

Overview
We all know Indexes in SQL Server are critical for optimizing query performance and ensuring efficient data retrieval. But beyond that, indexes play an important role in avoiding deadlock situations or database blocking. In a multiuser environment, Indexes play a vital role when there are concurrent transactions. Even when the size of a table is small, an index is required on one or more columns, which is primarily used for identifying a record. We are going to experiment and learn how the index is interconnected with the locking mechanism and helps to avoid database blocking.
How Indexes and Locks Interact
In SQL Server, indexes and locks are related, since both are mechanisms that influence how the data is accessed and managed in a database, particularly during query execution and transaction processing. Their relationship primarily revolves around how locks are applied to the indexed table to ensure data consistency and integrity.
Indexes are database structures that improve the speed of data retrieval by providing quick lookup paths to rows in a table. They are used for locating the data rows efficiently during query execution, reducing the number of pages scanned. Database locking in SQL Server is a mechanism used to manage concurrent access to data. Locks are used by SQL Server to manage concurrency, ensuring that transactions maintain data consistency by preventing conflicting operations. Locks can be applied at different granularity levels: row, page, table, or index key. When a query accesses data through an index, SQL Server may place locks on the index keys or data pages to prevent other transactions from modifying the data concurrently.
Let's look the following two sections to understand how data rows are identified and locks are applied, which helps us to do the experiment easily.
Index Structure and Lock Granularity
Indexes determine which rows or pages are accessed, and thus which objects (rows, keys, or pages) are locked. For example, a query using a clustered index might lock specific rows in the table, while a non-clustered index might lock index keys and corresponding data rows. A table without any indexes is a heap, meaning data is stored in no particular order, and SQL Server uses Row IDs (RIDs) to locate rows. Without indexes, SQL Server may need to scan the entire heap to locate rows, potentially leading to more locks or escalation to a table lock.
If a query performs a range scan on an index (e.g., WHERE column1 BETWEEN 100 AND 110), SQL Server may apply key-range locks to protect ranges of index keys, preventing other transactions from inserting or modifying data within that range.
Lock Types and Index Operations
Shared locks (S): This lock is used for read operations (e.g., SELECT) and it allows multiple transactions to read the same data but prevents modifications. For example, multiple users can read a row, but no one can update it while the shared lock is active. Shared lock is often applied to index keys or data rows accessed via an index / heap.
