

Introduction
Usually, when a view is created in the SQL Server database, it is just a virtual table (not stored on disk) that might fetch results from one or more underlying physical tables (stored on disk). Views are mainly created to maintain security on the tables, perform pre-aggregated calculations or limit the query to specific columns in the tables. Often at times, there can be complex logic that might be executed multiple times. SQL views also provide an encapsulation layer for such complex logic without the end-user having to know about it.
Views read data from the underlying tables and/or views, which can take many IO operations. It is not advisable to execute a standard view with complex logic and joins between high numbers of rows from a combination of tables multiple times as it might affect the performance of the database. This is because standard views are just designed to execute the underlying query without any performance optimization. That means every time a standard view is executed, the database engine has to perform the heavy lifting and build up the execution plan and compute the result set.
In order to enhance the performance of such views, we can create something known as an Indexed View in SQL, also sometimes referred to as a Materialized View. An indexed view is simply another view that creates its physical existence on the disk by creating a unique clustered index on one or more columns used in the view. When this view is executed, it refers to the clustered index instead of the underlying tables and thus is able to increase the performance of the view to a good extent. Another important aspect of creating such views is that other queries that don't use the indexed views can also benefit from the existence of the clustered index from the view.
There is also some cost involved in creating and maintaining an indexed view. When an indexed view is created, every time the data in the underlying tables are changed, the database engine has to update the clustered index entries for both, the tables and also for the view.
In this article, we will create an indexed view and also compare the performance of the indexed view to that of the original query used in the view.
Solution
For the sake of this tutorial, I'll be using data from one of my production databases. So, I'd refrain from displaying any user sensitive information and focus only on the queries and performance.
Preparing the query
I have a normal fact table - FactSales that stores information about sales, the customer, the item sold, quantity and the total sale amount along with some other information. Over a period of several years, this table has grown to a humongous size and has more than 2M records in it. There is a clustered index created on the primary key of the table - PK_FactSales. On top of this fact table, I have a view - vwOlapSalesAmount, and it aggregates the number of items purchased by each customer in a sale and the total sale amount for that sale. The definition of the view is provided below.
CREATE VIEW vwOlapSalesAmount AS SELECT FactSalesHeaderID ,CustomerID ,COUNT(ItemID)AS ItemsPurchased ,SUM(SalesAmount)AS SalesAmount ,COUNT(*)AS TotalSales FROM dbo.FactSales GROUP BY FactSalesHeaderID ,CustomerID GO
Let me write a simple query and fetch a the columns.
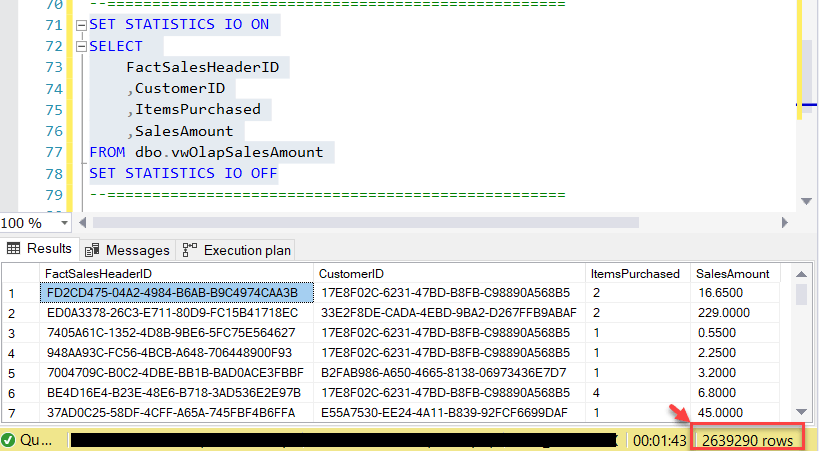
As you can see in the figure above, I have fetched the columns - FactSalesHeaderID, CustomerID, ItemsPurchased and SalesAmount from the vwOlapSalesAmount view.
Now, let's see the statistics and also the Execution Plan details for this query.
