

I recently ran across an interesting situation in our development databases. We have begun to protect various PII information in our systems by running scripts in the development databases when we restore a production backup. We do this as we have had executives express concern about losing data that exists on developer laptops and other systems.
During one of our development sprints, we realized that we have a process that totals up birthdays in a month for some award system. Since we were randomizing dates of these events, the totals for events didn't match any longer. As a result, we were asked to modify the script that change these dates to keep the year and month the same.
This post covers what I did and a little testing of the solution.
The Setup
I have a lot of columns in this particular table, but I mocked this up for this article. I decided to create a two column table that looks like this:
CREATE TABLE [dbo].[CustomerData]( [CustomerID] [int] NULL, [BirthDate] [date] NULL ) ON [PRIMARY] GO
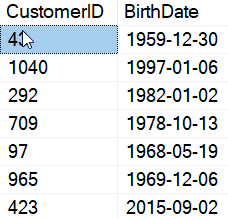
I inserted 1,000,000 rows in here to do some testing on how my script might work. I used data from the actual production table to populate this on my development system. Here is a sample of some data.
Altering the Day
To change the day, I thought of two ways to attack the problem. In both cases, I need to generate a random day, which I do using this type of structure:
ABS(CHECKSUM(NewId()) % n
n is the maximum value that I want to pick. I use this rather than RAND() as RAND() gives a random value, but the same one for every row.
For months, I usually think about 30, but since I could have February as a valid month, I want to avoid complexity. I decided to just use 28 instead, since that works for every month and we don't need any particular distribution of dates within a month.
If we did, I could use a CASE statement like this:
CASE WHEN MONTH(cd.BirthDate) IN (1,3,5,7,8,10,12) THEN ABS(CHECKSUM(NewId()) % 30 )+1 WHEN MONTH(cd.BirthDate) IN (4,6,9,11) THEN ABS(CHECKSUM(NewId()) % 29) + 1 WHEN MONTH(cd.BirthDate) = 2 THEN ABS(CHECKSUM(NewId()) % 27) + 1 END
If I run just the first code above, I see some data like this:
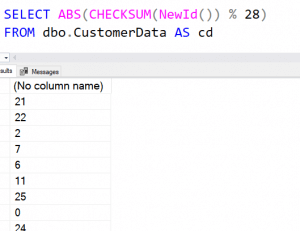
While this looks OK, the problem is in the row near the bottom. Using a 0 value in one of my techniques doesn't work. Therefore, if you use the first technique, you need to alter this.
I'll describe the two techniques below.
Building a Date
For some reason, the first thing I thought of was DATEFROMPARTS(). This function lets me send a year, month, and day into it and get a date out. This is kind of what I want, so I tried this:
SELECT CustomerID
, DATEFROMPARTS(YEAR(cd.BirthDate), MONTH(cd.BirthDate), ABS(CHECKSUM(NewId()) % 28))
FROM dbo.CustomerData AS cd
This started to work, but quickly threw this error:
Msg 289, Level 16, State 1, Line 4
Cannot construct data type date, some of the arguments have values which are not valid.
It took me a few minutes to realize that the "0" in some of the random numbers isn't valid for the DATEFROMPARTS() function.
The quick fix for me was to lower the value from 28 to 27 and then add 1 to all random numbers.
SELECT CustomerID
, DATEFROMPARTS(YEAR(cd.BirthDate), MONTH(cd.BirthDate), ABS(CHECKSUM(NewId()) % 27)+1)
FROM dbo.CustomerData AS cd
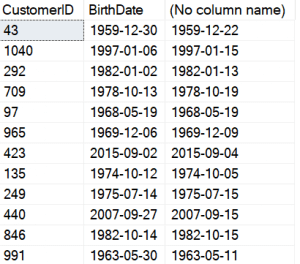
This works fine. As you can see in this image, I have the original birthdate and then my randomized one next to it. They all have the same month and year.
However, as I was figuring out the math, I thought of a better way.
Subtracting Dates
Since the first technique has a problem with zeros, I thought there might be a simpler method. While we don't have a beginning of month function, we do have EOMONTH(). This gives me the last day of the month.