Exclusive locks (X): This type of lock is used for writing operations (e.g., INSERT, UPDATE, DELETE) and applied to affected index keys or data rows to prevent concurrent modifications. It prevents other transactions from reading or modifying the locked data rows until the lock is active.
Update locks (U): It is a type of hybrid lock used during the initial phase of an UPDATE operation to prevent deadlocks. Meaning that it may escalate to exclusive locks (e.g., finding rows to update). This lock type allows reading but prevents other updates or exclusive locks on the rows or index keys.
How index helps to avoid blocking
Let's do the actual experiment using a simple table to prove that, Index helps to avoid blocking. Basically this demo explains without required Index, how an update and read operation on a table get into a conflict and leads to database blocking. Follow by that, we proved that after creating Index on the table, the conflict goes away. Because Index helps to reduce the scope of the resource (rows, keys or pages), which needs to be locked to complete the required operation.
Experiment a write and read operation on heap table
We are going to uses a table called “StocksTraded” in Markets database. This table is holding just about 3K records. This is a plain vannila table. It means, there is no constraint or index defined; it is a simple table.
When a user issues an update statement to change the value in a record of “StocksTraded”, the database engine finds the record first and then locks it. The lock will be existed until the transaction is completed, which is good and that is what we all wanted. But, when there is no index created on this table, it creates database blocking. Because, it has to do full table scan to find the record and as discussed above in “Index Structure and Lock Granularity”, without indexes, SQL Server may need to scan the entire heap to locate rows, potentially leading to more locks or escalation to a table level lock.
Let's start the experiment now. The first thing, we make sure, there is no index or primary key on the table “StocksTraded”. The following screenshot shows the schema of the table, which confirms that, no index exists.
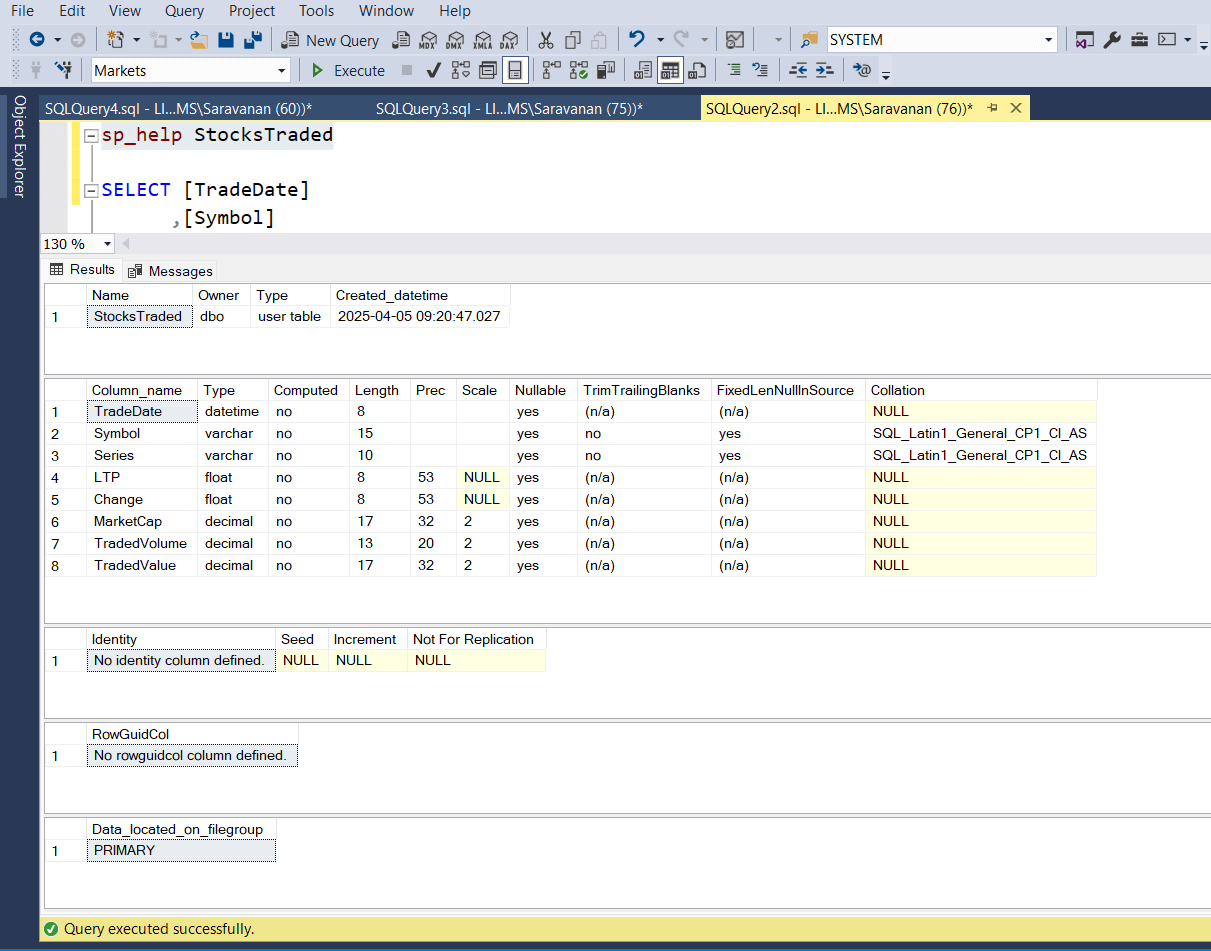
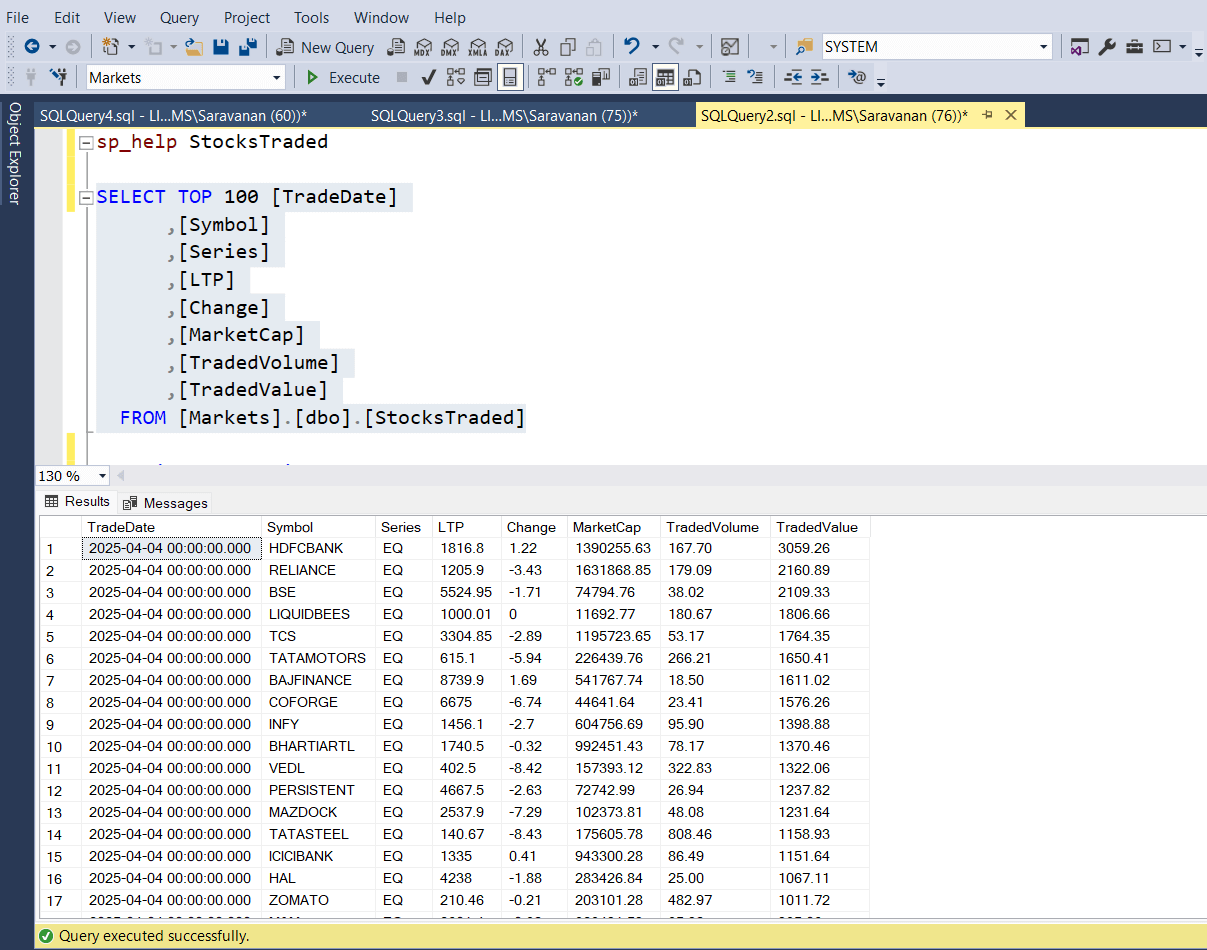
Now, let us query sample data to see and pick a record to update. The following screen shot shows that, top 100 records and we will pick the first record (where symbol = ‘HDFCBANK’) for our update operation. Probably we will pick the 3rd record for concurrent read operation (where symbol = ‘BSE’).
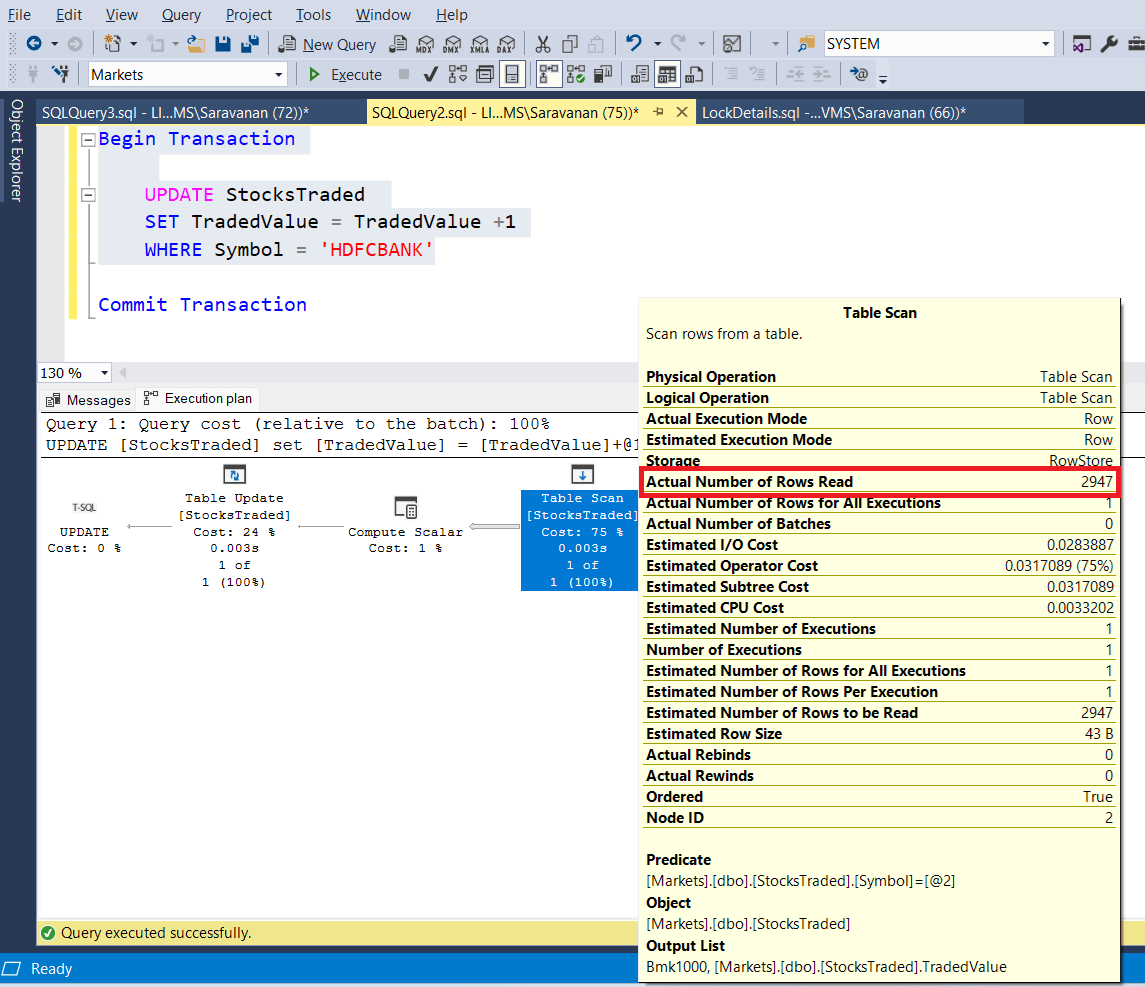
The following screenshots shows the update query and the corresponding execution plan. But for the experiment purpose, we are going to hold the open transaction for a while to prove the concurrency issue / database blocking. As per the where clause, we want to update only one record. But the engine reads the entire 2947 records.
