
This U-SQL Stairway has principally concentrated on development themes up to this point. Time for a slight change in direction, as we delve behind the scenes and learn about the catalog used by Azure Data Lakes.
Visual Studio 2017
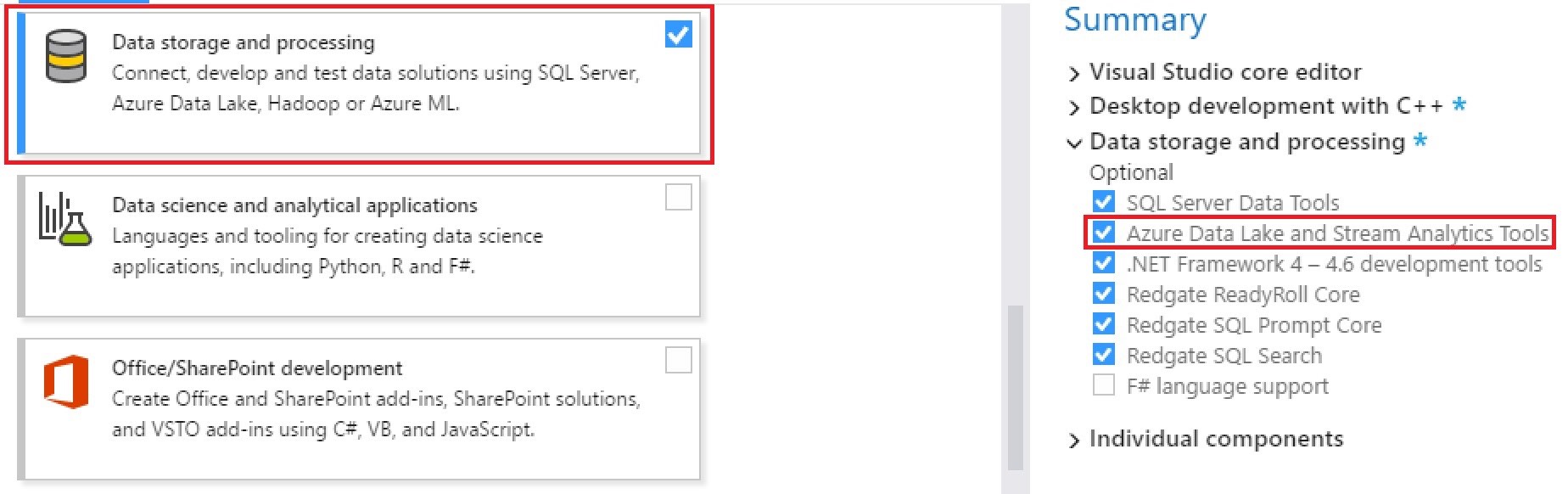
A quick note – as of this article, I have updated my Visual Studio installation, switching from Visual Studio 2015 to Visual Studio 2017. VS 2017 does not require a separate install of the Azure Data Lake Tools – they are provided as part of the main installer. To install the tools, open up the VS 2017 installer and look at the optional components you can install. Find Data Storage and processing and check the Azure Data Lake and Stream Analytics Tools option.
What is the Catalog?
Every Data Lake Analytics account has a catalog associated with it, which is used to store data and code. You can think of it as a collection of objects and data. The catalog is always present and cannot be deleted (in Azure, anyway; you can delete the file on your local machine, but it will be recreated from scratch the next time you open a U-SQL project). The principle aims of the catalog are to enable code sharing and enhance performance. It keeps a record of all of your databases and database elements, and comes with the master database built-in, which also cannot be deleted. The catalog stores databases, tables, table-valued functions (TVFs), schemas, assemblies and all other code-related items.
Don't confuse the Azure Data Lake Catalog with the Azure Data Catalog. The Azure Data Catalog is a complete standalone product and can be ignored for the purposes of this article.
We’ve covered most of the key database objects in past articles, so if you’ve been following the Stairway you have already been using the U-SQL catalog. It just sits in the background doing its thing. Knowing about it might just help you out when you have a rare bug and dropping objects doesn’t seem to fix it (yes, this has happened to me on occasion!).
Where is the Catalog?
