

In working with Azure DevOps, one of the challenges is to ensure that our processes can connect to systems, but not unnecessarily disclose credentials. While performing deployments with an automated process, we often allow many people to access and change the pipeline, but we may not want everyone to be able to see the actual users or passwords.
In this article, we will look at one way to store and protect the credentials in a project. A future article will look at how we might do this across multiple projects.
The Release Pipeline
When we go to deploy code to a database, we need an account with which to connect to the database and credentials to allow access. We may need this in multiple places, as I can show in an example pipeline. Here you can see that I have a few pipelines in this project. Not many clients have these, but a few do for different processes.

Inside these, I can have multiple stages and environments. In this example, I have a number of different environments listed, each of which has multiple tasks.
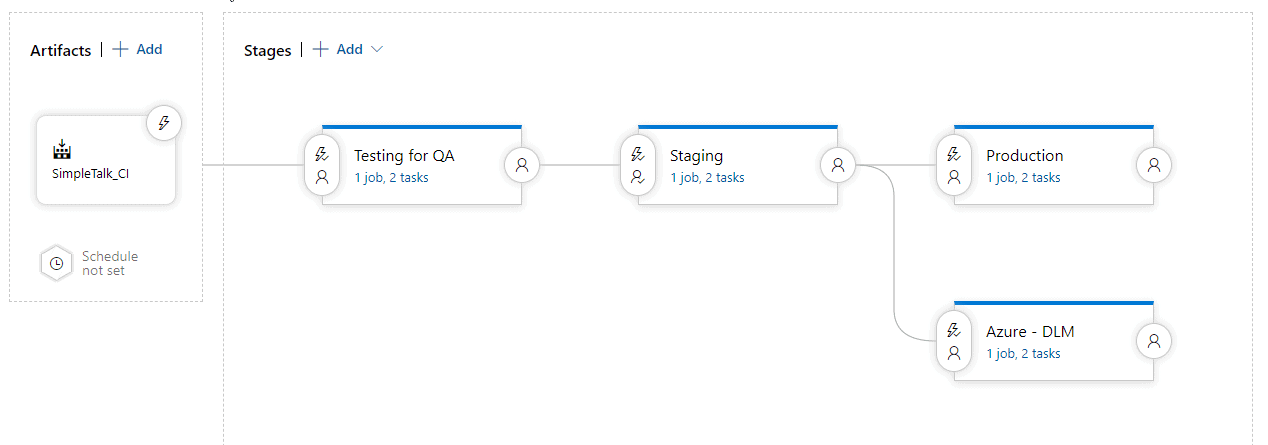
Any of the tasks in these stages might need to connect to a resource using credentials. While we may allow developers to edit these states, we don't want to expose credentials unnecessarily. Let's look at a simple system for keeping control of names and passwords.
Using Variables
When setting up this type of flow, often someone in infrastructure of operations has control of the credentials. They may create the login in SQL Server and keep track of it. In some places I've worked, the operations person would give me the credentials. In others, they'd enter them personally whenever I needed them inside a process. With Azure DevOps, we can come up with a compromise.
If I edit the pipeline and choose a state, I see the editor shown below. Notice there is a Variables item at the top.
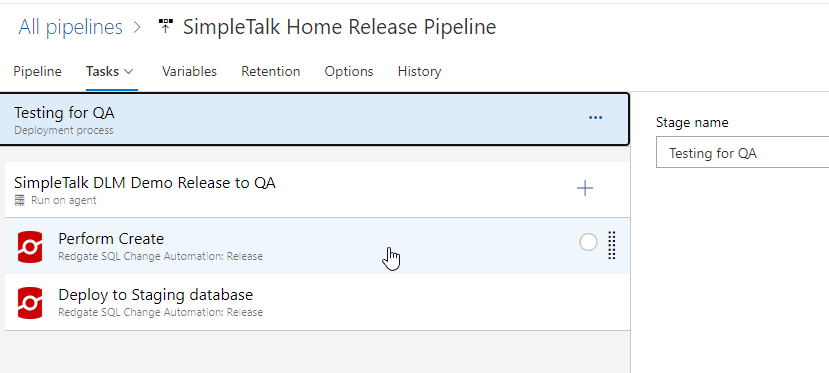
These variables are for all stages in this pipeline. I can see this, as the Tasks item has a drop down. I can choose any of the states, but I have the same list of variables.
