

SQL Server 2022 is in preview and I wrote a previous article on the T-SQL language changes. This article is a second part, covering a few more of the changes in T-SQL that are coming with this new version of the database platform.
The previous article looked at DISTINCT FROM, DATE_BUCKET, GENERATE_SERIES, GREATEST/LEAST, STRING_SPLIT, and DATETRUNC. In this article, I'll cover APPROX_PERCENTILE_CONT, APPROX_PERCENTILE_DISC and the bit manipulation functions. I'll also look at changes in FIRST_VALUE, LAST_VALUE, and LTRIM/RTRIM/TRIM changes.
This is a light look at these language features, as I am still experimenting and learning about them. My evaluation of SQL Server 2022 is from the perspective of someone trying to decide whether or not to recommend an upgrade to our systems, so I'm examining where we might use these language changes to make coding easier. I am working with SQL Server 2022 RC0 for my experiments.
APPROX_PERCENTILE_CONT
There is a PERCENTILE_CONT function in T-SQL already. This function is designed to return a value from a set of data based on a percentile requested. This is a window function that requires the OVER() clause a value closest to the percentile, which might not actually exist in the data. If I run a sample query from the Docs in the AdventureWorks database, I see this:
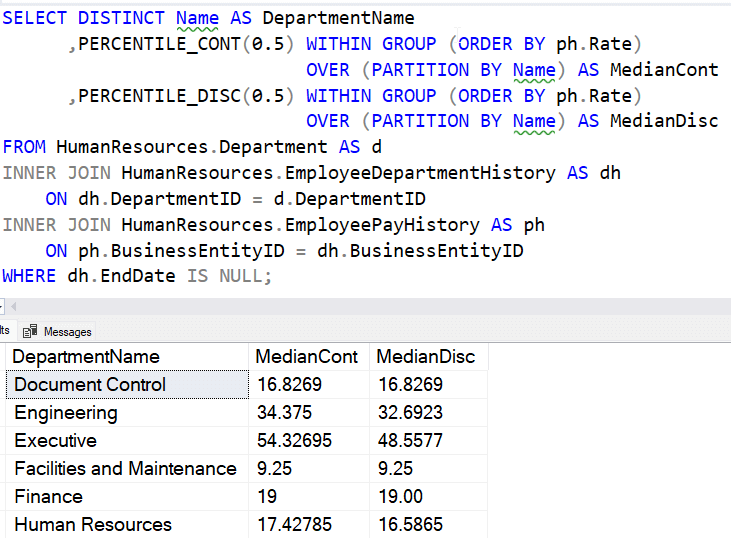
The approximate version of this function tries to get an approximate value of the same function, but without needing to read all the data. This value should be within some error specification. Microsoft Docs says this about the function:
This function returns an approximate interpolated value from the set of values in a group based on percentile value and sort specification. Since this is an approximate function, the output would be within rank based error bound with certain confidence. The percentile value returned by this function is based on a continuous distribution of the column values and the result would be interpolated. Due to this, the output might not be one of values in the data set. One of the common use cases for this function is to avoid the data outliers. This function can be used as an alternative to PERCENTILE_CONT for large datasets where negligible error with faster response is acceptable as compared to accurate percentile value with slow response time.
Basically, if you can accept an approximate value and want to minimize the resources needed, this function helps. This is similar to the APPROX_COUNT_DISCTINCT function.
This function is not a window function and doesn't use an ORDER clause. There is a grouping clause, and I can specify an ordering there. If I run this on the AdventureWorks data set, I see same results.
