

"SQL Spackle" is a collection of short articles written based on multiple requests for similar code. These short articles are NOT meant to be complete solutions. Rather, they are meant to "fill in the cracks".
--Phil McCracken
Introduction
Recently my SQL Server was upgraded to 2008, so I finally had a chance to explore its new features in practice. While exploring the new constructs for VALUES sets, much to my surprise I hit upon an alternate way to do an UNPIVOT. After a bit of Googling, I found only a few references to this approach. It seems you need to know about it before you can find it, so I immediately thought this could be a crack waiting to be filled with a little spackle.
In this article, we will examine the CROSS APPLY VALUES approach to UNPIVOT. To find information on this, you can Google the four capitalized keywords, but to help out here are a couple of relevant links:
When I first posted some code based on this to the SSC forum, I called it my Stupid SQL Trick for that Friday afternoon. Clearly I was fooling around then, but after thinking about it a bit I realized that perhaps it isn’t so stupid, and looked into it a little deeper.
The Basic, Traditional UNPIVOT
Examples using UNPIVOT are ubiquitous, and we’ll explore just a couple of basic ones. Let’s start with this one.
IF OBJECT_ID('tempdb..#Orders','U') IS NOT NULL
DROP TABLE #Orders
-- DDL and sample data for UNPIVOT Example 1
CREATE TABLE #Orders
(Orderid int identity, GiftCard int, TShirt int, Shipping int)
INSERT INTO #Orders
SELECT 1, NULL, 3 UNION ALL SELECT 2, 5, 4 UNION ALL SELECT 1, 3, 10
SELECT * FROM #OrdersWe wish to transform our initial data so that our results set looks like this:
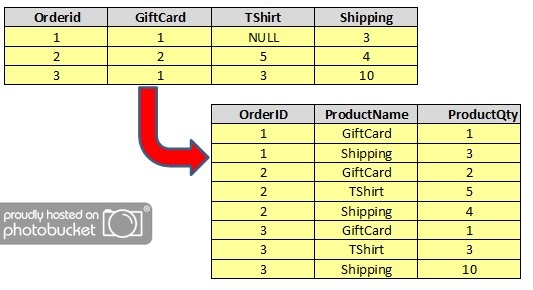
To UNPIVOT, we use the following SQL syntax:
-- Traditional UNPIVOT
SELECT OrderID, convert(varchar(15), ProductName) [ProductName], ProductQty
FROM (
SELECT OrderID, GiftCard, TShirt, Shipping
FROM #Orders) p
UNPIVOT
(ProductQty FOR ProductName IN ([GiftCard], [TShirt], [Shipping])) as unpvtLet’s now try the CROSS APPLY VALUES approach to this example:
SELECT OrderID, ProductName, ProductQty
FROM #Orders
CROSS APPLY (
VALUES ('GiftCard', GiftCard)
,('TShirt', TShirt)
,('Shipping', Shipping)) x(ProductName, ProductQty)
WHERE ProductQty IS NOT NULL
DROP TABLE #OrdersTry it yourself and you’ll find that it produces identical results right down to the natural ordering of the records. The syntax doesn’t seem that bad either, once you get used to it – though since that’s subjective, we’ll let the reader decide which they prefer.
