

Introduction
Many high-volume data sources, including sensors, logs from mobile applications, and the Internet of Things, operate in real time. As organizations have gotten better at capturing this data, they also want to process it in real time, whether to give human analysts the freshest possible data or drive automated decisions. Enabling broad access to streaming computation requires systems that are scalable, easy to use, and easy to integrate into business applications. In this paper, we begin by describing these challenges, based on experience.
I found that 3 challenges frequently came up with users. First, streaming systems often ask users to think in terms of complex physical execution concepts, such as at-least-once delivery, state storage, and triggering modes, that are unique to streaming. Second, many systems focus only on streaming computation, but in real use cases, streaming is often part of a larger business application that also includes batch analytics, joins with static data, and interactive queries. Integrating streaming systems with these other workloads (e.g., maintaining transactionality) requires significant engineering effort. Motivated by these challenges, we describe Structured Streaming, a new high-level API for stream processing that was developed in Apache Spark starting in 2016. Specifically, Structured Streaming differs from other widely used open-source streaming APIs in two ways:
- Incremental query model: Structured Streaming automatically incrementalizes queries on static datasets expressed through Spark’s SQL and DataFrame APIs [8], meaning that users typically only need to understand Spark’s batch APIs to write a streaming query. Event time concepts are especially easy to express and understand in this model. Although incremental query execution and view maintenance are well studied [11, 24, 29, 38], we believe Structured Streaming is the first effort to adopt them in a widely used open-source system. We found that this incremental API generally worked well for both novice and advanced users. For example, advanced users can use a set of stateful processing operators that give fine-grained control to implement custom logic while fitting into the incremental model.
- Support for end-to-end applications: Structured Streaming’s API and built-in connectors make it easy to write code that is “correct by default" when interacting with external systems and can be integrated into larger applications using Spark and other software. Data sources and sinks follow a simple transactional model that enables “exactly-once" computation by default. The incrementalization based API naturally makes it easy to run a streaming query as a batch job or develop hybrid applications that join streams with static data computed through Spark’s batch APIs. In addition, users can manage multiple streaming queries dynamically and run interactive queries on consistent snapshots of stream output, making it possible to write applications that go beyond computing a fixed result to let users refine and drill into streaming data.
Beyond these design decisions, made several other design choices in Structured Streaming that simplify operation and increase performance. First, Structured Streaming reuses the Spark SQL execution engine [8], including its optimizer and runtime code generator. This leads to high throughput compared to other streaming systems (e.g., 2× the throughput of Apache and 90× that of Apache Kafka Streams in the Yahoo! Streaming Benchmark [14]), as in Trill [12], and also lets Structured Streaming automatically leverage new SQL functionality added to Spark. The engine runs in a microbatch execution mode by default [37] but it can also use a low-latency continuous operators for some queries because the API is agnostic to execution strategy [6].
Second, found that operating a streaming application can be challenging, Hence designed the engine to support failures, code updates and recomputation of already outputted data. For example, one common issue is that new data in a stream causes an application to crash, or worse, to output an incorrect result that users do not notice until much later (e.g., due to mis-parsing an input field). In Structured Streaming, each application maintains a write-ahead event log in human-readable JSON format that administrators can use to restart it from an arbitrary point. If the application crashes due to an error in a user-defined function, administrators can update the UDF and restart from where it left off, which happens automatically when the restarted application reads the log. If the application was outputting incorrect data instead, administrators can manually roll it back to a point before the problem started and recompute its results starting from there.
Stream Processing Challenges
Despite extensive progress in the past few years, distributed streaming applications are still generally considered difficult to develop and operate. Before designing Structured Streaming, I spent time discussing these challenges with users and designers of other streaming systems, including Spark Streaming and streaming analytics services.
Complex and Low-Level APIs
Streaming systems were invariably considered more difficult to use than batch ones due to complex API semantics. Some complexity is to be expected due to new concerns that arise only in streaming: for example, the user needs to think about what type of intermediate results the system should output before it has received all the data relevant to a particular entity, e.g., to a customer’s browsing session on a website. However, other complexity arises due to the low level nature of many streaming APIs: these APIs often ask users to specify applications at the level of physical operators with complex semantics instead of a more declarative level.
As a concrete example, the Google Dataflow model has a powerful API with a rich set of options for handling event time aggregation, windowing and out-of-order data. However, in this model, users need to specify a windowing mode, triggering mode and trigger refinement mode (essentially, whether the operator outputs deltas or accumulated results) for each aggregation operator. Adding an operator that expects deltas after an aggregation that outputs accumulated results will lead to unexpected results.
