

Introduction
In my previous article named An Introduction to Azure Synapse Analytics Workspace,I discussed the step-by-step process to create a Synapse workspace and how to use its components and features. Another article named An Introduction to Azure Cosmos DB, has the details required for the initial understanding of Cosmos DB. In this article, I will discuss about the step-by-step process for configuration and use of Azure Synapse Link.
Azure Synapse Link is a cloud-native hybrid transactional and analytical processing (HTAP) capability that helps to create integrations between Azure Cosmos DB and Azure Synapse Analytics. Real time analytics can be run over the operational data in Azure Cosmos DB. Azure Synapse Link is in preview mode as of November 2020 and available for Azure Cosmos DB SQL API containers or for Azure Cosmos DB API for Mongo DB collections.
Query on Cosmos DB data from Synapse Workspace
Let's see how to query data in CosmosDB from Azure Synapse. First, I create an account and select the API as Core (SQL). I keep other property values as default.
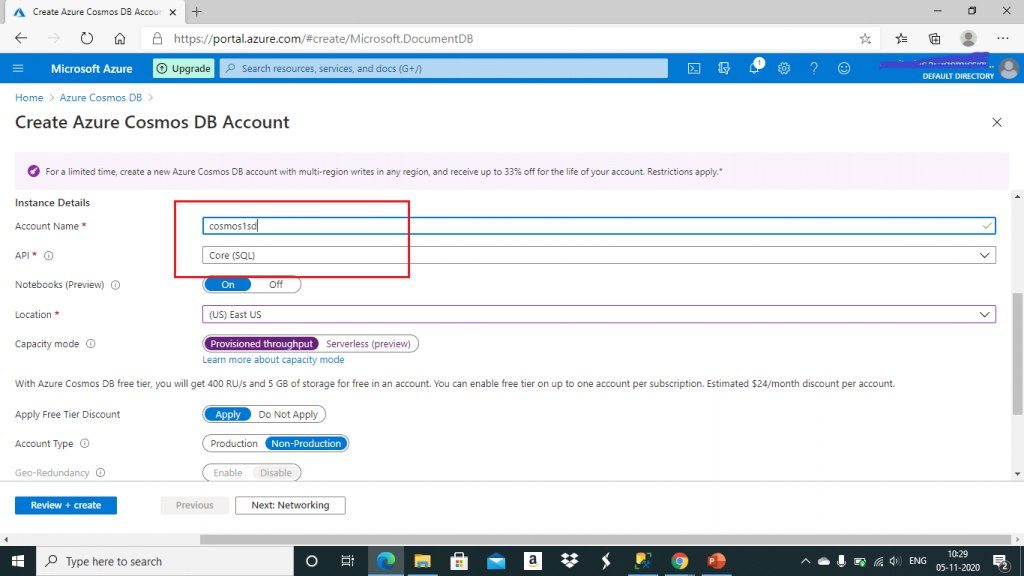
Once the Cosmos DB account is created, I go to Features pane and enable the Azure Synapse Link.
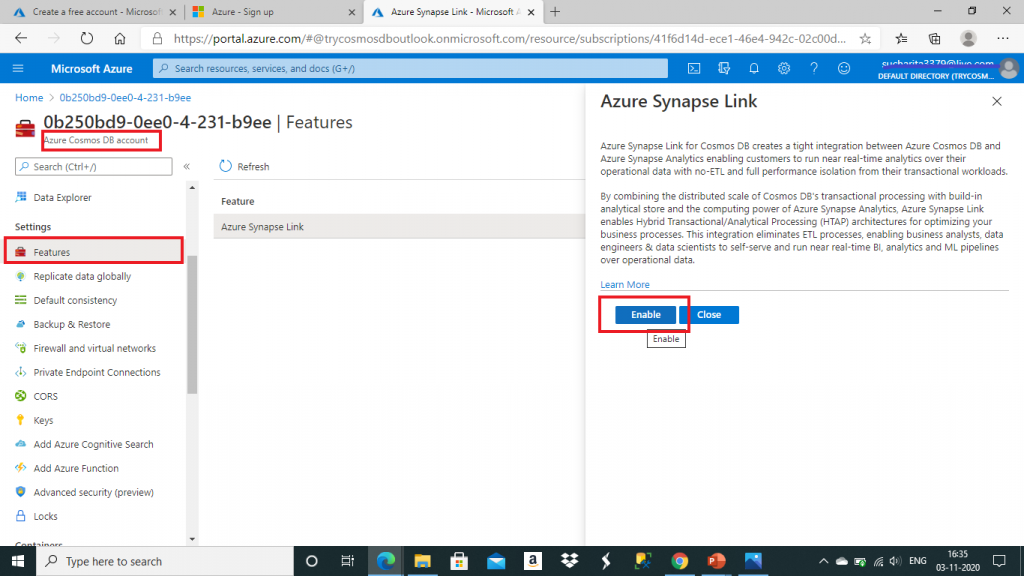
I need to enable Analytical store on the Cosmos DB containers. It will help to automatically replicate operational data from Cosmos DB transactional store to the analytical store. Real time analytics will be executed on the data available in the Analytical store. We will do that after the next few steps.
