

In Part 1 of this series, we talked about the art of data ingestion where we discussed the first steps you would put in place when you're ingesting data. In the second article, we looked at technical considerations that can set you up for success. In this third article, we'll discuss a dynamic file load solution using Azure Data Factory. Though this may not be a solution you implement, I hope it gets you thinking about data ingestion and dynamic loading and helps you look at an existing process you oversee or a new process you're creating with a new perspective.
In 2010, I wrote an article called Dynamic ETL with SSIS. This concept and design made my life and many others on my team at my work’s lives so much easier. We went from fiddling around with SSIS packages, their security, their parameters, debugging, and the learning curve of understanding them to creating something that basically never needed to be touched. We were all familiar with SQL code because we had to write it, test it, and use it on a daily basis, but when it came to SSIS packages we always felt rusty and unfamiliar.
Though there are organizations that have huge package farms, many organizations use a handful or more of packages for their projects. What this means is that each time you're in SSIS, you have to get familiar with the deep complexity that can exist within these extensively designed tools. My solution allowed us to keep the guts of what we needed in our ETL process (and really this concept converted it to an ELT process) in the database and in the SQL where we were familiar and use SSIS as the shell I needed it for (importing data). I wanted to revisit this concept now, ten years later, as recently I’ve been thinking about whether it would still apply in a cloud world. And the answer is yes AND no.
I recently came up to speed on ADF Pipelines, and they are definitely not SSIS packages. The cloud has brought a whole new world to data ingestion, and it is so much easier. The ease of use meant I could get data into the database quickly and the tools are great at intuiting how to handle my data. Security is much easier and I'm not spending tons of time on configuration packages or minute security details. My initial thought when I started working with them is that I definitely don’t need this dynamic ELT concept anymore.
Once I was over the hump of initial relief, I realized – wait, you can still have a huge number of pipelines (making things unwieldy) and you still need to rely on people to understand pipelines in addition to SQL (see above example about SSIS package understanding). You still need to figure out where something errored and how you’ll restart in your process. It’s intuitive to do basic things, but sometimes just like SSIS packages, they can get complicated quickly. So, I set out to test out my dynamic ELT process again with ADF pipelines. It works – though not for all file types, and I’ll discuss that more.
Why You Should Use This Design
I'm a big fan of Azure Synapse. It has solved a common problem for us all: the movement of the data. In Synapse, we query files from their location as if they are a SQL table, effectively removing the idea of moving data at all. Database engineers can spend a lot of time on the movement and transformation of data. Depending on the tool we use, the process can require specialized time, effort and monitoring to make sure the flow of data is smooth and error free. My goal with my ELT solutions has not only been to have a seamless process, but to have a process that can be easily understood by other developers, informative about what has happened and what it expects to happen, and communicates when there are problems. When there are problems, I want the solution to be easy to find and to fix. Is that too much to ask?
Having a dynamic design in your database allows you to work in a shared and common language, SQL. The idea of not having to fiddle with SSIS packages, ADF Pipelines, or tracking down errors in obscure places is dreamy. Personally, I would use Synapse before any other tool because of it's ease of use. However, maybe you are converting from SSIS packages to ADF pipelines and you have A LOT of files that you’re loading. Then my solution might be a good solution for you. Another reason may be that your code base is tightly controlled. Maybe it’s easier for you to add data into your database than it is to check in code. If you’re able to add data more easily than propping code, you could essentially extract and transform data without checking in code (this is if you’re inserts into the database are not in code, which often they are as well). Even if you do need to check in data insert code, it’s easier to script a data insert than create a pipeline and move it through the test cycles.
With this solution, you can also avoid having multiple pipelines that essentially do the same thing – download data. You can parameterize your pipeline to retrieve the files that you need to insert into the database from a table. If you load them all flat, then every file, no matter what the field format, can be loaded in at once at the same time. If there are issues in your data files, you can more easily manipulate the data to deal with those issues instead of changing packages and pipelines to bob and weave around data issues.
The scenario in which I would use this concept would be if I was loading a lot of flat data files now, there was minimal filtering of the data and I foresaw additional files to load in the future. This design pattern allows you to more easily implement data imports without the additional overhead of pipeline creation.
Lastly, whenever there is dynamic SQL, people get nervous. I get it. SQL injection is no joke. However, there are a number of different ways to protect and isolate dynamic SQL. One is to create a schema specific to ELT stored procedures and only grant access to this to a managed identity.
Why Not Use This Design?
There are a lot of really good reasons to NOT implement this concept. The underlying concept behind this is that the file needs to be loaded flat and these days there are many different file types, many of them binary. These compressed filetypes mean you can load a lot of data quickly and not have to store giant files. Azure Data Factory WANTS to help you break your file into the data fields. And though you can work around that desire for flat files, for other types like Parquet or JSON, it’s not possible.
