Introduction
In Level 1 of this series, I discussed Synapse Analytics basics and the steps for creation of the Synapse Workspace. In Level 2, I performed data analysis on Data Lake files using the Serverless SQL Pool. In Level 3, we examined data analysis on Data Lake files using Spark Pool. In Level 4, and Level 5, I discussed the Delta Lake.
In this level, I will discuss the Dedicated SQL pool.
Concepts and Design Decisions
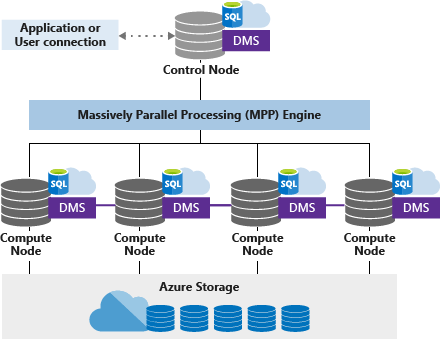
The Dedicated SQL pool is the enterprise data warehousing feature of Azure Synapse Analytics. The Dedicated SQL pool uses a node-based architecture. There will be one control node and one or more compute nodes. Applications issue T-SQL commands to the control node. The control node hosts the distributed query engine. This query engine optimizes the queries for parallel processing and then sends the operations to compute nodes.
The compute nodes execute the parallel queries and send the results back to the control node which in turn sends the final combined output to the application. A massively parallel processing (MPP) engine is used to efficiently handle large datasets and complex queries by distributed processing.
The Data Movement Service (DMS) helps to move data across the nodes to run queries in parallel.
Here is a diagram of the Dedicated SQL pool architecture components (from Microsoft Learn):
Data Warehouse Units (DWUs) represents an abstract, normalized measure of compute resources. Increasing the number of DWUs increase the performance of the pool and cost as well.
Compute is separate from storage in the Dedicated SQL pool. With decoupled storage and compute, compute power can be increased without changing storage. Also, compute capacity can be paused and resumed as required while leaving the data storage intact. Data is stored and managed by Azure Storage. There is a separate cost for storage consumption other than compute.
Data in Azure Storage is sharded into distributions to optimize the performance of the system. The three types of sharding patterns are:
- Hash
- Round Robin
- Replicate
Each is described below.
Distributions
A distribution is the basic unit of storage and processing. A query is divided into 60 smaller queries to run in parallel. Each compute node manages one or more of the 60 distributions depending on the number of compute nodes used.
Hash-distributed tables
A hash function is used to assign data to each distribution. One column is defined as the distribution column in the table and value in this column is used to decide the distribution for a row. Hash-distributed tables have the highest query performance for joins and aggregations on large tables.
Round-robin distributed tables
Data is distributed evenly across the table. A distribution is selected randomly and rows are assigned to distributions accordingly. Round-robin table is the simplest table to create. It delivers fast performance when used as s staging table.
Replicated Tables
Full copy of the table is available in all the compute nodes. Replicated tables are best utilized for small tables and give fastest query performance for small tables.
