

Introduction
In this example, we will show patterns between items stored in SQL Server using Python. We will use the FP-Growth algorithm to find common elements in the data that appear together in the transactions. For example, if we go to the supermarket, what items do we usually buy together?

Requirements
- First, we will need the SQL Server installed. In SQL Server, we will have the data to analyze.
- Secondly, we will use AdventureworksDW2009. This database contains sample data that we will use for this article.
- Thirdly, we will have Python installed.
- Finally, we will use Visual Studio Code to run Python, but you can use any Python platform to run the Python code.
FP-Growth algorithm patterns
FP-Growth (Frequent Pattern Growth) is a well-known mining algorithm used to find patterns in transactions. For example, a famous case study showed that people buy dippers and beer at the supermarket. This is because some young parents buy beer to watch the NFL (National Football League), but they will stay and take care of the children. Sometimes this algorithm helps a lot to find non-obvious patterns in the data.

Other applications for the FP-Growth algorithm
The typical example is the dippers and the beers in the supermarket, explained before. Also, in e-commerce, you can find patterns between products when customers buy products using the website. Additionally, you can check consumption patterns in restaurants like Coke+chips+hamburger and create attractive combos to increase sales. In addition, you can find patterns between genetic mutations and cancer.
Finally, there are other applications like financial fraud (suspicious combinations of transactions), e-learning platforms (content sequence of videos or articles).
Example using the FP-Growth algorithm
For this example, we will use the vAssocSeqLineItems. This is a view inside SQL Server in the AdventureworksDW2019 table.
Adventureworks is a fictitious company related to bikes.