I need to create the database in Cosmos DB. I go to Data Explorer and then press the New Container button. In the Add Container popup window, I create a new database and select the throughput as 400. Here, I may select an existing database as well for creation of the container.
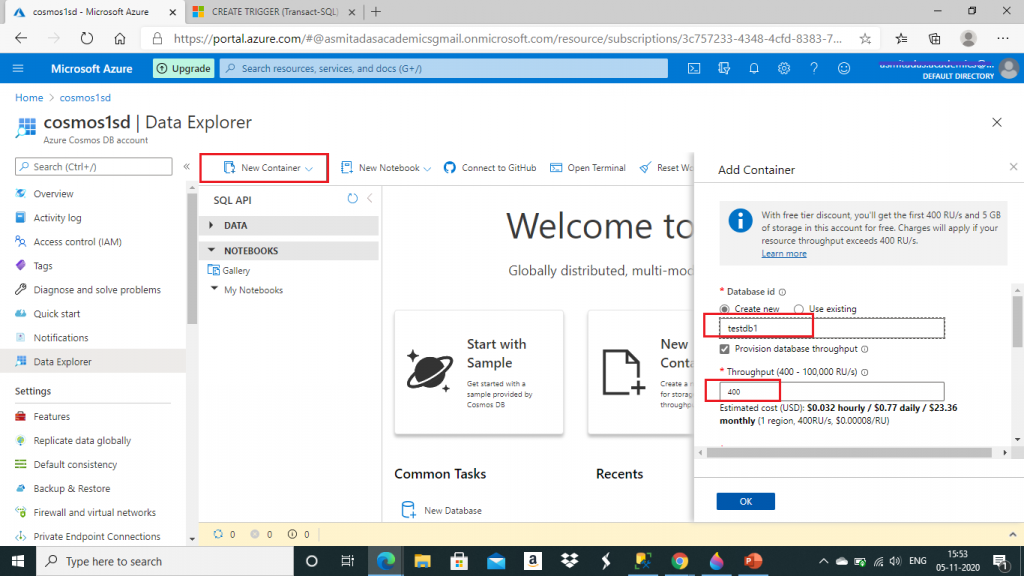
I give a name for the container and set the Analytical store option as On. Then, I press the OK button.
Enabling Azure Synapse Link is a prerequisite for enabling the Analytical store.
Analytical Store
This is a fully isolated column store. This is used for large-scale analytics against operational data in Azure Cosmos DB. There is no impact to the transactional workload due to the analytical queries as the analytical store is separate from the transactional store. Inserts, updates and deletes to operational data are automatically synced from transactional store to analytical store in near real time. So, the overhead of ETL process to transfer data from transactional store to analytical store is not required. Column store format is suitable for large-scale analytical queries to be performed in an optimized manner. Also, Azure Cosmos DB analytical store is schematized to optimize for analytical query performance.
