Introduction
The cloud promised scale. But let’s be honest—most traditional database models still act like they're running on bare metal. Even in Azure, tiers like General Purpose and Business Critical are essentially boxed-up deployments with just a bit more elasticity. Sure, they scale vertically, they offer HA, they’ve got managed backups—but they still carry the baggage of tightly coupled compute and storage.
You want more space? Scale the whole thing up. You want better read performance? Hope the primary can take it. You need instant recovery? Better start scripting around it.
Now imagine a model where none of that friction exists. A model where storage, compute, and transaction logs live in separate planes, where growth is instant and invisible, and where reads scale horizontally without breaking a sweat. That’s not a patch—it’s a rethink.
That’s where Azure SQL Hyperscale enters the picture—not as a competitor to General Purpose or Business Critical, but as a fundamentally different offering. This isn’t SQL Server with a few knobs turned up. This is SQL Server broken apart and rebuilt for Hyperscale workloads, powered by remote page servers, separate log services, and smart cache layers that act like a CDN for your data blocks.
It’s the tier that doesn’t ask "How big is your database?" but instead says, "Go ahead, throw whatever you’ve got."
This stairway begins by grounding you in that mindset. Not just what Hyperscale is—but why it exists, where it fits, and what kind of thinking you need to adopt when working with a platform that’s built to scale beyond what you’ve dealt with before.
What is Azure SQL Hyperscale?
Azure SQL Hyperscale is not just another pricing tier—it’s a cloud-native re-architecture of how SQL Server can operate at massive scale. While General Purpose and Business Critical tiers follow a more traditional model where compute and storage are tightly coupled, Hyperscale breaks that mold by decoupling compute, storage, and logging into independent, scalable components.
At its core, Hyperscale introduces Page Servers—a distributed layer that manages data storage remotely. Instead of relying on a local disk or attached SSD, Hyperscale streams only the required pages from these page servers to the compute node on demand. This drastically reduces storage bottlenecks and enables the database to grow up to 100 TB without manual intervention or downtime.
To speed up data access, Hyperscale uses a multi-tier caching system, with the RBPEX cache (Read Buffer Pool Extension) sitting close to compute for hot data. Think of it like an intelligent cache that avoids repeated calls to remote page servers, ensuring reads are fast even with a distributed backend.
Write operations are offloaded to a dedicated Log Service, which decouples transaction log management from the compute node. This separation allows faster ingestion, parallelization, and durability without the typical I/O contention.
Backups are snapshot-based and near-instantaneous—no more long backup windows or storage copy delays. Auto-grow is built-in, with no need to configure or allocate maximum file sizes up front.
And it’s not just about scale. Hyperscale fits perfectly for SaaS platforms, read-intensive dashboards, and HTAP systems where real-time writes and analytics collide.
A few key concepts are listed below:
| Feature | Hyperscale |
|---|---|
| Max database size | Up to 100 TB |
| Storage architecture | Distributed via page servers |
| Caching mechanism | Multi-tier with RBPEX cache |
| Log architecture | Decoupled log service |
| Compute separation | Yes – read and write compute split |
| Backup/restore | Instant snapshots (no file copy) |
| Auto-grow | Instantaneous – no file size setting |
| Use cases | SaaS apps, read-heavy workloads, massive OLTP/HTAP apps |
Azure SQL Hyperscale Architecture
This diagram captures the core design that makes Hyperscale unique: a decoupled, distributed system where each layer scales independently and optimizes for performance, durability, and elasticity.
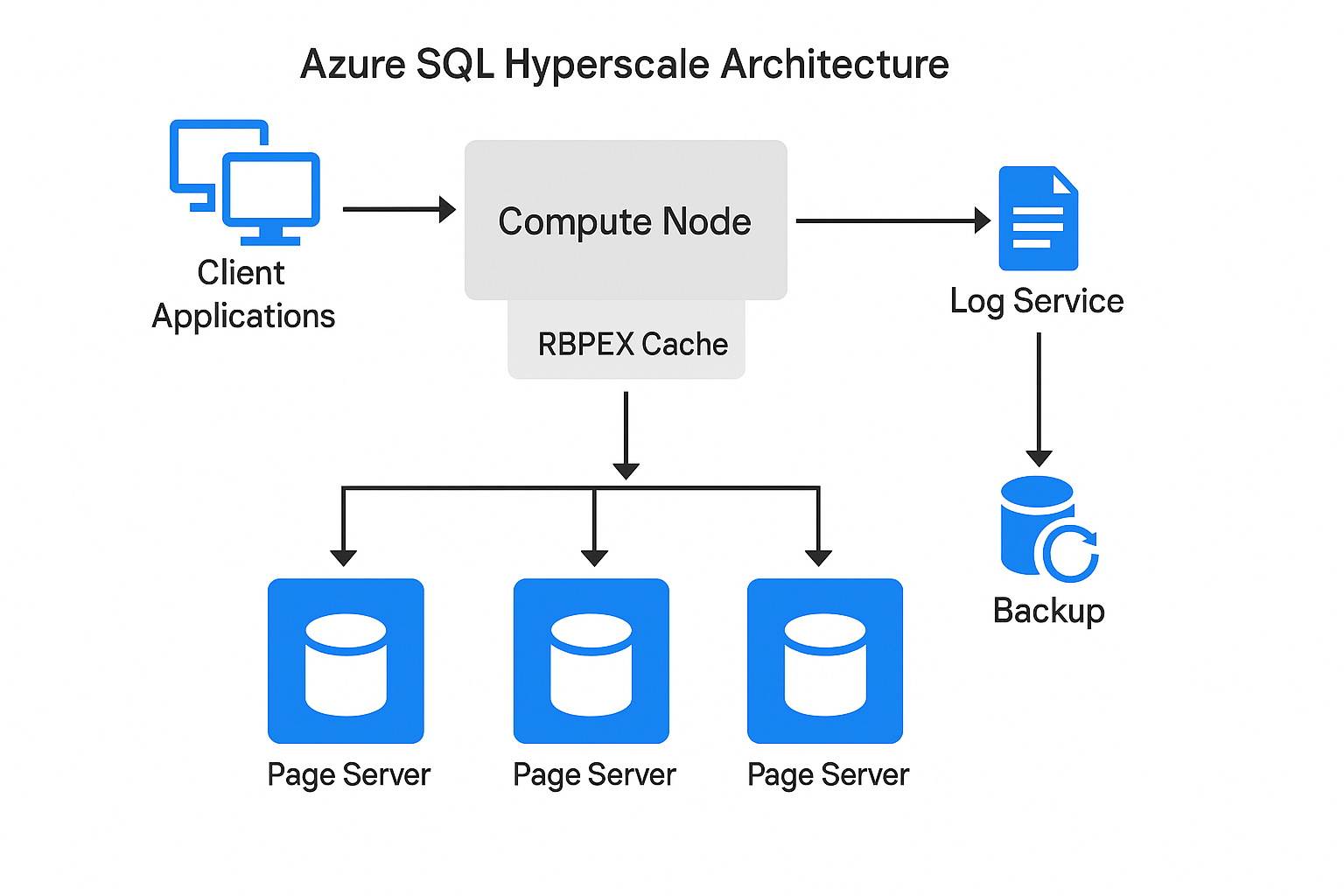
Figure 1- Hyperscale Architecture(Image by Author)
Each of the items described in above image, is described below in more detail.
Client Applications
This is where it all begins. Your web apps, APIs, dashboards—anything hitting the database—connects to Hyperscale just like they would with any SQL Server instance. There’s no special driver, no Hyperscale-specific connection string. To the client, it’s regular old SQL. But what they’re talking to under the hood is something way more powerful. They interact with the compute node, which orchestrates the magic behind the scenes.
Compute Node
This is the brains of the operation. The compute node handles all query execution—it parses T-SQL, builds execution plans, joins tables, does aggregations, all of it. But here’s the twist: it doesn’t own your data. It doesn’t even hold the full data files. Instead, it fetches just what it needs, in real-time, from downstream storage nodes. This design keeps the compute layer lightweight and fast. And if needed, you can spin up read replicas—each with its own compute node—to scale out your read workloads without touching storage.