Create Dedicated SQL pool
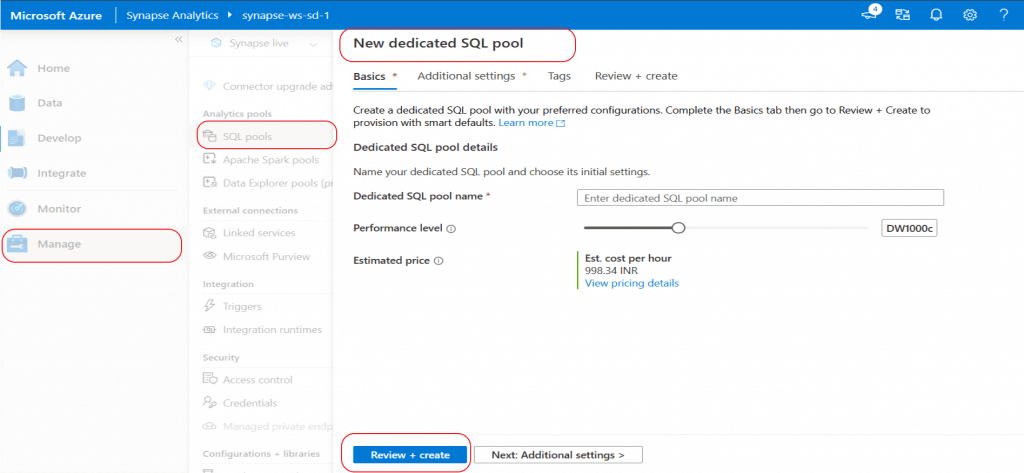
I go to the Synapse Workspace Overview page and click on the tab for New Dedicated SQL pool.
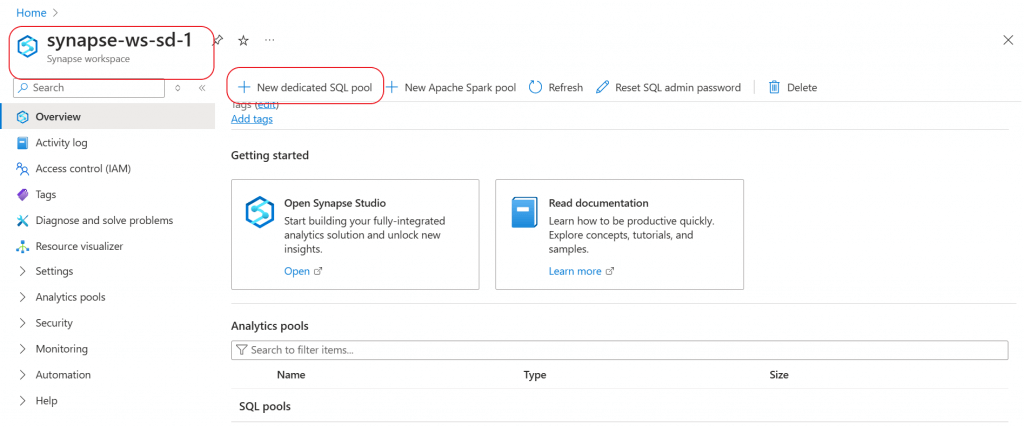
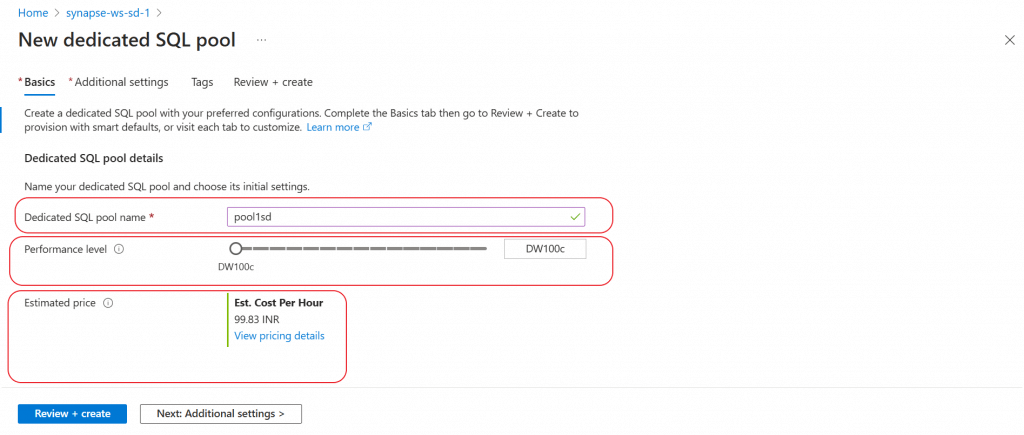
In the new pool creation page, I provide a name for the pool. The name should follow a predefined format and it should be unique within the workspace.