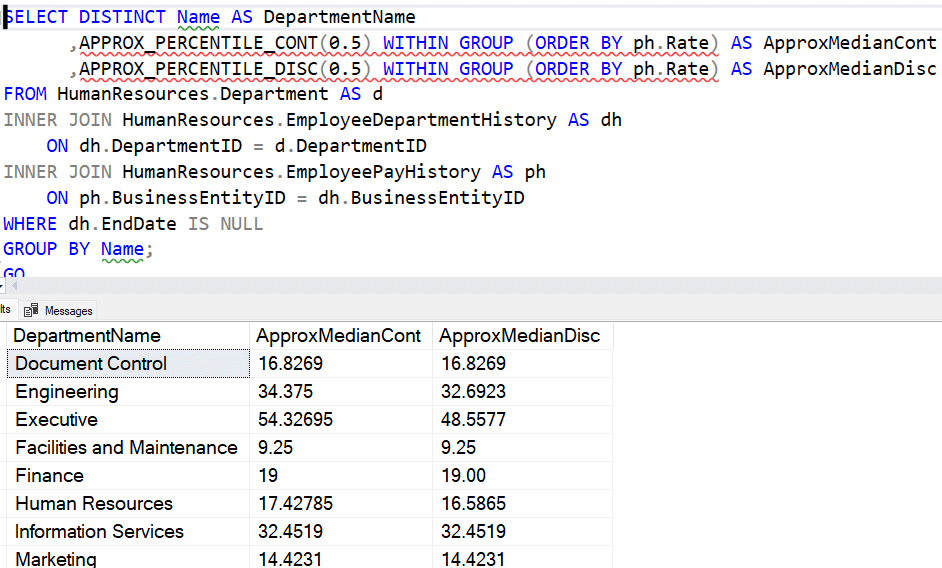
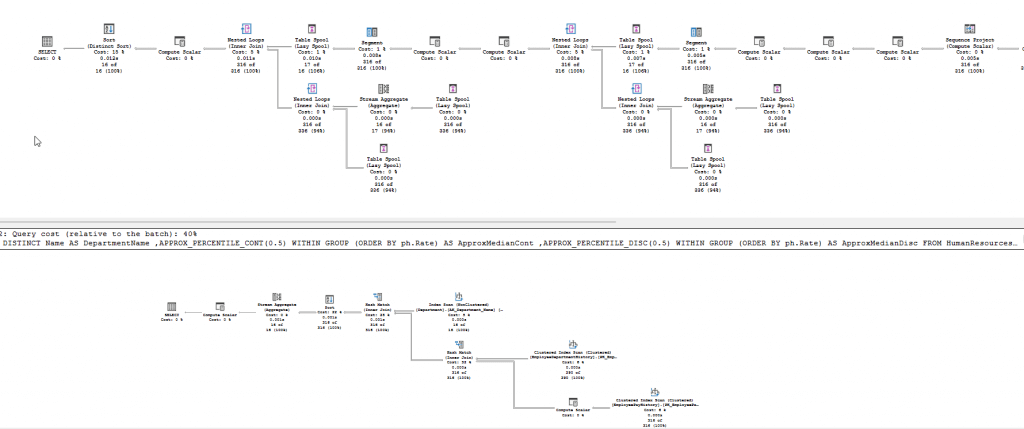
If I look at the execution plans, we can see the approximate version uses a much simpler plan. The top plan below is the PERCENTILE_CONT and the bottom one is APPROX_PERCENTILE_CONT.
APPROX_PERCENTILE_DISC
The PERCENTILE_DISC and APPROX_PERCENTILE_DISC functions are likewise related, with the new approximate function being quicker and less resource intensive, potentially at the expense of not being completely accurate. Both of these functions will again return a value based on a percentile of the data.
As with the functions above, I get the same values in AdventureWorks for both the accurate and approximate functions. The execution plan shapes look the same, with the approximate plan being much simpler.
Bit Operations
There are a number of bit functions added in 2022 to allow you to bit shift values. Bit encoding and manipulation is something that can be used as a set of toggles that are quicker and easier to set than using separate column values. This is harder to read, in my opinion, but this is the type of thing used in some internal settings. For example, the @@options number is really a series of bits that are set.
To try and explain this in a simple way, let's look at a number. For example, if I consider 64, this is stored in a binary value as a set of 7 bits. This value is 1000000. I can see this in a SELECT by using the AND (&) function with the value. Look at this, and you see that each bit is based on a power of 2.
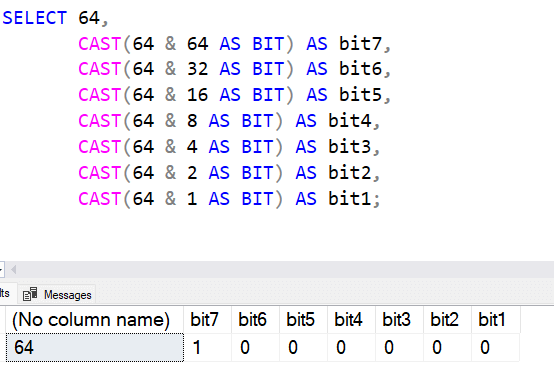
The following functions will affect these bits with various operations.
