

Data is the new gold and is truly an asset to any enterprise. As predicted by IDC, the size of the world's data – the Datasphere - will grow from an estimated 85 zettabytes (ZB) by the end of 2022 to 175 ZB by 2025. With the increased volume, velocity, and veracity of data, comes increased complexity in handling it and creating meaningful information out of it.
The Data Fabric is an emerging data analytics concept that has gained a lot of interest in the Data Management community over the last few years and is constantly growing. As per Gartner, the Data Fabric is one of the top 10 Data and Analytics technology trends.
This article provides an overview of the Data Fabric and explains how it differs from traditional Data Management. It also describes the four pillars of the Data Fabric.
Data Fabric Overview and How It Differs from Traditional Data Management
Enterprises need to leverage data to get insights and create analytics. Today, the data sources, structures, types, deployment environments, and platforms are diverse. Data Management is further complicated as enterprises adopt hybrid cloud and multi-cloud architectures. As a result, the operational data store (ODS) and the Data Warehouse are siloed, resulting in an enormous amount of redundant data. This leads to multiple sources and multiple versions of the truth.
Traditionally, an enterprise addresses data integration and access through a data hub or point-to-point (P2P) integration. The cost of P2P integration increases severalfold as a new endpoint is connected, making it an unscalable approach. Data hub provides easier integration of data sources; however, it increases the cost and complexity exponentially to maintain the data quality and trust within the hub. As a result, neither of these two is suitable or scalable for a diverse, distributed, and siloed data environment.
The Data Fabric is like a tapestry that connects data across multiple siloed systems such as on-premises, public, private, or hybrid cloud. It virtually connects the data endpoints and does not require movement or copying data from the siloed system. The Data Fabric ensures that the organization maintains the governance, risk, and compliance requirements as part of any regulation or business strategy. As shown in the picture below, traditional data management follows a "Collect" concept, which requires copying data from the source system into an ODS or a Data Warehouse. On the other hand, the Data Fabric follows a concept of "Connect," where it only connects to the source systems without making an additional copy of data.
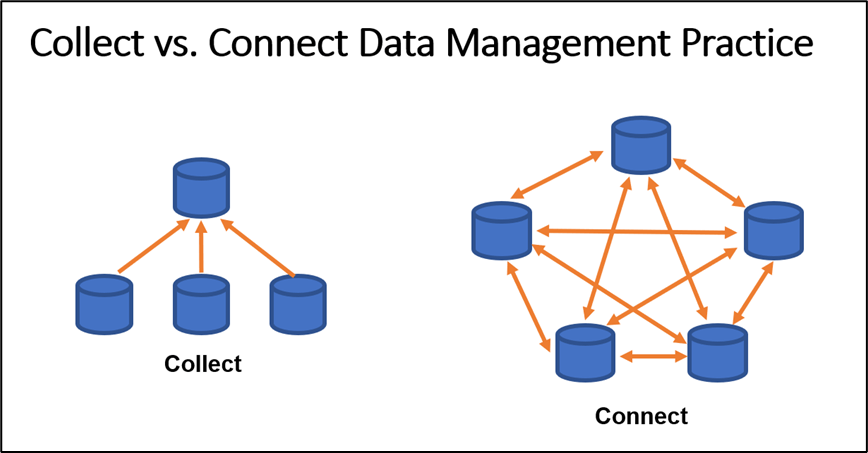
In simpler terms, the Data Fabric follows the concept of "Connect" instead of the "Collect" that the traditional Data Management follows.
Pillars of the Data Fabric
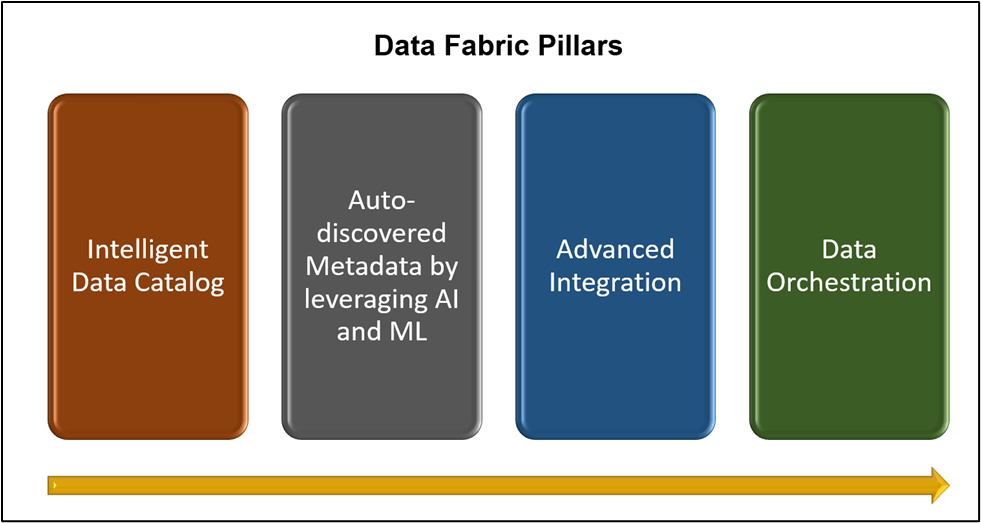
The Data Fabric has four pillars. Together, these pillars provide the capabilities needed to enable the business value out of the Data Fabric implementation using specialized software. The four pillars of the Data Fabric are as follows:-
- Intelligent Data Catalog
- Auto-discovered Metadata by leveraging AI and ML
- Advanced Integration, and
- Data Orchestration
As shown in the picture below, these pillars are implemented from left to right.