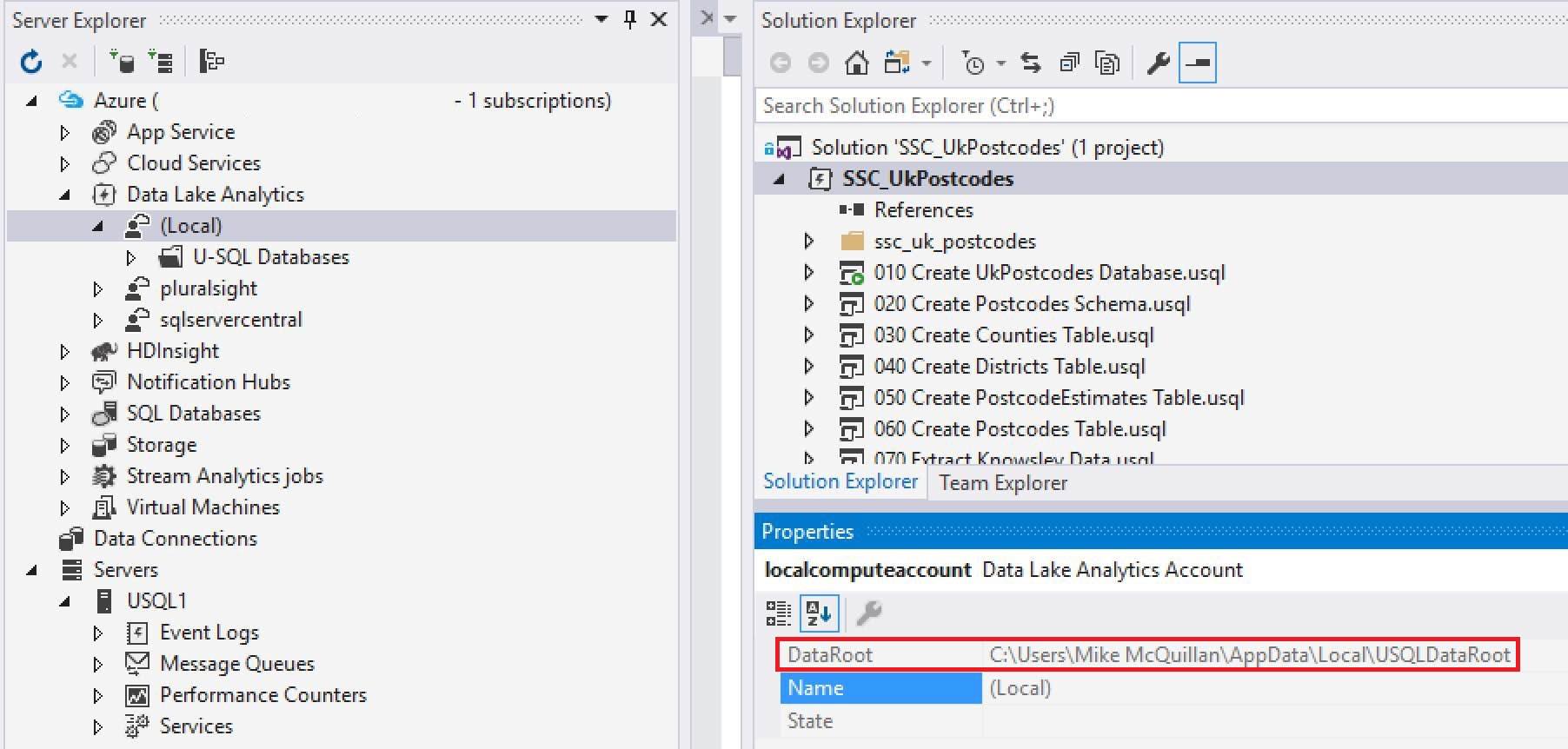
The location of the catalog depends upon the location of your Data Lake. If you’re using the local installation with Visual Studio, you can find the relevant folder by opening up Visual Studio and then opening up the Solution Explorer. Navigate to your Data Lake Analytics account and click on the (Local) option. Make sure the Properties window is displayed and take a look at the DataRoot path in there.
Copy this path, open Windows Explorer and paste the path into the Address Bar. If you’ve never created a custom database or you have a clean install (as in my image below), you should see a pretty empty folder, containing just one file. This file is part of your catalog, the rest of the catalog will appear as you create objects and insert data (upcoming images will make everything clear). We’ll talk about the file in a moment.