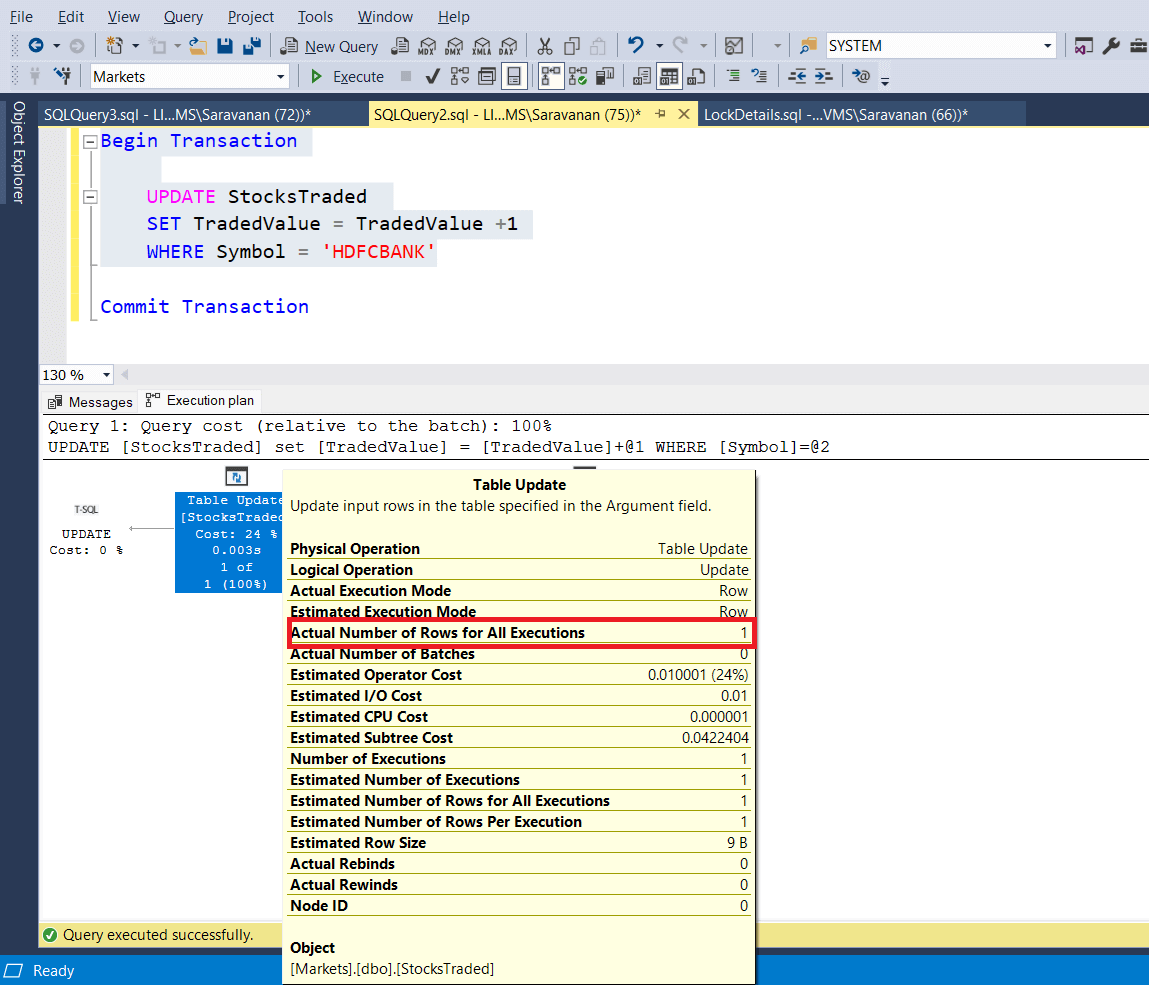
In the following screenshot, it proves that only one record is actually updated.
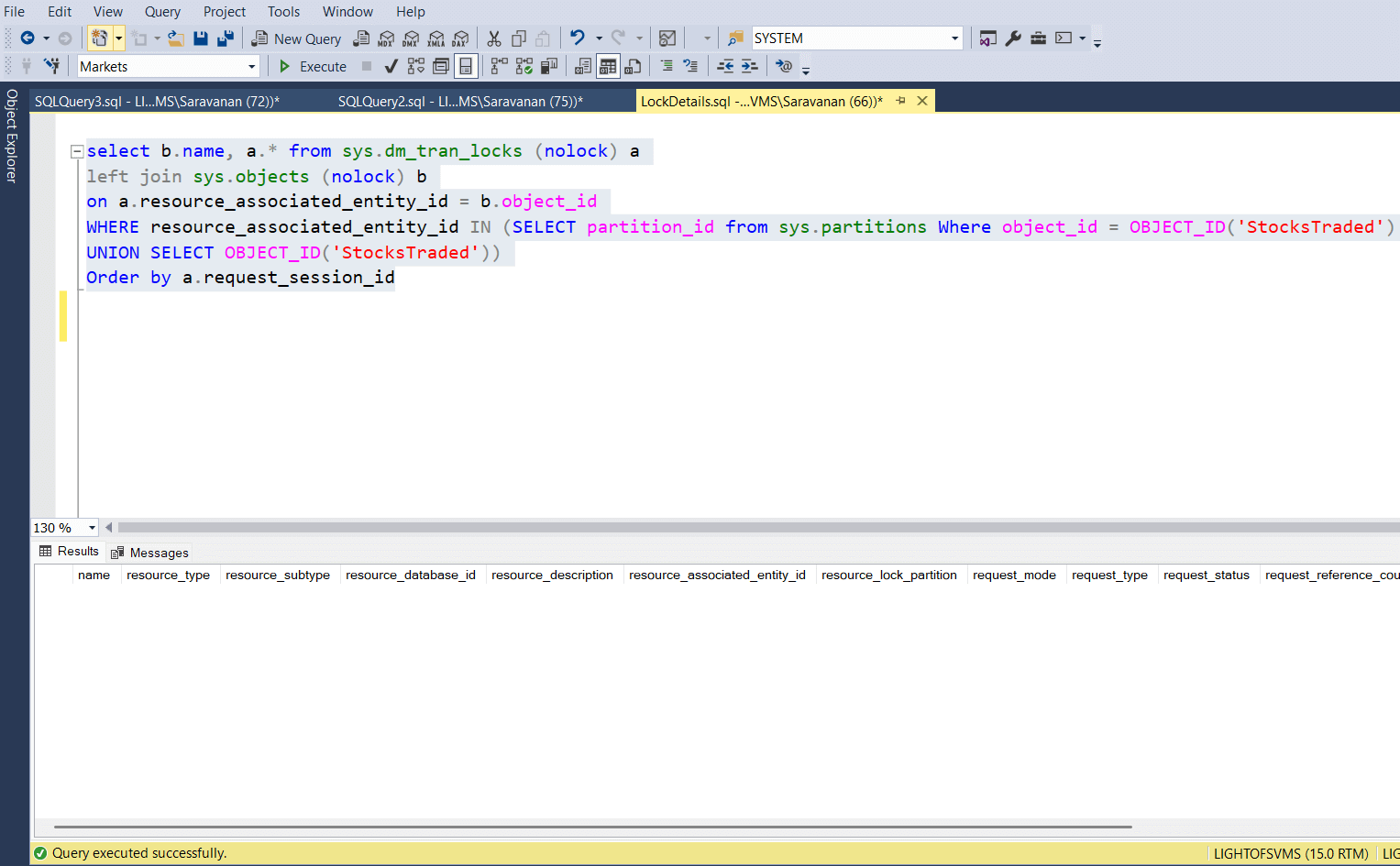
Now, let’s look at the active lock details, which are live with “StocksTraded” table. See the below screenshot. Exclusive lock is issued on the resource type RID.
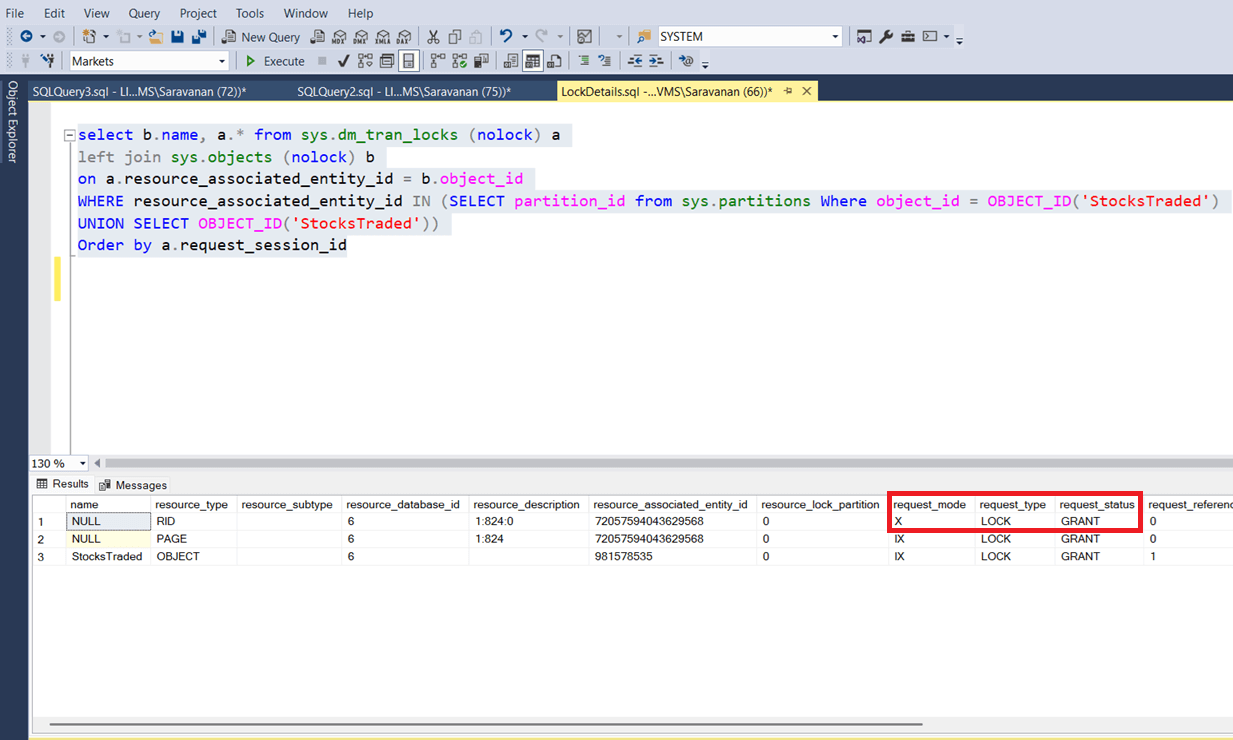
To check the impact on concurrent transaction, let us open a new session and run a select query to read the data, where the symbol is BSE.