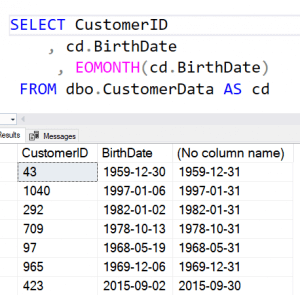
I can use this with DATEADD() to subtract a random number of days from the end of the month. This would give me random dates inside the month, and I can use my 28 instead of the 27+1 calculation. A 0 is a fine end of month value.
Note: If your system needs some beginning of the month dates, this won't give that for you except in February. You would need the CASE statement I showed above if this is your need.
I can now use this code, subtracting random numbers of days from the EOMONTH() output.
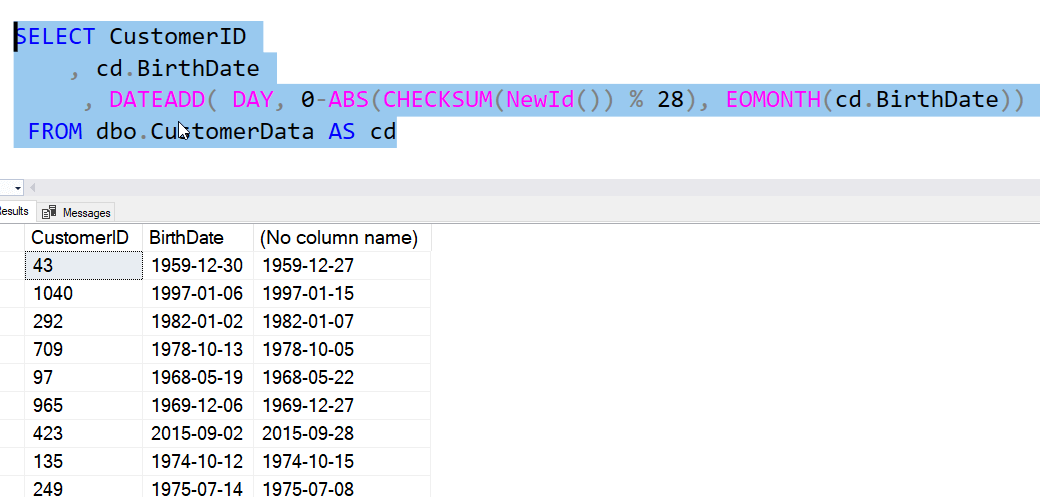
SELECT CustomerID
, cd.BirthDate
, DATEADD( DAY, 0-ABS(CHECKSUM(NewId()) % 28), EOMONTH(cd.BirthDate))
FROM dbo.CustomerData AS cdAs you can see in the image below, this gives me some dates before my original date and some after. Again, no first days of the month.
Performance
This script is one of many that run on the database after restore. Since there is nearly a TB of data in this database, we want these scripts to run quickly. While each script might not affect a lot of data, in total, they do. Therefore I was wondering which of these scripts runs faster.
I decided to do some testing, using SET STATISTICS. I ran code like this:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT CustomerID
, cd.BirthDate
, DATEADD( DAY, 0-ABS(CHECKSUM(NewId()) % 28), EOMONTH(cd.BirthDate))
FROM dbo.CustomerData AS cd
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
I then gathered some data. The IO is the same each time, so I didn't worry about these. Instead, what is the CPU load of running this? Here's what I found.
For the first technique, I saw some CPU values like this:
SQL Server Execution Times: CPU time = 469 ms, elapsed time = 3146 ms.
If I ran this a number of times, it seemed like this averaged:
- CPU: 482ms
- Elapsed: 3192ms
With the second technique, my averages were:
- CPU: 343ms
- Elapsed: 3113ms
This seems to indicate that the subtraction technique was faster. That's what I decided to do with.
Summary
I needed to alter dates randomly, but keep the dates within the same month. I had two techniques to do this, one with DATEFROMPARTS() and one with EOMONTH() and DATEADD(). The second one performed better, so that's what I used.