Intelligent Data Catalog
This pillar consists of the advanced feature of the logical data model, data dictionary, and their relationship with each other using Taxonomy and Ontology. It creates and maintains the data asset inventory by automatically discovering data source connections across multiple siloed systems. It also automates manual tasks such as data cataloging, data discovery, semantic relationship creation, etc., to give data consumers faster access and quicker data comprehension. Data consumers can use the Intelligent Data Catalog to understand the data context and identify data elements to extract meaningful information, knowledge, and analytics.
This pillar also creates the Taxonomy and Ontologies of the Data elements.
- Taxonomy helps with adding the hierarchical relationship between different data elements. The taxonomy does not include the nature of the relationship between the data elements. For example,
Insured > Customer > Claim
- Ontology further enhances the Intelligent Data Catalog by adding the essential nature of the relationship between the different data elements. For example
Insured > is a > Customer> has a > Claim
This pillar loads metadata into a graph database and generates or updates the knowledge graphs using taxonomy and ontologies on the connected metadata. To query the knowledge graph, you can use SPARQL or other built-in search engines, which have Natural language query (NLQ) features. SPARQL is a semantic query language for databases. If you would like to learn more about SPARQL, Apache has a good tutorial at Apache Jena - SPARQL Tutorial - Data Formats
Auto-discovered Metadata by Leveraging AI and ML
Most organizations use technical metadata mainly for troubleshooting. However, in the context of a Data Fabric, the technical metadata can enhance data provisioning capabilities by
- Collecting different forms of metadata to bridge the metadata siloes
- Using Graph Analytics to identify both direct and inferred data relationships.
Auto-discovered metadata leverages Artificial Intelligence (AI) and Machine Learning (ML) capabilities to enrich data sources automatically. AI and ML enable recommendations for new data sources based on usage patterns. To maintain better performance, this pillar can convert virtualized views to persistent views. When performance is not an issue, this pillar can convert persisted views to virtualized views to save cost.
Advanced Integration
This pillar of the Data Fabric is responsible for data preparation and identification of the data delivery mechanism. This pillar extracts, virtualizes, transforms, and streams data to enable data consumption. It is integrated with the knowledge core to automate data integration. It also has the built-in intelligence to decide which integration approach is best suited based on workloads and data policies. It automatically determines best-fit execution through optimized workload distribution.
The Data Fabric, through Advanced Integration, supports different data latency needs. Data Latency is the time it takes for data to become available to the end user after an event occurs. Examples of varying data latency needs are as follows: -
- High Latency - for batch jobs and data migration.
- Low Latency - for data stream integration and near-real-time change data capture (CDC)
- Variable Latency - the capability to switch between event-driven and schedule-driven
The Data Fabric also supports data delivery styles, such as virtualization, replication, and batch data delivery.
Data Orchestration
Data Orchestration is a key pillar of the Data Fabric that centralizes data operations visibility and control. It transforms, integrates, and delivers data to data consumers in support of different data analytics use cases. Data is delivered to the consumers using data pipelines. A data pipeline is a sequence of data processing steps used to automate the movement and transformation of data from the source system to a destination for analysis. During this process, the data undergoes transformations, including but not limited to filtering, masking, and aggregation. Data Orchestration provides agility and consistency to optimize the process, collaboration, and data communication. After the deployment, the data pipeline goes through continuous monitoring for optimization.
This pillar also applies the concept of DataOps to ensure a smooth data delivery flow. Gartner defines DataOps as a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and consumers across an organization.
Summary
This article provided an overview of the Data Fabrics and explained how it differs from traditional data management Practices. The Data Fabric fundamentally differs from traditional data management as it aligns with the "Connect" concept instead of the "Collect" concept. The article explained the four pillars of the Data Fabric, each of which is realized using specialized software. Please note that the Data Fabric is still in its infancy and is an emerging and evolving concept. As a result, the Data Fabric capabilities are still immature. Each vendor has a different viewpoint on how the Data Fabric works.