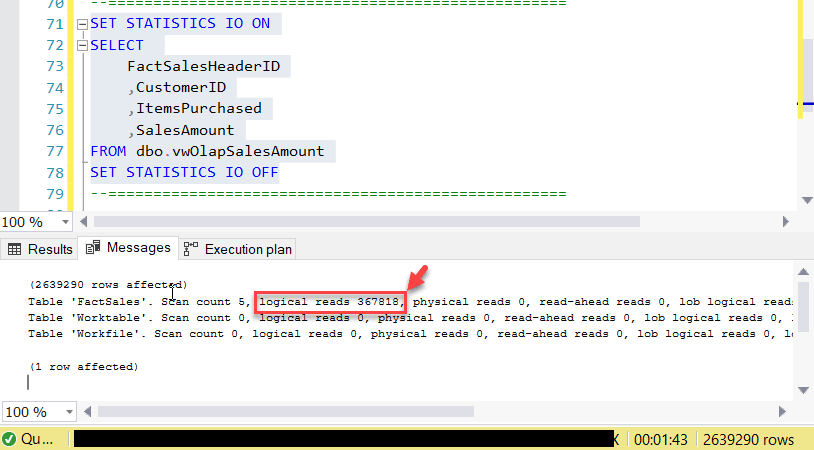
In this figure, you can see that the number of logical pages read by the view was 367818 and it fetched 2M+ records.
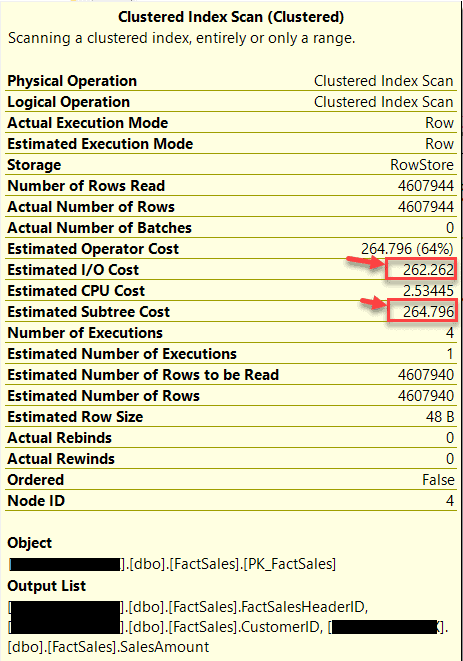
If we take a look at the execution plan in the figures below (Fig 3 and Fig 4), notice that the operation was a Clustered Index Scan on the Primary Key of the base table - i.e. FactSales. Also, another important items to keep an eye on are the Estimated I/O Cost and the Estimated Subtree Cost which are 262.262 and 264.796 respectively.
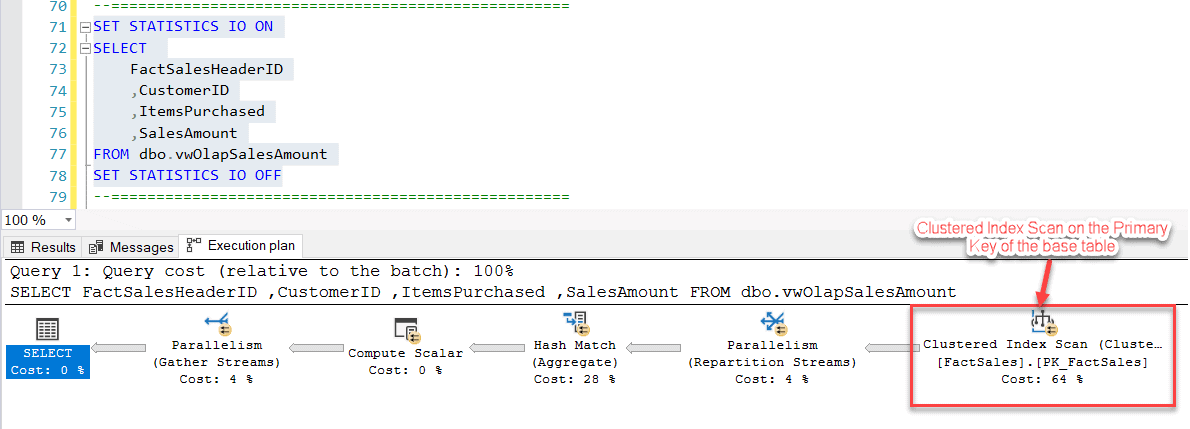
Fig 3 - Initial Query (Execution Plan)
Preparing the Indexed View
Now, let's modify this view to an indexed view which will return the same result. We will also create a unique clustered index for the FactSalesHeaderID field which will be used by the view for fetching results.
