

Introduction
In the big data era, organizations require real-time processing to make well-informed decisions and extract valuable insights from vast amounts of data. Initially, Lambda architecture emerged to address these needs. While it successfully provided a solution, its inherent complexity and the need for separate batch and streaming pipelines limited its effectiveness. As a result, developers created Kappa architecture, which employs a single, unified processing pipeline for both real-time and batch processing. This paper presents an in-depth overview of Kappa architecture, its advantages over Lambda architecture, and various practical use cases.
What is the Lambda architecture?
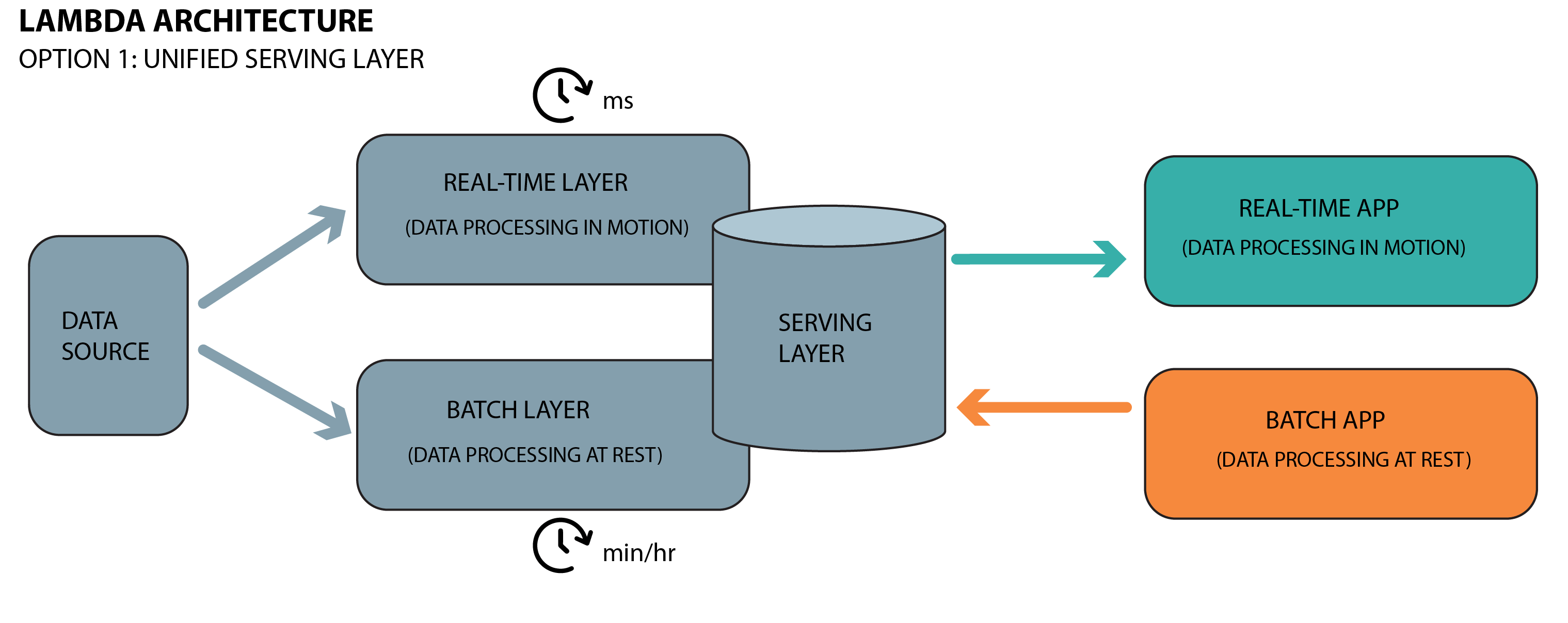
Lambda architecture is a data processing architecture designed to handle massive volumes of data by combining both batch and stream processing methods. It consists of three layers: the batch layer for storing and processing historical data, the speed layer for real-time data processing, and the serving layer for merging the results and providing insights. By leveraging this hybrid approach, Lambda architecture aims to provide fault-tolerant, scalable, and low-latency data processing solutions.