RBPEX Cache
Sitting just below the compute node is the RBPEX cache—short for Read Buffer Pool Extension. Think of this as the local memory of the compute tier. It stores recently accessed data pages and keeps them close so that the compute node doesn’t have to go back to the page servers every single time. This dramatically improves performance, especially for read-heavy workloads. If a page is already hot and cached, your query gets sub-millisecond latency. It’s like a smart CDN, but for database blocks.
Page Servers
These are where the actual data lives. Page servers are distributed components that handle sections of your database storage. When the compute node needs a data page that isn’t in RBPEX, it requests it from the appropriate page server. Only that page is streamed across—not the whole file, not a big chunk—just the page. This on-demand behavior lets the database grow ridiculously large (up to 100 TB) without ever needing to move or attach storage. The storage backend is fully disaggregated and highly elastic.
Log Service
Hyperscale doesn't treat the transaction log the old-school way. Instead of storing it with the database, the compute node pushes log records to a separate, dedicated log service. This log service is responsible for durability, replication, and making those log records available to read replicas or backups. By decoupling the log like this, Hyperscale avoids I/O contention between reads/writes and logs, and enables super-fast recovery if something crashes. It’s built for concurrency and resilience.
Backup
Hyperscale backups are not traditional BAK files or blob storage copies. Instead, they rely on snapshot-based backups that are tied into the log service and storage layer. When you take a backup, you’re just creating a consistent point-in-time view—not physically copying files. That means backups and restores are fast—even at terabyte scale. And because the log service tracks every change, you can restore to any precise second if needed.
Putting It All Together
This whole system is built for speed, scale, and separation of concerns. Clients query the compute node. The compute node fetches what it needs from page servers, caches what’s hot, and writes logs to a centralized log service. Backups are instant. Growth is elastic. Reads can be scaled out. And none of it depends on provisioning massive VMs or pre-sizing your storage. It’s SQL for the cloud era—finally done right.
When to Choose (or Avoid) Hyperscale
So here’s why Azure SQL Hyperscale even exists in the first place. In the old-school way of running databases—whether it’s on-premises or in the cloud—your compute and storage are tightly tied together. That means if you want more storage, you’re forced to scale up the whole VM, even if you don’t need more CPU or memory. Backups and restores? They’re painful, slow, and rely on copying huge files. And when a bunch of users start reading data, the primary replica starts getting slammed, because it has to handle all of that traffic too.
Hyperscale was built to solve exactly this kind of pain. It breaks that old monolithic model. Storage is now handled separately by remote page servers, so compute and storage can scale independently. Log writing? That’s offloaded to a separate log service. Restores? Instant snapshots, no more waiting around. And you can spin up read replicas that are just compute nodes, not full-blown database instances, which takes a huge load off the primary.
Now, when should you use it? Go for Hyperscale if your database is gonna shoot past 1 TB, or if your app grows fast and you can’t afford downtime. If you’re building a SaaS platform or running mixed workloads (like reads and analytics together), this thing’s a beast. It’s also a solid choice if you want quick restore times and high availability but don’t want to mess with complex setups like Always On AGs.
But it’s not perfect for everything. If your app needs super low write latency, the Business Critical tier might be better since it uses local SSDs. Also, if your system depends on stuff like cross-database transactions, contained AGs, or features like Change Data Capture or transactional replication—some of that’s still missing in Hyperscale. So yeah, it’s powerful, but not a one-size-fits-all.
Hands-On: Create a Hyperscale DB
Step 1: Choose Hyperscale Tier & Basic Settings
Start with the Azure Portal > SQL databases > Create SQL Database.
Select your Subscription and Resource Group.
Give your Database Name (e.g., sql1).
Choose your Server (or create a new one).
Under Compute + Storage, select the Hyperscale service tier.
Set vCores (as shown in screenshot summary: 2 vCores @ ₹12,202.66 each).
Estimated cost will be shown (₹24,405.32/month compute + ₹23.67/GB/month storage).