But if you are using Parquet, generally you have a large data set so you also may want to add additional filtering into your ADF pipeline and may want to limit the data you load. In that case, you are looking at an ETL process, not an ELT process. Which brings me to the second reason why you wouldn’t want to use this concept: there’s a good reason you’re doing an ETL process. You want to filter the data before it gets added to your database. This is not the process for you.
Azure Data Pipeline Creation
So, without further ado, let’s start with our basic Azure pipeline to load our data in flat into our database. I won’t go through the steps of creating the Azure storage account, Azure SQL database, the sample data or parameterizing the linked servers as there are lot of online tutorials about putting those in place. I also won’t go into the detail of how the dynamic field mapping works as that is detailed in the original article and remains the same (with a few small tweaks to some of the stored procedures/functions). However, the code to create the functions and stored procedures is attached with an insert of data representing the three test files as well as three test sample files you can use to test (you'll want to zip these). Remember that your data needs to either be a delimited file or a fixed length flat file, this design only works for those file types.
I have created two linked services in Azure Data Factory:
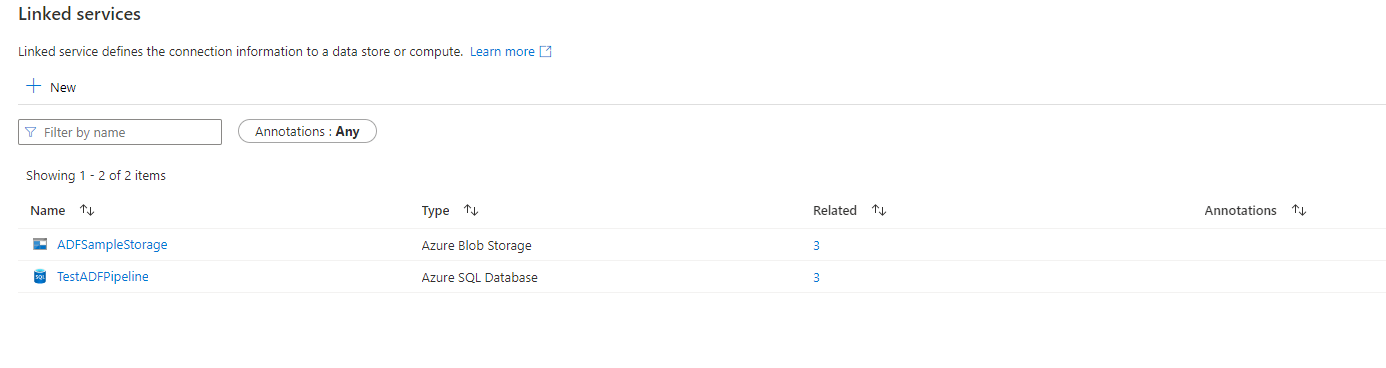
Once I have my linked services in place, I create three containers on my blob storage called: raw and curated (there is is no cleansed because we aren’t cleansing the data in this instance). I’ve uploaded three sample files (zipped) to my rawdata container in my Azure Storage account (a csv, a tab delimited, and a fixed length). These are my containers:
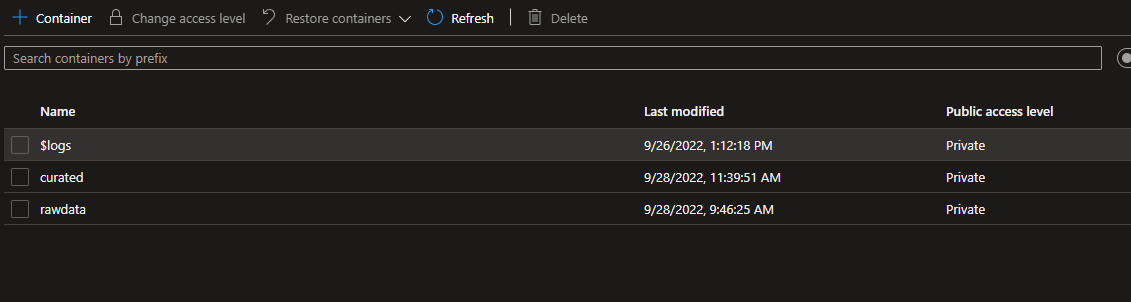
These are my sample files:

Next, please run the TSQL scripts on your database that adds all the tables and stored procedures that are needed as well as inserts into the tables.