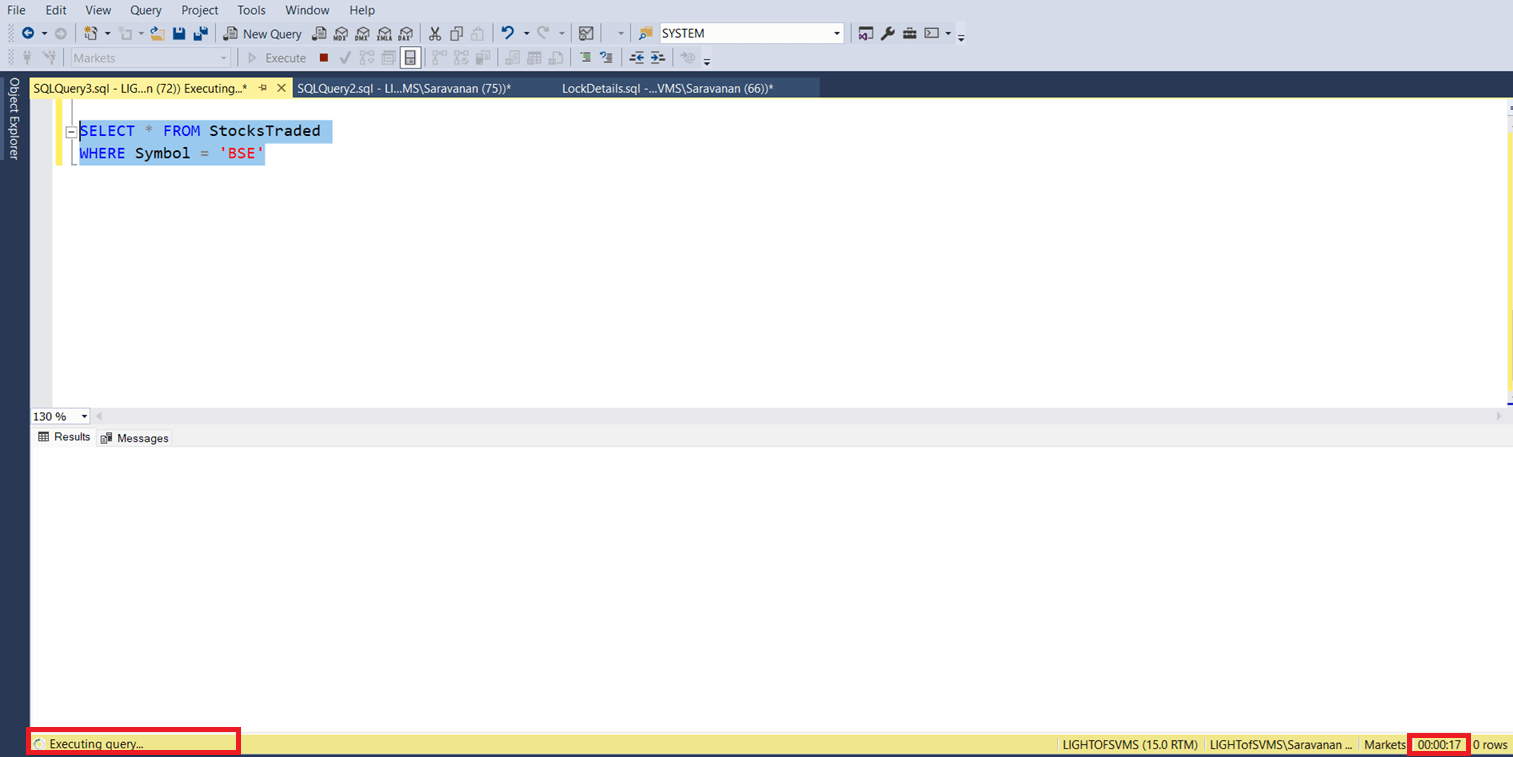
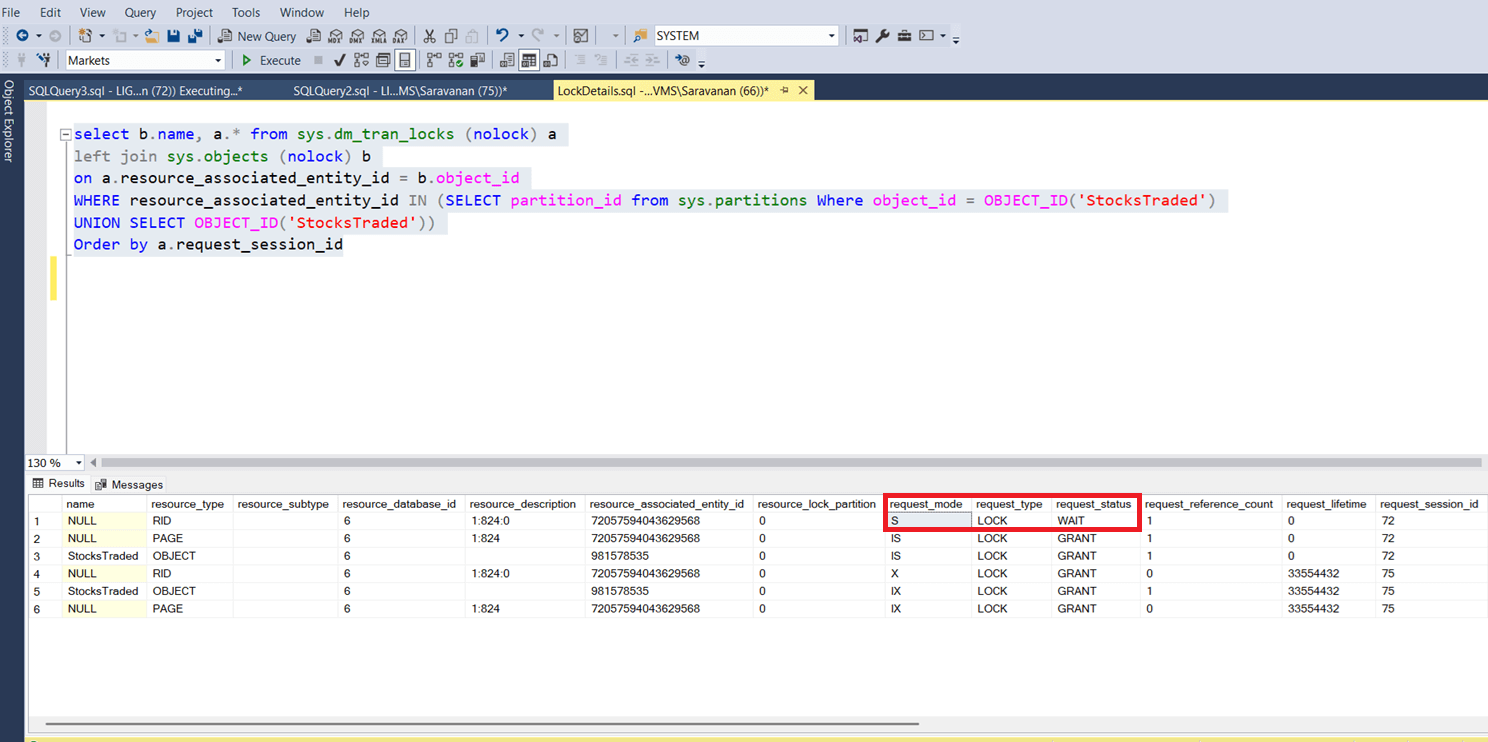
The above screenshot shows that, even though the select query is running to fetch the data for different criteria (where symbol is ‘BSE’), it is waiting for the engine to acquire shared lock to complete the read operation. The following screenshot shows the current situation / lock details on StocksTraded table. See the marked one and the request status is still wait. So, until the update transaction is completed, the read operation for some other record is also going to wait. Because without an index, it has to scan the table to fetch the data for the given criteria. The subsequent screenshot will prove that the select query does the full table scan.