LEFT_SHIFT ()
The LEFT_SHIFT() function is designed to shift the bits left, as you might guess. In this case, if I run this on the value, 64, then I get this result:
SELET LEFT_SHIFT(64,1) as NewValue NewValue -------- 128
The format of the function requires two parameters.
- An expression - either an integer or binary value that is not a large object (LOB)
- A number of bits to shift to the left
This returns the new binary or interger value. The shift can be on a binary value, so this is a BIGINT value.
If I run this on 32 with a shift of 1, then I end up with 64. That's what I expect, if you were to look at the two set of bits together. I've used a UNION query to allow you to see this. Here is the code:
DECLARE @number INT = 32, @new int;
SELECT left_shift(@number, 1)
SELECT @new = left_shift(@number, 1)
SELECT @number,
CAST(@number & 128 AS BIT) AS bit8,
CAST(@number & 64 AS BIT) AS bit7,
CAST(@number & 32 AS BIT) AS bit6,
CAST(@number & 16 AS BIT) AS bit5,
CAST(@number & 8 AS BIT) AS bit4,
CAST(@number & 4 AS BIT) AS bit3,
CAST(@number & 2 AS BIT) AS bit2,
CAST(@number & 1 AS BIT) AS bit1
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit8,
CAST(@new & 64 AS BIT) AS bit7,
CAST(@new & 32 AS BIT) AS bit6,
CAST(@new & 16 AS BIT) AS bit5,
CAST(@new & 8 AS BIT) AS bit4,
CAST(@new & 4 AS BIT) AS bit3,
CAST(@new & 2 AS BIT) AS bit2,
CAST(@new & 1 AS BIT) AS bit1;And here are the results. As you see, the 1 is shifted one space to the left. The shift also uses 0s to fill in from the right.

If I repeat this with 27, what you find is that I get 54. A bit shift is a way of multiplying by the base, which is 2. In other words, this doubles the value for each bit shift.

RIGHT_SHIFT ()
As you might guess, the correlated function to LEFT_SHIFT() is RIGHT_SHIFT(). This function moves bits to the right, which is a division by 2 for each bit shifted.
Let's use the same code as above, but with this new function. Now we see that if I start with 64 and shift 2 times to the right, I get 16. This means 64/2 = 32 and 32/2 gives me 16. Here's code:
DECLARE @number INT = 64, @new INT, @shifts INT = 2;
SELECT right_shift(@number, @shifts)
SELECT @new = right_shift(@number, @shifts)
SELECT @number,
CAST(@number & 128 AS BIT) AS bit8,
CAST(@number & 64 AS BIT) AS bit7,
CAST(@number & 32 AS BIT) AS bit6,
CAST(@number & 16 AS BIT) AS bit5,
CAST(@number & 8 AS BIT) AS bit4,
CAST(@number & 4 AS BIT) AS bit3,
CAST(@number & 2 AS BIT) AS bit2,
CAST(@number & 1 AS BIT) AS bit1
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit8,
CAST(@new & 64 AS BIT) AS bit7,
CAST(@new & 32 AS BIT) AS bit6,
CAST(@new & 16 AS BIT) AS bit5,
CAST(@new & 8 AS BIT) AS bit4,
CAST(@new & 4 AS BIT) AS bit3,
CAST(@new & 2 AS BIT) AS bit2,
CAST(@new & 1 AS BIT) AS bit1;And the visual results. Notice the 1 in bit 7 is slipped 2 places to the right.

What happens with two shifts of 54? After all, 27 doesn't divide by 2 evenly. You might guess we get the integer portion of the result (26) and the decimal is dropped (.5). That's integer division. Here are the bit shift results.

Another example to see shifts, let's see 100 shifted right twice. All 1s move to the right, with 0s willing in from the left.