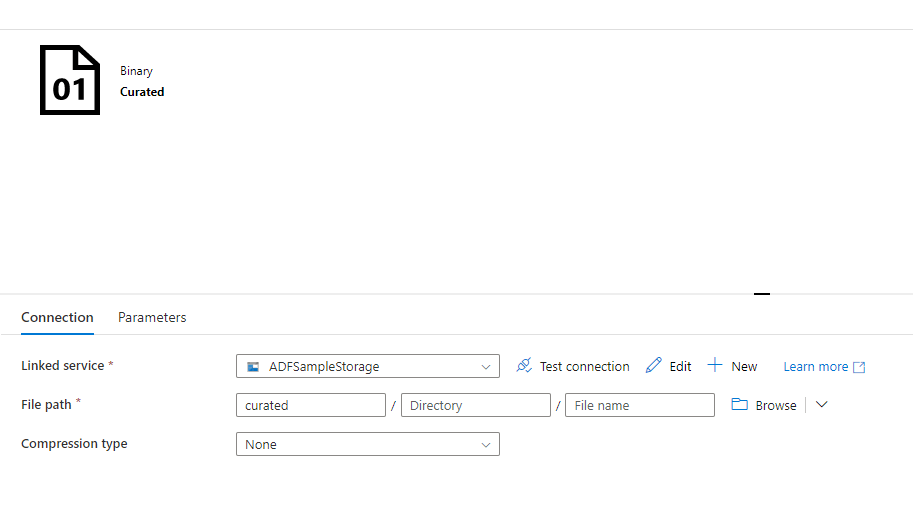
I will create five Datasets in ADF. Two binary data sets that point to the containers rawdata and curated in Azure storage. I’ve called them “Curated” and “RawData”. Here is what the “Curated” one looks like (Raw Data will be the same but point to the “rawdata” container instead):
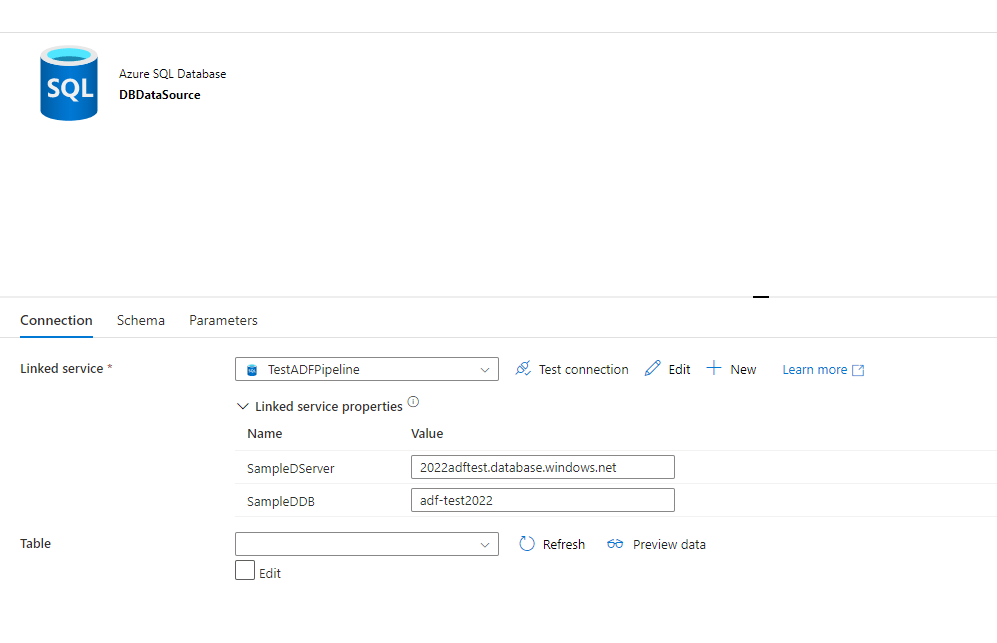
I create one that will point to my database called “DBDataSource”. It does not point to any specific table in the database:
Then I create my FlatFile Data Set called “FlatFileSource”. You will choose a DelimitedText (image shows CSV) as the format. You’ll put your container name “curated” as the container name and nothing else (though if you wanted to only select zip files, you could add *.zip). I use “Start of heading” as my delimiter, because I know my files won’t actually have this delimiter, and this allows me to import the row with no delimiting.
Do not choose “First row as header” as this would be something you would do if you wanted to break your header into fields, which we don’t want to do. If you have a sample file, you can import the schema to make sure that your file is NOT getting delimited.