Azure Synapse Link is used to build no-ETL HTAP solutions by directly linking to Azure Cosmos DB analytical store from Synapse Analytics. It enables to run near real-time large-scale analytics on the operational data.
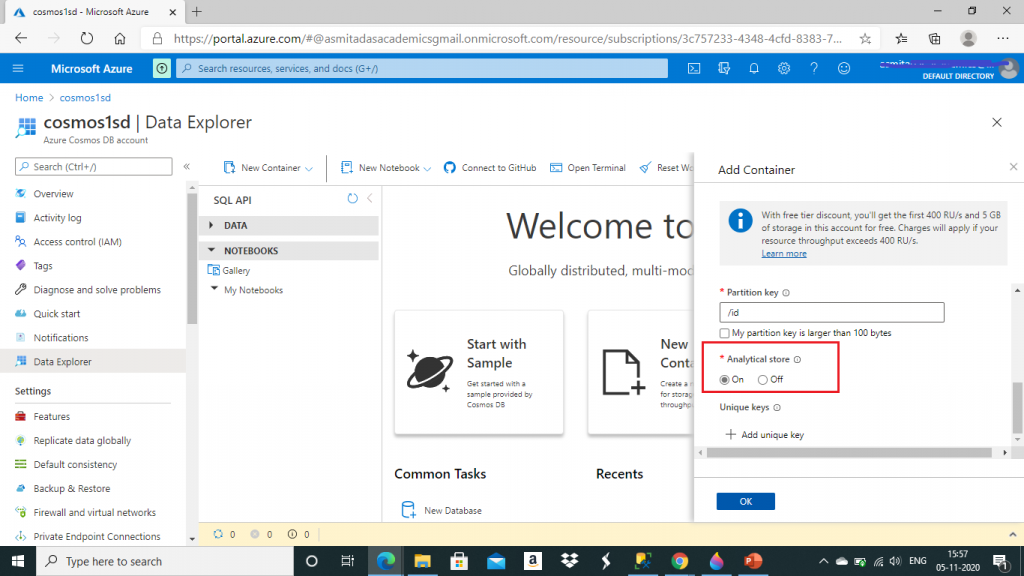
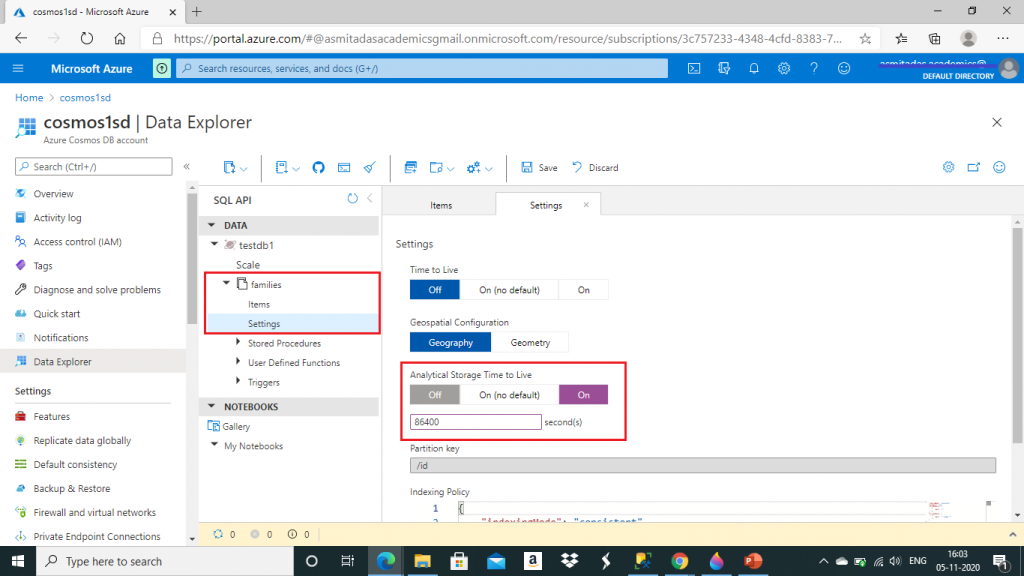
The container is now created with an Analytical Storage Time to Live (AnalyticalTTL) value set to -1. This is the default value. This value decides the default duration of the replicated operational data in the analytical store. The value -1 means indefinite retention. I change this value to 86400 seconds, i.e. one day.
Uploading Data
I created two more containers named cord19 and ecdcCases under the database named testdb1. I keep Analytical store setting as On and set Analytical Storage Time to Live (AnalyticalTTL) value as 86400 seconds as done for the first container. Now, I upload a JSON file named cord19.json in cord19 container.
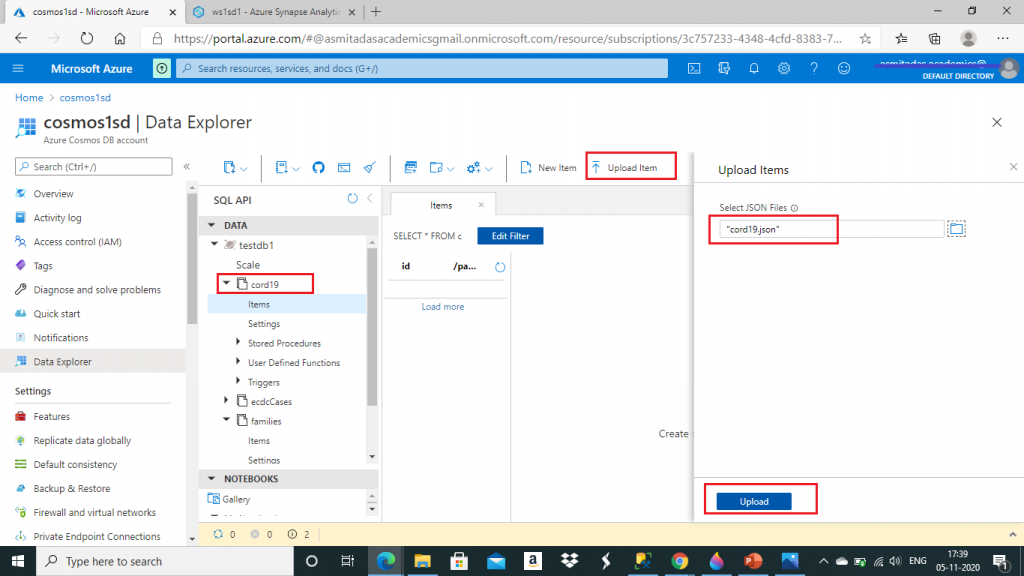
Similarly, I upload ecdcCases.json file in the ecdcCases container.
