

I haven’t found a good source of information on which primary key to use for busy tables in an OLTP environment. So I have decided to study this subject. The options are: integer types generated sequentially, guide types, or natural keys. Natural keys are possible only for limited number of systems.
For an ordinary order processing system, it is very unlikely that you can use any natural key as the only one I can think of is a precise order time. But there is a chance that these keys intersect at one moment. That is why I excluded natural keys from my research.
Sequential Integer Keys
Sequential integer keys are very common in MS SQL Server databases. The generation of new values for these keys is supported on the database engine level and is very efficient. In order to use this option you can declare a primary key as an integer field and use a special ‘identity’ keyword in order to get values automatically generated. How to use an identity declaration is described in details on the Microsoft Docs Identity page.
Also, you may consider using a sequence object as another option to generate sequential integer numbers. More information about using sequences you can find on the Microsoft Docs Sequence page. The sequences are become available starting from MS SQL Server 2012. That is very unlikely that in 2018 you will be using SQL Server 2008, but I have decided to mention this fact.
From the performance point of view sequential integer keys are very narrow (4 bytes for int type and 8 bytes for bigint). If you create a clustered index on that field, fragmentation stays low taking into account a low rate of updates and deletes on that table. That is a common OLTP database behaviour. Theoretically, these clustered indexes usually have a hotspot on left or right side of the index tree. That hotspot can reduce speed of inserts on a busy system.
Uniqueidentifier (GUID) fields
Uniqueidentifiers are unique binary values that can be generated on MS SQL Server. An example of such a value is "6A9619FF-9B86-D011-B42D-10C04FC9B4FF". As you can see they are pretty difficult to remember for a human being, but computers can easily operate with these values. Microsoft guaranteed that the uniqueidentifier values generated by a database engine are unique among all the uniqueidentifier values generated by that database engine. That means that if you try to join tables on wrong uniqueidentifier columns you don’t get any result back. Isn’t that handy? With integer keys, when you made a mistake with joins you may get a result, but it will be wrong. That is why database developers like uniqueidentifier keys.
In a MS SQL Server database, uniqueidentifier values can be generated by two different functions NEWID() and NEWSEQUENTIALID(). More information about these functions published on Microsoft Docs pages.
From the performance point of view uniqueidentifier is a relatively wide datatype. The size of a uniqueidentifier is 16 bytes, which is twice longer than bigint. Also, when you populate primary keys with NEWID() function that may cause significant fragmentation on an index. That is why Microsoft introduced the function, NEWSEQUENTIALID(). Fragmentation affects the performance of index scan operations and increases the amount of space for data storage. On the other hand, the random nature of this datatype reduces contention for a leftmost or rightmost page in an index. Theoretically that can increase speed of inserts in a busy OLTP database.
A Synthetic OLTP Load Test
I decided to perform a test based on the theoretical information I described early in this article. I decided to test and compare the performance of inserts and index fragmentation for tables with different primary keys (clustered indexes). I have created 3 similar databases on the same database instance. The first database has primary key on a uniqueidentifier field, which populates with the function NEWID().The second database has primary key on a uniqueidentifier field that populates with the function NEWSEQUENTIALID(). The third database has int field, which populates by identity as a primary key. Apart from that difference all 3 databases were identical.
Each database has two tables: orders and order_items. The definitions of these tables for the first scenario are shown below:
create table dbo.orders( id uniqueidentifier NOT NULL DEFAULT newid(), invoice int NOT NULL, some_data char(200) NOT NULL, some_vardata varchar(200), order_date datetime, constraint PK_orders PRIMARY KEY CLUSTERED (id) ); create table dbo.order_items( id uniqueidentifier NOT NULL DEFAULT newid(), order_id uniqueidentifier NOT NULL, some_data char(50) NOT NULL, some_vardata varchar(100), constraint PK_order_items PRIMARY KEY CLUSTERED (id), constraint FK_order_items_orders FOREIGN KEY (order_id) references dbo.orders(id) );
For the second and third scenarios, the difference is only in the primary key definitions. For second scenario the PK is ‘ id uniqueidentifier NOT NULL DEFAULT newsequentialid(),’ and for the third it is ‘id int IDENTITY NOT NULL,’.
The ‘invoice’ fields were populated using a sequence in order to show you how sequence works and compare it with identity. The sequence definition is below:
CREATE SEQUENCE [dbo].[invoice] AS [int] start with 1;
In order to perform a load test I have created several CMD files and one SQL script files. The SQL file is simple; it executes the [dbo].[create_some_order] procedure 20000 times in a cycle with no delays. The file has the same definition for all 3 database tests. The SQL file looks like this:
declare @i int =1; while @i<=20000 begin exec [dbo].[create_some_order]; set @i=@i+1; end;
The SQL file is executed on a database from a CMD file that connects to one of the 3 test databases using integrated security. The content of that file looks like this:
sqlcmd -E -S. -d PK_testdb1 -i batch.sql exit
Another CMD file scripts executes the previous CMD file 20 times asynchronously, which simulates high user load. The scripts are in the attachment to this article. You can use them to simulate load on your database. Ideally you will need two servers to simulate: one is a database server and another one is a client, which starts this workload.