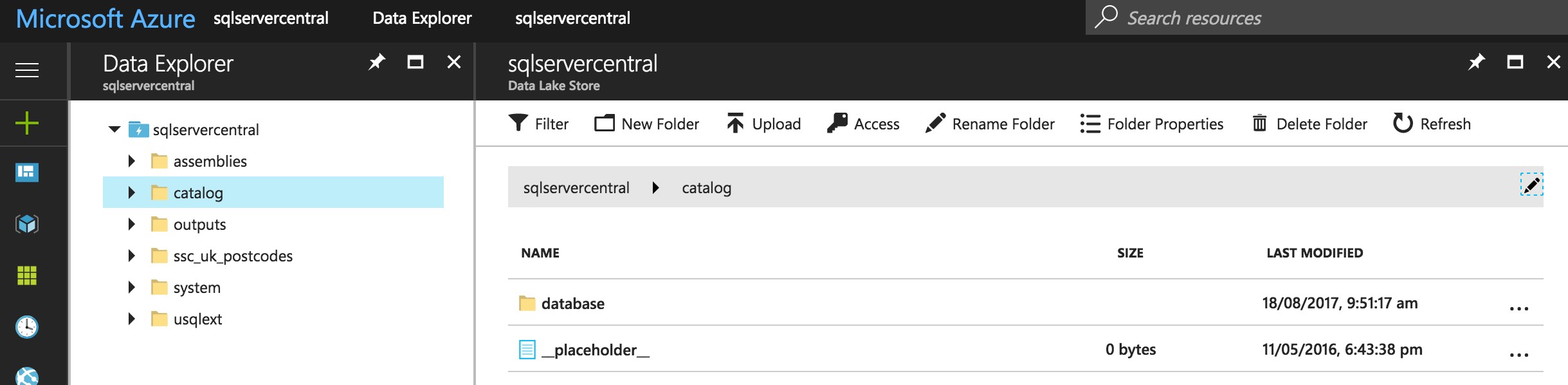
If you log on to Azure and open up your Data Lake Store account, you can use the Data Explorer to navigate to the catalog. The folder is simply entitled catalog, and even if you’ve only just set up your Store, it will contain an empty _placeholder_ file and a database folder.
What does the Catalog Contain?
So I can more easily demonstrate how the catalog ebbs and flows, I’ve cleared my local installation and my Azure installation, so just the defaults are present. We’ll take a look at how the local installation works first.

The localrunmetadata file contained within the folder maintains the metadata used locally. You won’t find this file in Azure. It’s a text file, and if you open it up in Notepad you’ll be able to make out some sense amongst the various coded characters. It’s possible to see a list of the various types that are registered for U-SQL, such as Microsoft.Analytics.Types.Sql.SqlInt32, which represents the int data type. There isn’t much value in looking at the contents of the file though, as any edits you make would render your installation unusable.
Every time you execute something locally, this file is updated. If you delete the file, it is recreated the next time you open a U-SQL solution or project in Visual Studio. If you’re having problems with your local installation, try deleting this file (make sure you back it up first, just in case!). It might solve your issue. You will need to recreate your databases and objects if you delete the file.
When you execute a script locally, you’ll see this file referenced by the Metadata Executor (the program that executes your U-SQL scripts). This tells the Executor where to obtain catalog information from locally.
In Azure, the catalog comes pre-populated with the master database. There’s a bunch of assemblies already installed too (system stuff like Python and R libraries – all the stuff that makes Data Lakes cool). This is a bit different from what you can see locally – you can’t see any centralised files managing your Data Lake, for instance. There isn’t any need for such a mechanism here – everything is spread across the Data Lake installation in Azure. All you can see here is the database folder. When you create objects and databases, they appear within this folder just like they do locally. The database folder contains one folder (you’ll see it with a GUID as the name), this is the folder that represents the master database.
Building up the Local Catalog
Let’s see how we can build the catalog up as we add items to it. I’ve opened up Visual Studio and created the following (all of the scripts executed are available in earlier articles in this Stairway series):
- A database, called UkPostcodes
- A schema within that database, called Postcodes
- Four tables – Counties, Districts, Postcodes and PostcodeEstimates
After running the above scripts locally, the USQLDataRoot folder looks like this:

No extra files! But the file has grown, up from 26k to 39k. So something has happened. Things might become a bit more concrete once I’ve inserted some data into the tables. I’ll insert:
- A file into the Counties table
- A file into the Districts table
- A file into the Postcodes table
- Four files into the PostcodeEstimates table
After inserting the data, we have a new folder, called _catalog_.

