

In the last year I’ve published articles on indexes to include Indexes: When Column Selectivity Is Not Always A Requirement – SQLServerCentral and Query Optimizer Suggests Wrong Index and Query Plan -- Why? – SQLServerCentral. This article is a continuation of just how the optimizer interacts with the index wizard.
We’ve all heard and read that you should always define an index (for a specific query) using first the columns used in an equality expression in the WHERE clause, but today let’s look at an example and see just what happens.
The Scenario
Consider the following query. This is from AdventureWorks 2017, modified by a script from Jonathan Kehayias (http://sqlskills.com/blogs/jonathan and with the attached script. The database has the Sales.SalesOrderHeader table increased from 31,465 rows to 1,258.600 rows, dropping all non-clustered indexes, and skewing the data for SalesPersonID = 289 (to have more rows)):
SET STATISTICS IO, TIME ON
GO
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WHERE [Status] = 4
AND SalesPersonID = 289
AND ModifiedDate >= '1/1/2014'
ORDER BY [Status],SalesPersonID,ModifiedDate
GO
SET STATISTICS IO, TIME OFF
GO
We get a result set of rows with 58,967 rows, 29295 logical reads, cpu Time of 588 ms, an ElapsedTime of 584 ms (the times are from the XML execution plan). Interestingly, the times from the XML execution plan are not the same as from the SET STATISTICS ON results – wonder which is correct; maybe that’s my next article. The execution plan looks like the image below:
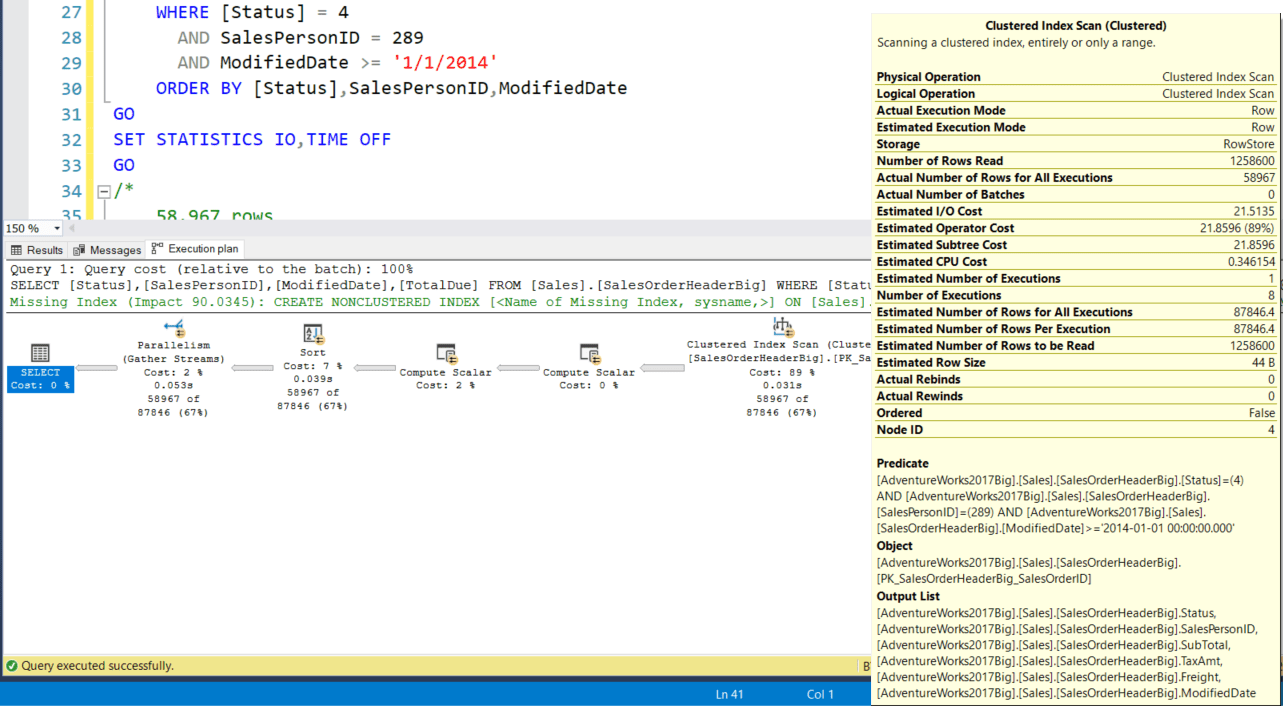
This plan has a clustered index scan and a query cost = 24.4894.