Another Example: UNPIVOT on Multiple Columns
This example will UNPIVOT 6 columns to 2; hence I call it the “double” UNPIVOT. First the setup data:
IF OBJECT_ID('tempdb..#Suppliers','U') IS NOT NULL
DROP TABLE #Suppliers
-- DDL and sample data for UNPIVOT Example 2
CREATE TABLE #Suppliers
(ID INT, Product VARCHAR(500)
,Supplier1 VARCHAR(500), Supplier2 VARCHAR(500), Supplier3 VARCHAR(500)
,City1 VARCHAR(500), City2 VARCHAR(500), City3 VARCHAR(500))
-- Load Sample data
INSERT INTO #Suppliers
SELECT 1, 'Car', 'Honda', 'Toyota', 'Nissan', 'Detroit','Miami','Los Angeles'
UNION ALL SELECT 2, 'Bike', 'Schwinn', 'Roadmaster', 'Fleetwing', 'Cincinatti', 'Chicago', 'Tampa'
UNION ALL SELECT 3, 'Motorcycle', 'Harley', 'Yamaha', 'Kawasaki', 'Omaha', 'Dallas', 'Atlanta' -- NULL
SELECT * FROM #SuppliersWe wish to transform our initial data so that our results set looks like this:
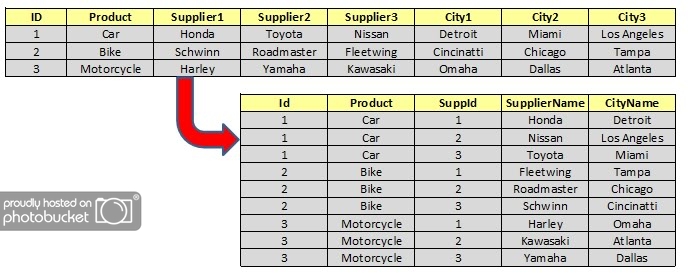
To make this happen, we need to use a double UNPIVOT, like so:
SELECT Id, Product
,SuppID=ROW_NUMBER() OVER (PARTITION BY Id ORDER BY SupplierName)
,SupplierName, CityName
FROM (
SELECT ID, Product, Supplier1, Supplier2, Supplier3, City1, City2, City3
FROM #Suppliers) Main
UNPIVOT (
SupplierName FOR Suppliers IN (Supplier1, Supplier2, Supplier3)) Sup
UNPIVOT (
CityName For Cities IN (City1, City2, City3)) Ct
WHERE RIGHT(Suppliers,1) = RIGHT(Cities,1)Now let’s try doing this with the CROSS APPLY VALUES method:
SELECT ID, Product
,SuppID=ROW_NUMBER() OVER (PARTITION BY ID ORDER BY SupplierName)
,SupplierName, CityName
FROM #Suppliers
CROSS APPLY (
VALUES (Supplier1, City1)
,(Supplier2, City2)
,(Supplier3, City3)) x(SupplierName, CityName)
WHERE SupplierName IS NOT NULL OR CityName IS NOT NULL
DROP TABLE #SuppliersIt certainly is more compact, and perhaps even a bit more understandable. Try it for yourself and confirm that once again it returns the exact same result set, right down to the natural row ordering.
A couple of things come to mind about the traditional approach though:
- Try replacing Atlanta on the last record with a NULL value (commented to the right). The result set omits that row even though there is a Supplier3 (just no City). I’m a bit puzzled to figure out how to bring that record back into the UNPIVOT results set. Examine the new approach: in this case, the WHERE clause allows the record with a NULL City to come through. If you want it to exactly emulate the results of the traditional approach, change the OR to AND.
- What’s up with that funky WHERE clause in the traditional approach anyway? Does that mean I can only UNPIVOT multiple columns if the column names end in a unique, one-character suffix for the conjoined pairs? That seems rather awkward. CROSS APPLY VALUES seems to have no such restriction. In actuality though, you can construct the WHERE as follows to achieve the same effect (although that is even more funky).
WHERE (Suppliers = 'Supplier1' AND Cities = 'City1') OR
(Suppliers = 'Supplier2' AND Cities = 'City2') OR
(Suppliers = 'Supplier3' AND Cities = 'City3')In either approach, as you can well imagine, any non-homogeneous data types in the UNPIVOTed columns need to be appropriately CAST.
Performance Comparison
So as to appease the pundits that would challenge me for not mentioning performance, let’s do a comparison between the two approaches.
For example 1, I constructed a test harness that allowed me to introduce sparseness into the results. I was able to parameterize it so that I can set a sparseness level, and the random numbers would do the rest. At 75% sparseness, that means that only 25% of the records have non-null values, so the final result set is smaller than at 50% sparseness. I did this thinking that it might impact the results.
