
Making Temporal Databases Work. Part 2: Computing Aggregates Across Temporal Versions
In this part 2 we discuss what kind of aggregates can be obtained from a temporal database and how to express these aggregations in the SQL language.
2024-08-02
In this part 2 we discuss what kind of aggregates can be obtained from a temporal database and how to express these aggregations in the SQL language.
2024-08-02

Join Redgate at the last Redgate Summit event of the year! This series of events is hosted across the globe for data professionals who want to improve their skills and knowledge about Database DevOps, learn about topics surrounding the Cloud, AI, and working across multiple databases.
2024-08-02
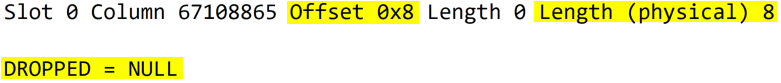
You have dropped a column and wondering why you haven't recovered any space? Let's take a look.
2024-08-01 (first published: 2024-04-26)
4,778 reads

One of the features in SQL Server Management Studio (SSMS) that I find very useful is to have a list of registered servers and databases in SSMS. This lets me quickly pick from a number of servers rather than flipping the drop down in the connection dialog. This post looks at this feature and how […]
2024-07-31
6,896 reads

Learn about Azure CLI and how to manage your Azure resources using commands instead of using the Azure portal.
2024-07-31

In celebration of their 25th anniversary in 2024, Redgate, as the host of PASS Summit, is thrilled to introduce the PASS Summit Futures Scholarship. This initiative aims to empower the next generation of data professionals from diverse backgrounds.
Applications are open internationally to students and early-career professionals. Each of the 10 lucky winners will be awarded:
2024-07-31
This article shows how to get started with the PostgreSQL API in Azure Cosmos DB.
2024-07-29
1,222 reads
I’ve talked about it before; you shouldn’t have a backup strategy, you should have a recovery strategy.
2024-07-29
Normalizing or UNPIVOTing data may be improved by using this lesser known approach in SQL Server 2008 or later.
2024-07-26 (first published: 2012-08-02)
45,676 reads
Learn about various options to migrate an entire SQL Server database to a PostgreSQL database.
2024-07-26
By Steve Jones
One of the things I’ve tried hard to do in database development situations if...
By DataOnWheels
The T-SQL Tuesday topic this month comes James Serra. What career risks have you...
This T-SQL Tuesday is hosted by the one and only James Serra – literally...
We have two "identical" instances of an ASP.NET web service (or so I have...
Comments posted to this topic are about the item OPENQUERY Flexibility
Comments posted to this topic are about the item A Full Shutdown
Which of these are valid OPENQUERY() uses?
See possible answers