Step 2: Configure Networking
In the Networking tab:
Select Connectivity Method →
Public endpoint.(As this is just for testing, but in real world deployments databases are always inside Private VPC for security, and so we will expose private endpoint)Allow Azure services to access the server → Yes.
Add your client IP address to firewall → Yes.
Leave the Connection Policy as default.
This ensures your SQL Server is accessible over public IP and connected securely.

Step 3: Security, Tags, and Review
In Security, optionally enable Microsoft Defender or encryption.
Skip or add Tags as needed.

Step 4: Additional Settings – Collation & Maintenance
In the Additional settings tab:
Choose Data Source →
None(for a blank DB).Keep the default Collation:
SQL_Latin1_General_CP1_CI_AS.Set Maintenance window → Default (5 PM to 8 AM) or choose custom slot.

Step 5: Deploy and Monitor
Once validated, click Create. Deployment begins.
On the Deployment screen, you’ll see multiple resources being created:
SQL Server
Firewall rules
Vulnerability assessments
Default connection config
When deployment is in progress you will see below screen:

Once all are green , your Hyperscale DB is ready!

Now we can go on Azure Portal, type in search bar SQL Databases and we will sql1 database already created there:

Step 6: Connect to Azure Hyperscale database:
Connecting to Azure Hyperscale, is not different than a tradition SQL Server database. You require SSMS or Azure Data Studio.
Before connecting we need to know the server name, which could be found in overview section of created database.