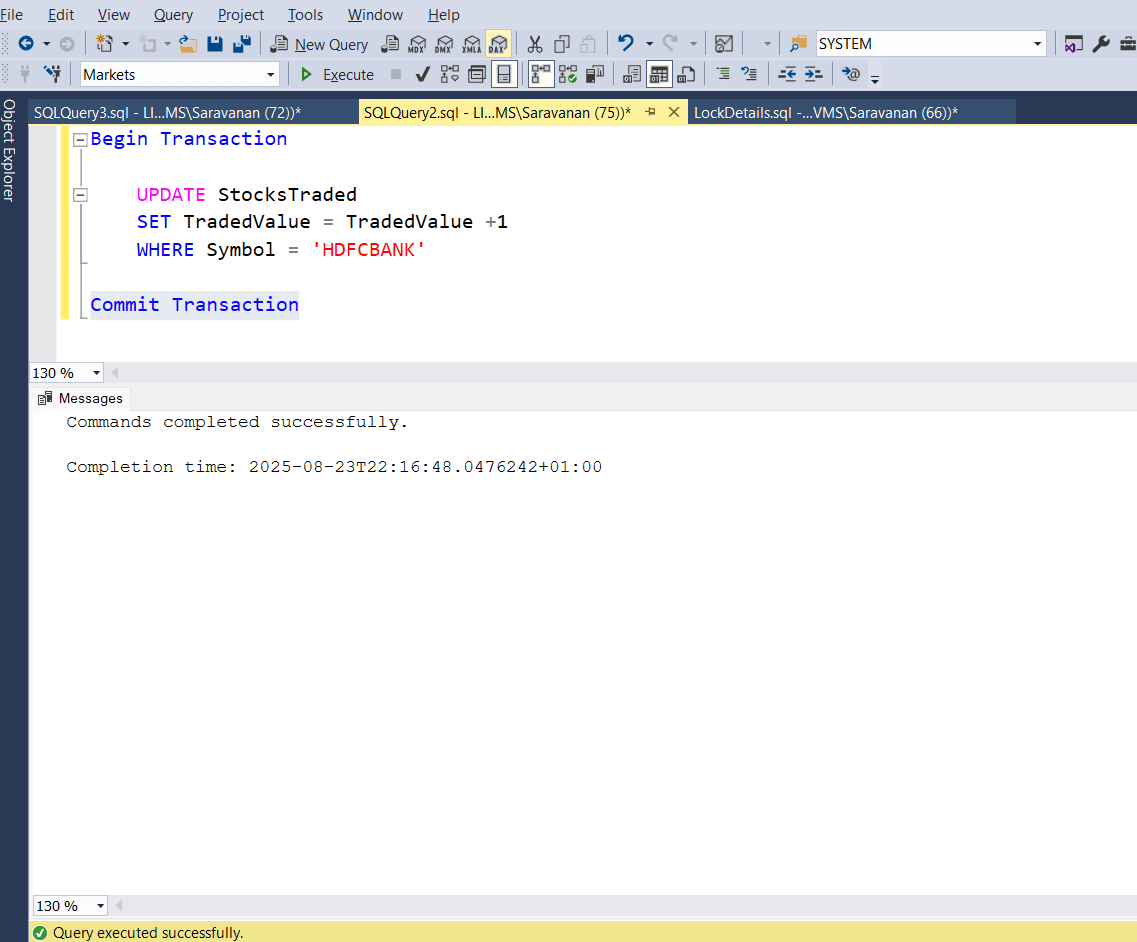
Let’s commit the transaction. So that both read and write will complete. The below screenshot confirms that the transaction is completed
The following screenshot shows the execution plan of the read operation. For read also it does table scan and reads the entire table. See the marked section from the screenshot. Actual number of rows read is 2947 and actual number of rows for all executions is 1.
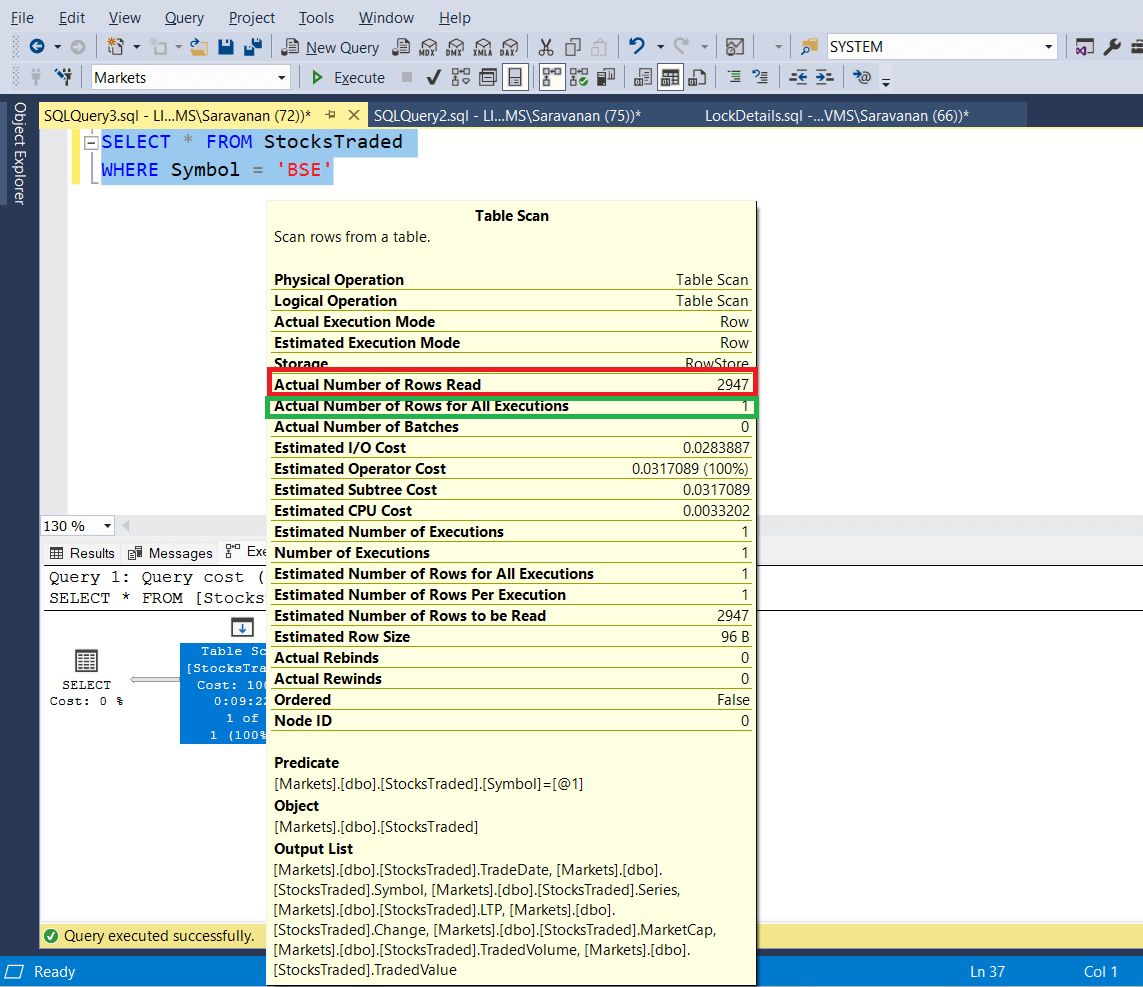
Basically, the read operation tries to acquire a shared lock on all the rows, since the scan is a sequential operation and it has to scan the all the records to return the correct result where symbol is ‘BSE’. But for the update operation, already exclusive lock is granted on the row where the symbol is ‘HDFCBANK’. So, until it is released, the read operation has to wait, since it has to read all the rows.