This contains a database folder. Go in there and you’ll find a GUID-named folder. This is the unique identifier assigned to the UkPostcodes database on your system, if you were to search the localrunmetadata file you’d find a load of references to the GUID in there, associating it with schemas, tables, views and the like.
Opening that folder reveals a schema folder, which in turn contains another GUID-named folder, this time representing the Postcodes schema. That’s where we’ll find the tables we created and populated. This folder contains a sub-folder called table, which contains four GUID folders – one for each table we inserted data into (Counties, Districts, Postcodes and PostcodeEstimates). This is how your tables are structured within the catalog. Open up one of those folders and you’ll see one or more SS files. These contain your source data (I’m not sure what SS stands for – “Structured Source” perhaps?).

If you look at one of these files in Notepad or similar, you’ll see all of the data from the table at the top, and then some XML which describes the structure. The folder containing four SS files is the PostcodeEstimates table – one file per input source. There were four files inserted into the PostcodeEstimates table, and a SS file has been generated for each of them.
Don’t touch these data files – the localrunmetadata file links them with the appropriate table. If you remove them as a quick way of trying to delete data, your EXTRACT scripts will run into trouble:

The only way to fix this condition is to drop the tables and recreate them. Once the CREATE TABLE scripts have been re-executed and re-populated, we can successfully run the script again. When the old tables were dropped, the GUID references were removed from the localrunmetadata file. New GUIDs were generated when we recreated the tables.
If you use any logical paths in your locally-executed scripts, the files they output or require need to end up in USQLDataRoot. If you run a script that outputs a file, such as this:
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; @pd = SELECT p.Postcode, p.Part1, p.Part2, p.CountyName, p.DistrictName FROM PostcodeDetailsView AS p; OUTPUT @pd TO "/outputs/pcodedetails.csv" USING Outputters.Csv();
An outputs folder will be created under the USQLDataRoot folder, and this will contain the pcodedetails.csv file.
Assemblies in the Catalog
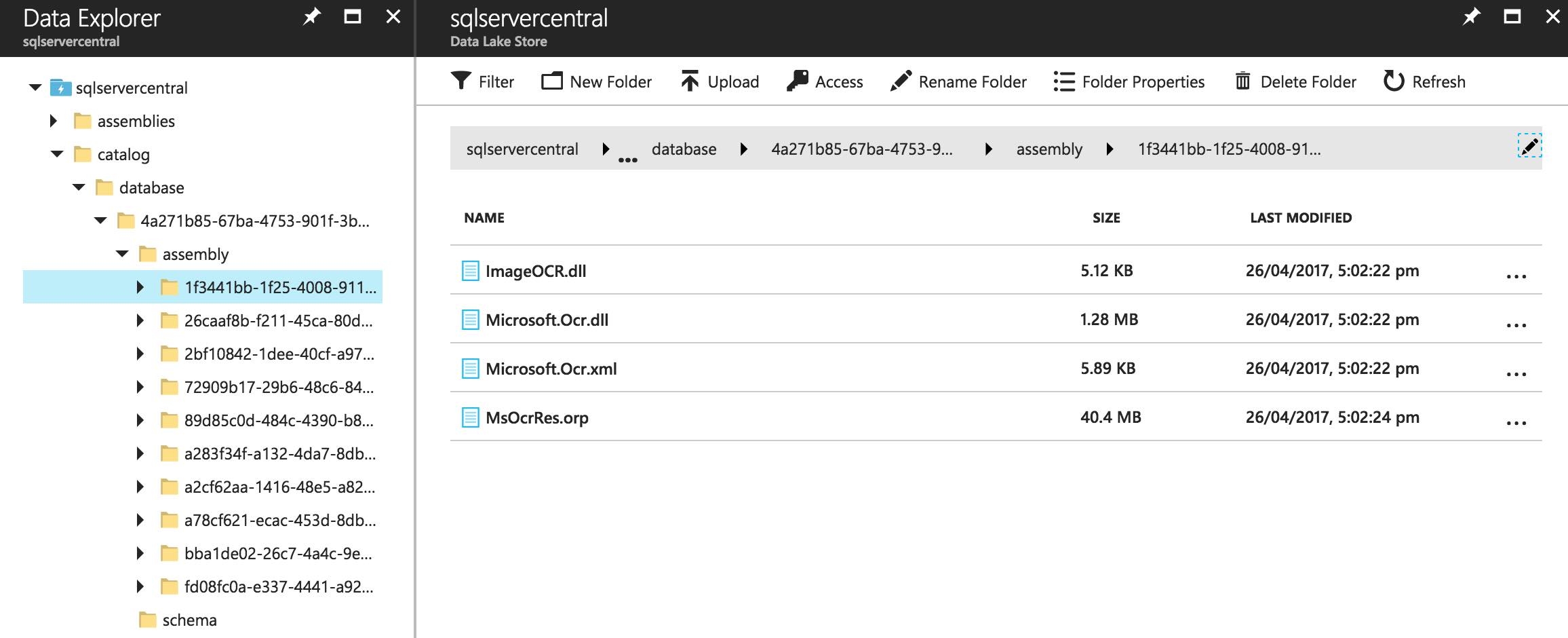
In the previous article in this Stairway, we created an assembly, written in C#. We had to register that assembly before we could use it. You guessed it, the assembly is registered in the catalog. Once registered, a new folder called assembly appears within the database folder (well, the actual GUID folder underneath database).