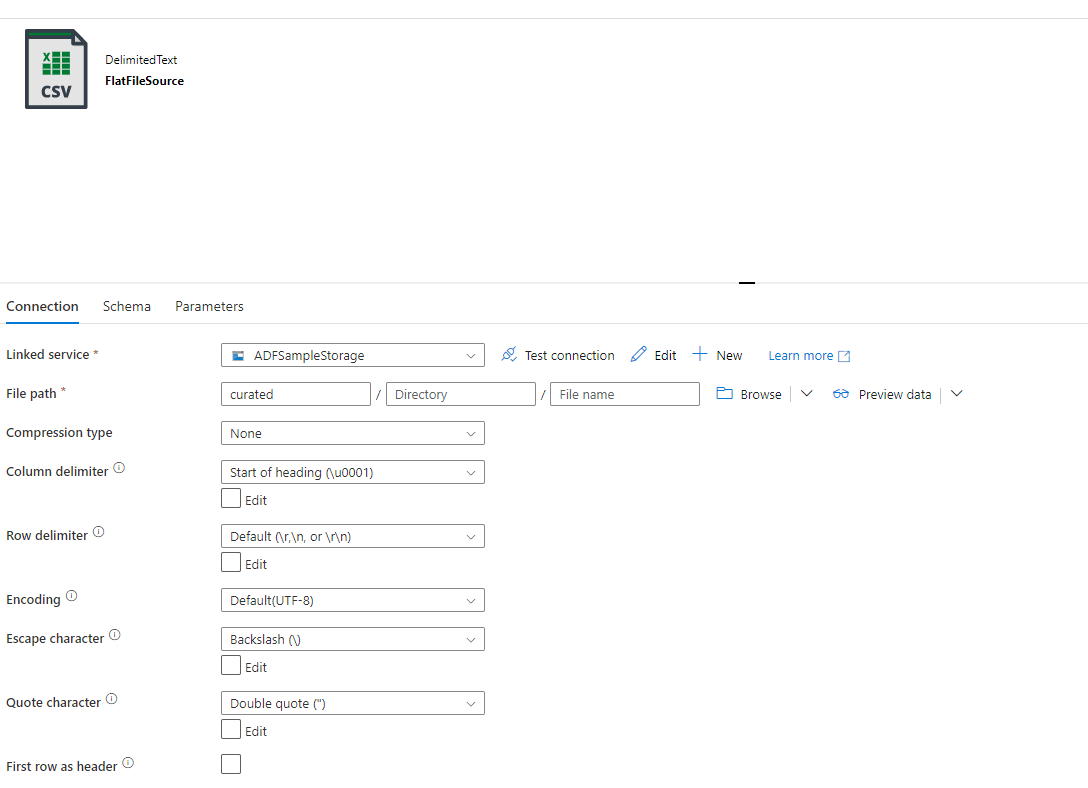
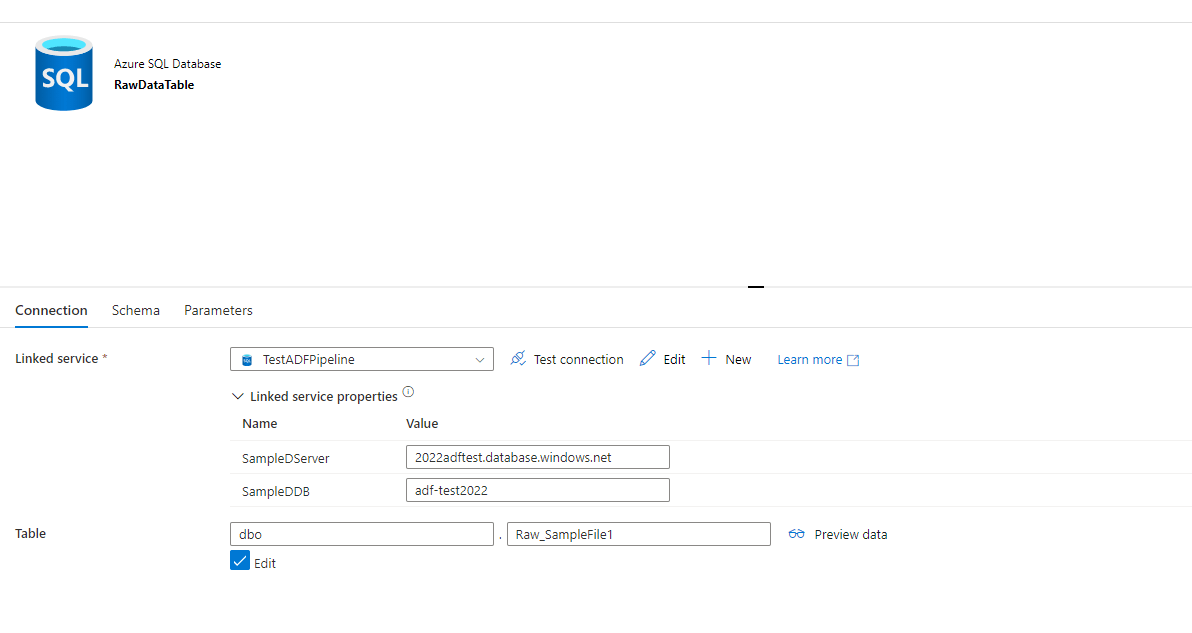
Now we’ll create a Data Set to point to the load table named “Raw_SampleFile1”. This Data Set will be just like your SQL Data Set but this time you WILL add a table (the one you just created). This Data Set is named “RawDataTable”:
Now create your new pipeline. Mine is named “LoadFlatFiles”.
