DenseRank
FROM StudentScores;
In essence, DENSE_RANK() is a powerful tool in SQL's ranking arsenal, helping to analyze and interpret data more effectively. Whether you’re identifying the most visited pages on your website, the highest-grossing movies, or the top-performing salesperson, DENSE_RANK() allows you to handle ties in your data gracefully, ensuring no valuable insights are overlooked. In the next section, we'll delve deeper into the differences between DENSE_RANK(), RANK(), and ROW_NUMBER(), and provide concrete examples to illustrate these concepts.
Practical Examples of SQL DENSE_RANK() Function
Navigating through the complexities of SQL functions can transform the way we approach data analysis and reporting. The DENSE_RANK() function, in particular, stands out for its ability to assign consecutive ranks to rows based on the specified order while ensuring no gaps in ranking values. In the upcoming sections, we'll delve into practical examples that illustrate how the DENSE_RANK() and RANK() function can be deftly applied to real-world databases, providing clear insights and streamlined data organization.
CREATE TABLE sales_data ( employee_id INT, sales_date DATE, total_sales DECIMAL ); INSERT INTO sales_data (employee_id, sales_date, total_sales) VALUES (101, '2024-01-01', 500), (102, '2024-01-01', 700), (103, '2024-01-01', 600), (101, '2024-01-02', 800), (102, '2024-01-02', 750), (103, '2024-01-02', 900), (101, '2024-01-03', 600), (102, '2024-01-03', 850), (103, '2024-01-03', 700);
For example, let's say you're a data analyst at Apple and you've been asked to structure a SQL query to identify the top B2B sales reps for each sales date.
SELECT
employee_id,
sales_date,
total_sales
FROM (
SELECT
employee_id,
sales_date,
total_sales,
DENSE_RANK() OVER (PARTITION BY sales_date ORDER BY total_sales DESC) AS sales_rank
FROM sales_data
) ranked_sales
WHERE sales_rank = 1;In this SQL solution, the first step is to select the desired columns from the sales_data table: employee_id (the unique identifier for each employee), sales_date (the date of each sale), and total_sales (the total amount of sales made on that particular date). This information will be necessary in order to identify the top B2B sales reps for each sales date.
Next, the data is further refined using a subquery. The subquery uses the DENSE_RANK() function to assign a ranking value for each employee based on their total sales in descending order on a particular sales date. This means that if an employee has the highest total sales on a given date, they will be assigned a ranking value of 1.
Finally, the outer query selects only those rows where the sales_rank is equal to 1, which represents the top B2B sales rep for each sales date. This data can then be used for further analysis or reporting purposes. This SQL solution is efficient and effective in finding the top B2B sales reps for each sales date as it utilizes a ranking function and filters out all other unnecessary data. It can easily be modified to find the top sales reps for specific product categories, regions, or other criteria by adjusting the partition and order clauses within the DENSE_RANK() function.
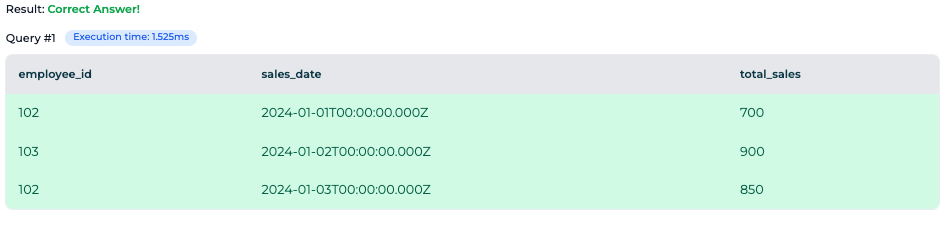
Using the same SQL schema, you've now been tasked with creating another SQL solution that shows the sales ranking for each employee across all dates. This can be achieved by using a combination of the RANK function and the SUM function, which will allow you to rank each employee based on their total sales across all dates.
SELECT employee_id, SUM(total_sales) AS total_sales_sum, RANK() OVER (ORDER BY SUM(total_sales) DESC) AS sales_rank FROM sales_data GROUP BY employee_id;

When deciding between DENSE_RANK() and RANK(), remember that RANK() groups the data and orders within each group, while DENSE_RANK() treats all rows as one group. In most cases, either function can be used interchangeably for the same outcome. The distinction between DENSE_RANK() and RANK() is nuanced yet significant. Both functions assign a unique rank or row number to each row in the result set. However, the discrepancy arises when there are duplicate values in the ordering columns.
Avoiding Common Mistakes with DENSE_RANK() in SQL
When working with DENSE_RANK() in SQL, it’s crucial to avoid common pitfalls that can lead to incorrect results or inefficient queries. Here are key strategies to ensure accurate and optimal use of this function:
- Understand the Ranking Basis: Make sure you are clear on the column (or columns) being used to determine the ranking order.
- Use ORDER BY Clause Correctly: The
DENSE_RANK()function requires anORDER BYclause; ensure it correctly reflects the desired ranking. - Distinct Partitions: Apply
PARTITION BYwhen needed to reset ranks for different data segments. - Avoid Ambiguous Columns: In the presence of JOINs, specify the table for the columns used within the
DENSE_RANK()to prevent confusion. - Handle NULLs Appropriately: Remember that
DENSE_RANK()treats NULL values as equivalent for ranking. - Performance Considerations: Index the columns used in the
ORDER BYclause to improve query performance. - Cross-check Results: After implementing
DENSE_RANK(), verify the results with test cases to ensure accuracy.
By conscientiously applying these strategies, you can harness the full potential of `DENSE_RANK()` to efficiently generate reliable rankings within your SQL queries.
Frequently Asked Questions
Where can I practice SQL interview questions including DENSE_RANK ()?
Answer: We recommend practicing online using sites such as BigTechInterviews, Leetcode, or similar platforms.
Answer: DENSE_RANK() is a window function in SQL that assigns ranks to rows of data based on the specified column, with ties given the same rank and no gaps in the ranking sequence.
What does Dense_rank () do in SQL?
Answer: DENSE_RANK() is a window function in SQL that assigns ranks to rows of data based on the specified column, with ties given the same rank and no gaps in the ranking sequence.
What is the difference between RANK () and ROW_NUMBER () and DENSE_RANK () in SQL?
Answer: RANK() and ROW_NUMBER() both assign ranks to data, but they handle ties differently. RANK() leaves gaps in ranking when there are ties, while ROW_NUMBER() assigns a unique number to each row without considering ties. On the other hand, DENSE_RANK() assigns identical ranks to tied data points without any gaps.
How to use DENSE_RANK () in the WHERE clause in SQL?
Answer: ENSE_RANK() is a window function and cannot be used directly in the WHERE clause. Instead, it can be used in conjunction with other functions like ROW_NUMBER() or RANK(), which can then be used in the WHERE clause to filter data based on rank.
Can DENSE_RANK () be used without PARTITION BY?
Answer: No, PARTITION BY is an essential component of the DENSE_RANK() function and is required for it to work properly. Without specifying a partition, all data would be treated as one group, and ranking would not be accurate or meaningful. Overall, mastering the use of DENSE_RANK() in SQL can greatly enhance your data analysis skills and provide valuable