
We’ve written a lot of queries as this Stairway has progressed. All of the queries have returned data that has been loaded up into the Data Lake, either as a file or into a Data Lake database. But what if we already have a load of data sitting in Azure? Say we have a SQL Server or an Azure SQL Data Warehouse. We don’t want to export that data and load it into the Data Lake, it’s already there in Azure! Can we query it where it lives? Sure we can! Read on and find out how Data Sources help us embed external data right into our U-SQL queries.
Why Query External Data?
Why not? If you already have a load of data sitting in a SQL Server, it seems a bit pointless to write an extract script or a SSIS package which can extract the data and drop it into your Data Lake. Much easier, faster and cheaper to simply reference it in your Data Lake. Keep that workload down!
How do I Query External Data?
Let’s take a look at the steps involved in querying external data.
- Create a credential within the Azure Data Lake, used to access the external data source
- Create a data source to point at the external data, within an Azure Data Lake database
- Optionally create an external table object, which can be used as an alias to query the external data source
- Write a query to obtain data from the external data source
- If necessary, configure the firewall for the external data source
What External Data Can I Query?
At the time of writing, three external sources are supported:
- Azure SQL Database
- Azure SQL Data Warehouse
- SQL Server running on an Azure VM
We’re going to see how to query an Azure SQL Database in this article.
Creating a Credential
In earlier incarnations, it was possible to create a credential with U-SQL, using the CREATE CREDENTIAL statement (there were also ALTER and DROP CREDENTIAL statements). This U-SQL mechanism is now deprecated and should be ignored – use PowerShell instead. The cmdlet to use is New-AzureRmDataLakeAnalyticsCatalogCredential. This requires the following parameters:
- Account Name (the Data Lake Analytics account)
- Database Name (the Data Lake Analytics database)
- Credential Name (supplied by the developer)
- Credential (login details – more on this in a moment)
- Database Host (the address of the server the credential is being created for)