My first step will be to Unzip the files, so I add a “Copy Data” activity that will unzip the files and move the unzipped files to the curated container:
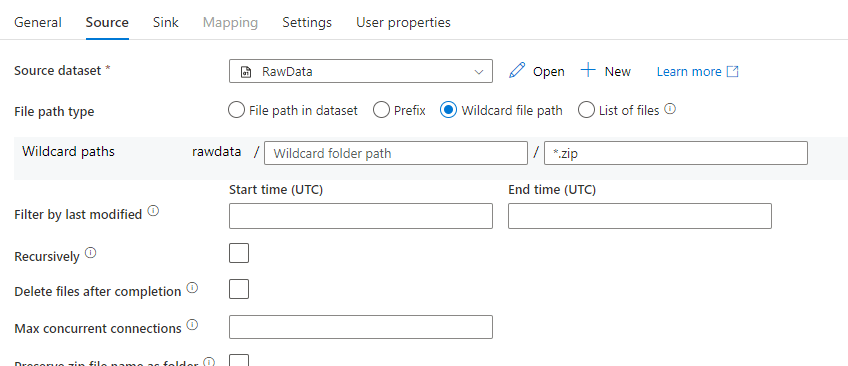
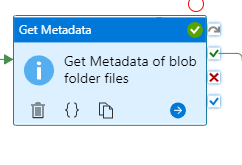
Next Activity is the “Get Metadata” activity. We’re going to grab all the file names from the curated folder:
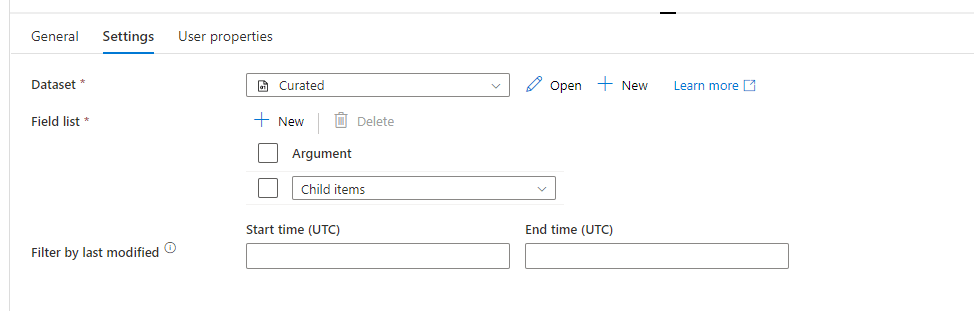
Now we’re going to load one file at a time. So we add a “ForEach” activity that takes the names of the files as an input:
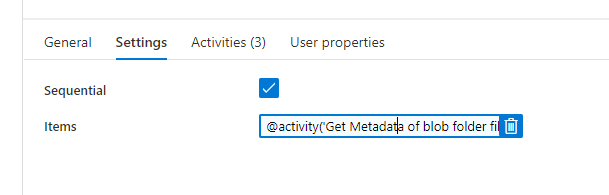
Your items should be dynamic:

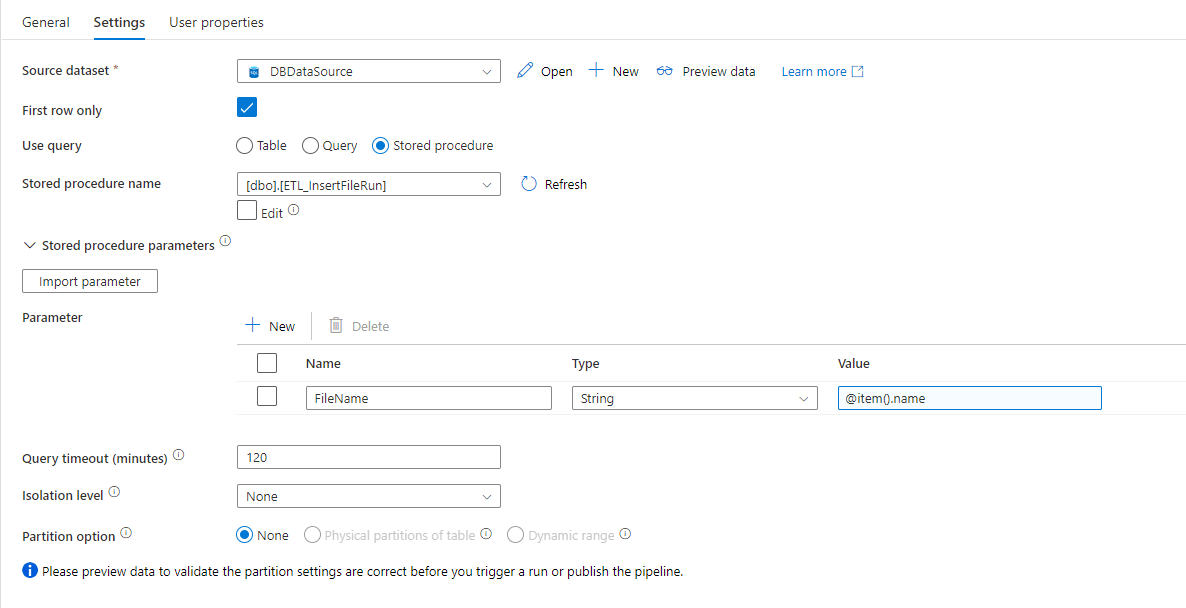
Now, within this ForEach loop, we add a new “Lookup” activity to create our run. This will call the stored procedure “ETL_InsertFileRun” :
Add a “Set Variable” activity. We’re going to set a Boolean variable to indicate whether the run was created for this file. It wouldn’t be created if the file had already been processed or didn’t exist as an active file in our ETL_ImportFile table to be run:
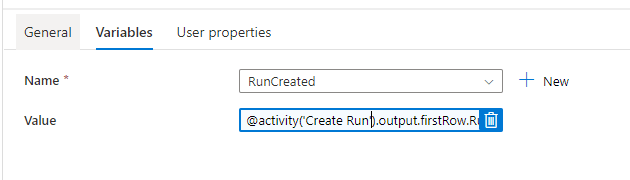

Next we’ll add an “If Condition” activity to load only files where we’ve created a run:
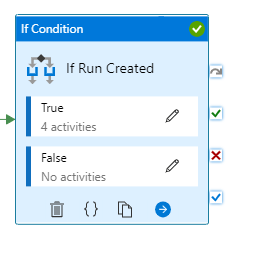
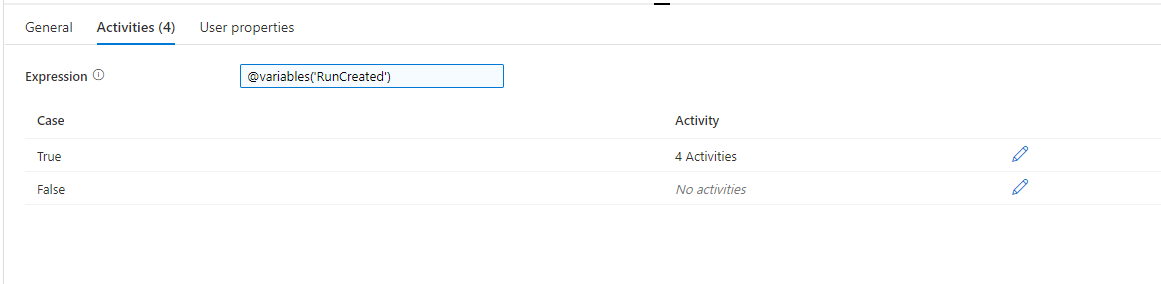