The sample JSON files are available in the following links:
- European Centre for Disease Prevention and Control (ECDC) Covid-19 Cases - Azure Open Datasets Catalog (microsoft.com)
- COVID-19 Open Research Dataset - Azure Open Datasets Catalog (microsoft.com)
Create the Synapse Workspace
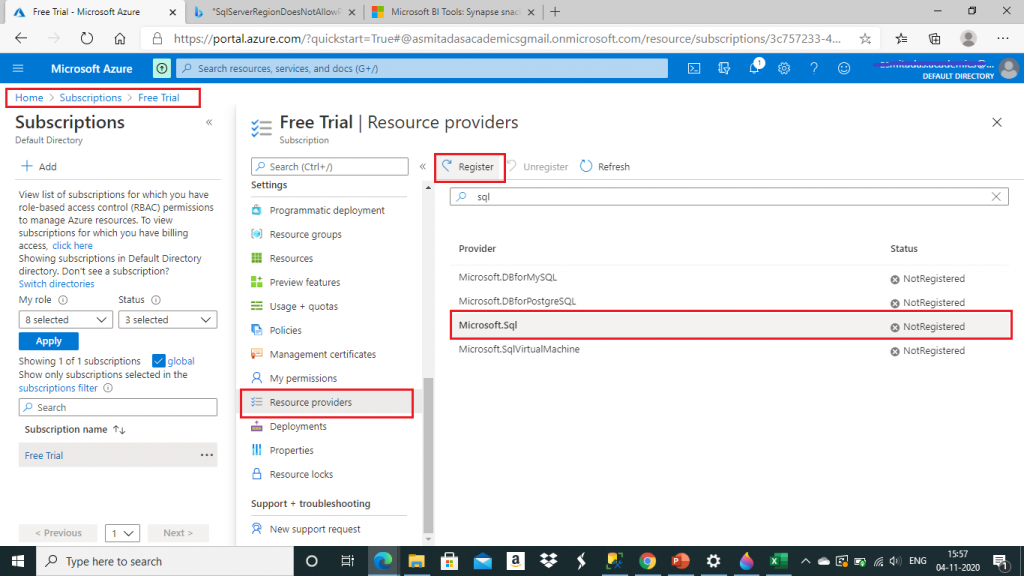
I create a new Synapse workspace. For the first time, the synapse resource provider needs to be registered to the Subscription. I press the link given and complete the registration.

I give details for the storage account. The storage account container needs to have adequate access. Otherwise, there will be error in creating the workspace. We do this be ensuring the checkbox shown below is checked.
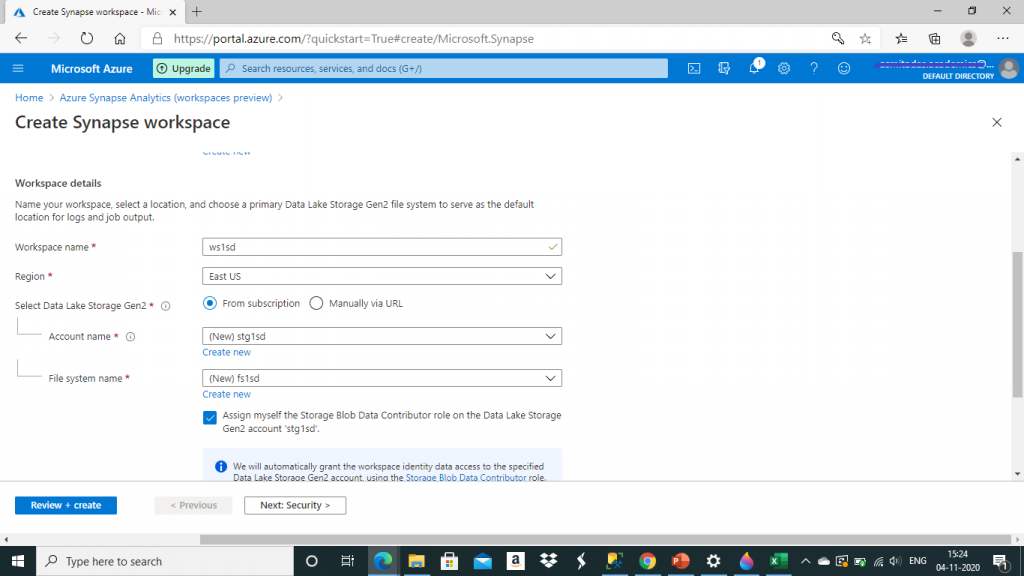
I provide credentials for database and press the 'Review + Create' button.
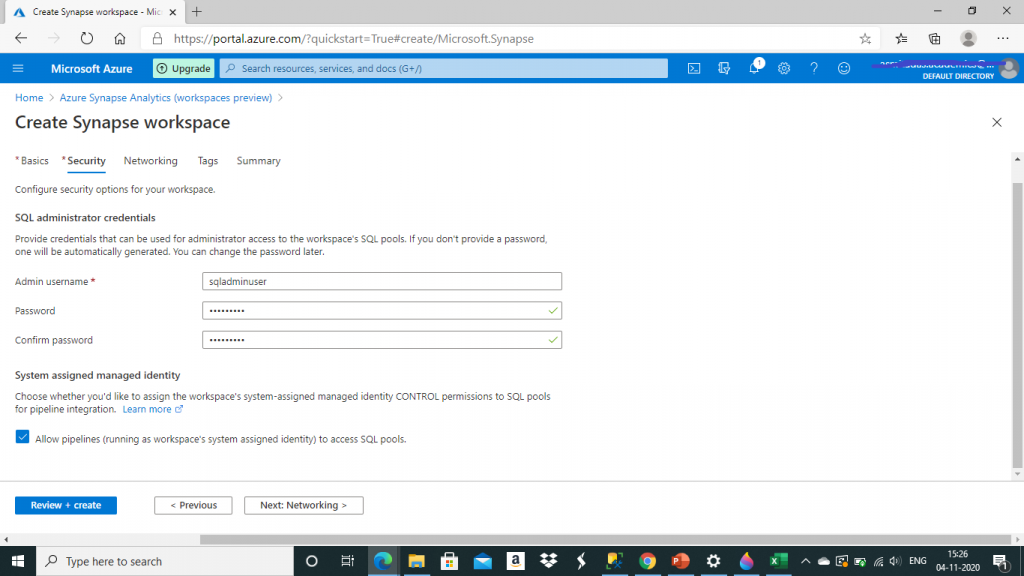
Here, I get an error that the creation of the new Azure SQL database is not allowed. After doing some analysis, I could understand the actual reason for this error. This error is not because of unavailability of SQL Server resource in the Azure region. This error is due to the reason that SQL Server is not registered as an allowed resource provider on my Azure Subscription.