Another GUID folder representing the assembly is in there, and within that is the PostcodeLibrary.dll file generated when we built the assembly. All files required by your assembly will be dumped in here. Interestingly, running the deployment script again causes another copy of the assembly to be created, with a different GUID. This supersedes the previous version and also causes the files for the previous version to be removed (but the GUID reference folder for the previous version remains, sitting hauntingly empty).
The Catalog in Azure
It won’t surprise you to learn the Azure version of the catalog builds up in a very similar way to the local version. There are one or two differences though. The main difference comes in the schema folder. After running the same scripts to create a database, schema and populated tables, we end up with five schemas!
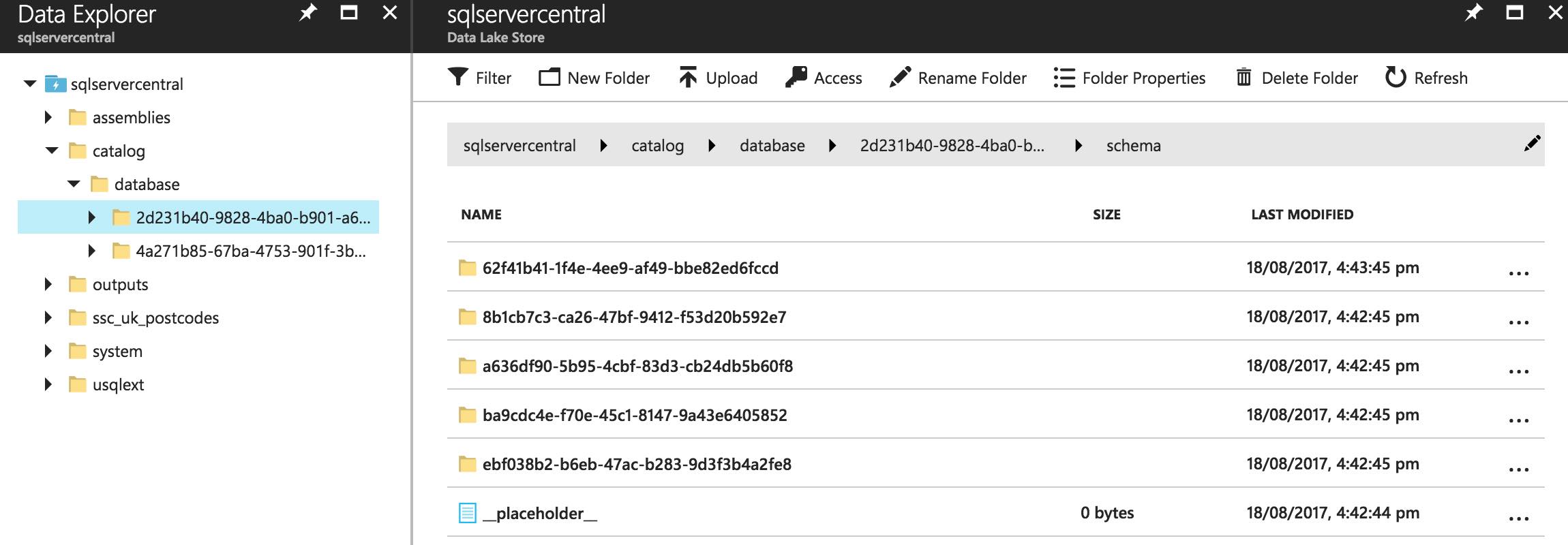
One of these is the Postcodes schema created by one of the executed scripts. The other four were automatically created when the new U-SQL database was instantiated. The default schemas are dbo, INFORMATION_SCHEMA, sys and usql.