IF OBJECT_ID('tempdb..#Orders','U') IS NOT NULL
DROP TABLE #Orders
-- DDL and sample data (100,000 row test harness) for UNPIVOT Example 1
CREATE TABLE #Orders
(Orderid int identity, GiftCard int, TShirt int, Shipping int)
DECLARE @Sparsity INT = 3 -- 0=0%, 1=~25%, 2=~50%, 3=~75%
,@NoRows INT = 100000
INSERT INTO #Orders
SELECT TOP (@NoRows)
CASE WHEN URN1 <= @Sparsity THEN NULL ELSE URN1 END
,CASE WHEN URN2 <= @Sparsity THEN NULL ELSE URN2 END
,CASE WHEN URN3 <= @Sparsity THEN NULL ELSE URN3 END
FROM sys.all_columns t1 CROSS APPLY sys.all_columns t2
CROSS APPLY (
SELECT ABS(CHECKSUM(NEWID()))%4+1, ABS(CHECKSUM(NEWID()))%4+1, ABS(CHECKSUM(NEWID()))%4+1
) a(URN1, URN2, URN3)
IF OBJECT_ID('tempdb..#Orders','U') IS NOT NULL
DROP TABLE #Orders
-- DDL and sample data (100,000 row test harness) for UNPIVOT Example 1
CREATE TABLE #Orders
(Orderid int identity, GiftCard int, TShirt int, Shipping int)
DECLARE @Sparsity INT = 3 -- 0=0%, 1=~25%, 2=~50%, 3=~75%
,@NoRows INT = 100000
INSERT INTO #Orders
SELECT TOP (@NoRows)
CASE WHEN URN1 <= @Sparsity THEN NULL ELSE URN1 END
,CASE WHEN URN2 <= @Sparsity THEN NULL ELSE URN2 END
,CASE WHEN URN3 <= @Sparsity THEN NULL ELSE URN3 END
FROM sys.all_columns t1 CROSS APPLY sys.all_columns t2
CROSS APPLY (
SELECT ABS(CHECKSUM(NEWID()))%4+1, ABS(CHECKSUM(NEWID()))%4+1, ABS(CHECKSUM(NEWID()))%4+1
) a(URN1, URN2, URN3)Here are my performance results, running 5 times at each sparseness level (100% sparseness is pretty meaningless). At 100,000 records in the test harness, the CROSS APPLY VALUES method is clearly faster in CPU time and slightly improved in elapsed time, nearly across the board. I ask those pundits mentioned earlier to forgive me for not using 1,000,000 rows, but I lack the patience to do 20 runs with that many records - I demand instant gratification! I have also shown the Execution Plan of the traditional method (shown first) vs. the CROSS APPLY VALUES approach.
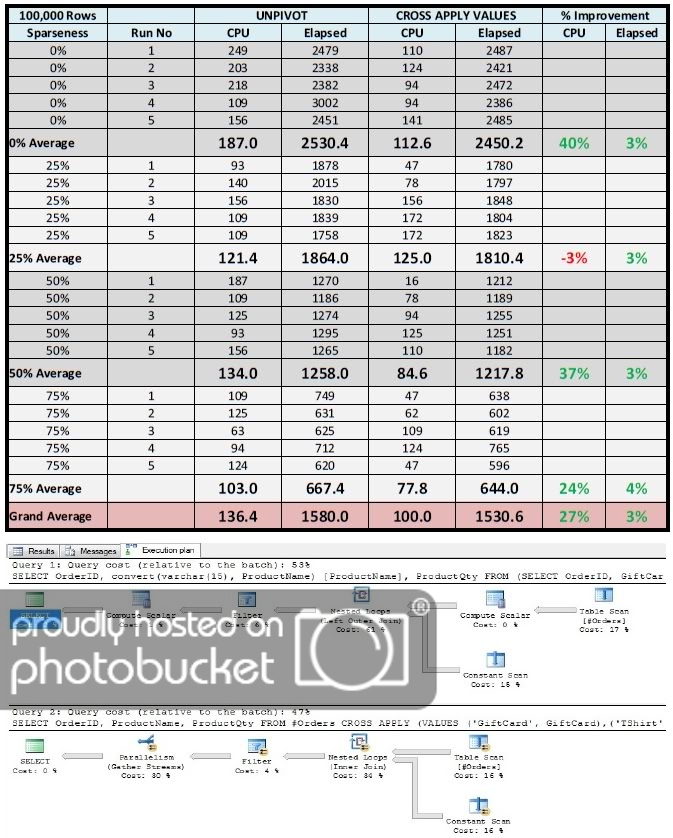
Since I didn’t see much variance across the sparseness factor in example 1, I decided to ignore this variable for example 2. Once again in the interests of instant gratification, I constructed a test harness with far fewer rows (24,003 to be precise), so that I could run through the test reasonably quickly and cut to the chase. Note that it builds onto the 3 rows added in the initial test.