I select the performance level as the minimum value available to save on the cost. This performance level needs to be selected as per the data processing requirement. After monitoring the performance of the data load, it is possible to scale-out the performance level as per requirement.
The estimated price is decided based on the performance level selected.
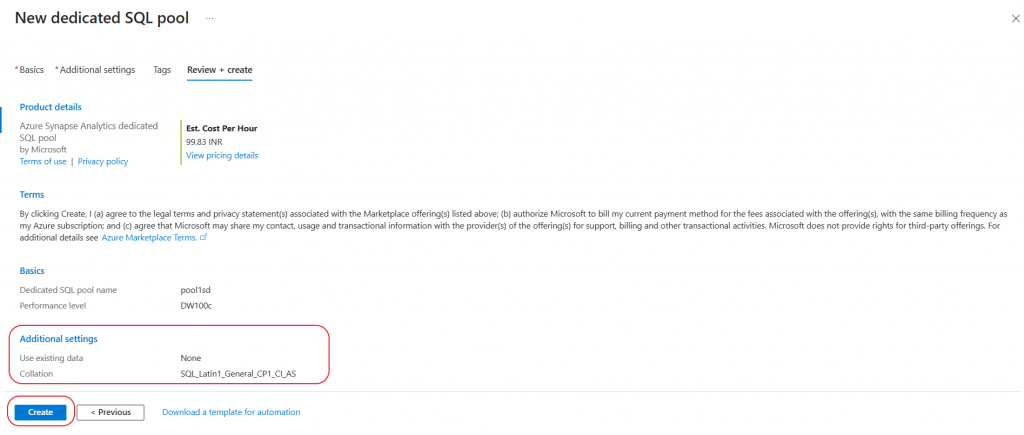
In the additional settings tab, I keep the default options provided for the fields. I go to the final tab and press the Create button to create the Dedicated SQL pool.
Alternatively, I may go to the Synapse studio and create the Dedicated pool. In the Manage tab, I need to select the SQL pool and then need to select the option to create a new Dedicated SQL pool. The steps to create the pool remains the same as done before.
Load Batch Data
For batch data ingestion in Dedicated SQL pool, both ETL (Extract, Transform, and Load) and ELT (Extract, Load, and Transform) processes can be used. However, ELT is preferred over ETL. ETL process uses the distributed query processing architecture that uses the scalability and flexibility of compute and storage resources. ELT process eliminates the resources needed for data transformation before loading.
Dedicated SQL pools support many loading methods including the SQL Server options like BCP and SqlBulkCopy API, the fastest and most scalable way to load data through PolyBase external tables, and the COPY statement. A detailed discussion about the data loading methods are available in the following articles:
- Loading data in Azure Synapse using Copy: https://www.sqlservercentral.com/articles/loading-data-in-azure-synapse-using-copy
- Loading data in Azure Synapse Analytics using Azure Data Factory: https://www.sqlservercentral.com/articles/loading-data-in-azure-synapse-analytics-using-azure-data-factory
- Access external data from Azure Synapse Analytics using Polybase: https://www.sqlservercentral.com/articles/access-external-data-from-azure-synapse-analytics-using-polybase
Load Streaming Data
Streaming data can be loaded in the Dedicated SQL pool using Azure Stream Analytics. Streaming data from Event Hub, IoT Hub, or other event-driven sources can be read and configured by Stream Analytics and then written the processed data in a table in the pool.
Loading data from Azure Stream Analytics to Dedicated SQL pool will be discussed in an upcoming article.
Query data from the SQL Pool
The Dedicated pool is now created and available in the Synapse workspace under the SQL pools menu. I click on the SQL pool.