In order to create an indexed view, it is mandatory to bind it with the table schema so that the underlying table structure cannot be altered after creating the view. Also, while creating index on a view, it is mandatory that we use COUNT_BIG function, instead of COUNT in order to count any group of records. You can read more about the COUNT_BIG function from the official documentation.

The script for modifying the view along with the clustered index is provided below.
ALTER VIEW vwOlapSalesAmount( FactSalesHeaderID ,CustomerID ,ItemsPurchased ,SalesAmount ,TotalSales ) WITH SCHEMABINDING AS SELECT FactSalesHeaderID ,CustomerID ,COUNT_BIG(ItemID)AS ItemsPurchased ,SUM(SalesAmount)AS SalesAmount ,COUNT_BIG(*)AS TotalSales FROM dbo.FactSales GROUP BY FactSalesHeaderID ,CustomerID GO CREATE UNIQUE CLUSTERED INDEX IX_FactSales_SalesAmount ON vwOlapSalesAmount(FactSalesHeaderID) GO
Now that the indexed view is ready, let's execute the initial query to fetch results from this view.
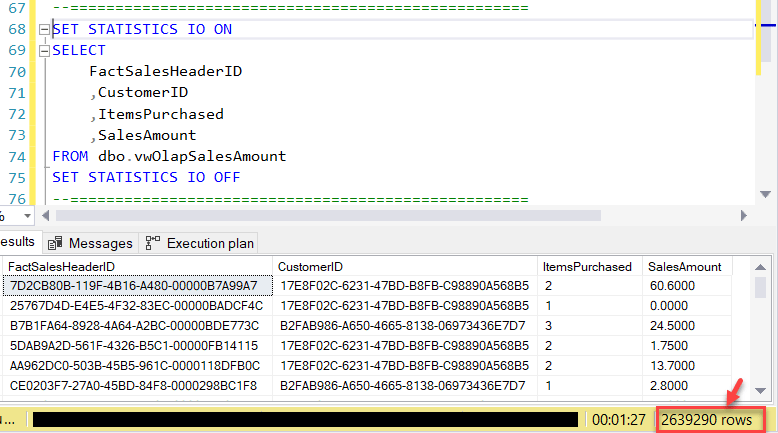
Moving on to the statistics and the execution plan in the next steps.
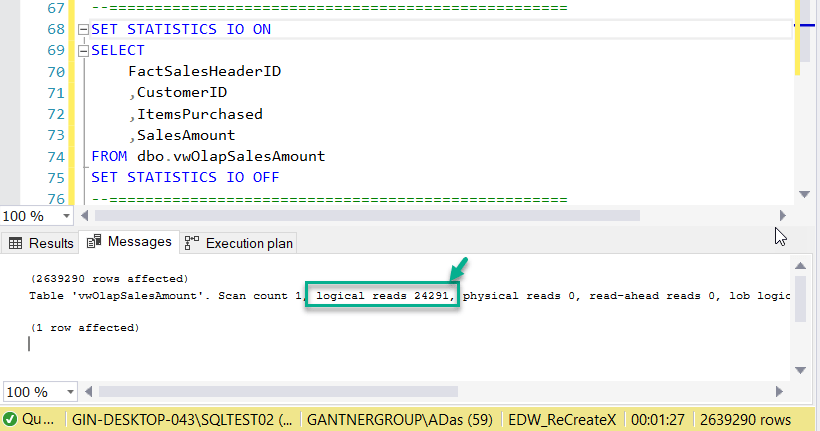
As you can see in the figure above, for the same number of rows (2639290), the number of Logical Reads has reduced drastically to 24291 which is clearly less than one-tenth of 367818.