Variables are what we might expect. I can declare a variable and give it a value. I can then use this in my pipeline. For example, here is my variable list right now.
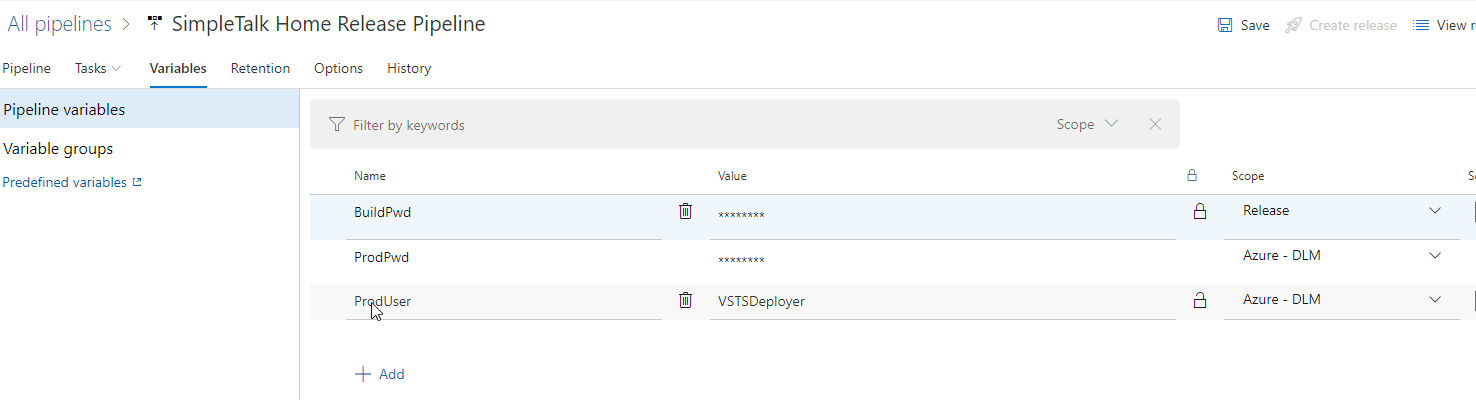
I have 3 variables here: BuildPwd, ProdPwd, ProdUser. Of these, I can see the value of just the ProdUser, which is set to "VSTSDeployer". The other two are secret, which means I cannot retrieve the values. I can set a new value, but I can't see what's there. Azure DevOps will substitute this in my task as a value for me, providing security.
Let's create a new variable and see how this is substituted into a task. If I click the "add" at the bottom, I can get another line in this table to add a variable. In my case, I'm going to add "BuildUser" as the name of the variable, and "VSTSBuildAgent" as the value. You can see this below.
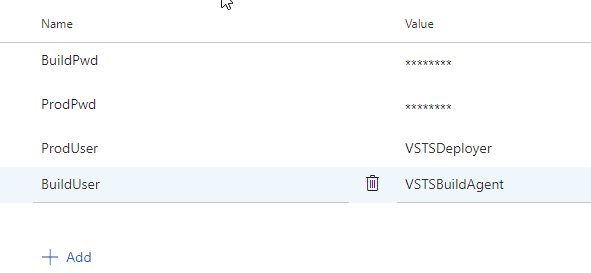
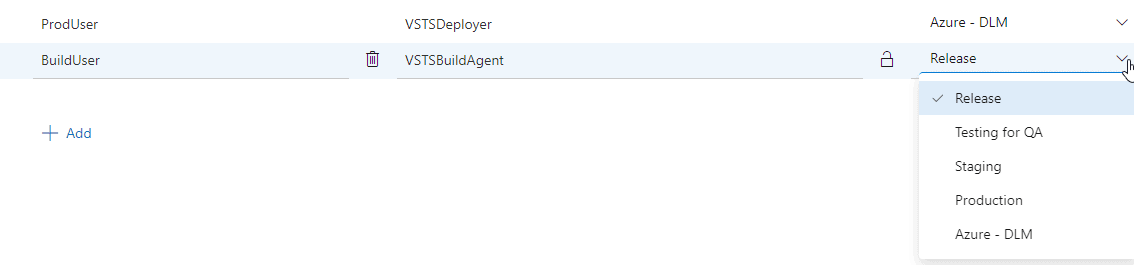
If I made a mistake and didn't want this variable, I would click the trash can icon next to the name.