;WITH Tally (n) AS (
SELECT TOP 8000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns t1 CROSS APPLY sys.all_columns t2)
INSERT INTO #Suppliers
SELECT ID+10*n
,Product + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,Supplier1 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,Supplier2 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,Supplier3 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,City1 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,City2 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
,City3 + RIGHT('00000'+CAST(n AS VARCHAR(6)), 6)
FROM #Suppliers
CROSS APPLY (SELECT n FROM Tally) x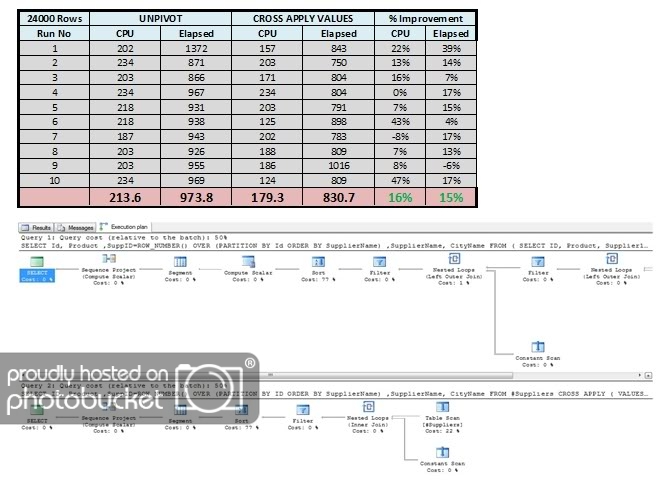
In these results we see a clear improvement in both CPU and elapsed times vs. the double UNPIVOT, with some variability. It would be interesting to see how these figures stack up in a triple UNPIVOT, but this is after all just a bit of spackle, so we won’t go completely overboard and build a whole wall. Once again, we also provide the Execution Plan comparison for completeness, even though the UNPIVOT approach was just a little too wide to fit on my screen.
Another Example
Here’s an example of an UNPIVOT that may not at first glance appear to be so. I have seen similar examples of reporting many times where time periods (e.g. months) are stored as columns. While I’m of course not an advocate of this, as a realist I do know that it happens. But hey, let’s face it: even though formatting like this should definitely be done in the front-end, UNPIVOT’s main usage is to normalize data that is poorly normalized in the first place!
