Introduction
In Level 1 of this series, I discussed Synapse Analytics basics and the steps for creating a Synapse Workspace. In Level 2, data analysis was done on Data Lake files using Serverless SQL Pool. In Level 3, data analysis was done on Data Lake files using Spark Pool. In Level 4, I started discussion on Delta Lake. In Level 5 also, I will continue discussing Delta Lake.
Data Analysis Steps
I will start with streaming data processing using Delta Lake. I will query Delta Lake using Serverless SQL Pool. The last topic will be Change data feed.
Streaming data processing
A stream processing solution can constantly read a stream of data from a source. The solution can process the data to select specific fields, aggregate and group values, and finally write the result to a sink.
Spark structured streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. A Spark Structured Streaming dataframe can read da ta from many different kinds of streaming sources such as Azure Event Hubs or Kafka, or file system locations. The streaming solution provides fast, scalable, fault-tolerant, end-to-end exactly-once processing.
A Delta Lake table can be used both as streaming source and sink for Spark Structured Streaming.
Use Delta Lake as a Streaming Sink
I have a streaming data source csv file on spotify history. I will attach the data file with this article.
I create a copy of that file with first 200 records from the original data source file and upload in a folder, named streamingdata, in the Data Lake container.
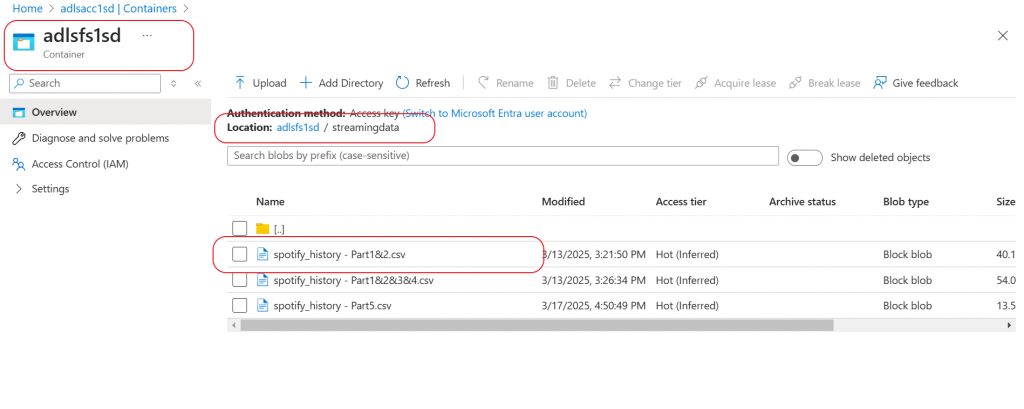
I create a new notebook in Synapse studio and Attach the notebook with the spark pool created earlier in the series. I write code to load the streaming data from the Data lake folder to a Delta lake.
# include the required library modules
from pyspark.sql.types import *
from pyspark.sql.functions import *
# Create a stream that reads CSV data from a folder
inputPath = '/streamingdata/'
# define the schema for Delta lake as defined in the csv file
csvSchema = StructType([
StructField("spotify_track_uri", StringType()),
StructField("ts", StringType()),
StructField("platform", StringType()),
StructField("ms_played", StringType()),
StructField("track_name", StringType()),
StructField("artist_name", StringType()),
StructField("album_name", StringType()),
StructField("reason_start", StringType()),
StructField("reason_end", StringType()),
StructField("shuffle", StringType()),
StructField("skipped", StringType())
])
# read the streaming data from csv file path to a streaming dataframe
stream_df = spark.readStream.format("cloudFiles").schema(csvSchema).option("maxFilesPerTrigger", 1).csv(inputPath)
# Write the stream to a delta table
table_path = '/delta/spotifyStreamData'
checkpoint_path = '/delta/spotifyCheckpoint'
delta_stream = stream_df.writeStream.format("delta").option("checkpointLocation", checkpoint_path).start(table_path)readStream
This method is used in reading streaming data. By default, structured streaming from file based sources require to specify the schema. This restriction helps to maintain a consistent schema for data reading.