I’m creating a credential for the UKPostcodes database in the sqlservercentral Data Lake Analytics account. The credential is called SqlNationalDataCreds, and the database host is usqlstairway.database.windows.net. The credential value is set to Get-Credential. Setting this value causes a user prompt to display, into which the SQL user name and password can be entered. Much more secure than storing it as part of your command.
Login-AzureRmAccount New-AzureRmDataLakeAnalyticsCatalogCredential -AccountName "sqlservercentral" -DatabaseName "UkPostcodes" -CredentialName " SqlNationalDataCreds" -Credential (Get-Credential) -DatabaseHost "usqlstairway.database.windows.net" -Port 1433;
Enter the user name and password you use to access the SQL Server database/data warehouse when the login prompt appears.
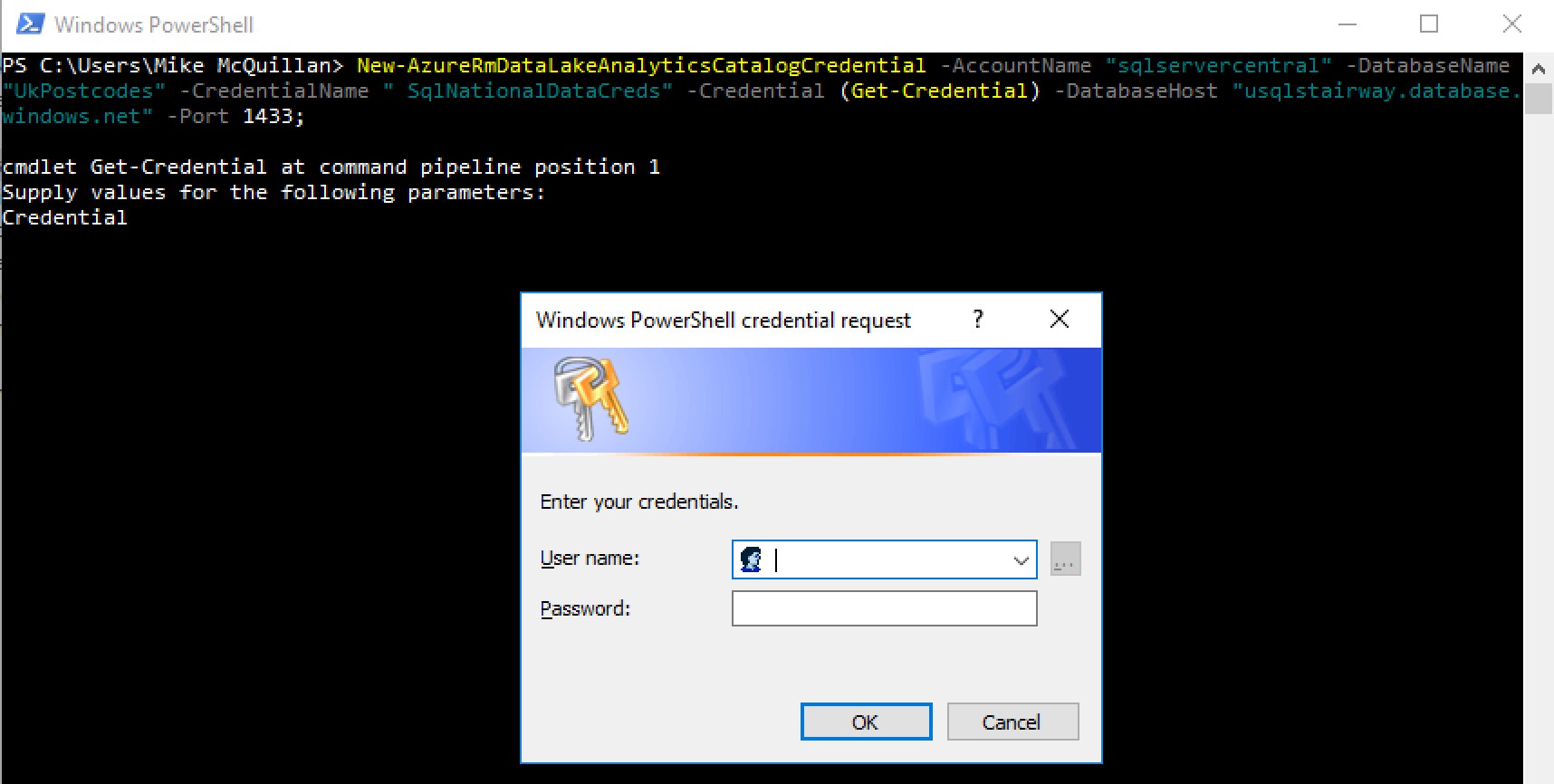
If you enter the wrong user name or password, you won’t be told here – the cmdlet will just complete. You’ll find out about your error a bit later in the process – keep reading!
Creating a Data Source
With the credential in place, it’s time to switch to Visual Studio to create a Data Source. This is similar to a linked server in SQL Server. I’ve opened up the SSC_UkPostcodes solution and added a new script to the SSC_UkPostcodes project. If you don’t already have this solution, you can pull it down from GitHub.
The new script is called 730 Create USQLStairway Data Source.usql. Here’s the code:
USE DATABASE UkPostcodes; CREATE DATA SOURCE IF NOT EXISTS UsqlStairwayAzureSqlDataSource FROM AZURESQLDB WITH ( PROVIDER_STRING = "Database=NationalData;Trusted_Connection=False;Encrypt=True;TrustServerCertificate=True", CREDENTIAL = SqlNationalDataCreds, REMOTABLE_TYPES = (bool, byte, DateTime, decimal, double, float, int, long, sbyte, short, string, uint, ulong, ushort) );
The USE statement tells Azure to create the Data Source in the UkPostcodes database. A data source always exists within the context of a database.
The CREATE DATA SOURCE statement will look familiar to most of us – the FROM AZURESQLDB part is the interesting bit. There are three values we can specify here:
- Azure SQL Database (AZURESQLDB)
- Azure SQL Data Warehouse (AZURESQLDW)
- SQL Server running on an Azure VM (SQLSERVER)
These values represent the external data sources we can hook a Data Lake up to. We’re targeting an Azure SQL database in this script.
Additional parameters are specified in the WITH clause. These are optional, with the exception of the credential, which has to be supplied to give the data source a security context under which it can execute your queries.