The test will be performed on equal database servers with different number of CPU: single CPU, 4 CPU, and 8 CPU. So we will be able to compare scalability of all 3 solutions.
Load test results
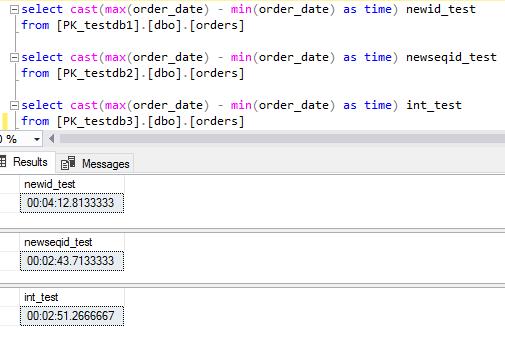
On 1 CPU database server the worst performance was on the database with primary key populated by NEWID() function. NEWSEQUENTIALID() and identity showed similar results.
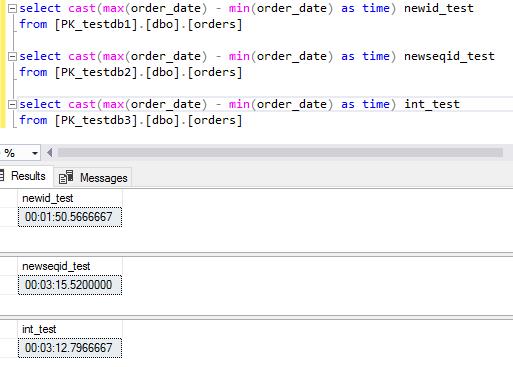
On 4 CPU results were opposite. NEWID() was the best performing and several times faster than on one CPU. But NEWSEQUENTIALID() and identity were slower even than on one CPU.
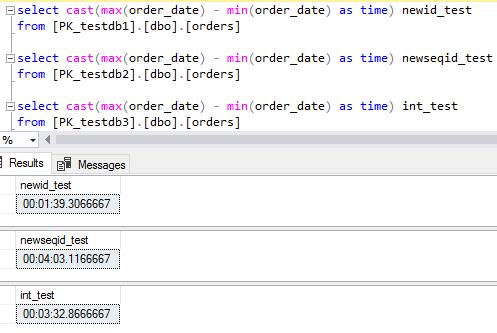
The performance test on 8 CPU was very similar to the test on 4 CPU. NEWID() was the best performing and slightly faster than on 4 CPU. NEWSEQUENTIALID() was slightly slower than identity.
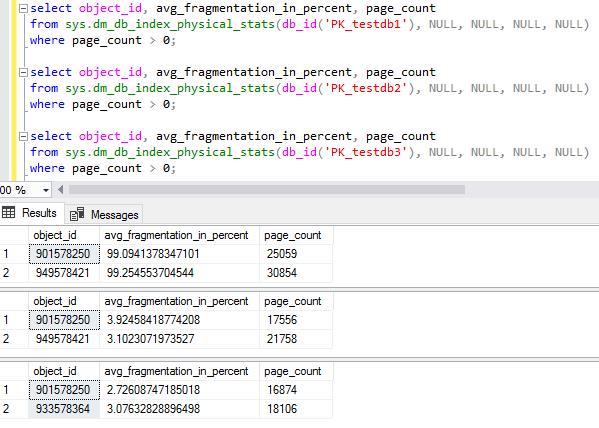
Index fragmentation
In terms of index fragmentation, as we expected, NEWID() caused 99% fragmentation with almost 50% more space usage than NEWSEQUENTIALID() and identity. NEWSEQUENTIALID() showed slightly higher fragmentation and space usage than identity.
Conclusion
When you build an OLTP database it is very important to choose right indexing strategy particularly clustered indexes. From my experiment, the worst performing was a clustered primary key populated using the NEWSEQUENTIALID() function. Even though that function was supposed to reduce index fragmentation, it didn’t eliminate it. Also the key value is the same width as that generated by the NEWID() and due to sequential nature of this key, insert operations slow.
The integer keys populated through an identity property are narrow, and index fragmentation is pretty low due the sequential nature of these keys. On the other hand, that sequential nature caused slow inserts under a heavy insert load.
If fast concurrent inserts are important, I would recommend using clustered primary keys populated using the NEWID() function or populated from the application.
Other RDMS have to deal with similar problems for example Oracle introduced Scalable Sequences in order to deal with insert hotspot. There is a good article on Oracle Scalable Sequences from Richard Foote. Also Oracle has reverse key indexes. I think that the similar features will appear in MS SQL Server as well.