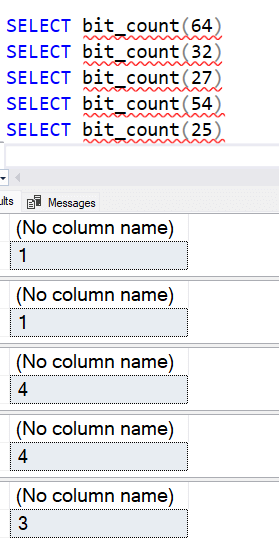
BIT_COUNT ()
The BIT_COUNT() function is designed to count the number of bits set to 1 in a numerical or binary expression. I don't quite know what you will use this for, though I imagine if you are allowing this to be a set of toggles, you get a number of toggles set to 1. Perhaps if I had something like the attendance of a class, where I have each student in a location. So imagine that bit 1 is Frank, bit 2 is Amy, bit 3 is Mark, etc. I can encode attendance by setting those bits and then count the attendance of how many students are in class with this function.
Using the examples above, we should get results from this function of:
- 64 = 1
- 32 = 1
- 27 = 4
- 54 = 4
- 25 = 3
We see these results from the function:
GET_BIT ()
As you might expect, GET_BIT() returns the value of a numerical (or binary) expression. Like LEFT_SHIFT(), we need a second parameter that is the offset of the bit. 0 is the rightmost bit, so if I want to get bit 3 from 100, I am looking for a 0. You can see the results below, but bit 3 is actually the 4th from the right since we start at 0.
Note: I have renumbered the bits from the code above.
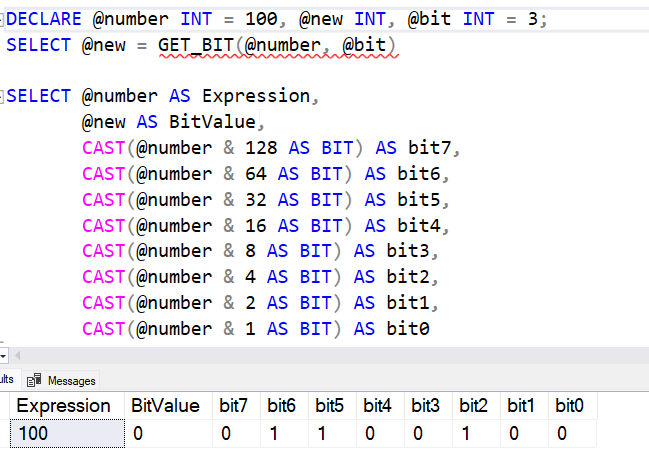
If I were continuing the attendance example above, I could get the attendance for a particular student by specifying their spot in the value to determine if they were present or absent.
SET_BIT ()
The opposite of GET_BIT() is SET_BIT(). This allows you to set a bit value in the expression. One interesting thing about this function is that you can not include the value to set if you want it to be one. If you want it to be 0, then the third parameter is included as a 0.
Here is some code that shows me setting bit 3 in 100. The value of bit 3 is a 0 in 100, and if I do not have a third parameter, this is set to 1. This spot in a binary value is the toggle for 8, so this actually adds 8, or 2^3, to the value. Here is the code:
DECLARE @number INT = 100, @new INT, @bit INT = 3;
SELECT @new = SET_BIT(@number, @bit)
SELECT @number AS Expression,
CAST(@number & 128 AS BIT) AS bit7,
CAST(@number & 64 AS BIT) AS bit6,
CAST(@number & 32 AS BIT) AS bit5,
CAST(@number & 16 AS BIT) AS bit4,
CAST(@number & 8 AS BIT) AS bit3,
CAST(@number & 4 AS BIT) AS bit2,
CAST(@number & 2 AS BIT) AS bit1,
CAST(@number & 1 AS BIT) AS bit0
UNION
SELECT @new,
CAST(@new & 128 AS BIT) AS bit7,
CAST(@new & 64 AS BIT) AS bit6,
CAST(@new & 32 AS BIT) AS bit5,
CAST(@new & 16 AS BIT) AS bit4,
CAST(@new & 8 AS BIT) AS bit3,
CAST(@new & 4 AS BIT) AS bit2,
CAST(@new & 2 AS BIT) AS bit1,
CAST(@new & 1 AS BIT) AS bit0
;
GOThe result, as shown below, is 108.

This is essentially a way to add or subtract a value from an integer.
FIRST_VALUE () / LAST_VALUE ()
These functions have been in SQL Server for a few versions. However, both FIRST_VALUE() and LAST_VALUE() gain two clauses. We can add either of these clauses to the function. I've included the language from MS Docs.