Managing the Metadata
There are no catalog or dynamic management views in U-SQL. Microsoft plan to add these in at some point in the future (the existence of the default schemas gives some hints about how such a feature may work). What you can do at the moment is either use the Visual Studio Server Explorer or PowerShell.
Visual Studio Server Explorer
This gives some limited access to the catalog, as we’ve seen in previous articles. You can right-click on tables to view metadata about the table, via the Preview option (it’s called Preview by Running a Job for databases located in Azure).
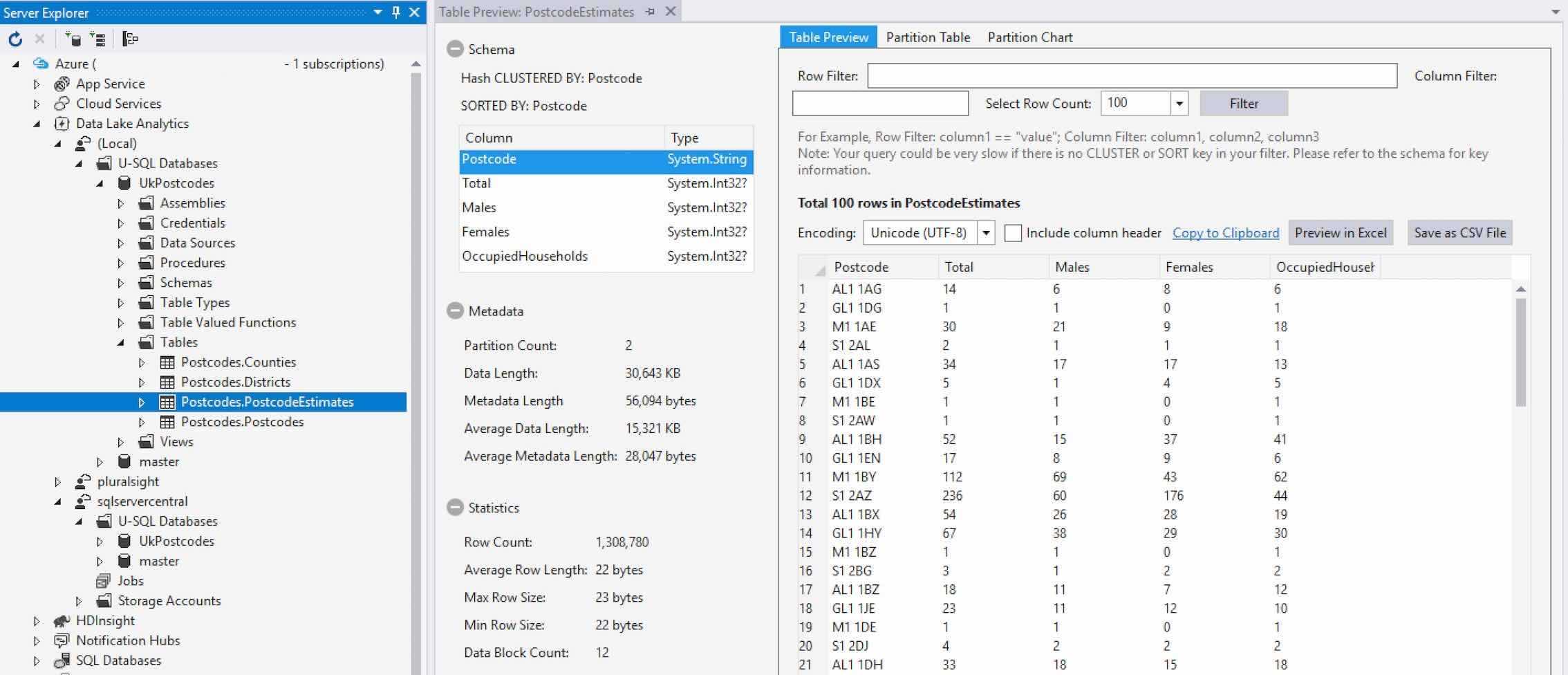
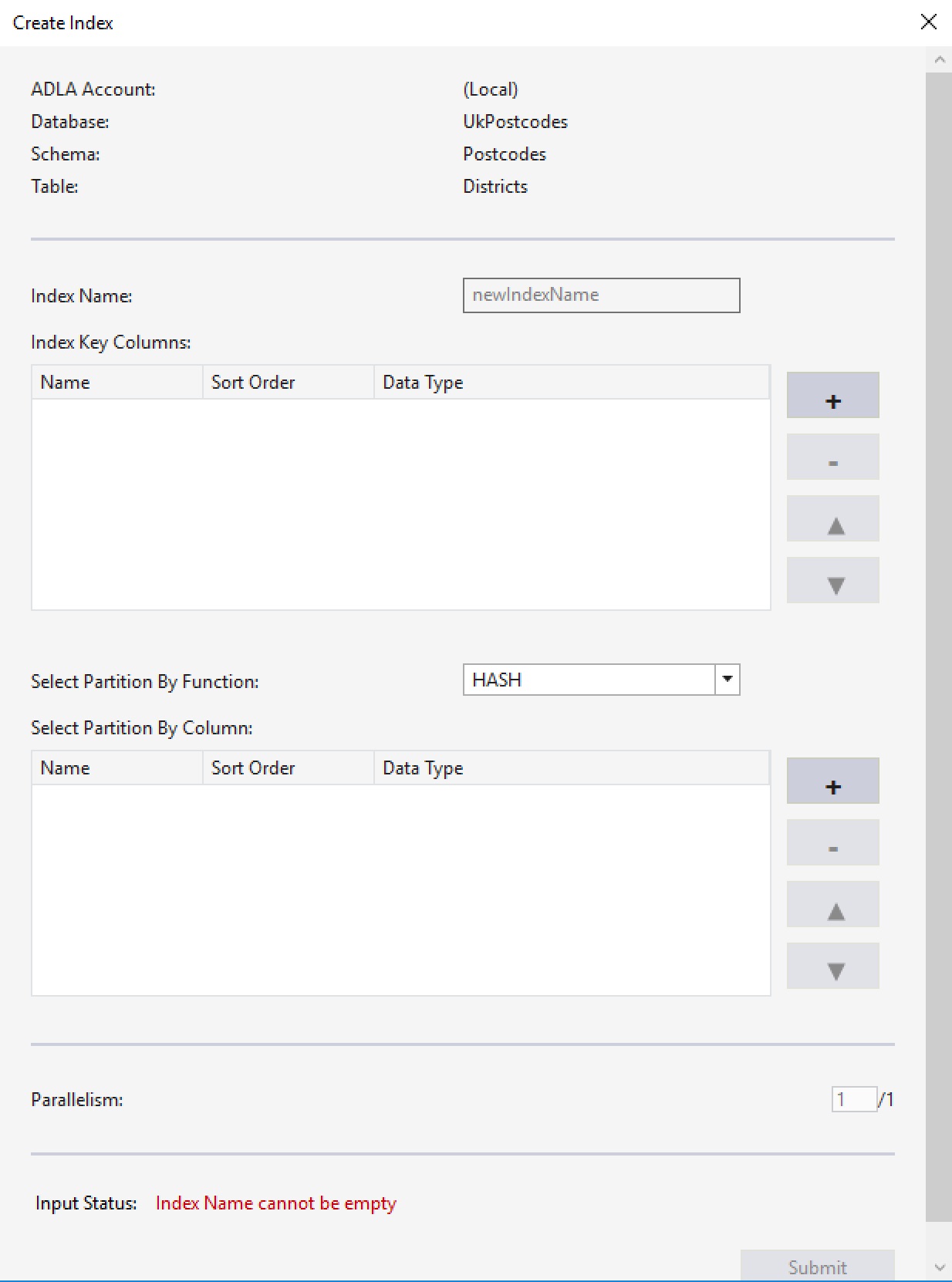
Scripts can be generated for objects like stored procedures, views and TVFs. Other items can be deleted, like schemas. You can even create clustered indexes through the GUI, by expanding the appropriate table and right-clicking on its Indexes node.