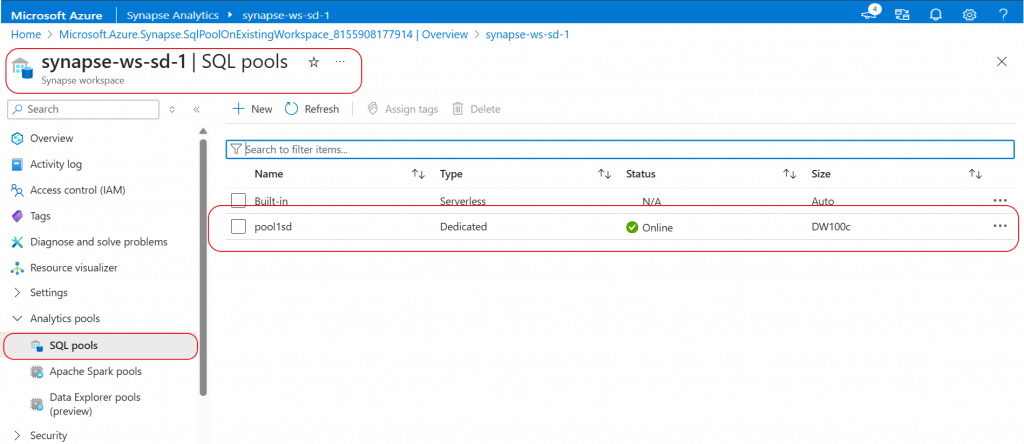
The Overview page for the Dedicated SQL pool is now open.
I can use the Pause button to pause the compute of the SQL pool when there is no data processing going on. The status of the pool will be paused. Then, with the resume button, the pool compute can be restarted.
With decoupled compute and storage, data is safe in the Storage while the compute can be increased/decreased in size and paused/resumed as required. There is separate charges for Storage and Compute consumption.
The Scale button can be used to change the performance level of the pool.
I click on the Open in Synapse Studio link.
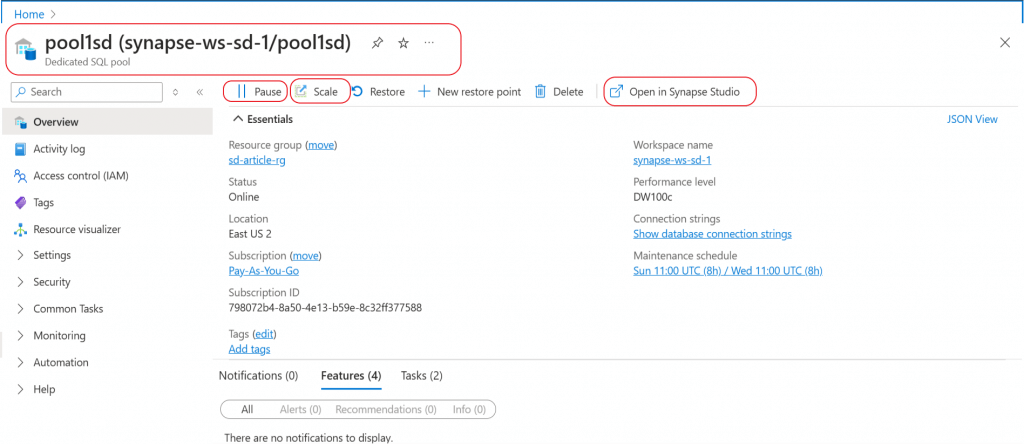
Now, I am in the Synapse Studio. In the data tab, under SQL database link, the newly created Dedicated pool is available. After expanding the pool, the database objects can be explored. As of now, no object is available in the database.
I start creating a new SQL script. I will use this script to create a table, insert data, and query the data in the table.