Now we want to add activities to the True part of our “If Condition” activity. The first activity will be to add a “Stored Procedure” activity that will create our destination table for this file type. Depending on how you want to do your loading, you may not want to have this activity and you may want to have your destination tables be set. It’s possible to load into your destination tables over and over. However, one thing to be aware of is that if you have issues with any of your data, you’ll need to be able to separate any bad data from the good data.
So, I prefer to have my destination table cleared and re-loaded. If you do load to your destination table over and over, I would recommend adding a FileId to the data that is loaded so you can differentiate where the loaded data came from. This is a good idea no matter what and an easy item to implement as part of the process.
We created our stored procedure activity that will dynamically create destination tables :
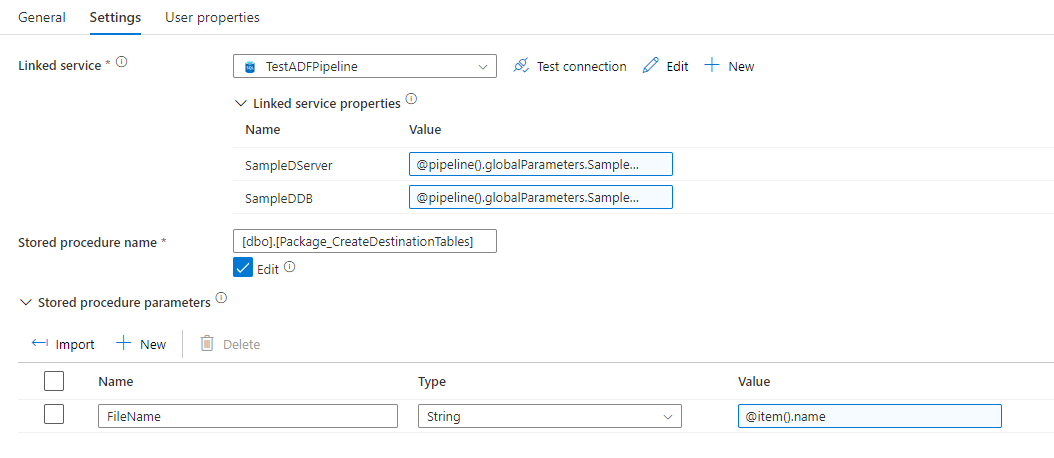
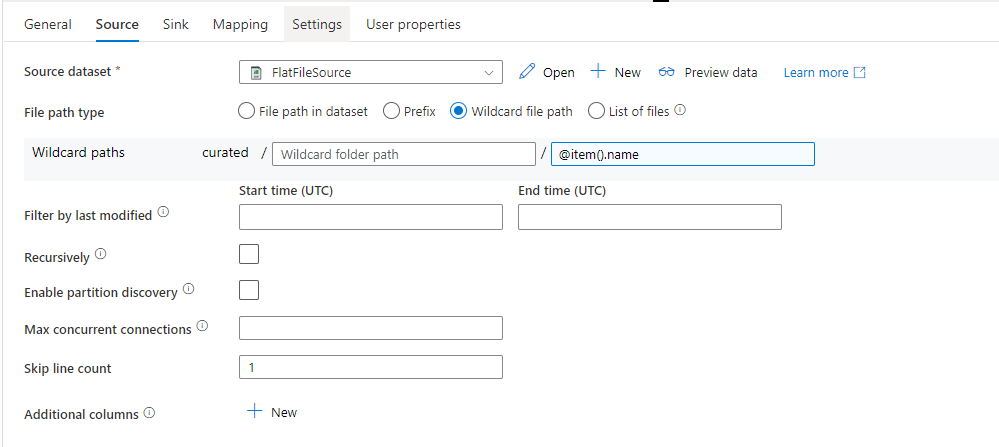