In broad terms, a data source consists of:
- A unique name
- The type of data source (e.g. Azure SQL Database)
- Connection details (connection provider string)
- A credential, providing security details
- A list of remotable types, which define what simple types are supported in queries
This can be executed directly against Azure from Visual Studio. It cannot be executed locally as the credentials only exist in Azure, not on the local machine. To point the script at Azure, select the appropriate account in the U-SQL toolbar.

With the correct account selected, hit Execute. Remember when I mentioned you’d see an error later in the process if you entered invalid user details when creating the credential? You’ve just reached that point in the process! If the credential details are wrong, your script will error out.
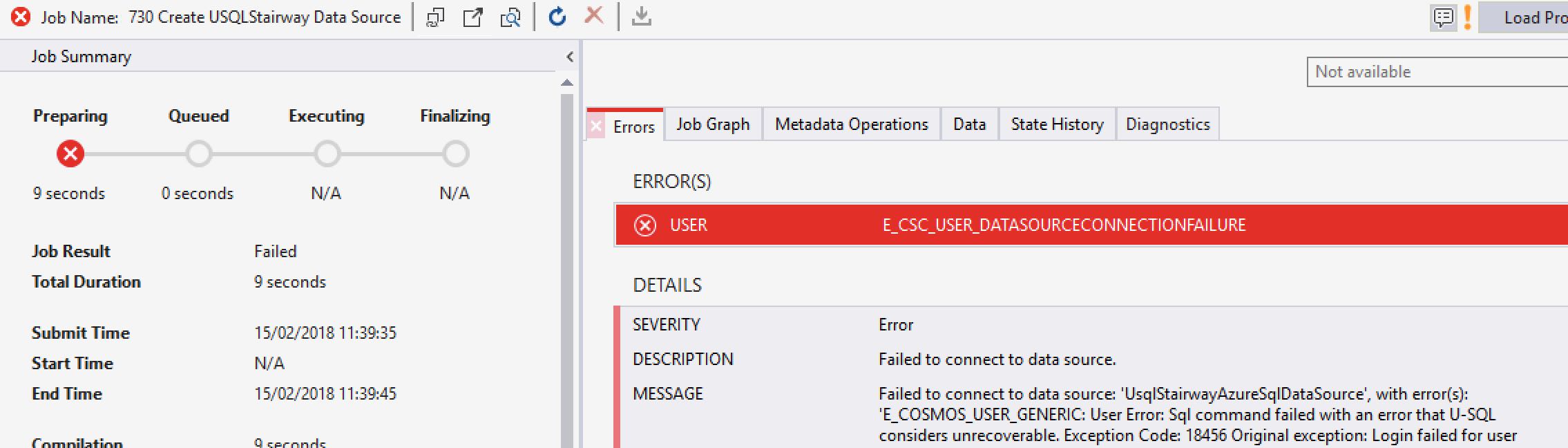
To fix this, drop the credential (see Dropping Objects below) and recreate it. Once correct credentials have been entered, the script will succeed.
Now we’re ready to write a query!
Querying the External Data Source Directly
There are two ways to query an external data source. We can either embed a SQL query directly into the U-SQL query, or create an external table alias over the data source and use that like we would any other table. Let’s look at querying the external data source directly. Another new query has been added to the project, 740 Direct External Data Source Query.usql.
Here’s a simple code listing which shows how U-SQL references the external data source.