Next open Azure Data Studio, click on new connections and fill all details for the SQL Server as shown in below imageL

After connecting successfully create a table by running the below command:
-- Connect to your Azure SQL Database
use Hyperscale
go
-- Create a sample table
CREATE TABLE dbo.LargeTable (
UserID INT IDENTITY(1,1) PRIMARY KEY,
Username NVARCHAR(100) NOT NULL,
Email NVARCHAR(255) NOT NULL,
CreatedAt DATETIME2 DEFAULT SYSUTCDATETIME(),
IsActive BIT DEFAULT 1
);
GO
We can see this script successfully running on my database.

And from here we are good to go with our newly created Hyperscale Database.
Hyperscale vs General Purpose vs Business Critical
To really see where Hyperscale shines, it’s worth holding it up next to the other two main Azure SQL Database tiers General Purpose and Business Critical.
General Purpose is the dependable all-rounder. It uses remote premium disks, which keeps the price reasonable and makes it a solid fit for most everyday OLTP workloads. It’s not blazing fast, but it gets the job done reliably. The main limit is that storage access is slower than local SSDs, and if you outgrow your compute, you can only scale up vertically — meaning you move to a bigger box rather than spreading the load across multiple replicas.
Business Critical is where speed takes the front seat. With local SSDs and AlwaysOn Availability Groups under the hood, it delivers low-latency performance and strong high availability. You can have up to four readable replicas to offload reporting or analytics. It’s fantastic for heavy transactional workloads that demand quick response times, but it comes at a higher cost and still tops out at 4 TB of storage.
Hyperscale feels more like a cloud-native rethink than just “another tier.” Your data is split across distributed page servers, managed by a log service and backed by Azure storage. That means you can go up to 100 TB, scale compute both vertically and horizontally, and take fast backups or restores thanks to snapshots. It’s a great choice when you’re dealing with large, fast-growing databases or need flexible scaling. The trade-off is that if your workload lives or dies by ultra-low latency, local SSD in Business Critical can still have the edge, and a few older SQL features aren’t available yet.
| Feature | General Purpose | Business Critical | Hyperscale |
|---|---|---|---|
| Storage type | Remote Premium Disks | Local SSD | Distributed Page Servers |
| Max size | 4 TB | 4 TB | 100 TB |
| HA strategy | Remote redundancy | AlwaysOn Availability Group | Replica set, log service, snapshots |
| Read replicas | 1 (readable secondary) | Up to 4 replicas | Up to 4 named replicas |
| Scaling (compute) | Vertical only | Vertical only | Vertical + Read Scaling |
| Target workloads | Standard OLTP | Low-latency OLTP | High-throughput, cloud-scale OLTP |
Snowflake vs Hyperscale (Cloud Thinking)
Now here’s the thing: if you're coming from a Snowflake background, Hyperscale may feel familiar in some ways — separation of compute and storage, quick spin-up replicas, independent scaling — but it still thinks like SQL Server at its core.
So I will a bit throw distinctions between both products.
Snowflake is a cloud-native beast. Built ground-up for elasticity, it separates compute and storage completely. You spin up virtual warehouses (compute clusters) only when needed, and you're billed per second of use. Perfect for analytics: massive joins, dashboards, BI tools — all can hammer it in parallel without stepping on each other. It’s magic when you throw petabytes at it and expect instant answers. But it’s not ideal for high-frequency transactional workloads, and keeping warehouses running long-term can get expensive.
Now Hyperscale is Microsoft’s answer to cloud scale for OLTP and HTAP workloads, built on SQL Server architecture. It breaks apart the monolith: remote page servers for storage, compute-only replicas for reads, instant snapshots for backups. You don’t need Always On AGs for HA anymore. You get high performance and huge scale — up to 100 TB. It’s amazing when you want SQL Server familiarity but with cloud-native scale. You don’t pay per query run; compute is always billed. Write-heavy transactional stuff is its real strength, not analytics-at-scale.
So if we have to chose between both, Snowflake wins the analytics war hands down and you are having fresh analytics with unstructured/structured combination of data. Hyperscale shines when it comes to real-time, transactional, highly available database systems and your core business is already residing in Microsoft SQL Server framework.
Pick based on your intent, not just the features list.
Summary
Azure SQL Hyperscale isn’t just a bigger SQL—it’s a smarter one. By separating storage, compute, and logging, it offers a flexible, cloud-native path to scale SQL workloads beyond what traditional architectures can support.
Now that you understand what Hyperscale is and where it fits, in Level 2, we’ll go deeper into the Page Server Architecture—the real engine behind Hyperscale’s massive scaling.
We’ll cover:
What page servers are
How they store and serve data
How compute nodes interact with them