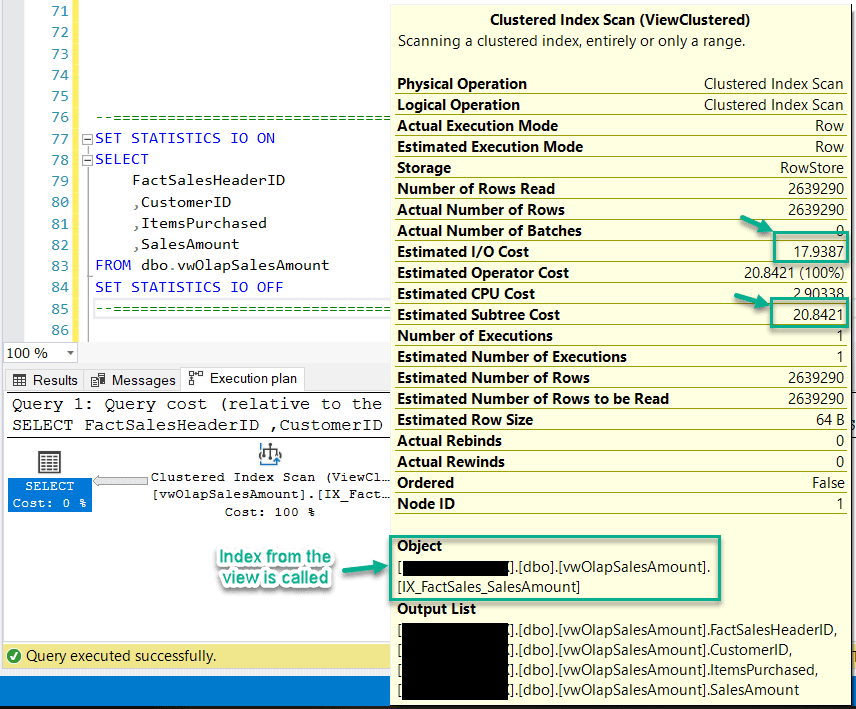
Similarly, if you take a look at the execution plan of this query, then it is evident that the operation performed here is a Clustered Index Scan on the view (IX_FactSales_SalesAmount) as opposed to the clustered index in the previous query (PK_FactSales). Also, notice how the values for Estimated I/O Cost and Estimated Subtree Cost has also reduced to 17.93 and 20.84 respectively. This is sufficient to prove that the performance of the query has now been improved after the view has been indexed.
But there's more to this, let's see what happens if we execute the original query now...