Registering the Resource Provider
I go the Resource provider pane of my Subscription. I select the Microsoft.Sql resource provider and press the Register button. Once Registration is completed, I try to create the Synapse workspace again. This time the resource creation is successfully completed.
Load Data and Check Our Work
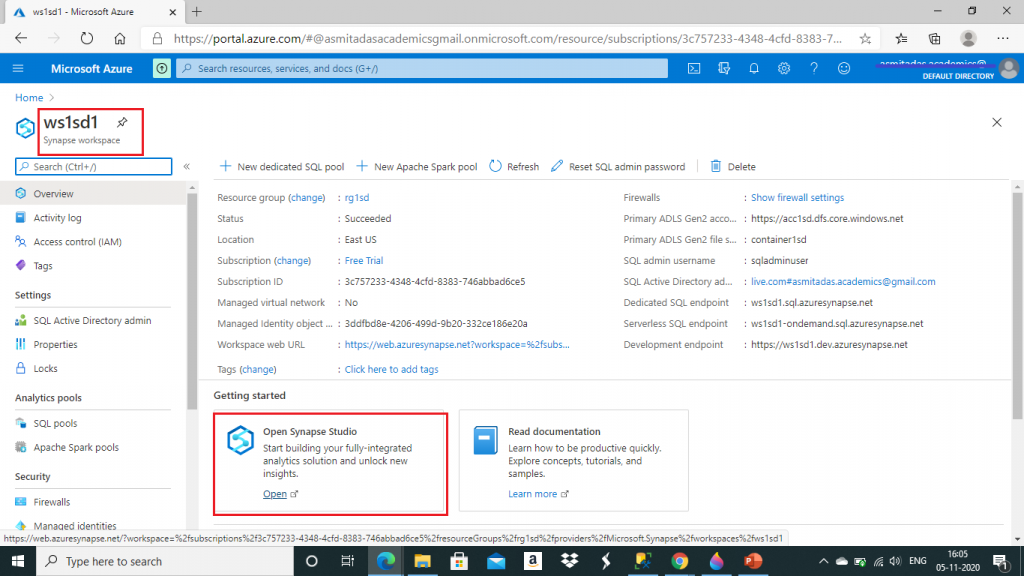
Once the Synapse Workspace is created, I go to the Overview. Then, I open Synapse Studio.
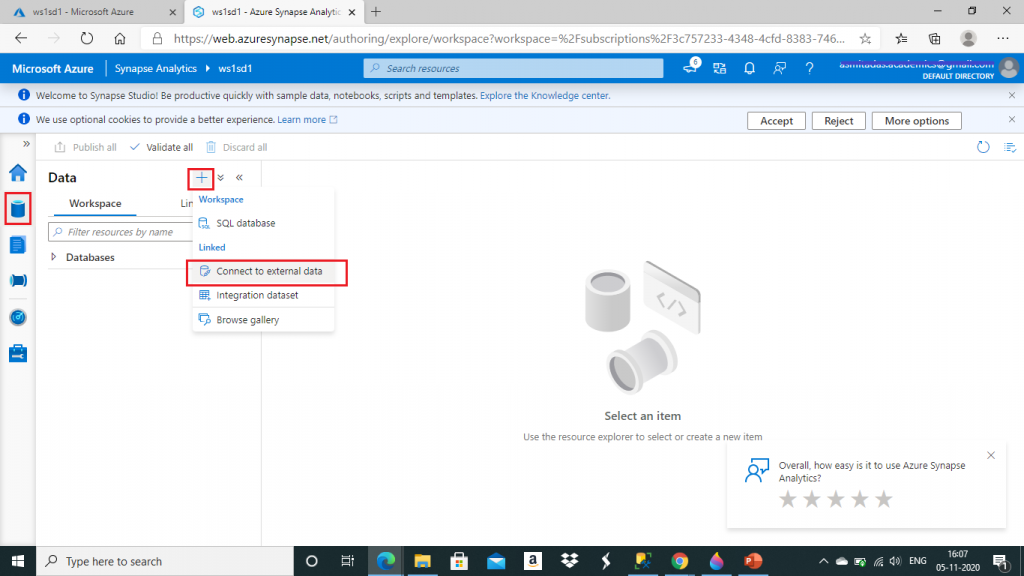
In the Synapse Studio, I go to the Data tab and click the link to Connect to external data. I will connect the Azure Cosmos DB from here.
One pop-up window opens with the external data source options to connect. I select Azure Cosmos DB (SQL API) and press the Continue button.