@results = SELECT * FROM EXTERNAL UsqlStairwayAzureSqlDataSource EXECUTE @"SELECT * FROM dbo.County";
The Data Source is referenced with the EXTERNAL keyword, and is followed by EXECUTE with the appropriate SQL statement. This would indeed return the data from the County table we saw earlier. However, it would be much more interesting if we joined it to the Counties table sitting in the Data Lake’s UKPostcodes database. Here’s the full script:
USE DATABASE UkPostcodes;
@results =
SELECT c.CountyCode,
c.CountyName,
u.AbbreviatedName,
u.NumberOfFootballTeams
FROM EXTERNAL UsqlStairwayAzureSqlDataSource LOCATION "dbo.county" AS u
INNER JOIN
Postcodes.Counties AS c
ON u.CountyCode == c.CountyCode;
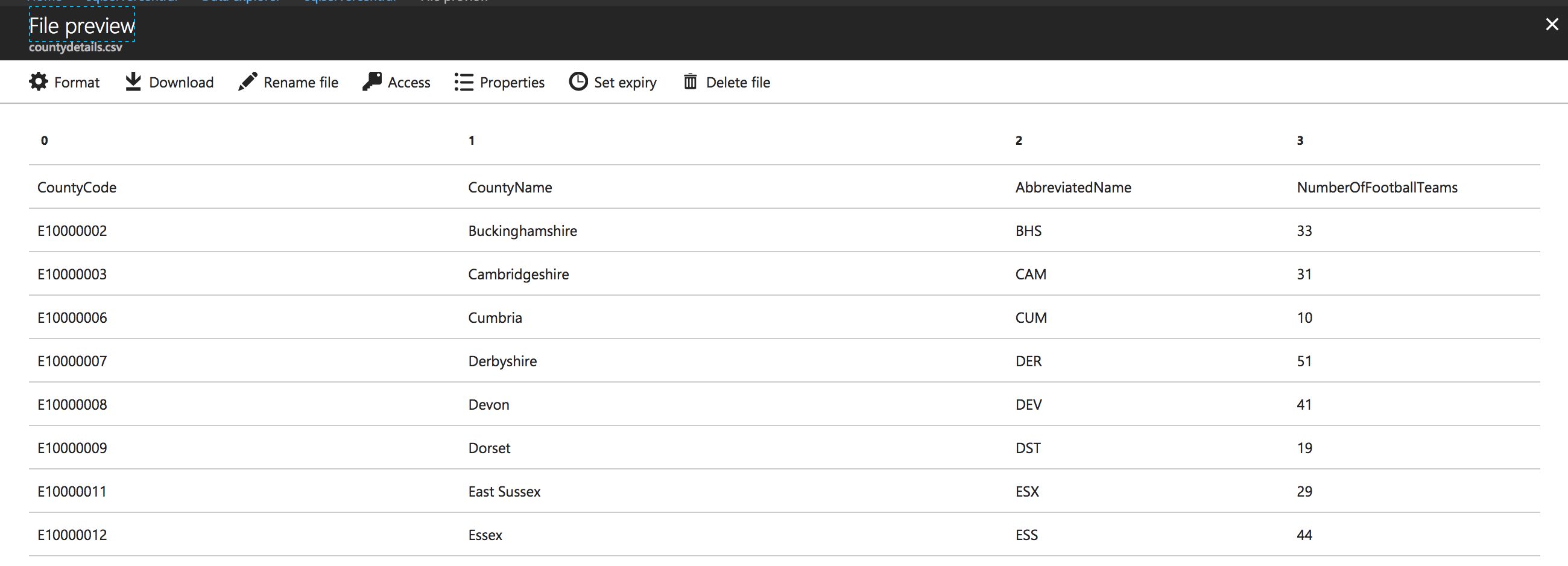
OUTPUT @results
TO "/Output/countydetails.csv"
USING Outputters.Csv(outputHeader: true);You can see that the EXTERNAL call can be aliased, in effect allowing it to act like any other table. We’ve also joined it to the Counties table on CountyCode, and removed the embedded SELECT statement from the external SQL query. That’s right, if you simply want all data from a table, you can just pass in the table name. The EXECUTE keyword has been changed to LOCATION, and the @ symbol has been removed as we don’t need to worry about escaping any characters.
Running this returns the merged output.
Creating an External Table
If the SQL statement you use to query the external data source is reasonably long or complex, you don’t really want to embed it in the middle of a U-SQL statement – it could make the query difficult to understand. This is where an external table comes in. This is similar to a view – it hides the complexity of the SQL statement, allowing us to reference the external table in queries just like any other table. If a table is being referenced, it reduces the amount of code you specify in your U-SQL statement. Win-win either way!
Just like when we create a “normal” table, we need to provide the column definitions. The EXECUTE command is used if a SQL statement is being used, LOCATION is required if a table is specified. The column names must match the names in the external table.