In essence, the raw API asks the user to write a physical operator graph, not a logical query, so every user of the system needs to understand the intricacies of incremental processing. Other APIs, such as Spark Streaming, are also based on writing DAGs of physical operators and offer a complex array of options for managing state. In addition, reasoning about applications becomes even more complex in systems that relax exactly-once semantics , effectively requiring the user to design and implement a consistency model.
To address this issue, we designed Structured Streaming to make simple applications simple to express using its incremental query model. In addition, we found that adding customizable stateful processing operators to this model still enabled advanced users to build their own processing logic, such as custom session-based windows, while staying within the incremental model (e.g., these same operators also work in batch jobs).
Integration in End-to-End Applications
The second challenge we found was that nearly every streaming workload must run in the context of a larger application, and this integration often requires significant engineering effort. Many streaming APIs focus primarily on reading streaming input from a source and writing streaming output to a sink, but end-to-end business applications need to perform other tasks. Examples include:
- The business purpose of the application may be to enable interactive queries on fresh data. In this case, a streaming job is used to update summary tables in a structured storage system such as an RDBMS or Hive. It is important that when the streaming job updates its result, it does so atomically, so users do not see partial results. This can be difficult with file-based big data systems like Hive, where tables are partitioned across files, or even with parallel loads into a data warehouse.
- An Extract, Transform and Load (ETL) job might need to join a stream with static data loaded from another storage system or transformed using a batch computation. In this case, it is important to be able to reason about consistency across the two systems, and it is useful to write the whole computation in a single API.
- Job may occasionally need to run its streaming business logic as a batch application, e.g., to backfill a result on old data or test alternate versions of the code. Rewriting the code in a separate system would be time-consuming and error prone. We address this challenge by integrating Structured Streaming closely with Spark’s batch and interactive APIs.
Operational Challenges
One of the largest challenges to deploying streaming applications in practice is management and operation. Some key issues include:
- Failures: This is the most heavily studied issue in the research literature. In addition to single node failures, systems also need to support graceful shutdown and restart of the whole application, e.g., to let operators migrate it to a new cluster.
- Code Updates: Applications are rarely perfect, so developers may need to update their code. After an update, they may want the application to restart where it left off, or possibly to recompute past results that were erroneous due to a bug. Both cases need to be supported in the streaming system’s state management and fault recovery mechanisms. Systems should also support updating the runtime itself (e.g., patching Spark).
- Rescaling: Applications see varying load over time, and generally increasing load in the long term, so operators may want to scale them up and down dynamically, especially in the cloud. Systems based on a static communication topology, while conceptually simple, are difficult to scale dynamically. • Stragglers: Instead of outright failing, nodes in the streaming system can slow down due to hardware or software issues and degrade the throughput of the whole application. Systems should automatically handle this situation.
- Monitoring: Streaming systems need to give operators clear visibility into system load, backlogs, state size and other metrics.
Cost and Performance Challenges Beyond
operational and engineering issues, the cost-performance of streaming applications can be an obstacle because these applications run 24/7. For example, without dynamic rescaling, an application will waste resources outside peak hours; and even with rescaling, it may be more expensive to compute a result continuously than to run a periodic batch job. We thus designed Structured Streaming to leverage all the execution optimizations in Spark SQL [8]. So far, we chose to optimize throughput as our main performance metric because we found that it was often the most important metric in large-scale streaming applications. Applications that require a distributed streaming system usually work with large data volumes coming from external sources (e.g., mobile devices, sensors or IoT), where data may already incur a delay just getting to the system.
Structured Streaming Overview
Structured Streaming aims to tackle the stream processing challenges we identified through a combination of API and execution engine design. In this section, we give a brief overview of the overall system. Figure 1 shows Structured Streaming’s main components. Input and Output. Structured Streaming connects to a variety of input sources and output sinks for I/O. To provide “exactly-once" output and fault tolerance, it places two restrictions on sources and sinks.