- cloudfiles: this format is used for implementing Auto Loader. Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage.
- maxFilesPerTrigger: this option is used to maintain a consistent batch size for streaming query. This value specifies an upper-bound for the number of files processed in each micro-batch.
writeStream
This method is used for writing streaming dataframe to a sink. It configures how data is written in real-time to various destinations.
- checkpointLocation: this option is used to write a checkpoint file that tracks the state of the stream processing. This file helps to recover from failure at the point where stream processing stopped.
- writeStream is started. Data is now flowing to the Delta table as mentioned in the query.
I define the delta table as a catalog table and write select statement on the table to verify the streaming file records in the table.
%%sql -- create a new catalog table CREATE TABLE IF NOT EXISTS spotifyStreamData USING DELTA LOCATION '/delta/spotifyStreamData'; -- select number of records from the table SELECT COUNT(1) as Computed FROM spotifyStreamData;
The stream is running. As the Auto Loader is activated, every new streaming file will be processed only once and data will be populated in the Delta table.
I create another copy of the spotify history file with 100 records and upload in the same storage location and execute the select statement to count the records in the catalog table. The count is now increased by 100. For every new streaming file uploaded with the same schema, the delta table will be populated.
I can stop the stream once not required with this code.
# stop the stream delta_stream.stop()
Streaming data was populated in the Delta table in the last step. I will now use the Delta table as a streaming source. I will populate the streaming dataframe from the delta table and will output the streaming data to console.
# import the library modules
from pyspark.sql.types import *
from pyspark.sql.functions import *
# Load a streaming dataframe from the Delta Table
stream_df = spark.readStream.format("delta") \
.option("ignoreChanges", "true") \
.load("/delta/spotifyStreamData")
# process the streaming data in the dataframe
stream_df.writeStream \
.outputMode("append") \
.format("console") \
.start()The readStream parameter is:
- option: adds input options for the underlying data source. When ignoreChanges is enabled, the stream will continue to read the Delta table. It will only process the data present in the table at the time the stream started, ignoring any subsequent updates or delete.
The writeStream parameters are:
- outputmode: defines how data is written to the sink for each micro-batch. The possible values are: append, complete, and update.
- format: specifies the output format. Few possible values are: parquet, csv, json, console etc.
Query a Delta Table from the Serverless SQL pool
Serverless SQL pool can be used to read data stored in Delta Lake and the retrieved data can be used for reporting purpose. It is not possible to insert, update, or delete data in the Delta table using Serverless SQL pool.
I write a SQL query to retrieve the latest data from the Delta table stored in the specified file location.
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'spotifyStreamData',
DATA_SOURCE = 'https://adlsacc1sd.blob.core.windows.net/adlsfs1sd/delta/',
FORMAT = 'delta'
) as rows;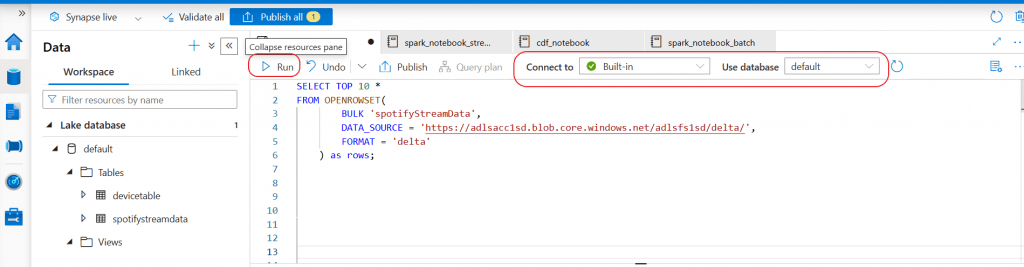
Next, I create a database in the Serverless SQL pool and populate the data from the Delta table in external table and then in a view.