PowerShell
Microsoft continue to build out the PowerShell functionality for Data Lakes, we’ll be looking at this in more depth over some upcoming articles. Not only can you dig out metadata about the Data Lake from the PowerShell cmdlets, you can also create and execute U-SQL jobs and manage data – in fact, you can do a lot of the things we’ve been covering in the Stairway so far.
IMPORTANT! BEFORE YOU CAN RUN POWERSHELL CMDLETS, YOU NEED TO ENSURE YOU HAVE INSTALLED THE WINDOWS AZURE POWERSHELL MODULE. If you don’t install this you’ll be told “the cmdlet name was not recognized” whenever you try to execute one of the commands below.
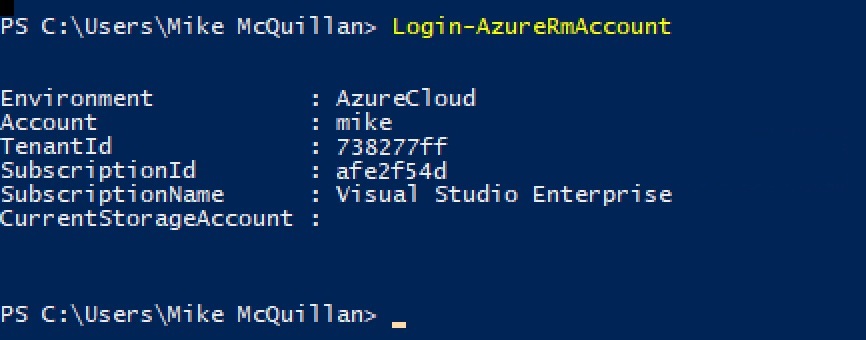
Before you can execute cmdlets against your Data Lake Analytics account, you need to log in using the command Login-AzureRmAccount. This will display a login prompt – enter your Azure details and a bit of confirmation information will appear. When you see this you’re good to go.
There are two PowerShell cmdlets which help you manage the catalog:
- Get-AdlCatalogItem
- Test-AdlCatalogItem (checks if the specified item exists)
Both require an ItemType parameter, which can be used to specify Database, Schema, Table, View, Procedure and a host of other options. Use this command to view the help for the appropriate cmdlet:
get-help Get-AdlCatalogItem
To list the schemas for a database, you could use this PowerShell command:
Get-AdlCatalogItem -Account "sqlservercentral" -ItemType Schema -Path "UkPostcodes"
Which returns:
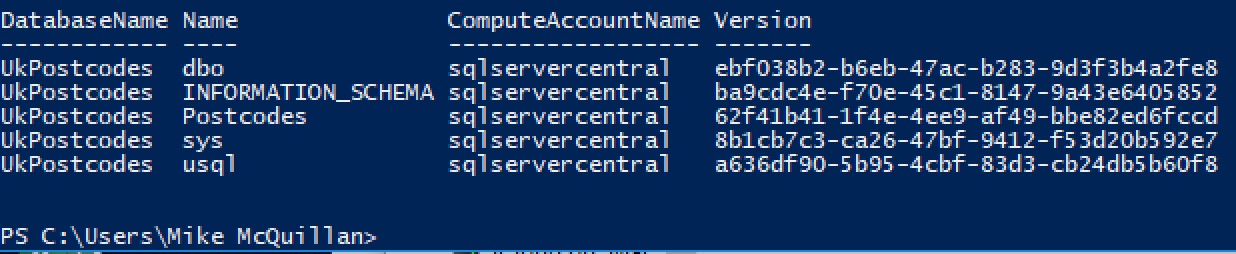
To test if a table called Postcodes exists in the UkPostcodes database, we could use:
Test-AdlCatalogItem –Account “sqlservercentral” -ItemType Table –Path “UkPostcodes”
This returns true:

There isn’t a way to list all items in the Data Lake from a single cmdlet – you’d need to write your own (hey, there’s an idea for a future article!). You can specify a path though, which allows you to limit the items that are returned. In fact, you must specify a path for all object types except databases.
Summary
This has been a deep dive into the back-end of Azure Data Lakes. Hopefully, you now have a better general idea of how things are working behind the scenes of your Data Lake, and the catalog isn’t a big mystery any longer.
We also took a brief look at PowerShell and how it can be used to provide some basic management of the catalog. We’ll take a good look at the other things we can do with PowerShell in the next article.