Let’s do the same experiment after creating index on symbol column
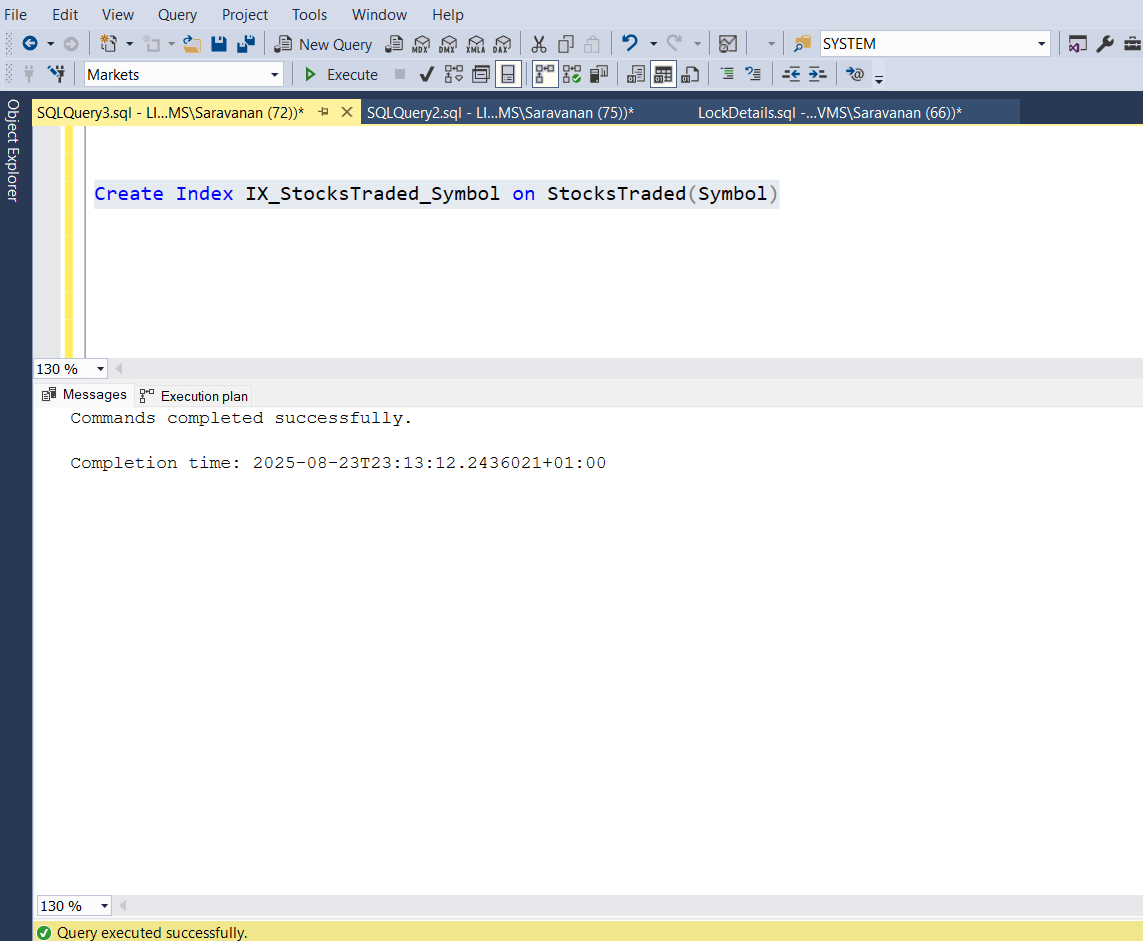
Creating an index on the column used to identify a row will eliminate this blocking issue, Since the table scan will go away and the query operation will use Index seek, which will only read the records in scope. The following screenshot shows the index creation.
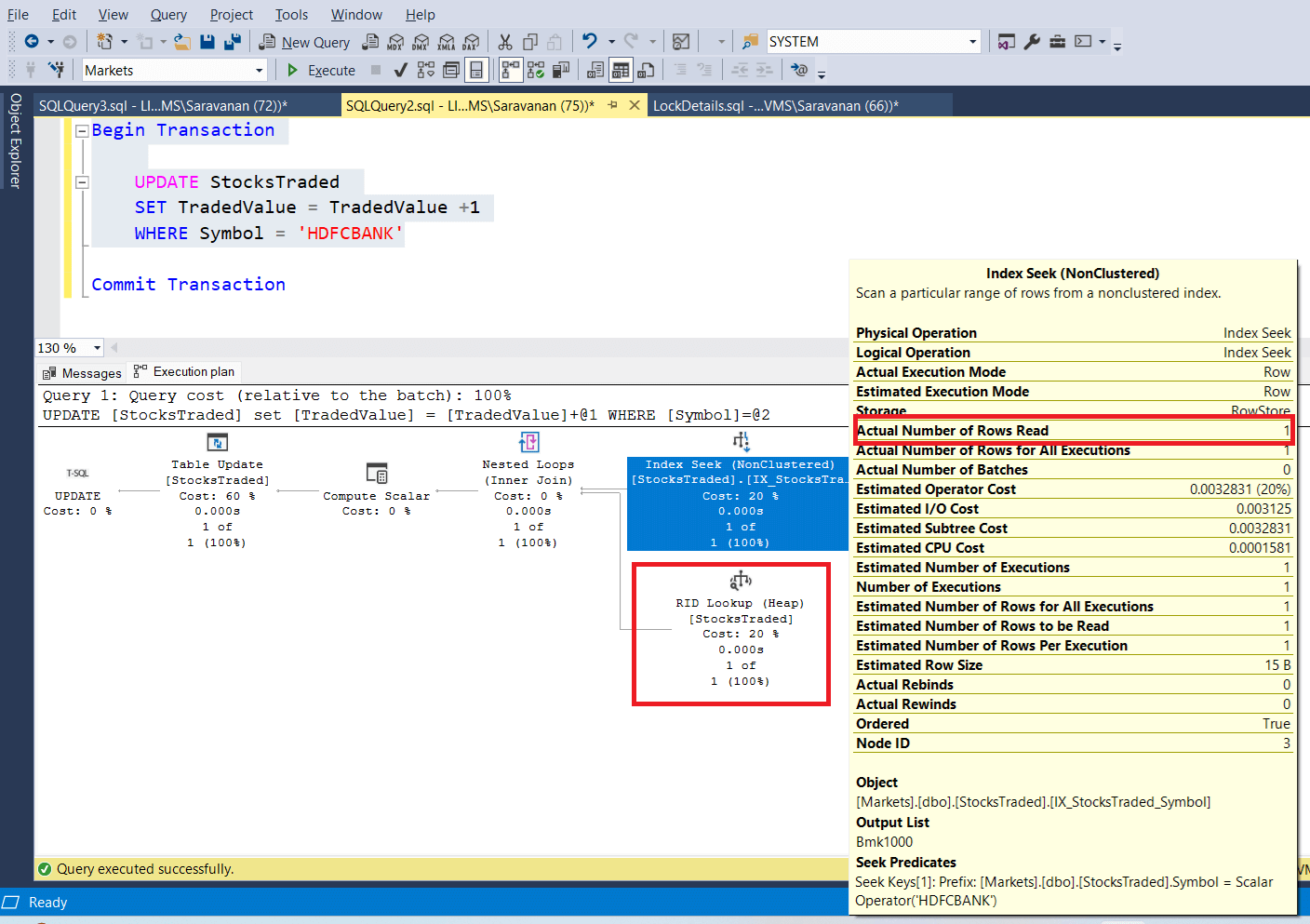
Let us run the update query, which updates a record, where the symbol is ‘HDFCBANK’. Also keep the transaction open to do the experiment. The following screenshots shows the update query and execution plan. It uses index seek to find the particular record (it just reads 1 record and not the entire records, which is 2947) and RID lookup to update the corresponding record in the heap.
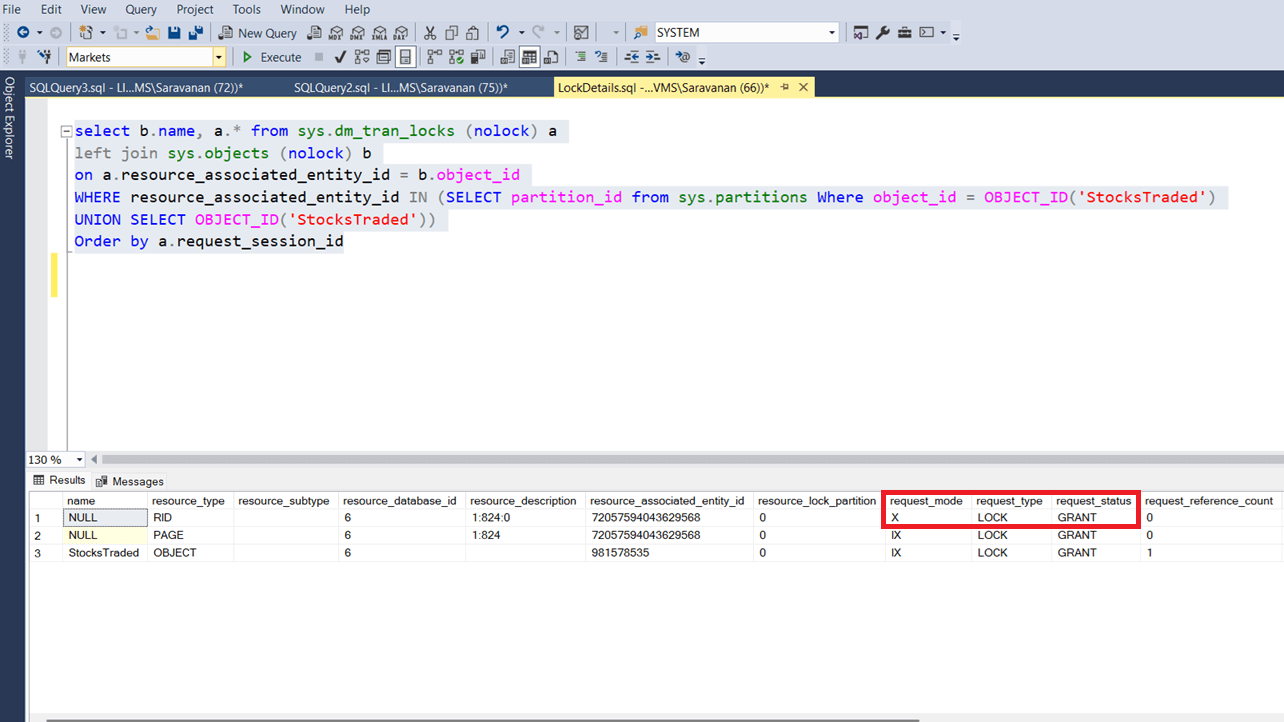
The following screenshot shows the current locks acquired on the StocksTraded table.