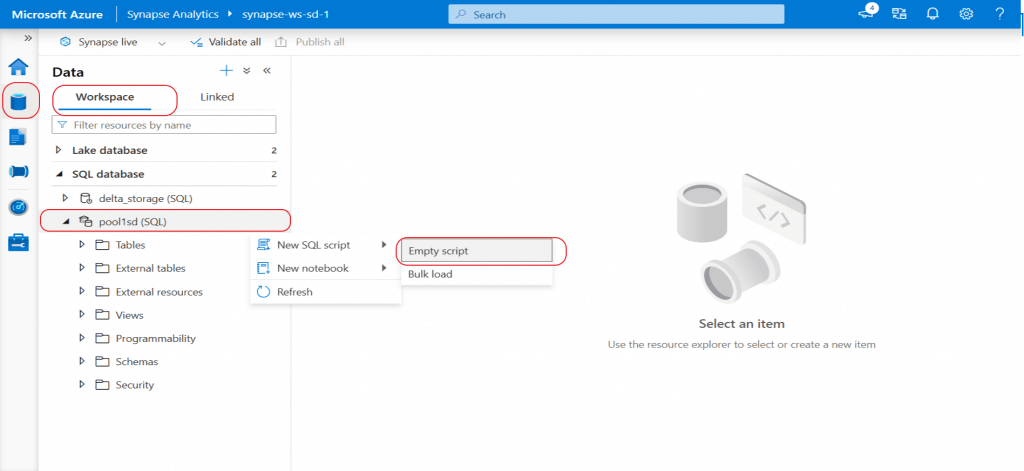
I create a table named emp in the existing dbo schema. I select the distribution as round robin which is the default distribution. Based on the working of the table, the appropriate distribution need to be selected.
Clustered columnstore index is the default option when no other index option is specified on the table. Clustered columnstore tables offer both the highest level of data compression and the best overall query performance. For small tables or table with transient data, heap or temporary table should be considered instead of clustered columnstore index.
I create both primary key and unique key on the table. The primary key is created as non-clustered as there can be only one clustered index on a table. The NOT ENFORCED clause needs to be added with primary key and unique key. This clause ensures that the database engine does not prevent duplicate values from being inserted into the indexed columns.
The column named emp_id is defined as an identity column. So, this column value will be populated automatically. The identity column value may not match the order in which the values are allocated due to the distributed architecture of the Dedicated pool. The identity property will scale out across all the distributions without affecting load performance.
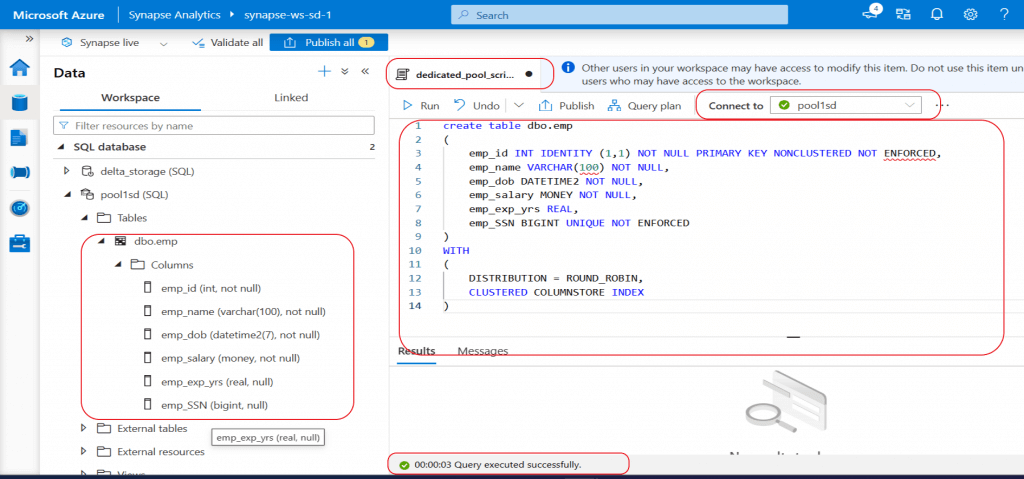
The SQL script used to create the table, populate data, and retrieve records is as shared below:
-- create a table
create table dbo.emp
(
emp_id INT IDENTITY (1,1) NOT NULL PRIMARY KEY NONCLUSTERED NOT ENFORCED,
emp_name VARCHAR(100) NOT NULL,
emp_dob DATETIME2 NOT NULL,
emp_salary MONEY NOT NULL,
emp_exp_yrs REAL,
emp_SSN BIGINT UNIQUE NOT ENFORCED
