

Introduction
In the lesson 11, we learned XMLA to process Data Mining objects, delete them and create or modify them. We also mentioned that DMX is similar to T-SQL. In this lesson, we will learn:
- How to create a Mining Structure in DMX
- How to create a Mining Model with DMX
- How to query a Model with DMX.
- Some functions in DMX that will be useful.
The DMX means Data Mining Extensions. These is the language used by Microsoft to create and query mining models. We will learn the basis in this lesson.
Requirements
We will work with the Adventurewok Project used in earlier chapters.
Getting Started
Let's start creating a Data Mining Structure. In order to start, start SQL Server Management Studio and open Analysis Services.
Press the DMX icon to start doing DMX queries.

In the Connect to Analysis Services Window, specify your server and press Connect.
In the Database combobox, select your Adventure Works DW database.
The first query is similar to a create table in T-SQL. Instead of using the create table you create a mining structure. The script creates a structure Named MyStructure. Press F5 to execute these DMX statements:
CREATE MINING STRUCTURE [MyStructure] ( [Customer Key] LONG KEY, [Age]LONG DISCRETIZED(Automatic,10), [Bike Buyer] LONG DISCRETE, [Commute Distance] TEXT DISCRETE, [Education] TEXT DISCRETE, [Gender] TEXT DISCRETE, [House Owner Flag] TEXT DISCRETE, [Marital Status] TEXT DISCRETE, [Number Cars Owned]LONG DISCRETE, [Number Children At Home]LONG DISCRETE, [Occupation] TEXT DISCRETE, [Region] TEXT DISCRETE, [Total Children]LONG DISCRETE, [Yearly Income] DOUBLE CONTINUOUS )
The structure can be used by many Data Mining Algorithms. In this sample, the name of the structure is MyStructure. The columns can be:
- Text
- Boolean
- Long
- Double
- Date
For more information about Data Types, go to the Microsoft Data Types help.
The columns can also have a content type. The content type can be:
- Discrete (which contains a finite number)
- Discretized (a continue numbers converted to discrete numbers)
- Continuos (which contains an ifinite number)
- Key (unique identifier)
- Key sequence (for the sequence cluster algorithm)
- Table (when the column contains a table)
- Cyclical (for a cyclical order set)
- Ordered (for sequencial order)
- Classified (to create relationships between columns).
For more information about Content Types, you can go to the Microsoft Documentation.
If you refresh the object browser you will be able to see the Data Mining Structure just created.

The next step is to create Mining Models using the current structure. As I said before, the Mining Structure can have many models. In this sample we are going to Alter the Mining Structure just created and add a Decision Tree Model named MyTreeModel:
ALTER MINING STRUCTURE [MyStructure] ADD MINING MODEL [MyTreeModel] ( [Customer Key], [Age], [Bike Buyer] PREDICT, [Commute Distance], [Education], [Gender], [House Owner Flag], [Marital Status], [Number Cars Owned], [Number Children At Home], [Occupation], [Region], [Total Children], [Yearly Income] ) USING Microsoft_Decision_Trees WITH DRILLTHROUGH
We are using the Alter sentence to modify the Mining Structure. The Add Mining Model Sentence will add the new model to the structure. The value to Predict is the Bike Buyer column which returns a value of 0 if the customer is not a buyer and 1 if he is.
The USING Microsoft_Desicion_Trees specified the algorith used by the model and the WITH DRILLTHROUGH option allows to get details about the model.
Execute the script with F5 and verify that the new Mining model named MyTreeModel is created.

The next step is to add information to the mining Structure. We are going to use the Database from the SQL Server Database Engine. The database name is AdventureWorksDW2012. Verify the name of your DW Adventureworks to include the exact name in the OPENQUERY Sentence. The view with the information about the customers is dbo.TargetMail. We are going to load the information from this view to the Mining Structure named MyStructure using the INSERT INTO Sentence:
INSERT INTO MINING STRUCTURE [MyStructure]
(
[Customer Key],
[Age],
[Bike Buyer],
[Commute Distance],
[Education],
[Gender],
[House Owner Flag],
[Marital Status],
[Number Cars Owned],
[Number Children At Home],
[Occupation],
[Region],
[Total Children],
[Yearly Income]
)
OPENQUERY([AdventureWorksDW2012],
'SELECT CustomerKey, Age, BikeBuyer,
CommuteDistance,EnglishEducation,
Gender,HouseOwnerFlag,MaritalStatus,
NumberCarsOwned,NumberChildrenAtHome,
EnglishOccupation,Region,TotalChildren,
YearlyIncome
FROM dbo.vTargetMail')SELECT Predict([MyTreeModel].[Bike Buyer]) From [MyTreeModel] NATURAL PREDICTION JOIN (SELECT 37 AS [Age], '5-10 Miles' AS [Commute Distance], 'Bachelors' AS [Education], 'M' AS [Gender], 'S' AS [Marital Status], 0 AS [Number Cars Owned], 'Professional' AS [Occupation], 0 AS [Total Children]) AS t
The query is a select to the Mining Model MyTreeModel. We are using the predict function which will return the value of 1 if the customer with a Commute Distance of 5-10 miles, who is single (S) with 0 Number of Cars and Professional, 37 years old, with Bachelors Education, Male (M) will buy a bike.
If you run the query the Result will be 1. That means that a user with the characterists specified will buy a bike.