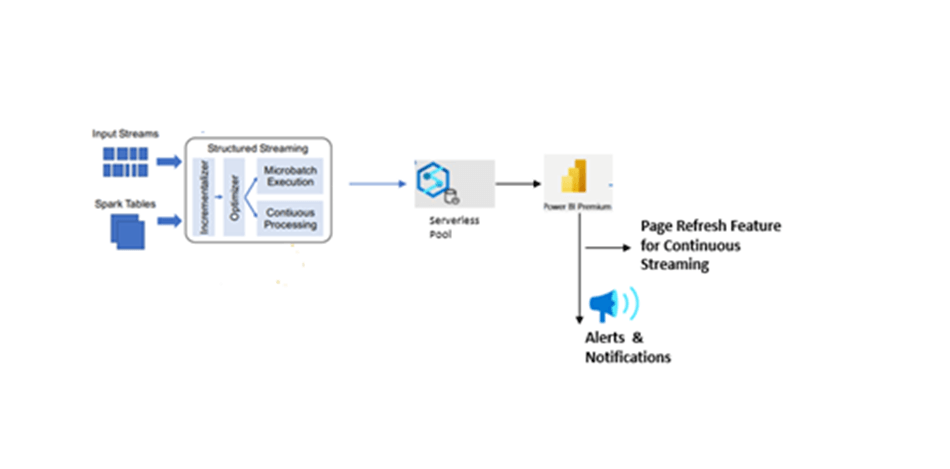
Figure 1: The components of Structured Streaming
- Input sources must be repayable, allowing the system to re-read recent input data if a node crashes. In practice, organizations use a reliable message services like logic app to send notification.
- A PySpark notebook will read data from different sources like logs, sensors, IoT, Event Hub and write data into blob as parquet format and to spark tables dynamically, then these spark tables connected to Power BI tool for reporting, If any anomaly is detected, the Power BI reporting tool will send an notification in email to end users.
- In report dataset refresh performed with the page refresh feature in Power BI
Output sinks must support idempotent writes, to ensure reliable recovery if a node fails while writing. Structured Streaming can also provide atomic output for certain sinks that support it, where the entire update to the job’s output appears atomically even if it was written by multiple nodes working in parallel.
Shifting to a Streaming Data Solution with Page Refresh in a Reporting Tool
Enabling a real-time analytics solution based on streaming data provides a solution to several of the challenges of real-time data at scale. The model for the implementation represents a significant shift by moving from point queries against stationary data, to a standing temporal query that consumes moving data. Fundamentally, we enable insight on the data before it is stored in the analytics repository. As such, companies gain the benefits of real-time insights on data as business events occur, but also the ability to store this information in a robust repository for historical analysis later. The following diagram illustrates the approach to real-time analytics, demonstrating the contrast of Figure 1 to show how real-time analytics is applied below.
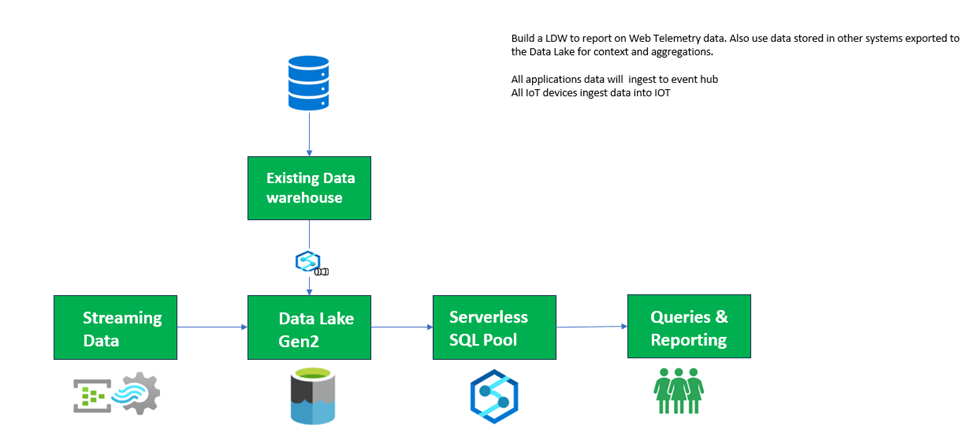
Figure 2: Streaming Architecture Design
Here is a more detailed look at a modern streaming serverless pool architecture, using a number of Azure services.