This view contains information about the parts of a bike, order numbers, line numbers, and Models.
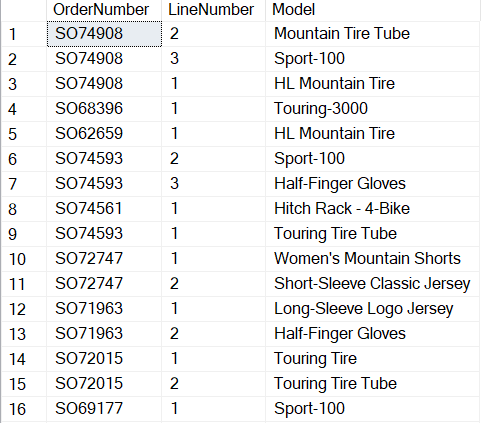
We will work to find patterns between these products.
Writing PF-Growth code
The code to find PF-Growth patterns of our data is the following:
import pandas as pd
import pyodbc
from mlxtend.frequent_patterns import fpgrowth, association_rules
# Connect to SQL Server
conn = pyodbc.connect(
'DRIVER={ODBC Driver 17 for SQL Server};' # Specify SQL Server drives
'SERVER=localhost;' # SQL Server instance name
'DATABASE=AdventureWorksDW2019;' # Database name
'Trusted_Connection=yes;' # Use Windows Authentication to connect
)
# Select data from the view vAssocSeqLineItems
query = """
SELECT OrderNumber, Model
FROM vAssocSeqLineItems
"""
df = pd.read_sql(query, conn)
# Transform to baskedt format (uno-hot encoding)
basket = df.pivot_table(index='OrderNumber',
columns='Model',
aggfunc=lambda x: 1,
fill_value=0)
# Apply the FP-Growth algorithm minimal support = 5
frequent_itemsets = fpgrowth(basket, min_support=0.05, use_colnames=True)
# 5. Generate association rules with confidence = 50
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)
# Show results
print("✅ Frequent sets found:")
print(frequent_itemsets)
print("\n📘 Association rules found:")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])PF-Growth libraries
First, we will explain the libraries invoked:
import pandas as pd import pyodbc from mlxtend.frequent_patterns import fpgrowth, association_rules
The pandas library is used to read the data and convert it to a dataframe. Also, the pyodbc is used to connect to the SQL Server database. Finally, the mlxtend.frequent_patterns library is used to find the patterns of the data.
PF-Growth database connection
The next section of code is used to connect to SQL Server.
# Connect to SQL Server
conn = pyodbc.connect(
'DRIVER={ODBC Driver 17 for SQL Server};' # Specify SQL Server drives
'SERVER=localhost;' # SQL Server instance name
'DATABASE=AdventureWorksDW2019;' # Database name
'Trusted_Connection=yes;' # Use Windows Authentication to connect
)First, we create the connection named conn using the pyodbc library. This connection will use the ODBC Driver 17 for SQL Server. This driver is usually installed by default with SQL Server.
conn = pyodbc.connect(
'DRIVER={ODBC Driver 17 for SQL Server};' # Specify SQL Server drivesSecondly, we will connect to our local SQL Server. In this example, you can add your SQL Server name here, and the database is the AdventureworksDW2019 database. Check the requirements if you have not installed it yet.
'SERVER=localhost;' # SQL Server instance name 'DATABASE=AdventureWorksDW2019;' # Database name Finally, we will provide the Windows Authentication credentials. This means that the current Windows user that is running the code should have access to SQL Server. 'Trusted_Connection=yes;' # Use Windows Authentication to connect
Run a query and load the data
Also, we will run the query. We connected to SQL Server, and now we will run a query on the view vAssocSeqLineItems and load the data into a DataFrame.
# Select data from the view vAssocSeqLineItems query = """ SELECT OrderNumber, Model FROM vAssocSeqLineItems """ df = pd.read_sql(query, conn)
Prepare the data for the PF-Growth algorithm
This is the main part of the code where we convert to a format useful for the PF-Growth algorithm.
# Transform to baskedt format (one-hot encoding) basket = df.pivot_table(index='OrderNumber', columns='Model', aggfunc=lambda x: 1, fill_value=0)
First, we pivot the data and add a 0 if the item is not bought in the transaction and 1 if it is bought.
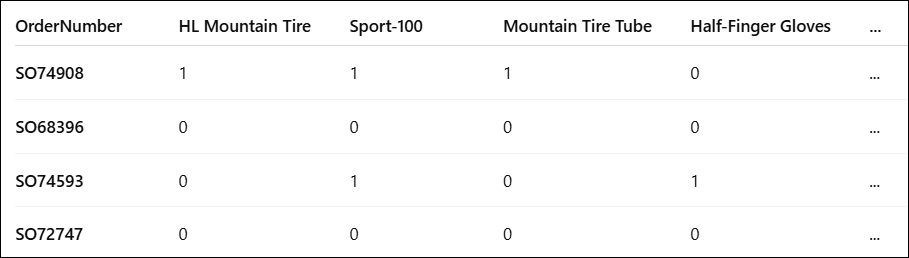
If the value is in the order, the value is equal to 1 (aggfunc=lambda x: 1). Otherwise, the value is 0 (fill_value=0)
Find frequent items and association rules
This section of the code finds the frequent items in the orders and the association rules.
# Apply the FP-Growth algorithm, minimal support = 5 frequent_itemsets = fpgrowth(basket, min_support=0.05, use_colnames=True) # 5. Generate association rules with confidence = 50 rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)
First, we use the fpgrowth function with the minimum support equal to 0.05. This function finds the frequency of the item groups. The basket is the table generated in the previous step. Only keeps combinations of products that appear in fewer than 50 0f the orders. Also, we have the use_colnames=true to use the actual product names.
In addition, we have the association_rules functions. First, we receive the frequent_itemsets values. Secondly, we have the metric ="confidence". Confidence is used to measure how often items in consqquents appear in transactions.
Finally, min_threshold=0.5 means that we are using a confidence level equal to 50 This means that we are only counting rules where the confidence is equal to 50 0r higher.
Print the FP-Growth results
In the last part, we are going to show the results.
# Show results
print("✅ Frequent sets found:")
print(frequent_itemsets)
print("\n📘 Association rules found:")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])We are just printing the results of the PF-Growth algorithm. Let’s run the code and analyse the results.
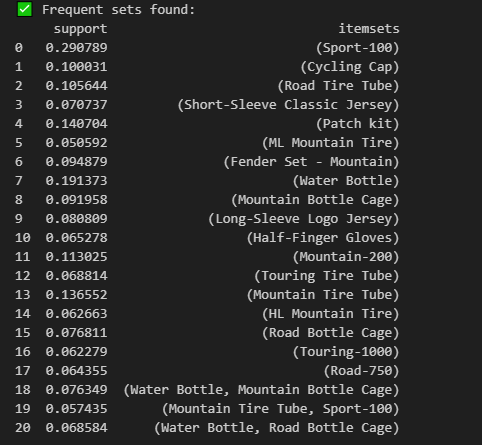
First, we have the Frequent sets found. This will show you the frequency of the items. Support is a value between 1 and 0. If the item sport 100 has a support of 0.29, it means that 29 0f the orders included that item.
Secondly, we have the association rules found.

Also, these results show the related items. In this example, the mountain bottle cage is bought with the water bottle. Also, some items bought together are the Road Bottle Cage and the water bottle. We could create some special combos and offers to increase sales.
As you can see, the code is not so difficult. We can find patterns in our data and find relationships between products.