Issues with Lambda Architecture
Lambda has some limitations, as 2 pipelines have to be maintained in parallel. This means two code bases, two sets of logs, data quality checks and monitoring. Any time there is a code change, it must be made in two places. This increases complexity and makes it difficult to set up and maintain. The Lambda architecture also requires data duplication, which can be inefficient and costly.
What is the Kappa architecture?
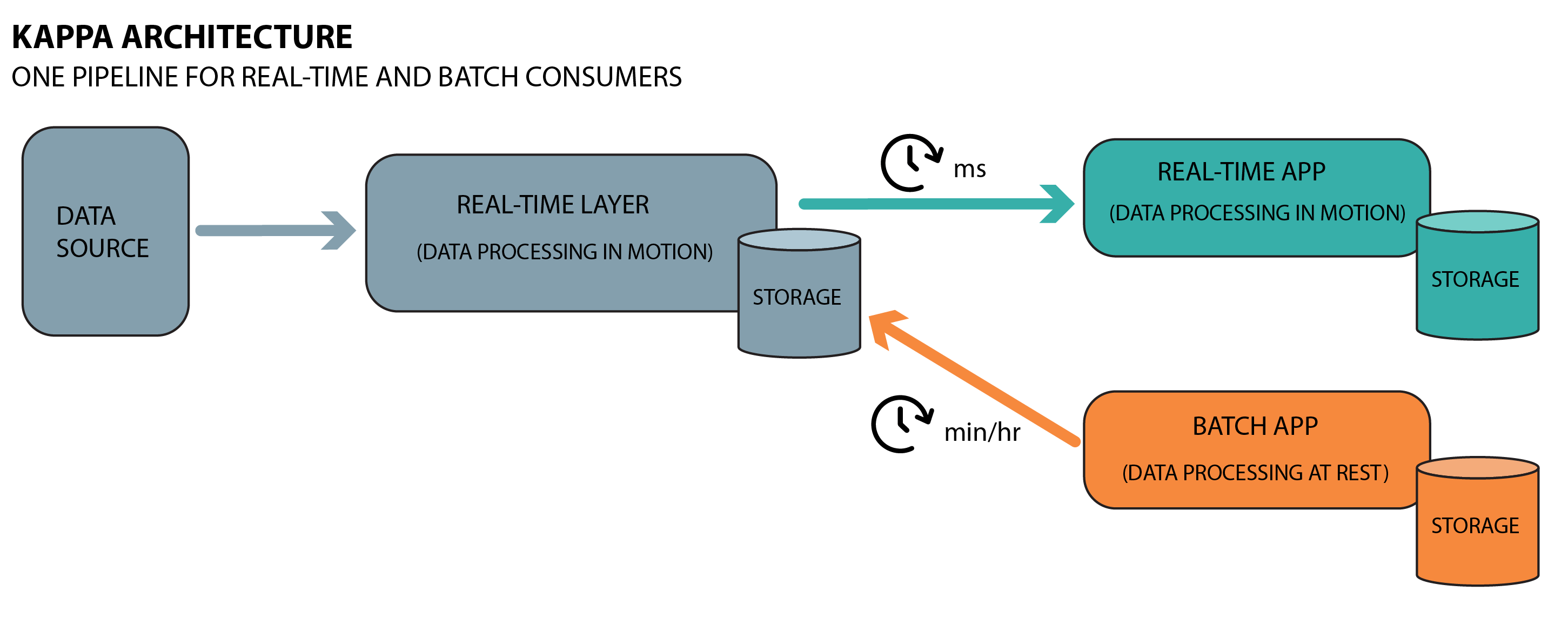
The Kappa architecture processes data in real-time and eliminates the need for batch processing. It is designed to handle real-time data processing that is scalable, fault-tolerant, and flexible. Kappa has only one processing layer (the stream layer) that processes data in real-time. The stream layer collects and processes incoming data and stores it in a distributed data store. Kappa's advantages include its simplicity, reduced latency, scalability, and lower costs.