--create a new database
CREATE DATABASE delta_storage
go
-- use the new database
USE delta_storage
go
-- create external data source with the root folder of the Delta lake
CREATE EXTERNAL DATA SOURCE DeltaLakeStore1
WITH ( LOCATION = 'https://adlsacc1sd.blob.core.windows.net/adlsfs1sd/delta/');
GO
-- create file format for delta
CREATE EXTERNAL FILE FORMAT DeltaLakeFormat WITH ( FORMAT_TYPE = DELTA );
GO
--create external table with the delta lake structure and populate data from Delta lake
CREATE EXTERNAL TABLE DeltaDataSQL
(
spotify_track_urivarchar(8000) NULL,
ts varchar(8000) NULL,
platform varchar(8000) NULL,
ms_played varchar(8000) NULL,
track_name varchar(8000) NULL,
artist_namevarchar(8000) NULL,
album_namevarchar(8000) NULL,
reason_start varchar(8000) NULL,
reason_end varchar(8000) NULL,
shuffle varchar(8000) NULL,
skipped varchar(8000) NULL
)WITH (
LOCATION = 'spotifyStreamData', --> the root folder containing the Delta Lake files
data_source = DeltaLakeStore1,
FILE_FORMAT = DeltaLakeFormat
);
-- retrieve data from external table
SELECT TOP 10 *
FROM DeltaDataSQL
--create view from external table
create view DeltaDataView
AS
SELECT * FROM DeltaDataSQL WHERE artist_name = 'Justice'
-- retrieve data from view
SELECT * FROM DeltaDataViewThe serverless SQL pool has shared access to databases in the Spark metastore. So, the pool can query the catalog tables using Spark SQL.
SELECT TOP (10) * FROM [default].[dbo].[spotifystreamdata]
Change Data Feed (CDF)
Change Data Feed (CDF) feature of Delta Lake allows the Delta tables to track row-level changes between the versions. Insert, Update, Delete, and Merge operations are tracked using CDF. CDF is not enabled by default. This feature can be enabled for new table as well as existing tables. The default Delta table property can also be set to enable CDF for all the new tables.
--enable CDF for a new table CREATE TABLE IF NOT EXISTS spotifyStreamData USING DELTA LOCATION '/delta/spotifyStreamData' SET TBLPROPERTIES (delta.enableChangeDataFeed = true) --enable CDF for an existing table ALTER TABLE spotifystreamdata SET TBLPROPERTIES (delta.enableChangeDataFeed = true) --enable CDF for all new tables set spark.databricks.delta.properties.defaults.enableChangeDataFeed = true;
Changed data in the table is tracked only after the feature is enabled on the respective table.
I enabled CDF on spotifyStreamData table at version 3. So, changed data will be captured from version 3 onwards for this table. I read the changes in the streaming table by mentioning the starting version as 3. If an earlier version is mentioned, the query throws error.
#read changed data from the streaming table from version 3 in a dataframe
stream_df=spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 3) \
.table("spotifystreamdata")
#print data
display(stream_df)When change data feed is read, the latest table version schema is used. In addition to the data columns, three metadata columns are returned. These additional columns identify the type of change event.
- _change_type (value: insert, update_preimage , update_postimage, delete
) - _commit_version (value: table version containing the change)
- _commit_timestamp (value: timestamp for the commit)
CDF can be enabled for the batch table data as well in the similar way.
Further reading
- Delta Lake Documentation: https://docs.delta.io/latest/delta-intro.html
- Structured Streaming Programming Guide: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Conclusion
Support for both batch and streaming data ingestion in Delta lake allows unified data processing and simplified data pipeline design. Delta lake features like data skipping and partitioning help to improve query performance significantly. Delta tables can be created and managed using Spark pool and can be queried using Serverless SQL pool. Real time analytics can be done on Delta lake and data can be shared with various services like Power BI and Azure Analysis Services with the help of Serverless SQL pool.