Let us run a select query where symbol is ‘BSE’ and see whether we get the output or get into blocking. 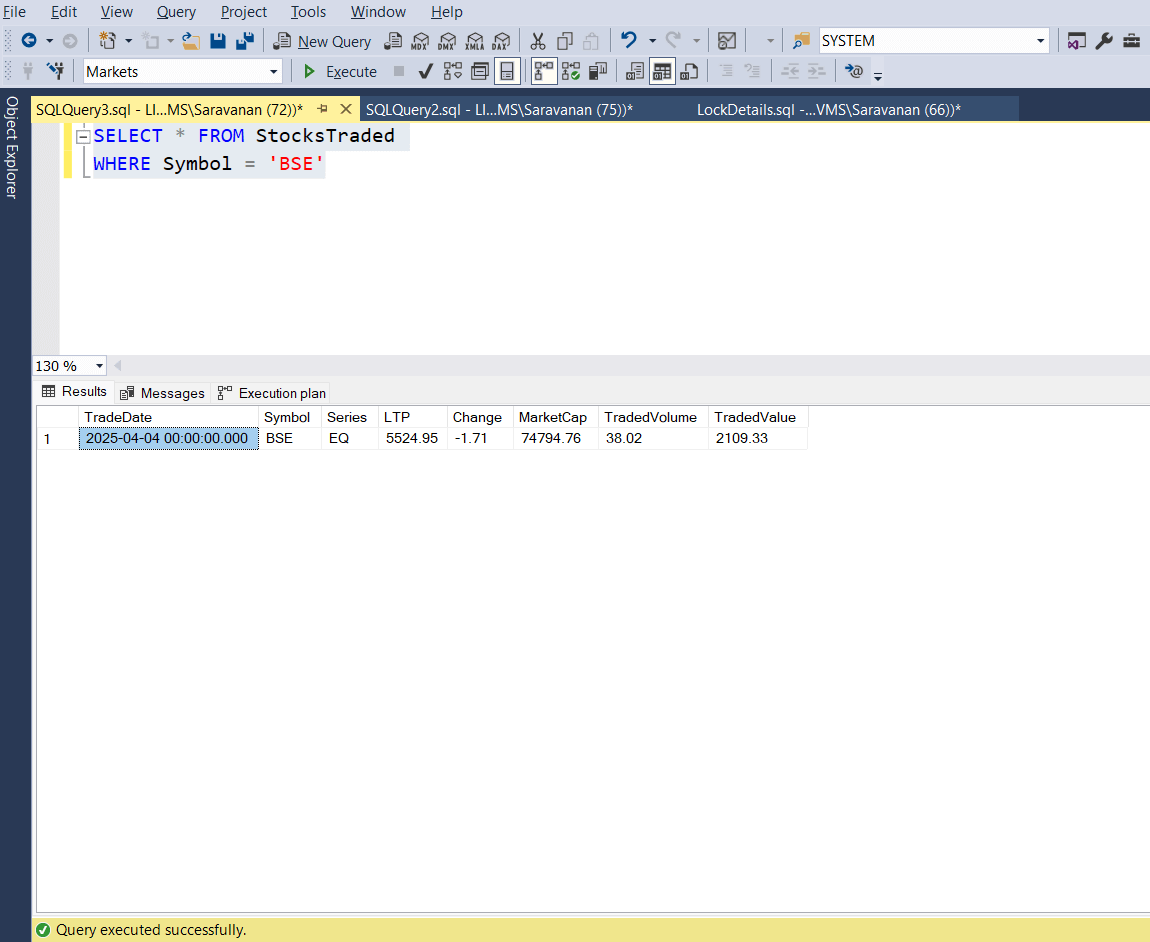
The above screenshot shows the select query is executed successfully and returned the results.
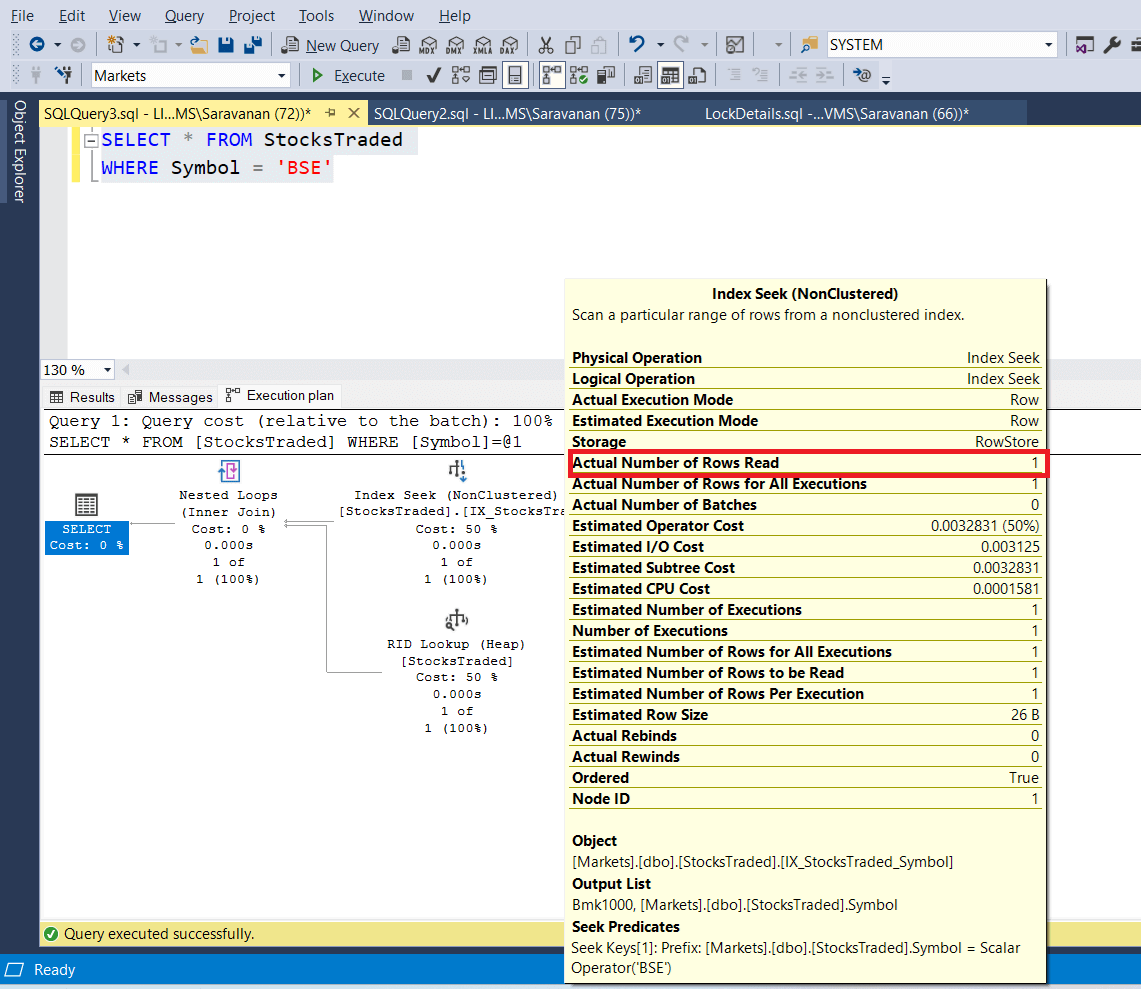
The following screenshot of execution plan clearly shows that; it uses index seek and actual number of rows read is just 1 row and not 2947 rows. Basically, it is not waiting for the row, which was exclusively locked for update operation, because it is not in the scope for select query where the symbol is 'BSE'. The point is the query engine is using Index seek to find the appropriate record and it doesn't need to scan the entire table. Remember, the full table scan needs to acquire shared lock on all the rows.