- IGNORE NULLS - Ignore null values in the dataset when computing the first value over a partition.
- RESPECT NULLS - Respect null values in the dataset when computing first value over a partition.
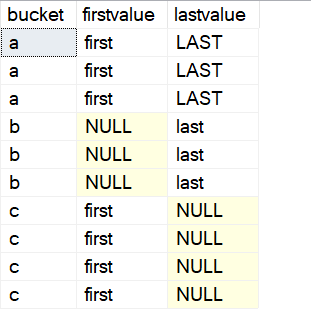
This means that if there are NULL values in a partition (data set), we can either include or exclude them. As an example, I've got a data set in a virtual table, which has an ordering an a few buckets of data. Here is the code:
SELECT bucket,
FIRST_VALUE(val) OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS firstvalue,
LAST_VALUE(val) OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lastvalue
FROM ( VALUES
('a', 1, 'first'),
('a', 2, NULL),
('a', 3, 'LAST'),
('b', 1, NULL),
('b', 2, 'mid'),
('b', 3, 'last'),
('c', 1, 'first'),
('c', 2, 'mid1'),
('c', 3, 'mid2'),
('c', 4, NULL)
) A(bucket, bucketorder, val)If I run the function as it works in 2019, I see some NULL values.
I can add in 2022 the clause for IGNORE NULLS. This is after the function and before the OVER() clause. Here is the code:
SELECT bucket,
FIRST_VALUE(val) IGNORE NULLS OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS firstvalue,
LAST_VALUE(val) IGNORE NULLS OVER (PARTITION BY A.bucket ORDER BY A.bucketorder ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lastvalue
FROM ( VALUES
('a', 1, 'first'),
('a', 2, NULL),
('a', 3, 'LAST'),
('b', 1, NULL),
('b', 2, 'mid'),
('b', 3, 'last'),
('c', 1, 'first'),
('c', 2, 'mid1'),
('c', 3, 'mid2'),
('c', 4, NULL)
) A(bucket, bucketorder, val)Now I see no NULL from the same data set.

If I add RESPECT NULLS, I get the same results as from 2019. This means that RESPECT NULLS is the default.
LTRIM ()
There is a change to the LTRIM() function in SQL Server 2022, which allows you to trim specific characters. The default is a space, but you can change this. The description of the function says this removes char(32) or other characters from the beginning of the string. This didn't work on CTP 2.1, but in RC0, this does work. Here is some code:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,' '),
LEN(LTRIM(StringValue,' ')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bbbString4bbbb')
) A(StringValue)
GO
In this code, I am removing spaces from the left side of the strings. If you look at my strings, there are 4 values which have spaces on the left (string1, string2, string2, and string5). When I run this, I see these results:

Those 4 stings are shorter, as the spaces are removed. It can be hard to see spaces, which is why I have the lengths. Now, let's remove another character. I'll remove the 'a' with this code:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,'a'),
LEN(LTRIM(StringValue,'a')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bbbString4bbbb')
) A(StringValue)
GO
In the results, only string4 has an a at the beginning, and all 3 of those are removed.

I do seem to also remove multiple characters as well as this code shows:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
LTRIM(STRINGVALUE,'The'),
LEN(LTRIM(StringValue,'The')) AS TrimLength
FROM (
VALUES
('The quick brown fox'),
('The end of the story'),
('TheThe Boat')
) A(StringValue)
GO
And the results:
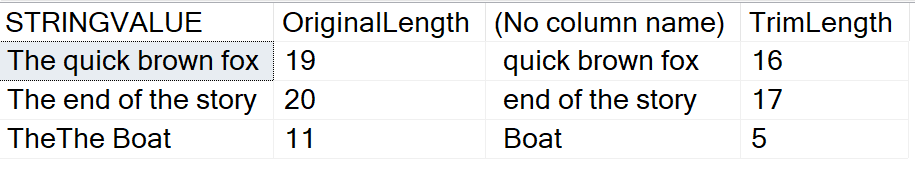
Note, this doesn't remove the word "The", but rather looks for any of the characters at the beginning of the string and removes them. So, if a "t", an "h", or an "e" are at the beginning, they are removed. This means that SELECT LTRIM('tehhts', 'the') returns only an 's'.