To the right of this, I have a scope drop down. By default, this variable is available in all tasks if I leave the scope as Release. If you look a couple images above, you will see a few variable are limited to the production task only.
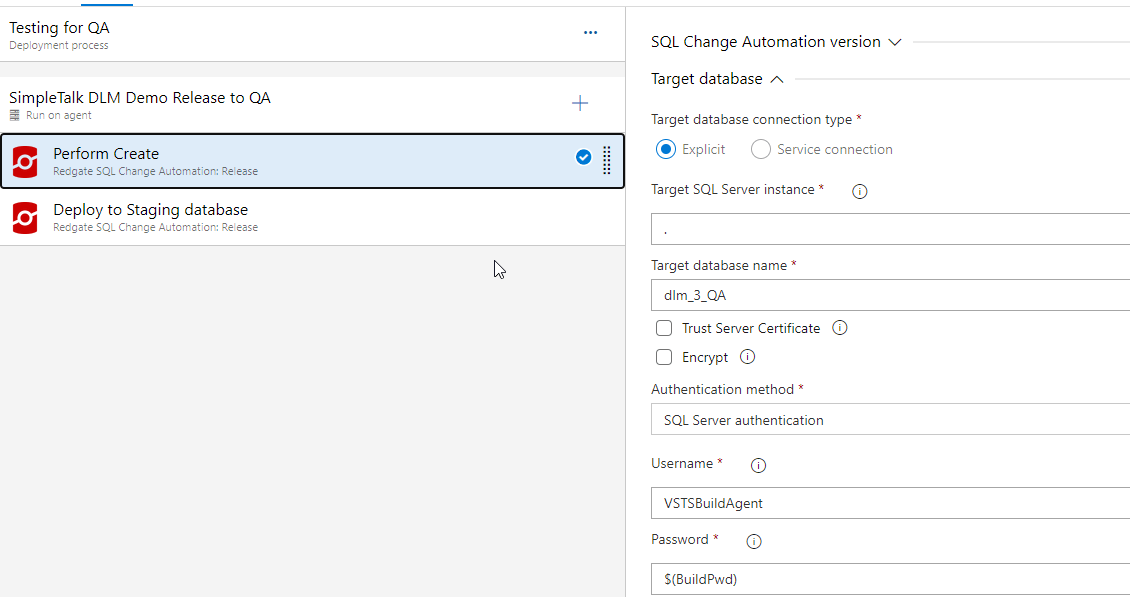
Once I do this, I can use the variable in a task. In this case, when the pipeline was set up, the actual value was put into the task. If you look below, on the right, the Username item has a hard coded value in the text box.
I want to replace this with my variable. I do that by using a dollar sign ($) and then enclosing my variable name in parenthesis.