Stream layer
The stream layer (also known as the speed layer) is the single data processing layer in the Kappa architecture, which is responsible for collecting, processing, and storing live streaming data. The Kappa architecture is usually implemented using a stream processing engine such as Apache Storm, Apache Kinesis, Apache Kafka, and Apache Flink.
This layer has two main components, including the ingestion component and the processing component. Let’s explain each of these components in detail;
- Ingestion component
- This component of the stream layer is tasked with the critical role of collecting, gathering, and preserving incoming data from a plethora of sources, including but not limited to APIs, sensors, log files, and numerous others. The ingestion process is executed in real-time, with the collected data subsequently stored in a distributed data store for future use.
- Processing component
- This component of the stream layer is responsible for processing incoming data in real-time and storing it in a distributed data store for future use. To handle this role, the processing layer is designed to handle vast amounts of data, which is typically achieved through the use of a stream processing engine such as Apache Flink or Apache Storm.
Now that we have covered the basics of the Kappa architecture let’s discuss its advantages.
Advantages of Kappa architecture
We have a few advantages in a Kappa architecture. These are summarized below.
Simplicity
Among the reasons why the Kappa architecture has become popular in recent years is its simplicity. In contrast to the Lambda architecture, which requires two separate layers for batch and real-time processing, the Kappa architecture only has a single processing layer (the stream layer). This single layer handles both batch processing and real-time processing. Having a single layer simplifies the architecture, making it much easier to maintain and manage.
Reduced latency
Latency is a crucial factor for enterprises that require real-time data processing. The Lambda architecture requires batch processing to update the serving layer, which leads to increased latency. However, the Kappa architecture eliminates batch processing, and the serving layer is updated in real-time, reducing latency.
Since the Kappa architecture leverages Apache Kafka's stream processing capabilities, it allows data to be processed as it comes in. Ultimately, this eliminates the need for data to be stored in batches, resulting in faster processing times and reduced latency.
Scalability
The Kappa architecture is also more scalable than the Lambda architecture. The Lambda architecture requires multiple systems to handle real-time and batch processing separately, which can lead to scalability issues. However, the Kappa architecture has a single processing pipeline that handles both real-time and batch processes, making it more scalable.
Lower costs
Eliminating the need for a separate batch processing layer can significantly reduce infrastructure costs. Furthermore, the simplified architecture of the Kappa architecture also reduces the need for complex ETL pipelines, which can further reduce infrastructure and maintenance costs.
Simplified testing and debugging
Being able to perform both real-time and batch processing with a single technology stack simplifies the Kappa architecture, making it much easier to test and bug software code. With this architecture, developers can develop, test, debug, and operate their applications on a single processing framework for both real-time and batch systems.
Use Cases of Kappa Architecture
- IoT Data Processing - IoT devices generate a large volume of data, and the Kappa architecture can process this data in real-time, reducing latency, improving scalability, and reducing maintenance overhead. This allows for rapid response to changing conditions, immediate detection of anomalies, and efficient integration of machine learning models to optimize performance and extract valuable insights from the vast amounts of data generated by IoT ecosystems.
- Fraud Detection - The Kappa architecture is suitable for fraud detection. Fraud detection requires processing data in real-time to detect fraudulent activities. The Kappa architecture can handle this data in real-time, reducing latency and improving fraud detection accuracy.
Real-World Example of a Kappa Architecture
Uber relies on Kappa architecture to manage its complex, data-driven operations in a real-time, distributed environment.