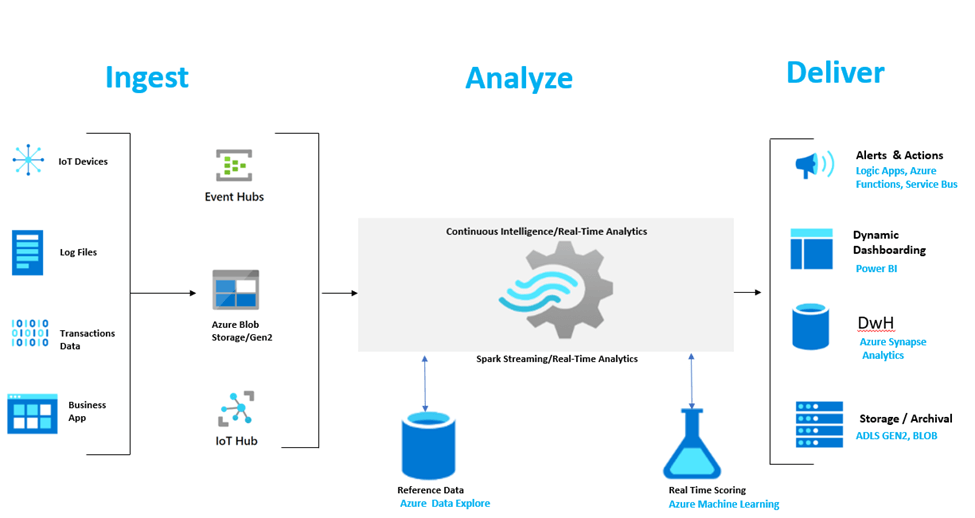
- Stream Data into blob from event hub/IoT/Sensors/Business App/Transactions Data
- Read source event hub stream data in spark notebooks synapse and create data frame.
- Create 2 containers in blob 1) Stream write 2) Stream checkpoint.
- Apply transformation to the data frame as 1) Parquet format 2) add ingestion timestamp and write data into Stream Write container and write data into Stream write check point.
- After applying transformation create spark table from stream write from blob container
- Use this function called as await termination() this will help to keep stream until stop
The
- Event Hub
- Blob Storage
- Pyspark Notebook
- Serverless pool
- Spark Table
- Pyspark
- Power BI
The source files in the Data Lake look like this:
Transformations on DStreams
Similar to that of RDDs, transformations allow the data from the input DStream to be modified. DStreams support many of the transformations available on normal Spark RDD’s. Some of the common ones are as follows.
| Transformation | Meaning |
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
A few of these transformations are worth discussing in more detail.
UpdateStateByKey Operation
The updateStateByKey operation allows you to maintain arbitrary state while continuously updating it with new information. To use this, you will have to do two steps.
- Define the state - The state can be an arbitrary data type.
- Define the state update function - Specify with a function how to update the state using the previous state and the new values from an input stream.
In every batch, Spark will apply the state update function for all existing keys, regardless of whether they have new data in a batch or not. If the update function returns None then the key-value pair will be eliminated.
Let’s illustrate this with an example. Say you want to maintain a running count of each word seen in a text data stream. Here, the running count is the state and it is an integer. We define the update function as:

The transformation code in pyspark using spark streaming is shown below.

Output Operations on DStreams
Output operations allow DStream’s data to be pushed out to external systems like a database or a file system. Since the output operations actually allow the transformed data to be consumed by external systems, they trigger the actual execution of all the DStream transformations (similar to actions for RDDs). Currently, the following output operations are defined:
| Output Operation | Meaning |
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
The streaming output in Power BI for 2 seconds is shown here:
Checkpointing
A streaming application must operate 24/7 and hence must be resilient to failures unrelated to the application logic (e.g., system failures, JVM crashes, etc.). For this to be possible, Spark Streaming needs to checkpoint enough information to a fault- tolerant storage system such that it can recover from failures. There are two types of data that are checkpointed.
- Metadata checkpointing - Saving of the information defining the streaming computation to fault-tolerant storage like HDFS. This is used to recover from failure of the node running the driver of the streaming application (discussed in detail later). Metadata includes:
- Configuration - The configuration that was used to create the streaming application.
- DStream operations - The set of DStream operations that define the streaming application.
- Incomplete batches - Batches whose jobs are queued but have not completed yet.
- Data checkpointing - Saving of the generated RDDs to reliable storage. This is necessary in some stateful transformations that combine data across multiple batches. In such transformations, the generated RDDs depend on RDDs of previous batches, which causes the length of the dependency chain to keep increasing with time. To avoid such unbounded increases in recovery time (proportional to dependency chain), intermediate RDDs of stateful transformations are periodically checkpointed to reliable storage (e.g. HDFS) to cut off the dependency chains.