I also tried changing the order of the conditions in the WHERE clause, but the results (and execution plan) were identical except column ordering in the Predicate where the parameter conditions were in the same order as specified in the WHERE clause.
The query plan also suggests a missing covering index of
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate
ON Sales.SalesOrderHeaderBig ([Status] ASC, SalesPersonID ASC, ModifiedDate ASC)
INCLUDE (TotalDue)
Notice that the suggested index columns, Status and SalesPersonID, are in the same order as the WHERE clause. The first 2 columns use a ‘=’ connector and the third column uses a ’ >=’ connector. Also, note that SS2019 parameterized the query.
Now let’s look at 3 different indexes (the first being the suggested index) and the other two having the same columns as the first, but in a different order.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate
ON Sales.SalesOrderHeaderBig ([Status] ASC, SalesPersonID ASC, ModifiedDate ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GO
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate
ON Sales.SalesOrderHeaderBig (SalesPersonID ASC,[Status] ASC, ModifiedDate ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GO
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID
ON Sales.SalesOrderHeaderBig ( ModifiedDate ASC,[Status] ASC, SalesPersonID ASC)
INCLUDE (TotalDue)
WITH (Data_Compression = ROW)
GO
Notice I use Row Compression in all 3 indexes. In my 12+ years using row compression I have yet to find a detrimental effect on performance and in almost all cases have had substantial performance improvements with reduced logical reads (SQL Server 2008 Table Compression (logicalread.com).
So, if we rerun the original query we still get 58,967 rows and a non-clustered index seek but with an execution cpu of 41 ms, 551 ms elapsed time, logical reads = 174, and a query cost of 0.306444 with the following query plan:
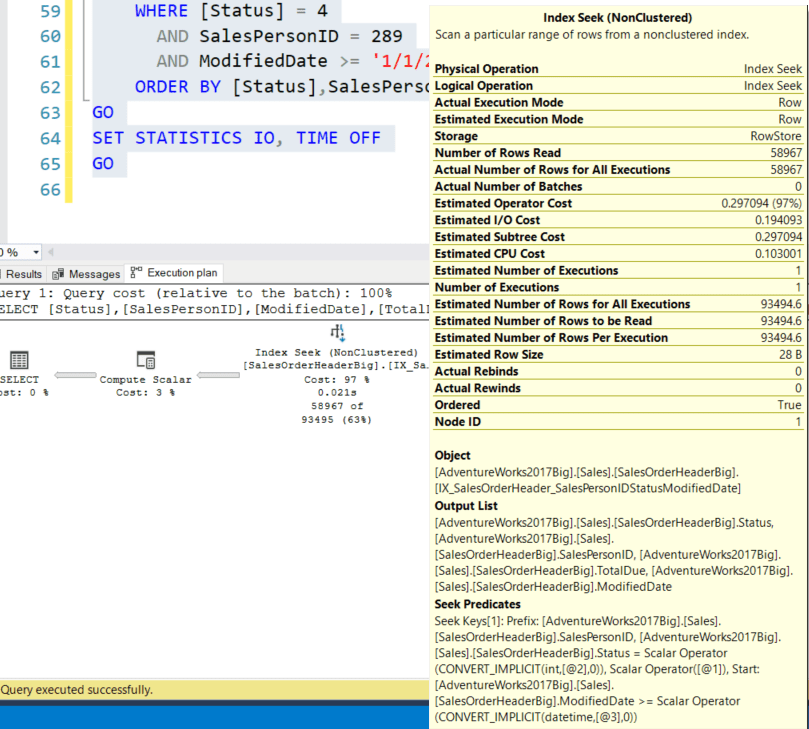
We now get a Seek Predicate on all three index columns, but WAIT! The query plan used the second index (not the suggested one): IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. Hmmm, the query optimizer suggested one index and the actual execution used a different one (Status and SalesPersonID reversed) in the definition. We’ll talk more about this a little below, but first, let’s force the query to use the original missing index on the original query:
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WITH (INDEX (IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate))
WHERE [Status] = 7
AND SalesPersonID = 289
AND ModifiedDate BETWEEN '1/1/2014' AND '6/30/2021'
ORDER BY [Status],SalesPersonID,ModifiedDate
We get the same result set (58,967 rows) but with cpu = 42 ms, elapsed time = 547, logical reads = 182, and a query cost of 0.30707 with the following query plan:
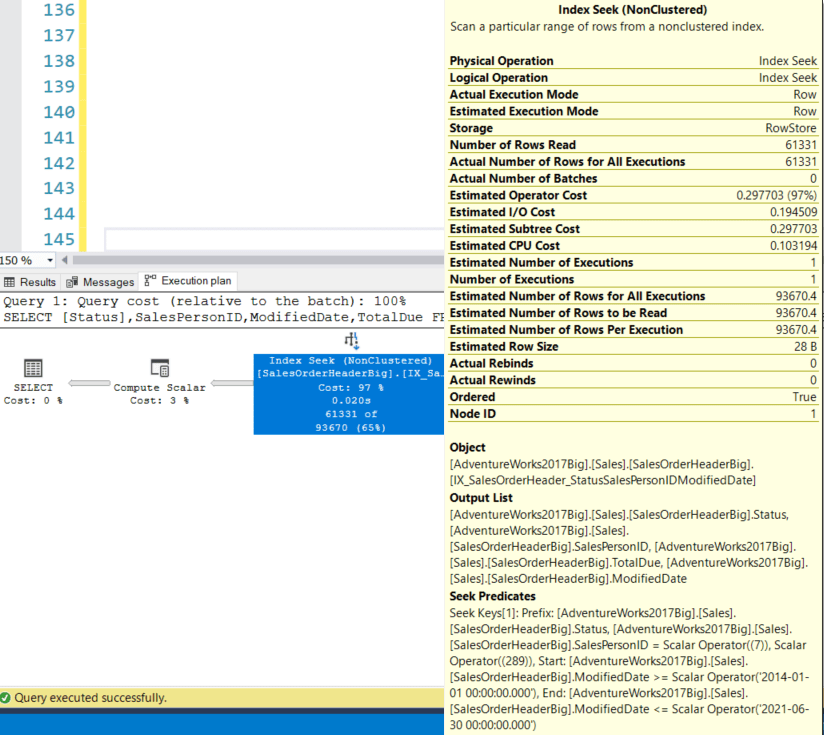
Essentially the same query plan, but just slightly higher on cpu time, logical reads, and query cost. Now the Seek Predicate parameters are Status, SalesPersonID, and ModifiedDate. Again, we’ll talk about this a little later.