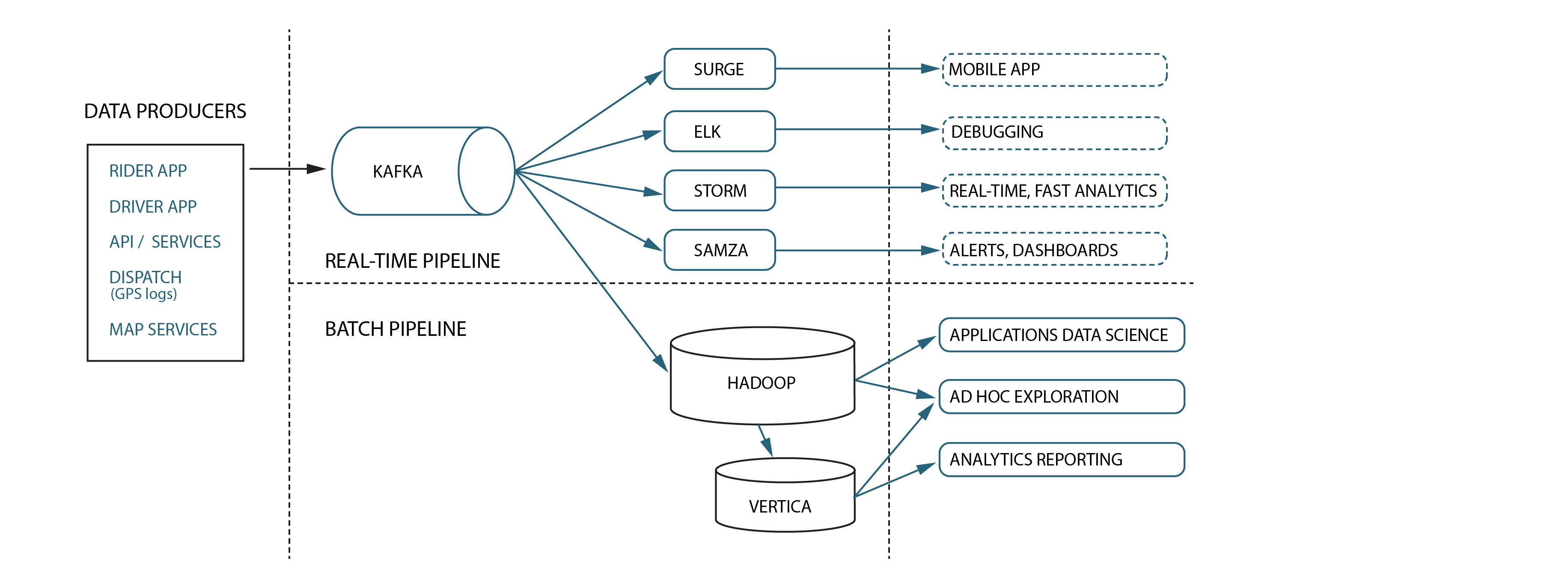
Uber's core real-time infrastructure is built upon Kafka, functioning as a central nervous system for data management. While batch pipelines remain in use, Uber also offers APIs for integration with mobile applications. As expected, their technology stack includes traditional SQL and NoSQL databases, along with business intelligence reporting tools, dashboards, and various other components to support their vast array of services.
- Real-time data ingestion: Kappa architecture enables Uber to efficiently ingest and process vast data streams from GPS, user interactions, and driver updates, allowing quick reactions to changing conditions.
- Stream processing: Uber uses Apache Kafka within Kappa architecture for real-time data processing, analysis, and aggregation.
- Machine learning integration: Kappa architecture allows Uber to incorporate machine learning models for route optimization, fare estimation, and surge pricing, enhancing user experience.
- Fault-tolerance and scalability: Kappa architecture provides built-in fault tolerance and scalability, helping Uber accommodate its growing user base and coverage area.
- Simplified maintenance: Kappa architecture's single processing pipeline streamlines Uber's data processing systems, reducing overhead and enabling engineering teams to focus on other aspects of the platform.
Final thoughts
The Kappa architecture is a powerful solution for processing real-time streaming data. By eliminating the batch layer, it simplifies the overall architecture and provides faster processing, better scalability, easier maintenance, and potential cost savings. While the Lambda architecture is still a valid option for certain use cases, the Kappa architecture offers several distinct advantages in the realm of big data processing. As organizations continue to generate and analyze increasingly large volumes of data, the Kappa architecture represents a compelling solution for handling the challenges of real-time data processing.