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
-- insert 5 records in the table
INSERT INTO dbo.emp
(emp_name,emp_dob,emp_salary,emp_exp_yrs,emp_SSN)
VALUES
('name1','01/01/2000',10000,6.3,123456)
INSERT INTO dbo.emp
(emp_name,emp_dob,emp_salary,emp_exp_yrs,emp_SSN)
VALUES
('name2','01/02/2001',9000,5.3,123457)
INSERT INTO dbo.emp
(emp_name,emp_dob,emp_salary,emp_exp_yrs,emp_SSN)
VALUES
('name3','01/01/2002',8000,4.3,123458)
INSERT INTO dbo.emp
(emp_name,emp_dob,emp_salary,emp_exp_yrs,emp_SSN)
VALUES
('name4','01/01/2003',7000,3.3,123459)
INSERT INTO dbo.emp
(emp_name,emp_dob,emp_salary,emp_exp_yrs,emp_SSN)
VALUES
('name5','01/01/2004',6000,2.3,123450)
-- query data from the table
SELECT * FROM dbo.empThe Dedicated SQL pool can be connected using SQL Server Management Studio (SSMS). The SQL Authentication connection details can be used. The password that was generated during Synapse workspace creation need to be used.
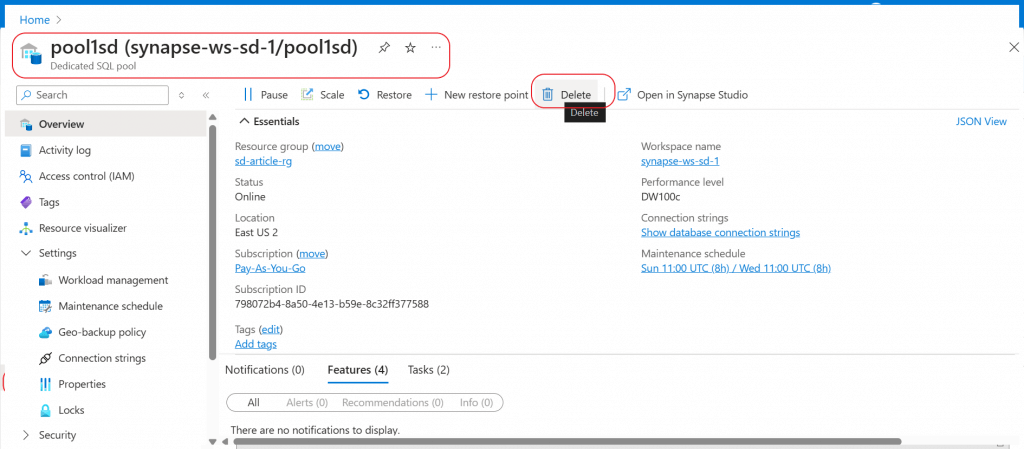
Delete the Pool
Once the pool is not in use, I delete the pool from the Overview page. Both the compute and storage are released. So, the data saved in the pool will be deleted.
Conclusion
Dedicated SQL pool should be used when a large-scale data warehousing and analytics solution is required with high performance, scalability, and cost effectiveness. Power BI reports can be created with DirectQuery mode by connecting the Dedicated SQL pool using linked services. Dedicated SQL pools are primarily used for structured data processing and may not be as flexible in processing unstructured data as compared to Apache Spark pool. For ad-hoc and infrequent data processing, serverless SQL pool may be a better option.