The code for script 750 Create External Table.usql is:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
CREATE EXTERNAL TABLE IF NOT EXISTS Postcodes.ExternalCountyData
(
CountyCode string,
CountyName string,
NumberOfFootballTeams int,
AbbreviatedName string,
AreaKMSquared int,
Population1991 int,
Population2001 int,
Population2011 int,
Population2016 int
)
FROM UsqlStairwayAzureSqlDataSource LOCATION "dbo.County";So far, so good. We’ve even put the table into the Postcodes schema. But running this script fails!
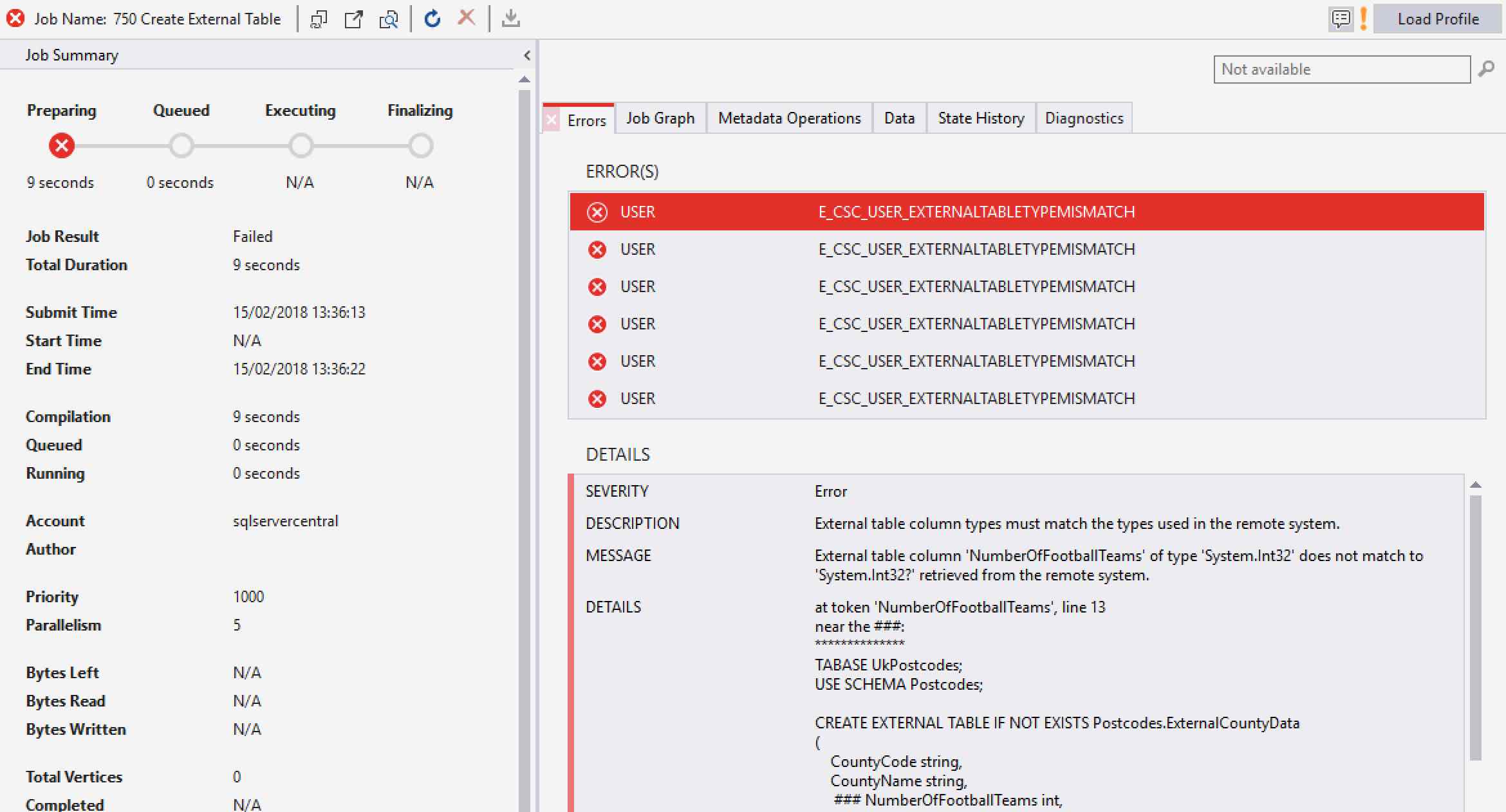
The data types must be able to map all possible values in the external data source. The integer columns in the SQL Server table can all accept NULL values. We didn’t cater for that!