In the next screen, I create a linked service. Here, I need to provide a name for the linked service. I also select the Cosmos DB account name and the database name from drop-down list and press the Create button.
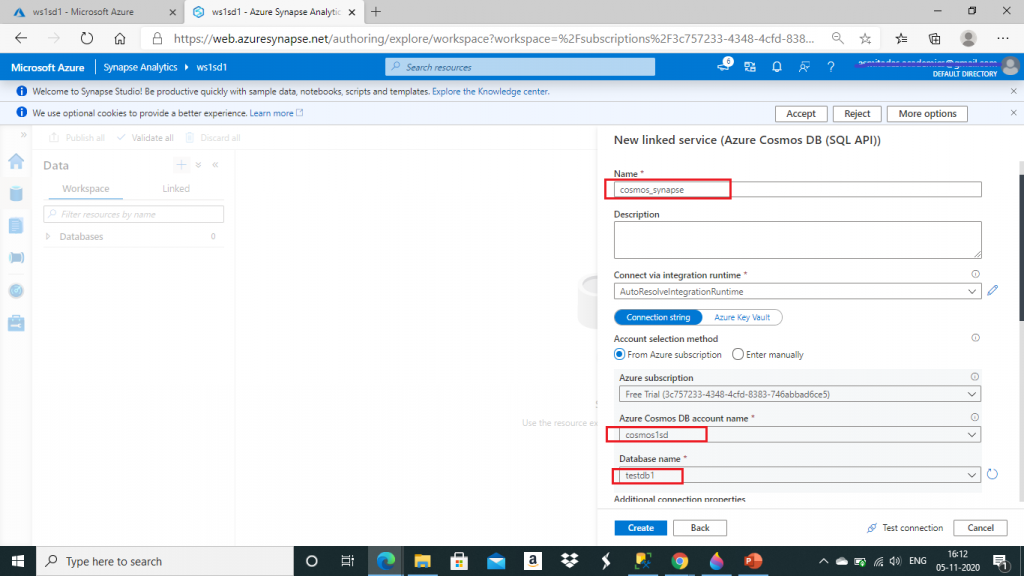
The linked service for Azure Cosmos DB is created. I go to Manage tab and can see the linked service.
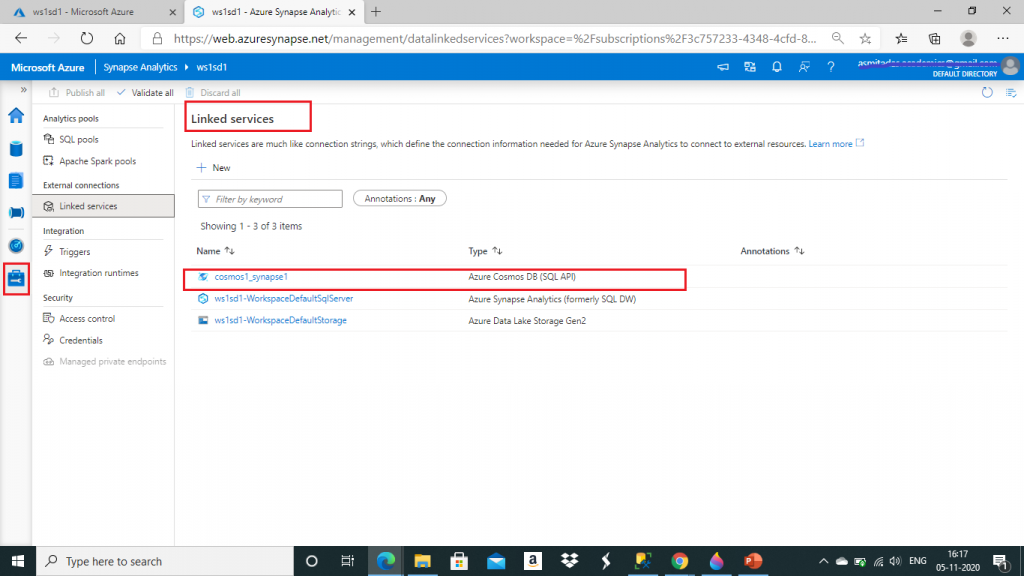
I go to the Develop tab and click on the '+' sign and SQL script. A new script will be open.

I connect to Synapse SQL serverless and write a Select query. In the Properties window at right, I select a name for the script. I save the script using the Publish button. I execute the query and the result in row-column format is displayed at the bottom. I use the serverless SQL pool (earlier known as SQL On-demand) to analyze data in Azure Cosmos DB containers enabled with Azure Synapse Link. Familiar T-SQL syntax is used to query data from the analytical store in near real time without affecting the performance of transactional workloads.
For querying Azure Cosmos DB, the OPENROWSET function is used. It is possible to store data and query results from Azure Cosmos DB in Azure Blob Storage or Azure Data Lake Storage by using create external table as select (CETAS).