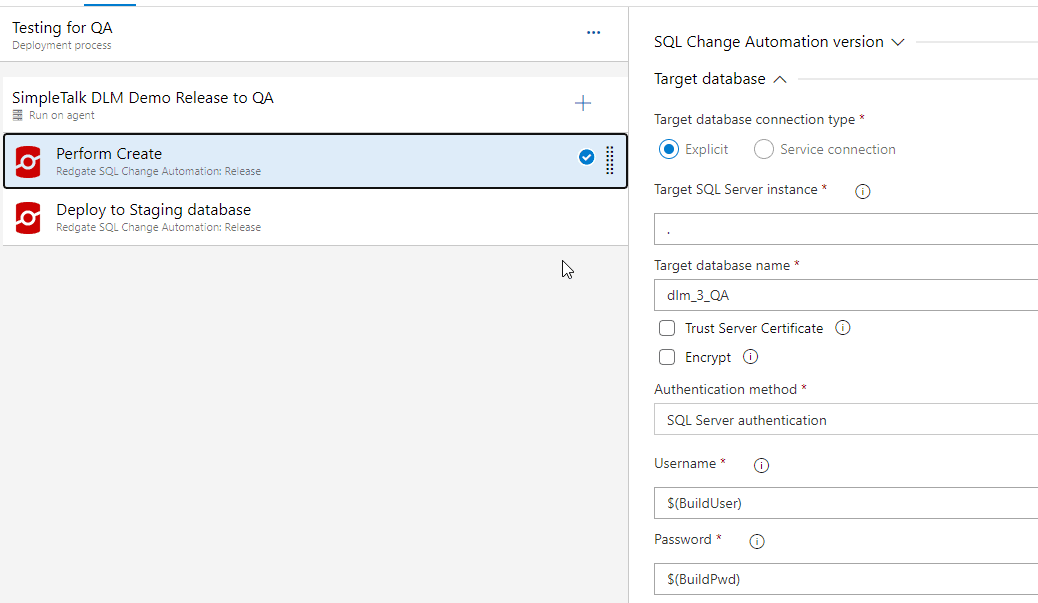
This matches the pattern for the Password. Any variable I then create follows this pattern, as do the build in variables provided by Azure DevOps. I can now use this variable in any task in the release, replacing any hardcoded values. If we add new tasks where this is applicable, I can use this again. In this case, I have this same login in the "Deploy to Staging Database" task and in one other task.
I can save this, and return to the variables page. I can still see the variable value when I do this. If I click the "padlock" icon next to the value, the value is replaced with asterisks.
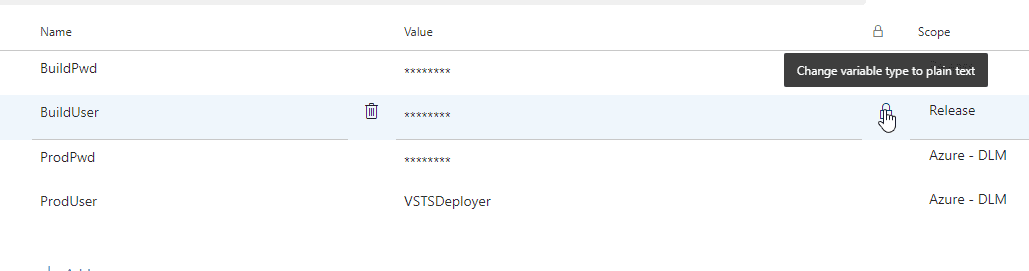
The tooltip shows changing this back to plain text, but I can only do that before I save the pipeline. If I clicked this by accident, I click it again. If I save this, then the value cannot be retrieved. If I edit this pipeline and wanted to change this value, or set it to plain text, I would need to re-enter the value.
This is the end of a quick look at using variables for credentials.
A First Step
When you first start to build automation, we often just hard code values into parameters or scripts. This is a good way to test things, but once we get a process that others may use or expand on, we often want to use variables when we need secret values, or we need items in more than one task. It's much better to store things in one place for future maintenance, so using variables makes sense.
This works well for smaller orgs, with limited automation. However, there are two other ways to handle these items, which are more advanced, but slightly better choices. The first is variable groups. In the images above, you can see the "Variable group" item to the left. These are places I can use variables, but across different releases and projects. If I use these, I can have users across pipelines use them, and I can also use them in YAML pipelines.
The second way to store secrets is to use Azure Key Vault. This is a separate key-value store that is designed for sensitive information.
I'll look at both of these in future articles.
Summary
This is a quick look at how you can manage credentials in a safe way and make them available in your pipeline. You can limit their scope to a particular stage, or they can be available for all stages.
Using variables makes sense whenever you need the same information in multiple places. Having this stored in a variable simplifies your task maintenance over time and prevents multiple typos or extra work when something changes. I would urge you to use these to in your pipelines as much as possible.