But, for completeness let’s force the query to use the 3rd index (ModifiedDate column first in index definition):
SET STATISTICS IO,TIME ON
GO
SELECT [Status],SalesPersonID,ModifiedDate,TotalDue
FROM Sales.SalesOrderHeaderBig
WITH (INDEX (IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID))
WHERE [Status] = 4
AND SalesPersonID = 289
AND ModifiedDate BETWEEN '1/1/2014' AND '6/30/2021'
ORDER BY [Status],SalesPersonID,ModifiedDate
GO
SET STATISTICS IO,TIME OFF
GO
We get the same result set (58,967) but with an execution cost of 3.43921, cpu = 118 ms, elapsed time = 535, logical reads = 2868, and a query cost of 3.43921 with the following query plan:
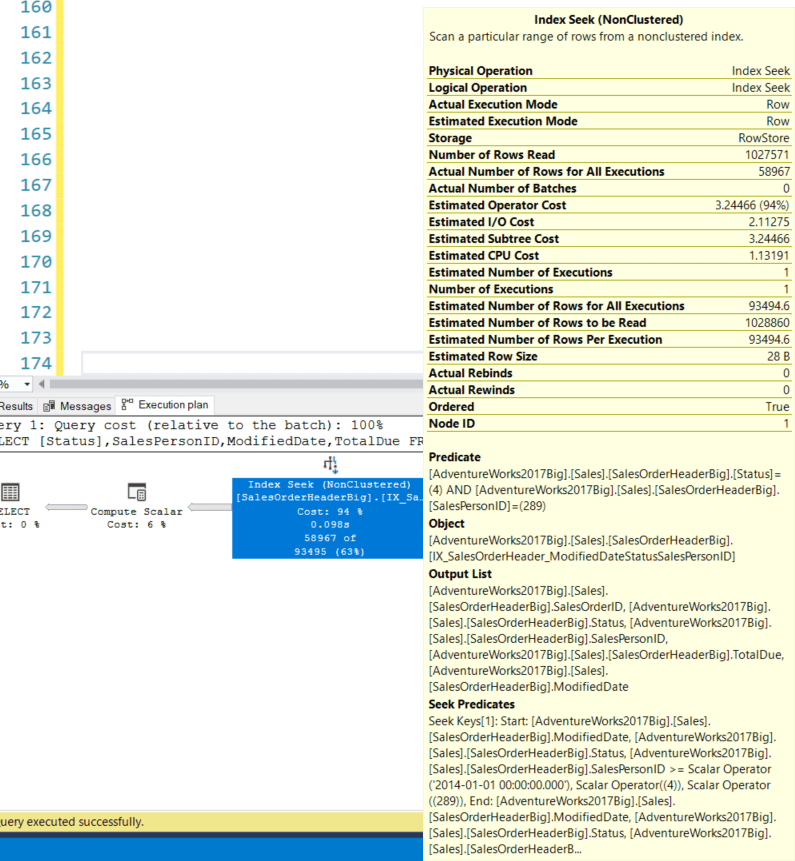
Still overall reasonable performance, but now in this query plan, we have a Seek Predicate on ModifiedDate and a Predicate on Status and SalesPersonID columns. The jump in logical reads is caused by how the data is organized in the applicable index. We will show that below. But in the meantime all 3 indexes improved performance – just one better than the two others and it was not the suggested index.
The Why?
First, let’s just look at the data and how each column is populated. If we run the following query:
dbcc showcontig ('Sales.SalesOrderHeaderBig') with tableresults, all_indexes, all_levels;we get (screen shot of part of the result set):
| IndexName | IndexID | Level | Pages | Rows |
| PK_SalesOrderHeaderBig_SalesOrderID | 1 | 0 | 29,040 | 1,258,600 |
| PK_SalesOrderHeaderBig_SalesOrderID | 1 | 1 | 51 | 29,040 |
| PK_SalesOrderHeaderBig_SalesOrderID | 1 | 2 | 1 | 51 |
| IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate | 3 | 0 | 3,485 | 1,258,600 |
| IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate | 3 | 1 | 16 | 3,485 |
| IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate | 3 | 2 | 1 | 16 |
| IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate | 4 | 0 | 3,484 | 1,258,600 |
| IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate | 4 | 1 | 15 | 3,484 |
| IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate | 4 | 2 | 1 | 15 |
| IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID | 5 | 0 | 3,484 | 1,258,600 |
| IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID | 5 | 1 | 16 | 3,484 |
| IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID | 5 | 2 | 1 | 16 |
Each index has a Root page, one intermediate level, and one leaf (data) level with almost equal space requirements for each non-clustered index. But this doesn’t tell us how the data is organized within each index.