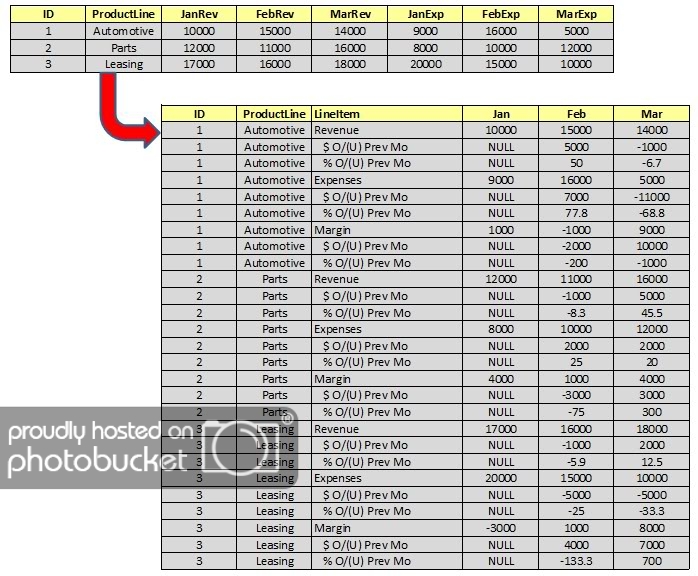
Here is how we would perform this transformation using the CROSS APPLY VALUES approach:
IF OBJECT_ID('tempdb..#ProfitLoss','U') IS NOT NULL
DROP TABLE #ProfitLoss
-- DDL and sample data for UNPIVOT Example 3
CREATE TABLE #ProfitLoss
(ID INT, ProductLine VARCHAR(500)
,JanRev MONEY, FebRev MONEY, MarRev MONEY
,JanExp MONEY, FebExp MONEY, MarExp MONEY )
-- Load Sample data
INSERT INTO #ProfitLoss
SELECT 1, 'Automotive', 10000, 15000, 14000, 9000, 16000, 5000
UNION ALL SELECT 2, 'Parts', 12000, 11000, 16000, 8000, 10000, 12000
UNION ALL SELECT 3, 'Leasing', 17000, 16000, 18000, 20000, 15000, 10000
SELECT * FROM #ProfitLoss
SELECT ID, ProductLine, LineItem, Jan, Feb, Mar
FROM #ProfitLoss
CROSS APPLY (SELECT JanRev-JanExp, FebRev-FebExp, MarRev-MarExp) y(JanMar, FebMar, MarMar)
CROSS APPLY (
VALUES ('Revenue', JanRev, FebRev, MarRev)
,(' $ O/(U) Prev Mo', NULL, FebRev-JanRev, MarRev-FebRev)
,(' % O/(U) Prev Mo', NULL, ROUND(100*(FebRev-JanRev)/JanRev, 1), ROUND(100*(MarRev-FebRev)/FebRev, 1))
,('Expenses', JanExp, FebExp, MarExp)
,(' $ O/(U) Prev Mo', NULL, FebExp-JanExp, MarExp-FebExp)
,(' % O/(U) Prev Mo', NULL, ROUND(100*(FebExp-JanExp)/JanExp, 1), ROUND(100*(MarExp-FebExp)/FebExp, 1))
,('Margin', JanMar, FebMar, MarMar)
,(' $ O/(U) Prev Mo', NULL, FebMar-JanMar, MarMar-FebMar)
,(' % O/(U) Prev Mo', NULL, ROUND(100*(FebMar-JanMar)/JanMar, 1), ROUND(100*(MarMar-FebMar)/FebMar, 1))
) x(LineItem, Jan, Feb, Mar)
DROP TABLE #ProfitLossWe won’t do a performance test for this example, and instead leave it as an exercise for our intrepid readers to generate the same data transformation using UNPIVOT and tell us which approach is better.
Conclusion
We have demonstrated that the CROSS APPLY VALUES approach to UNPIVOT is both syntactically compact and appears to perform better than the traditional UNPIVOT approach. In certain cases it may offer even more flexibility. It seems it may not be nearly as well known, having only appeared in SQL Server 2008; so now is the time to add this tool to your war chest. Just remember to test, test, test for your particular case, so that some anomaly doesn’t surface, dragging your applications down into the performance gutter.
Remember also that there is no such thing as a free lunch. I suspect that the improvement in CPU usage comes at the cost of using more memory.
The only thing bad I can see about this approach is the name. Let’s face it, the CROSS APPLY VALUES approach to UNPIVOT sounds enough like the “Epsilon Delta approach to Limits” to make anyone feel uncomfortable. Perhaps CAVATU or CAVATUP? Sorry, but that doesn’t work for me either. I’d call it the “quirky UNPIVOT” but it’s not all that quirky, and besides someone has already used a name like that. So I guess we’ll just have to settle for the “other UNPIVOT.”
In the end, we won’t claim that this approach is better for UNPIVOT, because we have not done extensive testing on both, but I think I’ll probably use it. We’ll let our readers decide if it is best for them as well. Was this a crack worthy of the application of a little SQL Spackle?