RTRIM ()
Similar to LTRIM(), RTRIM() has been changed to allow a character to remove to be specified. Here is some code:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
RTRIM(STRINGVALUE,'b'),
LEN(RTRIM(StringValue,'b')) AS TrimLength
FROM (
VALUES
(' String1'),
(' String2'),
(' String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('String6bbbb')
) A(StringValue)
GO
The results look like LTRIM(), but from the right side of the strings we have characters removed.
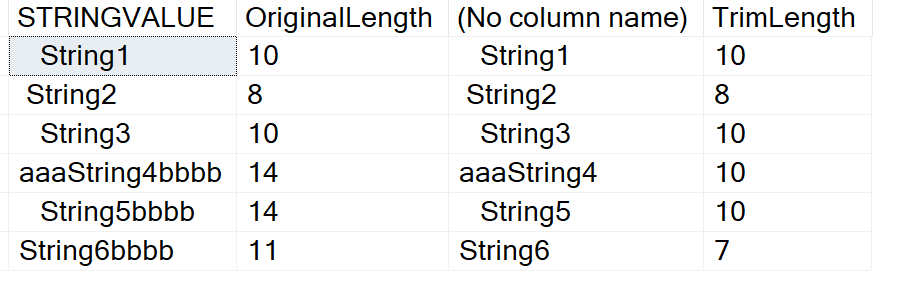
This is a useful function as we sometimes get extraneous characters entered by customers and want to remove something other than a space.
TRIM ()
TRIM() has similarly been enhanced, but with other syntax. The new syntax for 2022 is shown in Docs like this:
TRIM ( [ LEADING | TRAILING | BOTH ] [characters FROM ] string )
I can add leading to get LTRIM behavior, TRAILING for RTRIM, or BOTH for TRIM. I then have a string that contains the characters I want to remove and then the string itself. Strange language choice, though it reads well. Some examples in this code:
SELECT STRINGVALUE,
LEN(StringValue) AS OriginalLength,
TRIM(BOTH 'b' FROM STRINGVALUE),
LEN(TRIM(BOTH 'b' FROM STRINGVALUE)) AS TrimLength
FROM (
VALUES
(' b String1b'),
(' String2b'),
('b String3 '),
('aaaString4bbbb'),
(' String5bbbb'),
('bString6bbbb')
) A(StringValue)
GOIf we look where there is a 'b' at the beginning or ending of a string, we find that string1, string2, string3, string4, string5, and string6 would have bs removed. If we see the results, we see that this is the case.
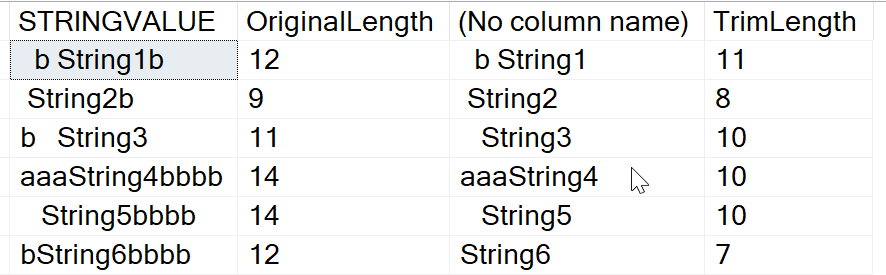
String 1 doesn't have the first b removed because there are spaces first and we haven't added spaces in our search parameter. However, string3 shows the leading b removed. String6 has both leading and trailing removed.
I could see this being handy in removed a few different initial characters, but I also think we could get into trouble with code that has multiple characters, and potentially places where we want to remove "Mr. " from "Mr. XX YY" but run into cases where "Mr. Michael" causes both Ms to be removed. Tricky function.
Summary
Some of these are interesting functions. I like the appoximate ones, as they can save resources, though I don't know I'd use them as we don't use the PERCENTILE_CONT and PERCENTILE_DISC now. The bit shift ones have me thinking about where we might find value in encoding some switches. I think configuration settings could be useful here, though I do worry about the complexity of encoding things and having to explain that over and over to customers.
The TRIM functions have good enhancements, but I worry about multiple characters here causing issues. At the same time, I don't know if we want to have multiple TRIM statements in place either. Hard to know how useful these are against the danger of using them.
In the next article, I'll look at some of the JSON changes.