To summarize, metadata checkpointing is primarily needed for recovery from driver failures, whereas data or RDD checkpointing is necessary even for basic functioning if stateful transformations are used.
Checkpointing must be enabled for applications with any of the following requirements:
- Usage of stateful transformations - If either updateStateByKey or reduceByKeyAndWindow (with inverse function) is used in the application, then the checkpoint directory must be provided to allow for periodic RDD checkpointing.
- Recovering from failures of the driver running the application - Metadata checkpoints are used to recover with progress information.
Note that simple streaming applications without the stateful transformations can be run without enabling checkpointing. The recovery from driver failures will also be partial in that case (some received but unprocessed data may be lost). This is often acceptable and many run Spark Streaming applications in this way. Support for non-Hadoop environments is expected to improve in the future.
Checkpointing can be enabled by setting a directory in a fault-tolerant, reliable file system (e.g., HDFS, S3, Azure BLOB/Data Lake etc.) to which the checkpoint information will be saved. This is done by using streamingContext.checkpoint(checkpointDirectory). This will allow you to use the stateful transformations. Additionally, if you want to make the application recover from driver failures, you should rewrite your streaming application to have the following behavior.
- When the program is being started for the first time, it will create a new StreamingContext, set up all the streams and then call start().
- When the program is being restarted after failure, it will re-create a StreamingContext from the checkpoint data in the checkpoint directory.
- If the checkpointDirectoryexists, then the context will be recreated from the checkpoint data. If the directory does not exist (i.e., running for the first time), then the function functionToCreateContext will be called to create a new context and set up the DStreams. See the Python example py. This example appends the word counts of network data into a file.
- You can also explicitly create a StreamingContextfrom the checkpoint data and start the computation by using getOrCreate(checkpointDirectory, None).
- In addition to using getOrCreateone also needs to ensure that the driver process gets restarted automatically on failure. This can only be done by the deployment infrastructure that is used to run the application. This is further discussed in the Deployment section.
- Note that checkpointing of RDDs incurs the cost of saving to reliable storage. This may cause an increase in the processing time of those batches where RDDs get checkpointed. Hence, the interval of checkpointing needs to be set carefully. At small batch sizes (say 1 second), checkpointing every batch may significantly reduce operation throughput. Conversely, checkpointing too infrequently causes the lineage and task sizes to grow, which may have detrimental effects. For stateful transformations that require RDD checkpointing, the default interval is a multiple of the batch interval that is at least 10 seconds. It can be set by using checkpoint(checkpointInterval). Typically, a checkpoint interval of 5 - 10 sliding intervals of a DStream is a good setting to try.
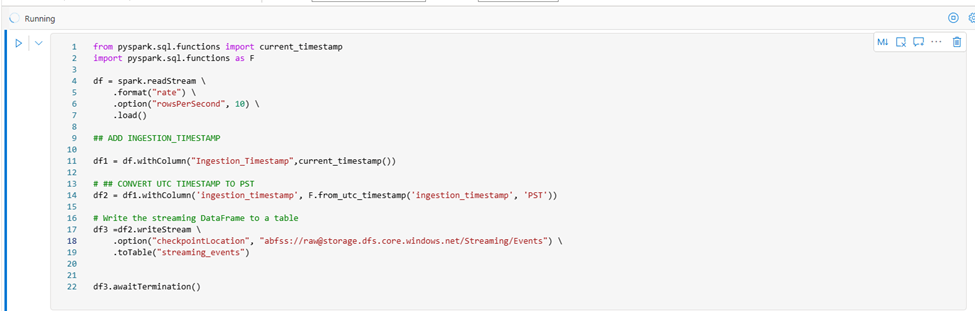
Another example of live Streaming with pyspark is generating data (dynamically) into blob 10 rows/per second as per below code.
- Read data and write into data frame.
- Since data ingestion time in UTC time zone
- Convert UTC Time zone into Local time as (PST Time Zone)
- Write data into new data frame df2 (Transform data as needed as parquet format)
- Finally write streaming data into df3 and then write into spark table
- Connect Spark table into reporting tool for continuous streaming analysis as below.