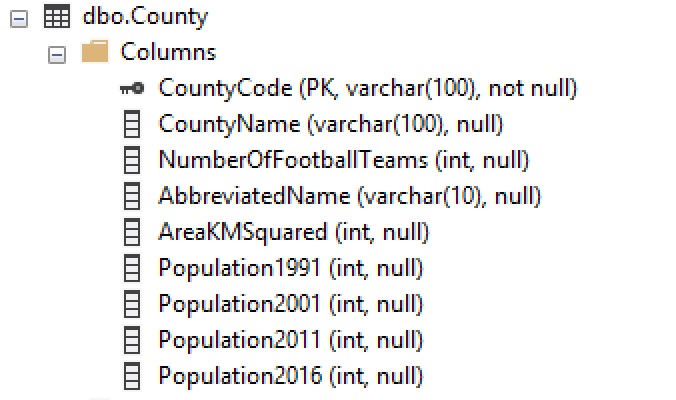
Fortunately, it’s an easy fix. Just add the nullable operator – a question mark – to the end of each int, making it a nullable int.
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
CREATE EXTERNAL TABLE IF NOT EXISTS Postcodes.ExternalCountyData
(
CountyCode string,
CountyName string,
NumberOfFootballTeams int?,
AbbreviatedName string,
AreaKMSquared int?,
Population1991 int?,
Population2001 int?,
Population2011 int?,
Population2016 int?
)
FROM UsqlStairwayAzureSqlDataSource LOCATION "dbo.County";Run the script again, and this time things go to plan.
Querying the External Table
Here’s another new script, 760 External Table Query.usql. This is the same query used in script 740, except it returns more columns and uses the external table instead of an embedded SQL statement.
USE DATABASE UkPostcodes;
@results =
SELECT c.CountyCode,
c.CountyName,
u.AbbreviatedName,
u.NumberOfFootballTeams
FROM Postcodes.ExternalCountyData AS u
INNER JOIN
Postcodes.Counties AS c
ON u.CountyCode == c.CountyCode;
OUTPUT @results
TO "/Output/countydetails.csv"
USING Outputters.Csv(outputHeader: true);Run this, and hey presto! All of the data is returned. If you hadn’t written it, you wouldn’t have a clue that an external table was being used in this query (unless you spot the big clue in the name, of course!).
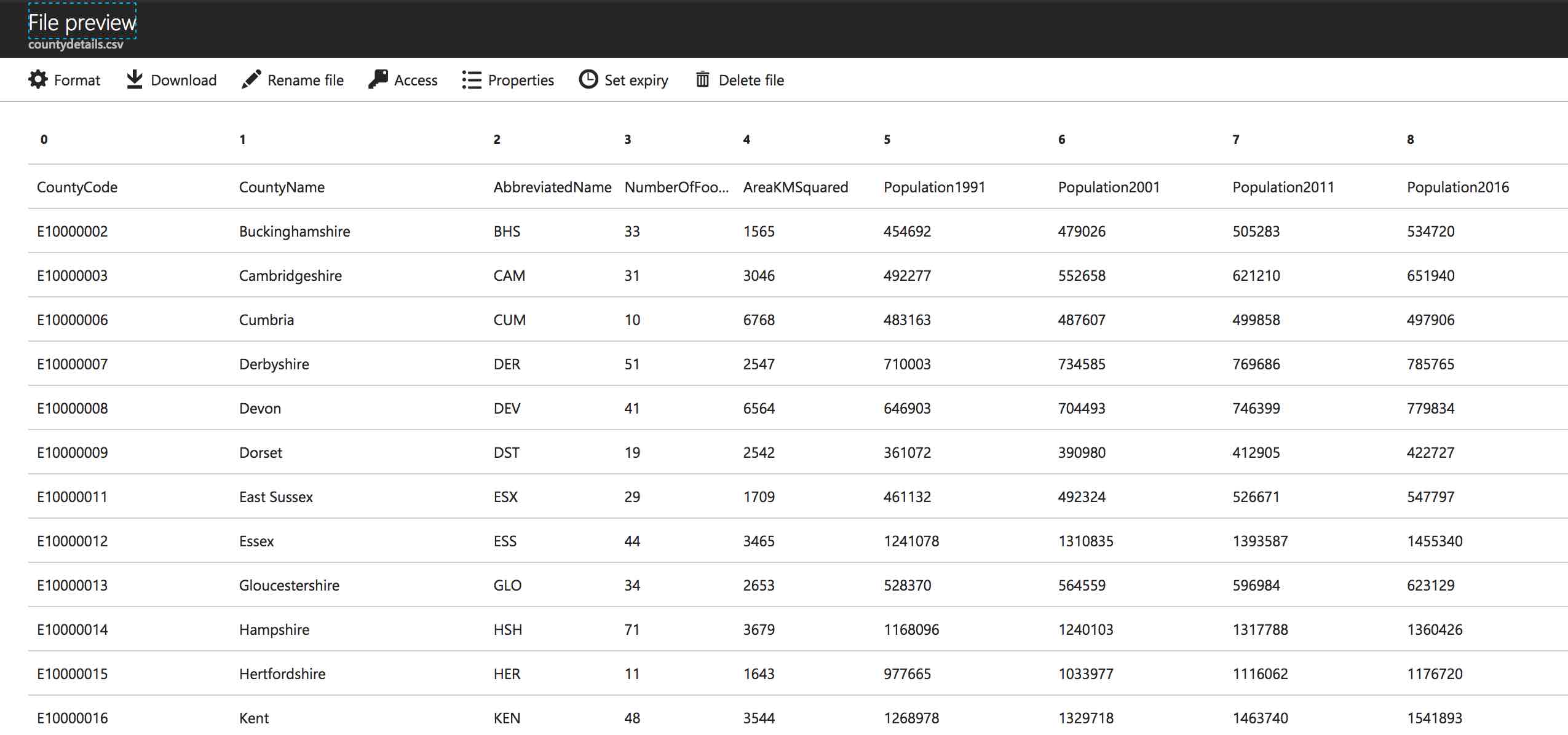
Dropping Objects
If you want to remove your objects at any point, U-SQL and Powershell have you covered. If you want to drop the external table, you might expect to use DROP EXTERNAL TABLE. No way! Just use DROP TABLE.
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; DROP TABLE IF EXISTS Postcodes.ExternalCountyData;
USE DATABASE UkPostcodes; DROP DATA SOURCE IF EXISTS UsqlExtDbDataSource;
