

Note: This document is intended for Active-Active traditional clusters (MSCS) with multiple SQL instances hosted on it. In big IT shops, due to separation of duties, host patching is managed by a different group other than the SQL Server group. The host patching team usually uses automated scripts to patch host servers.
After host patching, SQL instances on an active-active cluster may end up running on one single node. Due to the increase in load, resource consumption on the instances will eventually grow compared to the usage when SQL instances were installed. Due to constraints, some legacy applications/databases cannot be migrated to new infrastructure nodes. In this scenario, there is a need to balance the resources and make sure the instances are load balanced across all available nodes of the cluster. The preferred node setting makes sure that SQL instances are running on their preferred node only. Settings in the failback options helps us to configure the time period when auto failback can happen as well as number of attempts cluster service should try to perform the failback.
The below configuration is required to make sure that SQL instances are on their preferred node.
First, log on to the server. Then open Failover Cluster Manager. In this example, SQL instance N2APP2 is chosen
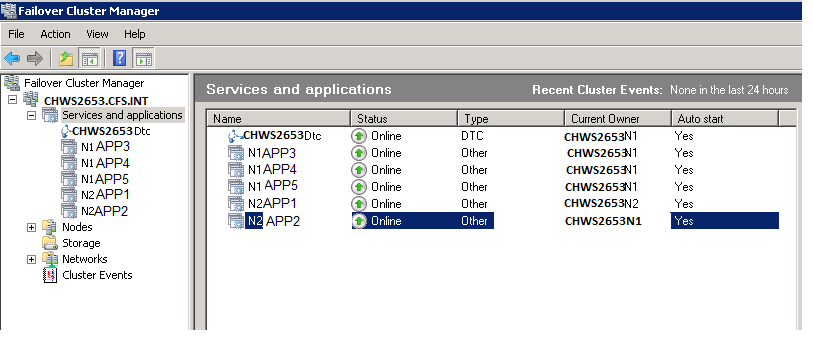
Next, right click on the group and select properties.
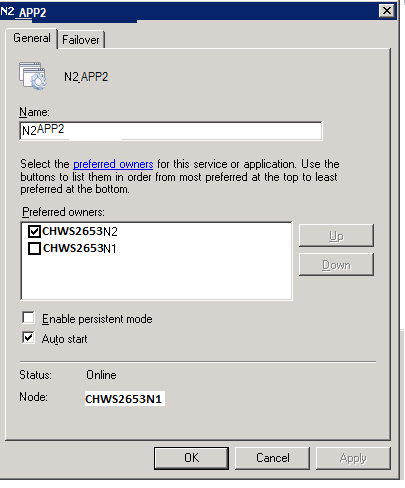
On the general tab, select the preferred node. In this example preferred node is CHWS2653N2.
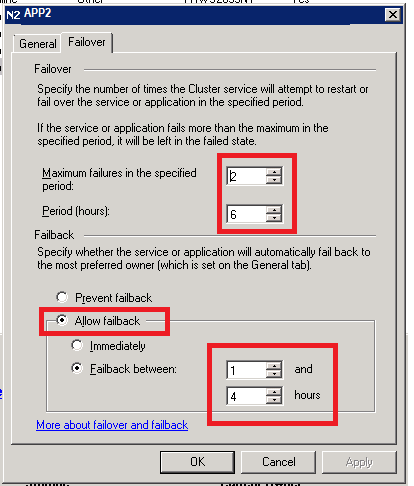
Now, click on the Failover tab.
- Enter Maximum failures in the specified period = 2
- Period (Hours) = 6
- Select Radio Button “Allow Failback” radio button.
- Select “Allow failback” radio button.
- Select “Failback between” : 1 and 4 hours
- Click “OK”
Make this change on all the cluster groups on the cluster. The changes will go into effect after the server restart.
Once the change goes into effect, anytime an instance is moved to node which is not a preferred node, cluster service will move back the instance to the preferred node in the above mentioned time window.
Ref: https://support-msft-us1.vtv.stillw.com/en-us/kb/197047