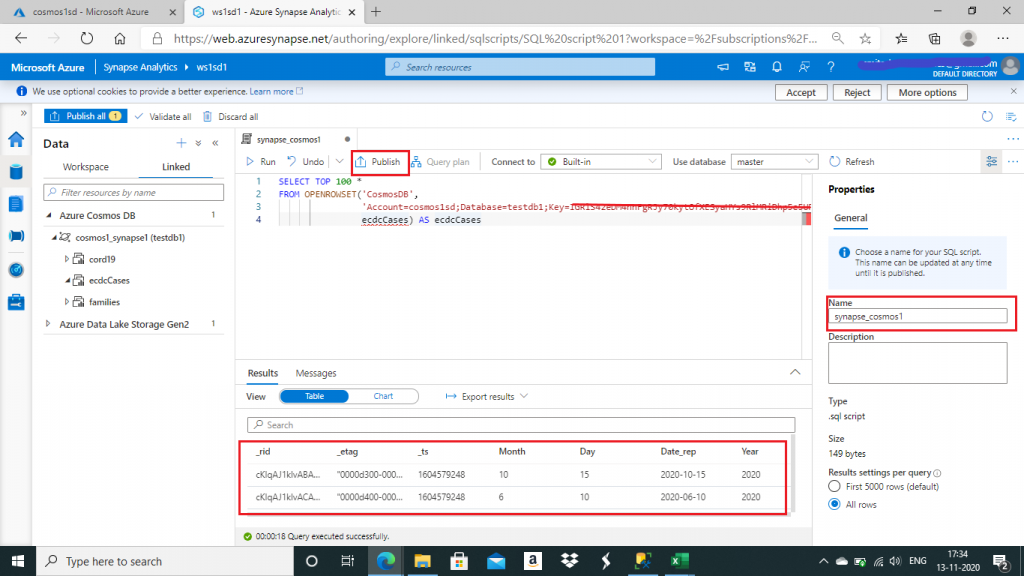
The SQL script is given below:
SELECT TOP 100 *
FROM OPENROWSET('CosmosDB',
'Account=cosmos1sd;Database=testdb1;Key=<key value>',
ecdcCases) AS ecdcCases
SELECT TOP 100 *
FROM OPENROWSET('CosmosDB',
'Account=cosmos1sd;Database=testdb1;Key=<key value>',
cord19) AS cord19I retrieve the top 100 records from ecdcCases and cord19 using OPENROWSET function. This function returns all the properties from the Azure Cosmos DB items as available in the mentioned container.
The serverless SQL pool uses the following parameters with OPENROWSET function: 'CosmosDB', 'Azure Cosmos DB connection string' and Cosmos DB container name. The container name is not written within quotes. The container name should be wrapped within square brackets ([] ) if there is a special character in the name.
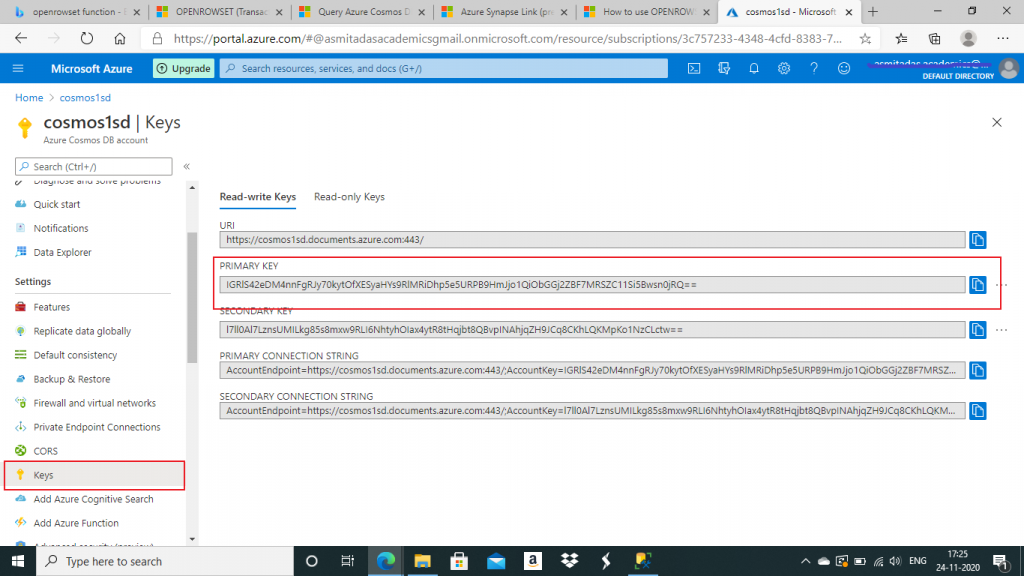
The first parameter is a hard coded value. The second parameter i.e. the connection string has few components: account name, database name, Region and the Key. The region is the optional component and contains the region of the container's analytical store. I retrieved the primary key value from the Keys pane of the Cosmos DB account and pasted in the OPENROWSET function parameter value.
I can use the WITH clause of the OPENROWSET function to retrieve only a subset of properties. The exact column types also can be mentioned.
In Azure Cosmos DB, complex data models are represented by composing them as nested objects or arrays. When the OPENROWSET function reads the nested objects and arrays, they are represented as JSON strings in the query result. I may use the JSON functions to retrieve the data as SQL columns.