Let’s look at each index and how it sorted the data. The suggested index IX_SalesOrderHeader_StatusSalesPersonIDModifiedDate uses Status for the first column followed by SalesPersonID and the Modified Date. Let’s look at a partial representation of the data sorted by each index as shown below:
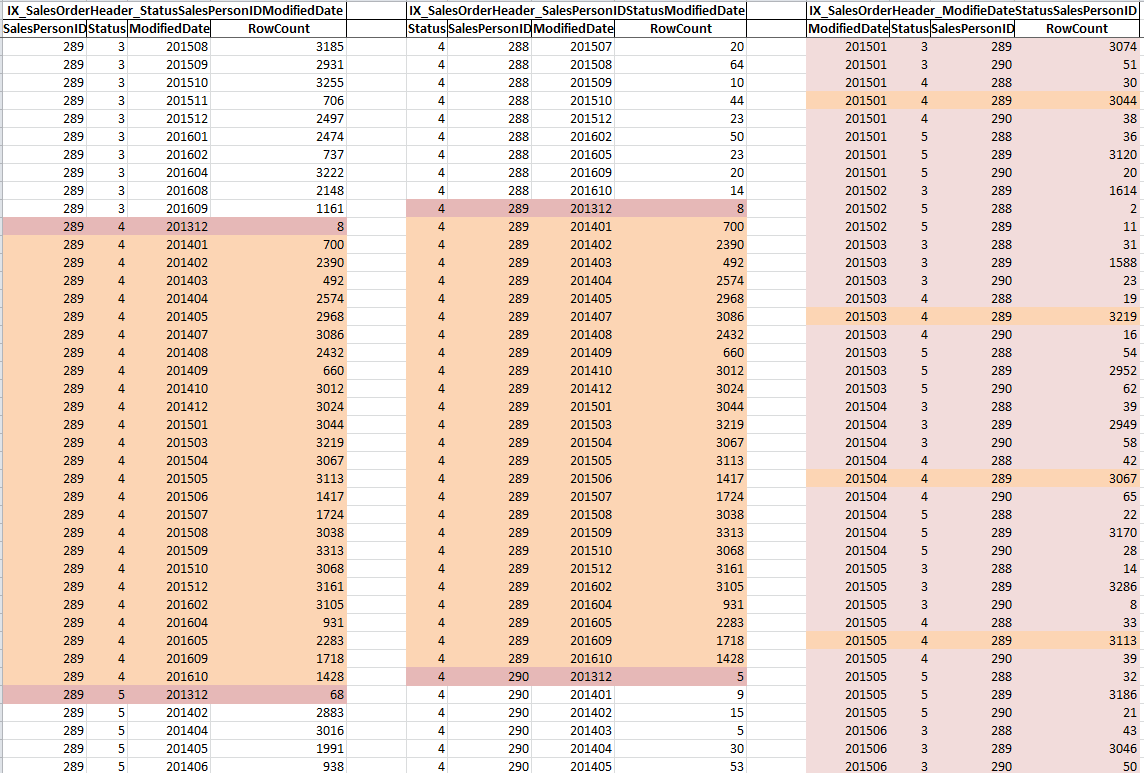
In this case, when the equality operator for Status and SalesPersonID is specified, the optimizer can go directly to Status = 4 and SalesPersonID = 289 rows and because of the index definition of ModifiedDate being the third column, that data is already sorted. So the optimizer can go directly to the specified rows (this is a seek) and only return those rows (this is a Seek Predicate) and the same applies to the second index IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate. The only difference is how the data is stored within the index pages. Notice that the IX_SalesOrderHeader_SalesPersonIDStatusModifiedDate index has one less intermediate page and one less leaf level page.
However, when you look at IX_SalesOrderHeader_ModifiedDateStatusSalesPersonID you can see the data is sorted by date but has to skip multiple rows to get to the next applicable Status and SalesPersonID. This causes considerable more page reads as shown in the earlier results.
Although I’ve heard many times that the index wizard maintains the same order of the column operators in the WHERE clause using the equality operator. I cannot prove this, but I’m not aware of any different circumstances.
Conclusion
So, when writing queries and indexes for those queries you need to be aware of what criteria is to be used in the query WHERE clause. Index column select and order need to use parameters for equality criteria first, and then possibly take advantage of ordering in greater than or less than WHERE clauses.
The attached script contains all the referenced T-SQL statements as well as comments and most result sets.