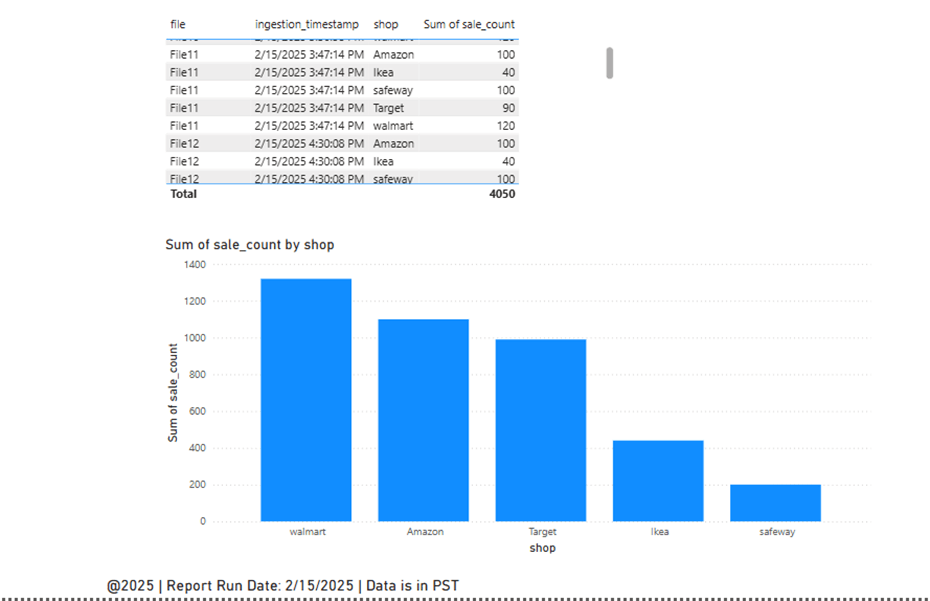
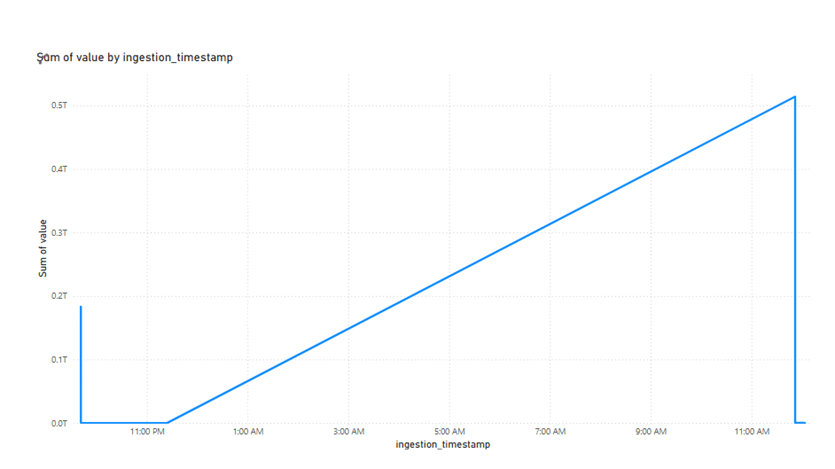
The output of continuous streaming data for report analysis and this below report will show the last 1440 mints (24 hrs) data dynamically
The filter added is shown below.
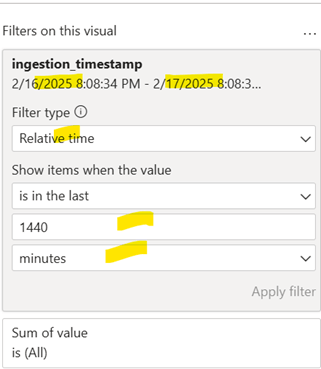
The Spark configuration that can support trillions of data as report snippet above in line graph.