- JSON_VALUE: Extracts a scalar value from a JSON string
- JSON_QUERY: Extracts an object or an array from a JSON string
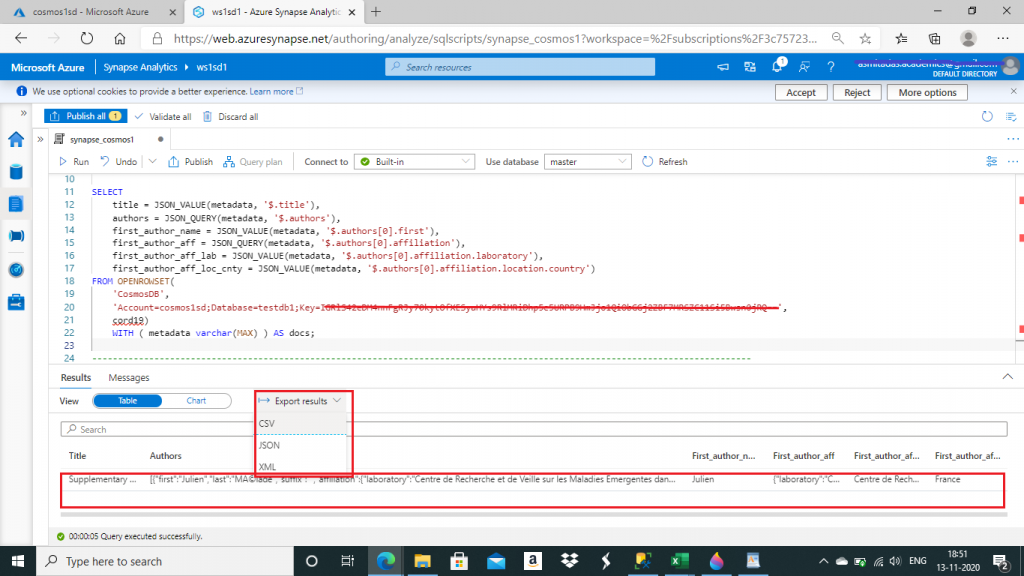
I write the following query to first retrieve the metadata property of the items from the cord19 container using WITH clause of the OPENROWSET function. Then, I use JSON_VALUE to extract the scalar values and JSON_QUERY to retrieve the array values from the JSON string of metadata. I retrieved different levels of values from the JSON string and output them as simple SQL column values.
--nested objects and arrays
SELECT
title = JSON_VALUE(metadata, '$.title'),
authors = JSON_QUERY(metadata, '$.authors'),
first_author_name = JSON_VALUE(metadata, '$.authors[0].first'),
first_author_aff = JSON_QUERY(metadata, '$.authors[0].affiliation'),
first_author_aff_lab = JSON_VALUE(metadata, '$.authors[0].affiliation.laboratory'),
first_author_aff_loc_cnty = JSON_VALUE(metadata, '$.authors[0].affiliation.location.country')
FROM OPENROWSET(
'CosmosDB',
'Account=cosmos1sd;Database=testdb1;Key=<key value>',
cord19)
WITH ( metadata varchar(MAX) ) AS docs;I can use OPENJSON function to flatten the nested subarray structure of a nested property of the Cosmos DB data items. I also use CROSS APPLY
- OPENJSON: this is a table-valued function. It parses JSON text and returns data in row and column format. I can use WITH clause which contains a list of columns with their types for OPENJSON to return.
- CROSS APPLY: returns only those rows from the left table expression if it matches with the right table expression. It is equivalent to inner join. But, APPLY operator needs to be used instead of JOIN when there is a table-valued function in the query.
In the following query, I retrieve authors nested array and then use CROSS APPLY with the outcome of the OPENJSON function. OPENJSON returns the table data for the mentioned columns from authors array. In the SELECT list, data is retrieved as individual flattened columns from the nested structure. So, this is a very useful way to return data as row-column format from the complex nested JSON item.
SELECT
author_first_name = first,
author_middle_name = middle,
author_last_name = last,
author_suffix_name = suffix,
author_affiliation_laboratory_name = JSON_VALUE(affiliation, '$.laboratory'),
author_affiliation_institution = JSON_VALUE(affiliation, '$.institution'),
author_affiliation_location_addrLine = JSON_VALUE(affiliation, '$.location.addrLine'),
author_affiliation_location_country = JSON_VALUE(affiliation, '$.location.country'),
author_email = email
FROM OPENROWSET(
'CosmosDB',
'Account=cosmos1sd;Database=testdb1;Key=<key value>',
cord19)
WITH ( authors varchar(max) '$.metadata.authors' ) AS docs
CROSS APPLY OPENJSON ( authors )
WITH (
first varchar(50),
middle varchar(50),
last varchar(50),
suffix varchar(50),
affiliation nvarchar(max) as json,
email varchar(50)
) AS aI export the query output to a CSV file. Other file formats like JSON and XML are also available to save the query result.
Conclusion
In this article, I discussed about the creation of Azure Synapse link to query data from Azure Cosmos DB using Synapse workspace. Synapse link provides an integrated analytics experience without impacting the performance of the transactional store. So, it should be used when it is needed to run analytics, BI and machine learning over the operational data present in Cosmos DB. I will discuss about other functionalities and features of Synapse link in the upcoming articles.