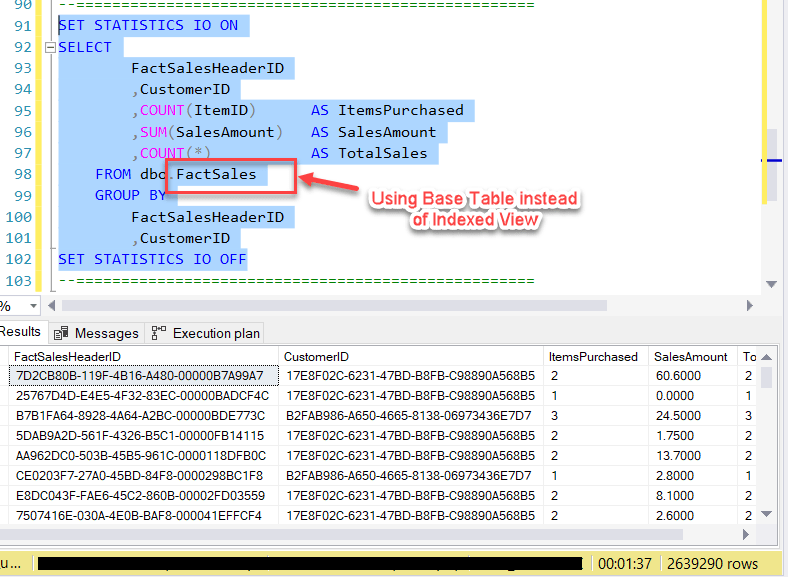
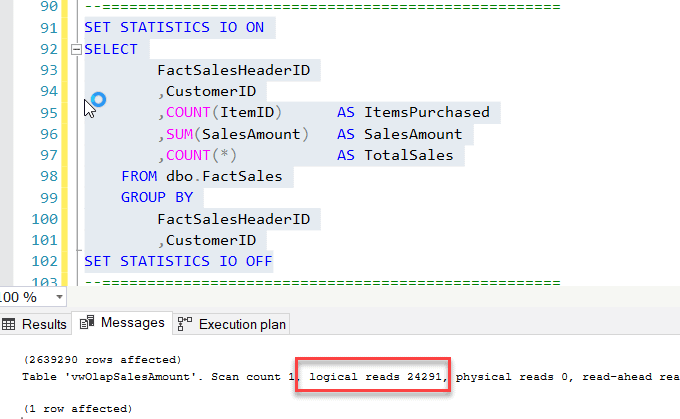
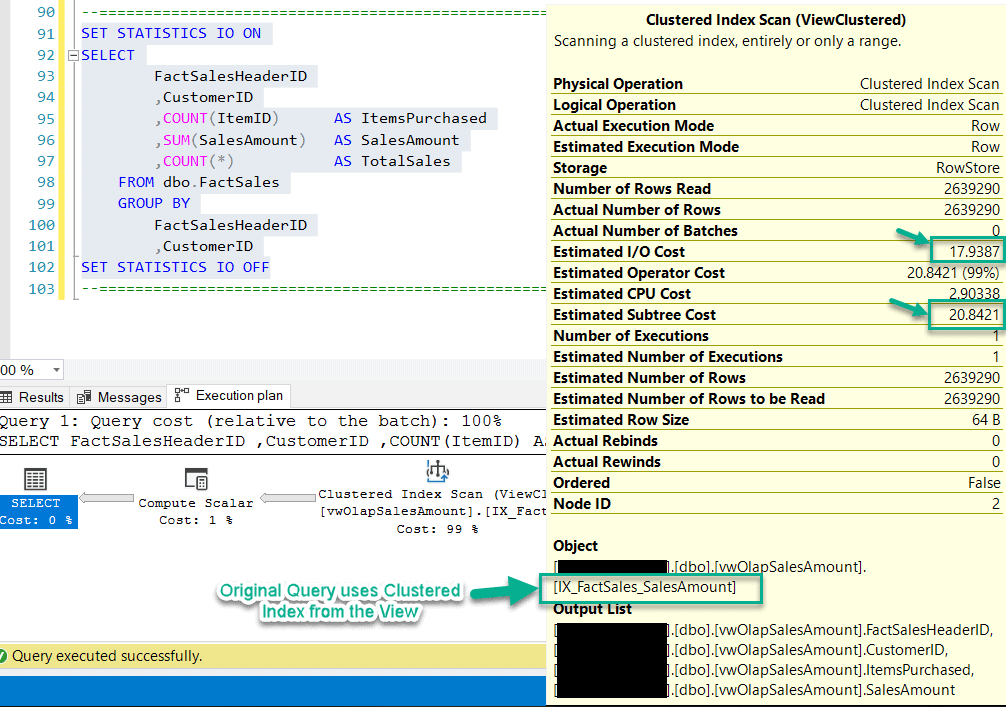
As you can see, the same query now uses the Clustered Index from the view and not the Primary Key Clustered Index, as it used earlier. That's an amazing query optimization technique by the SQL Server database engine. However, this feature is only limited to the Enterprise Edition of the SQL Server.