Next we add a “Copy data” activity to copy the raw data to the load/staging table. Notice that I have “Skip Line count” equal to 1. My first row is a header row, so I want to skip it. If your data does not have a header, you would want to leave this out. However, you may have some rows that have a header and some that don’t. One way to handle this would be to add something to the database that indicates whether this is a header file and set the variable for that. The variable would either be 1 or 0. Then you can actually add the Skip Line count dynamically through the expression builder.
Next step is to populate our destination table. We’re going to add a “Stored Procedure” activity that will call the stored procedure that populates the destination table. This table is essentially using your import dictionary to break the flat file into it’s respective fields in your table.
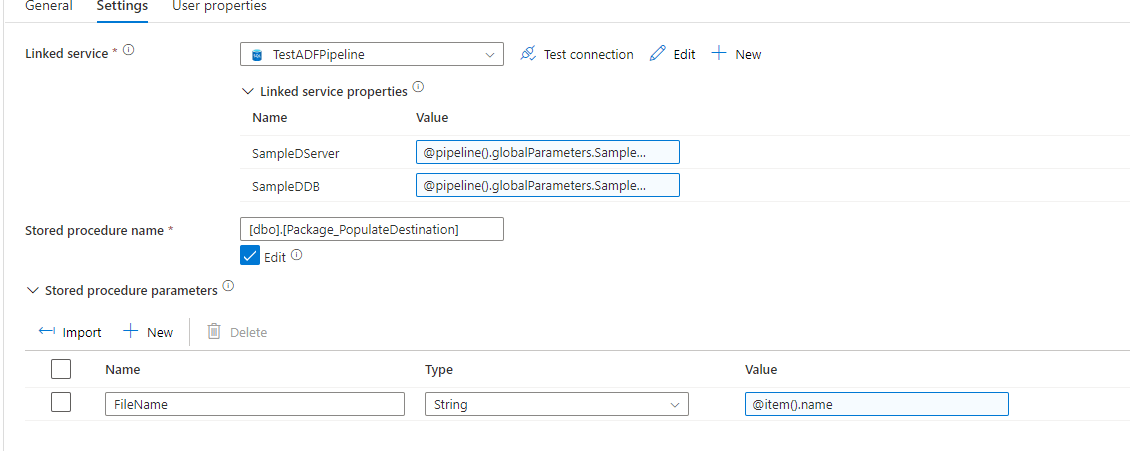
From here, you could run any potential processing if you wanted to on the data. In this example, I’m just showing the dynamic creation of the data, so I haven’t added any processing. If you were going to do any processing, you would most likely create one stored procedure that perhaps based on filetype calls another stored procedure that does the processing. That way you can have one step for all processing.