Dropping the credential can’t be done with U-SQL. Use the snappily named PowerShell cmdlet Remove-AzureRmDataLakeAnalyticsCatalogCredential instead. Here’s an example which would remove the SqlNationalDataCreds credential object created earlier.
Remove-AzureRmDataLakeAnalyticsCatalogCredential -Account "sqlservercentral" -DatabaseName "UkPostcodes" -Name " SqlNationalDataCreds"
You can’t drop a credential until all items dependent upon it have been dropped, so make sure you’ve cleared things up before running this cmdlet.
Configuring the Firewall
Everything went smoothly for me whilst running the scripts in this article. If you do receive access errors, you’ll need to configure your Azure firewall. This has to be done on the SQL Server or Data Warehouse side.
In Azure, open up your SQL Server or Data Warehouse, and click on Set server firewall.

If you’ve already added your client IP and your SQL database/data warehouse exists in the same region as the Data Lake, chances are things will just work. If your Data Lake is in a different region, you’ll need to open up the firewall so the IP range for the appropriate region can access the data source. PowerShell scripts are available which will tell you what the ranges are.
If SQL Server on a virtual machine is being used, you’ll need to open up the SQL Server endpoint, giving access to the IP range for the region where your U-SQL scripts are being executed.
Summary
We’ve just expanded the capabilities of our Azure Data Lake! No longer are we limited to data we’ve loaded into the Data Lake – now we can query data where it lives! As long as it lives in SQL Server or Data Warehouse in Azure, that is. But it gives us a lot of flexibility, and saves us storing the same data in multiple places. We’ll continue this investigation next time, as we see how to send data in the opposite direction - from the Data Lake to an Azure SQL Database. Catch you soon!