Now if we change the query with different information about the customer we will notice that this new customer with the new characteristics will not buy a bike and the result of the query will be 0.
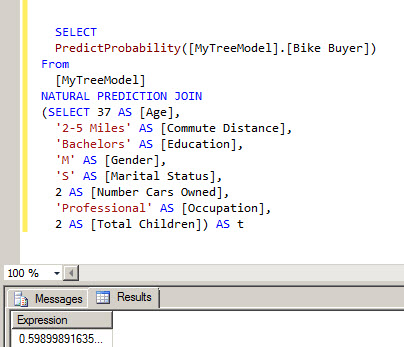
SELECT Predict([MyTreeModel].[Bike Buyer]) From [MyTreeModel] NATURAL PREDICTION JOIN (SELECT 37 AS [Age], '2-5 Miles' AS [Commute Distance], 'Bachelors' AS [Education], 'M' AS [Gender], 'S' AS [Marital Status], 2 AS [Number Cars Owned], 'Professional' AS [Occupation], 2 AS [Total Children]) AS t

This new sample uses the predictProbability. Instead of returning a 0 or a 1 it returns the exact value between 0 and 1. In this sample the value returned is 0.5989.
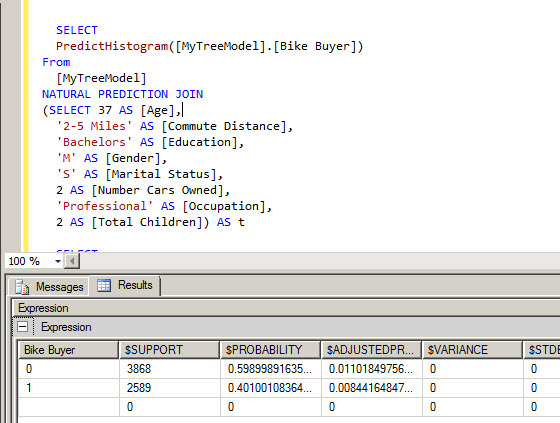
The PredictHistogram shows more complete information. It gives probabilities, the support, adjusted Probability, Variance, The Standard Deviation.
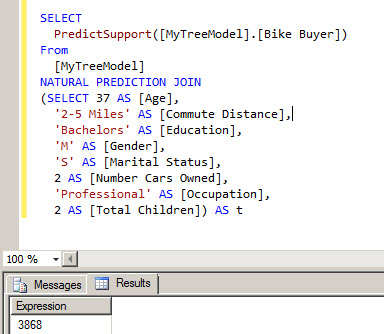
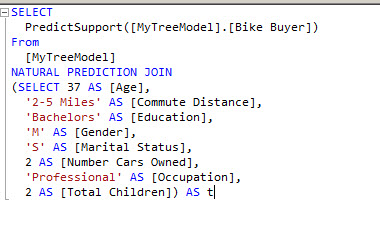
These new sample shows how to use the PredictSupport function. It shows the number of cases that follows the queries.
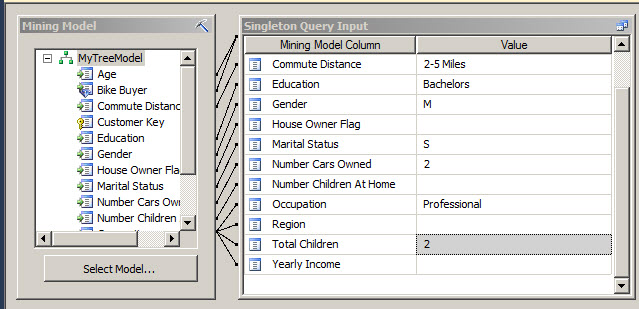
Finally, you can create your DMX queries using the Build Prediction Query option.

You can specify the values of the columns with the information to query.
Right click to switch to the Query mode:
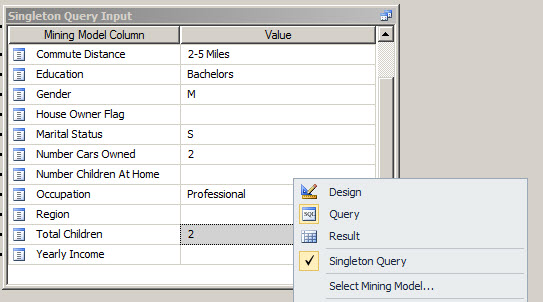
Now you have your DMX query ready.
Conclusion
In this sample, we learned simple samples to create a Data Mining Structure with DMX, we created a Mining Model, we then load the model with information from a SQL Server View and then we used DMX queries to predict if a customer with specific information will buy or not a bike.
References
http://technet.microsoft.com/en-us/library/ms174796.aspx