Next we’re going to mark the run complete by adding another “Stored Procedure” activity:
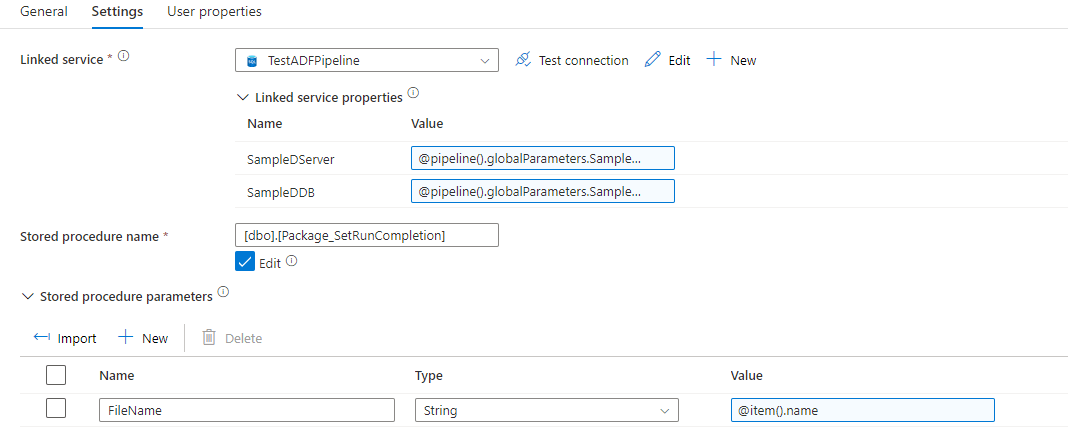
We also want to make sure we clear the staging table for the next file. So we create another “Stored Procedure” activity called “Clear Staging Table”:
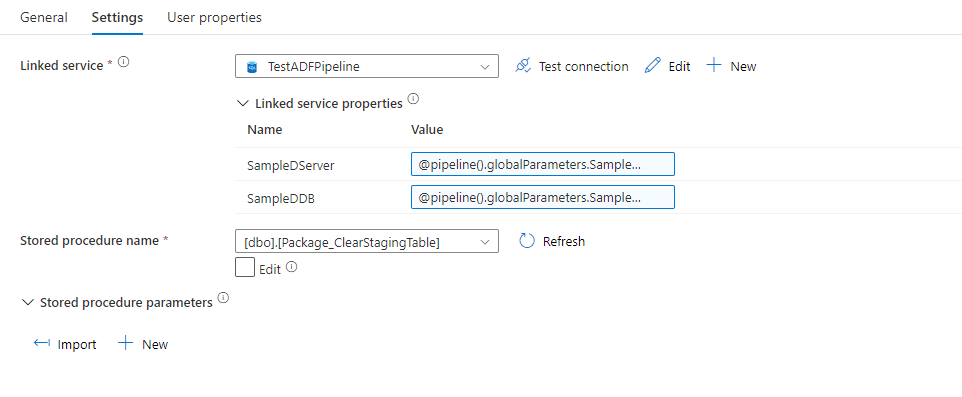
You may want to also create an activity to clear your destination table, depending on how you are post-processing the data. If you leave the “Create Destination Tables” activity in there, the destination table will be dropped and re-created any way.
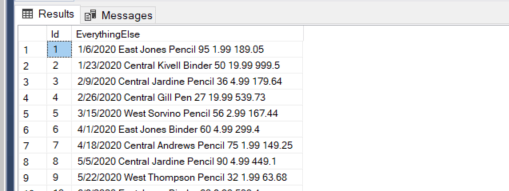
Here is what my data looks like loaded into the flat staging/load table (my table is called “Raw_SampleFile1”):
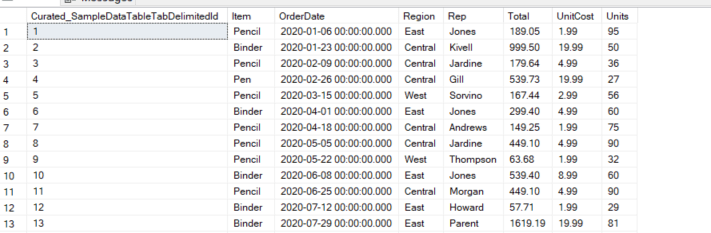
Here’s what it looks like after it’s been loaded (my destination here is the Curated_SampleDataTableTabDelimited table):
A few last discussion points. You should add error handling and transactions to your stored procedures. I would also recommend adding error activities to your pipeline. These error handling activities should go ahead and set the ContainsErrors indicator in the ETL_Run table. If you do this, I would recommend moving on to your next file so you can finish the other files and come back to those with issues.
If you have frequently dirty data, I would recommend your destination table’s data types be varchar or nvarchar so that you can run a SQL script that does validation and potential clean up once it’s been delineated into fields. This can avoid erroring out say if you thought you were getting a numeric field and it wasn’t numeric. A good idea is to take certain rows that cause issues, and quarantine them to another table where they can be processed or dealt with later. At the end of your pipeline or in a new pipeline, I would also add an email task that sends you an email telling you which files had issues and potentially need to be re-run as well as any information about files that should have been out on the storage but weren’t.
There are also many potential variations to this pipeline. As discussed, your destination tables can be set and not re-built. You can process after each file is loaded or process once all data is loaded at the end of the pipeline. You can cast data into datatypes as it’s being delineated or run a post-process to validate the data. I would recommend creating stored procedures that deal with any problems you come across and create processes that fix those issues for the future.
I hope this solution is helpful!