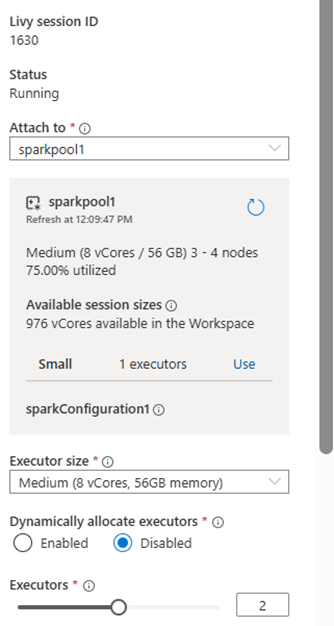
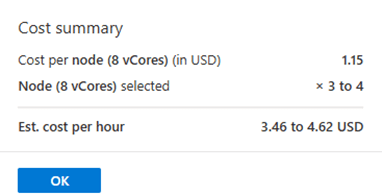
The cost summary is show here:
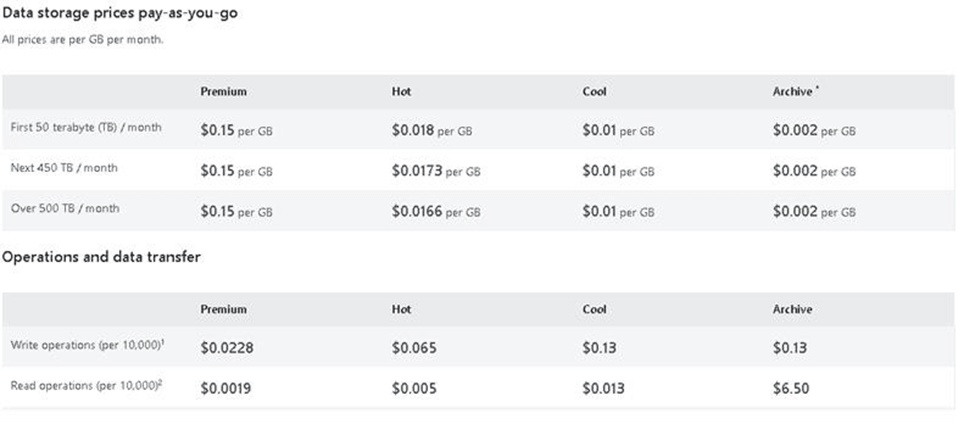
Premium tier for Data Lake Storage
Data Lake Storage Gen2 now supports premium block blob storage accounts. Premium block blob storage accounts are ideal for big data analytics applications and workloads that require low consistent latency and have a high number of transactions. Example workloads include interactive workloads, IoT, streaming analytics, artificial intelligence, and machine learning.
Premium block blob storage accounts have a higher storage cost, but a lower transaction cost as compared to standard general-purpose v2 accounts. If your applications and workloads execute a large number of transactions, premium blob blob storage can be cost-effective, especially if the workload is write-heavy.
Premium block blob storage accounts make data available via high-performance hardware. Data is stored on solid-state drives (SSDs) which are optimized for low latency. SSDs provide higher throughput compared to traditional hard drives. File transfer is much faster because data is stored on instantly accessible memory chips. All parts of a drive accessible at once. By contrast, the performance of a hard disk drive (HDD) depends on the proximity of data to the read/write heads.
In most cases, workloads executing more than 35 to 40 transactions per second per terabyte (TPS/TB) are good candidates for this type of account. For example, if your workload executes 500 million read operations and 100 million write operations in a month, then you can calculate the TPS/TB as follows:
- Write transactions per second = 100,000,000 / (30 x 24 x 60 x 60) = 39(rounded to the nearest whole number)
- Read transactions per second = 500,000,000 / (30 x 24 x 60 x 60) = 193(rounded to the nearest whole number)
- Total transactions per second = 193+ 39 = 232
- Assuming your account had 5TBdata on average, then TPS/TB would be 230 / 5 = 46.
Scenarios:
- Scenarios that require real-time access and random read/write access to large volumes of data
- Workloads that have small sized read and write transactions
- Read heavy workloads.
- Workloads that have a high number of transactions or high transactions per GB ratio
The relationship between the STORAGE costs and TRANSACTION costs.
Conclusion
Data science and data technology advance quickly. While some businesses are still struggling with questions others are using cloud computing and big data analysis to optimize their operations.
Modernization can be an intimidating process for businesses with established infrastructure. Yet, programs like Azure Synapse are making it easier to modernize legacy systems. We hope this guide explains whether Azure Synapse is the best choice for your streaming modernization and watch live streaming data. This modern spark streaming model is very cost effective with less resources
References
- https://azure.microsoft.com/en-us/blog/introducing-azure-premium-blob-storage-limited-public-preview/#:~:text=Data%20in%20Premium%20Blob%20Storage%20is%20stored%20on,for%20workloads%20that%20require%20very%20fast%20access%20times.
- https://docs.databricks.com/en/structured-streaming/delta-lake.html
- https://www.databricks.com/glossary/what-is-spark-streaming
- https://azure.microsoft.com/en-us/blog/azure-premium-block-blob-storage-is-now-generally-available/
- https:// spark.apache.org/docs/latest/streaming-programming-guide.html