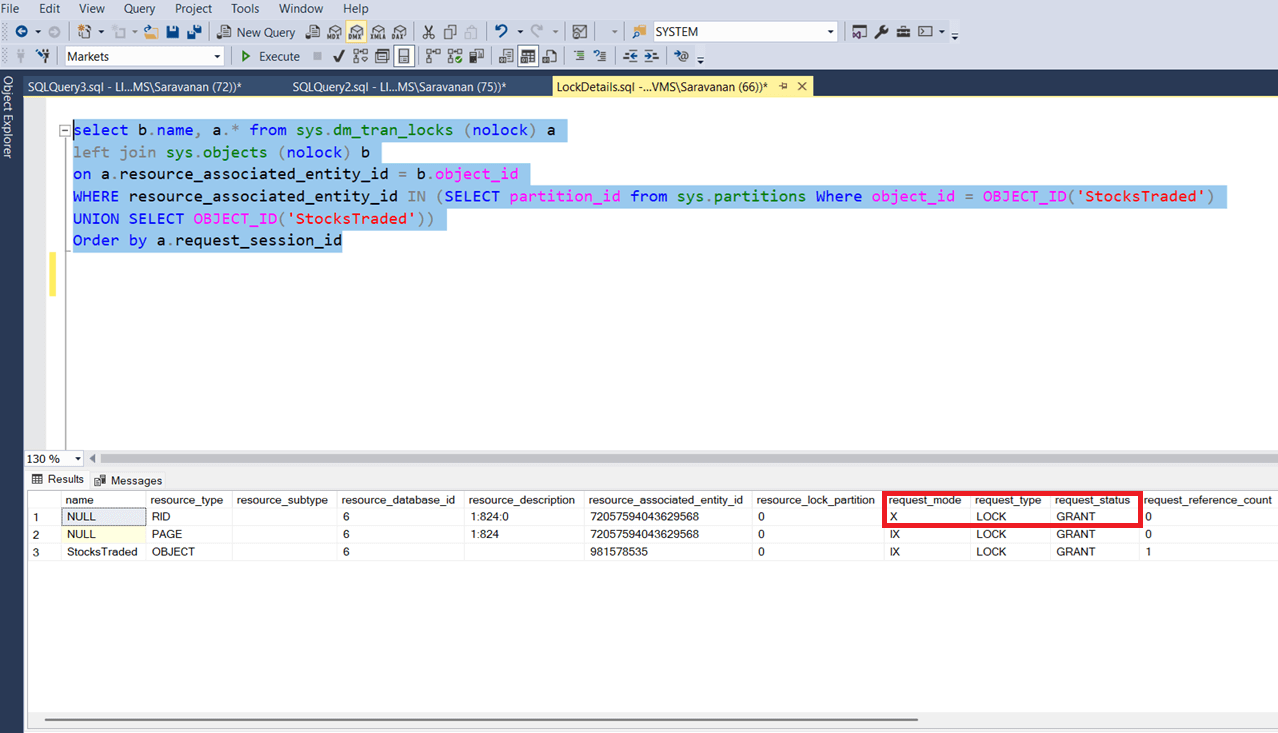
Now run a query again to get the current active lock details. The following screenshot shows the current lock details on the StocksTraded table. Since the select query / read operation from other session was not waiting for the lock to be acquired, there is no other lock request is waiting.
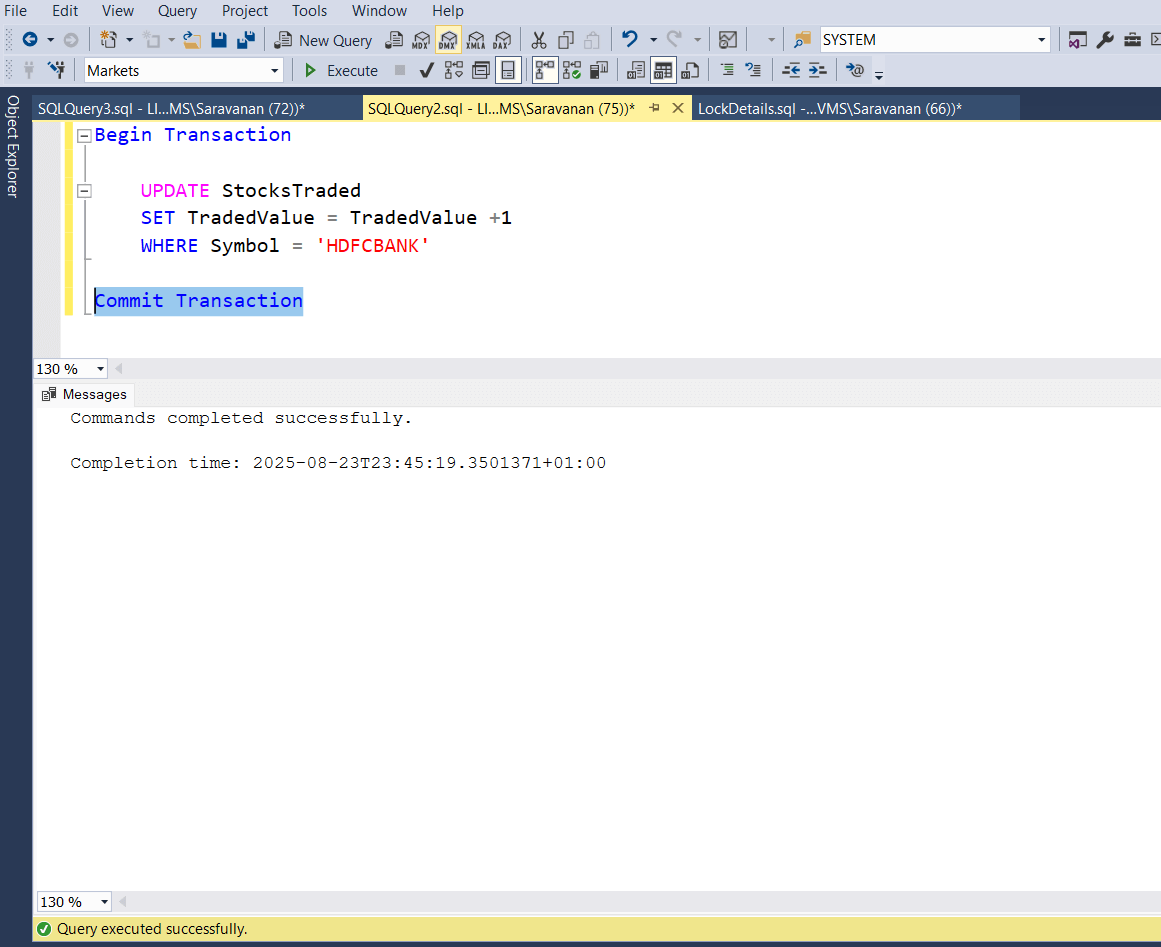
Now, let’s commit the update transaction, which we kept one to complete the experiment. the below screenshot 1 confirms that, the transaction is completed and screenshot 2 confirms that, there is no active locks on the StocksTraded table.
Screenshot 1
Screenshot 2
With this exercise we didn't get the blocking, since we created an index on the column, which is used to identify a record, and it narrowed down the read operation. Instead of doing the full scan, the query engine used index seek. So, efficient indexes can reduce the scope of locks, improve concurrency and avoid the blocking.
Conclusion
The above exercise proves that, when we have appropriate Index, it reduces the scope of the locks, improving the concurrency. The lock request is going to be only on the required resources and not beyond what is required. Primarily it will use the index to get the relevant RID reference to do lookup and return the results from the heap. So, the indexes are not only helping to speed up the query execution. It is playing a vital role to support the multiuser/session environment to avoid blocking. Updating a row in a table with no indexes (a heap), SQL Server typically locks the row or page being modified. However, without indexes, inefficient scans can increase the number of locks, potentially triggering lock escalation to a table lock, especially for large tables or non-selective updates. Adding appropriate indexes can reduce the scope of locks and improve concurrency by enabling more precise data access. You can try this exercise using like or range operators in the filter criteria and you will learn/understand more how much the index is helping beyond speed-up the query execution.

