

Introduction
In the chapter 12, we learned about DMX. We learned some functions like the Predict, PredictHistogram, PredidictSupport and other functions.
This lesson will show more DMX functions.
Requirement
This chapter assumes that you are already familiar with the DMX language explained in the chapter 12.
Getting Started
1. In the SQL Server Management Studio (SSMS) connect to the Analysis Services and create a new DMX query.

2. Let's start with the IsInNode function, shows the cases related to a node specified.
Select *
from [Customer Clusters].Cases
WHERE IsInNode('008')As you can see, the query requires the model name and the node name. The query shows the cases related to the node 008.
3. You can find the node and model information using this query:
SELECT MODEL_NAME, NODE_NAME FROM $System.DMSCHEMA_MINING_MODEL_CONTENT
4. Another function is the Lag(). This function is used in time series algorithms only. The following example shows the amount earned, the quantity sold, and the Time Index of the cases in the last 24 months of the trained data.
SELECT Amount, Quantity, [Time Index] FROM [Forecasting].CASES WHERE Lag() < 24
5. The function RangeMax returns the maximum value of a bucket of a discretized column. The following example shows the maximum value of amounts earned for the forecasting algorithm.
SELECT DISTINCT
RangeMax([Amount]) AS [Maximum]
FROM [Forecasting]6. If we try the same query for the TM Cluster algorithm, we will have 10 values for the ages of the customers.
SELECT DISTINCT
RangeMin([Age]) AS [Maximum]
FROM [TM Clustering] 
7. This is because the ages are discretized in 10 buckets.

8. In the same way, you can obtain the Minimum discretized value of a bucket.
SELECT DISTINCT
RangeMin([Amount]) AS [Maximum]
FROM [Forecasting]9. Or the Midle value of a bucket in a discretized column.
SELECT DISTINCT
RangeMid([Amount]) AS [Maximum]
FROM [Forecasting]10. Let's talk a little more about decition trees nodes. In decition trees, you have a parent child with different children.
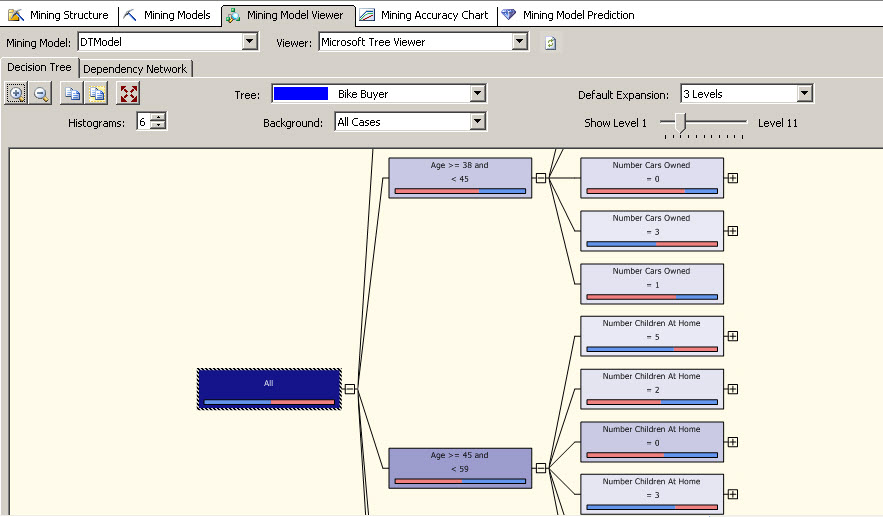
11. The IsDescendant shows the information about the descendats of the node 00000000100002010101
SELECT MODEL_NAME,NODE_NAME,NODE_DESCRIPTION
FROM [TM Decision Tree].CONTENT
WHERE IsDescendant('0000000010002010101')12. The following function is the Cluster. The cluster algorightm does not have parents and children as the desicion trees. Each node (cluster) is independent. The cluster function obtains the cluster name that will probably contain the case specified. The following example shows the cluster name of the user male, married with 1 car and 2 children at home.
SELECT
Cluster()
FROM [TM Clustering]
NATURAL PREDICTION JOIN
(SELECT 28 AS [Age],
'High School' AS [Education],
'M' AS [Gender],
'M' AS [Marital Status],
1 AS [Number Cars Owned],
2 AS [Number Children At Home]) AS t13. The cluster probability shows the probability for a specific node to accomplish a specific case. For example, in this query we are checking the probability of the Cluster 8 to accomplish the following charactecteristics of a user that is male, married with 1 car and 2 children at home.
SELECT
ClusterProbability('Cluster 8') as [probability]
FROM [TM Clustering]
NATURAL PREDICTION JOIN
(SELECT 28 AS [Age],
'High School' AS [Education],
'M' AS [Gender],
'M' AS [Marital Status],
1 AS [Number Cars Owned],
2 AS [Number Children At Home]) AS t14. If you to want to check the Cluster names of a Mining Model, you can use the following query:
SELECT NODE_CAPTION FROM [TM Clustering].CONTENT
SELECT
ClusterDistance() as distance
From [TM Clustering]
NATURAL PREDICTION JOIN
(SELECT 28 AS [Age],
'2-5 Miles' AS [Commute Distance],
'Graduate Degree' AS [Education],
0 AS [Number Cars Owned],
0 AS [Number Children At Home]) AS t16. As you know (or should know), when you create your data mining structure, part is used for training and part is used for testing the model (see the step 11 of the Introduction chapter for more information). You can query the test data and training data.
The following example shows the age, bike buyer, education and occupation information of the training cases of the customers whose education is bachellor.
SELECT Age, [Bike Buyer],Education, Occupation FROM [TM Decision Tree].CASES WHERE IsTrainingCase() and Education='Bachelors'
17. The next example shows the same information of the step 16, but it shows the Data used to test the Data mining structures.
SELECT Age, [Bike Buyer],Education, Occupation FROM [TM Decision Tree].CASES WHERE IsTestCase() and Education='Bachelors'
18. The other function is the StructureColumn it shows the value of the structure column.
SELECT StructureColumn('Gender') as Gender
FROM [TM Decision Tree].CASES
WHERE IsTrainingCase() and [Customer key]=11081Conclusion
As you can see, the DMX functions are not difficult to learn. There are some tricks to use them and they have many limitations compared with the T-SQL which is extremely flexible compared with the DMX.