

Introduction

In Classical Antiquity, an oracle was a person considered to be a source of wise counsel with prophetic predictions or precognition of the future, inspired by the gods. They had the gift to predict the future and advise the people with their wisdom. Today we do not have those oracles to predict the future. It would be nice to have an oracle to predict if our business is going to make profits, how much are we going to earn in the next 2 years and the answers to other questions related to the future.
Since we do not have oracles (at least not good ones), data mining was created to help us to analyze our information and predict the future.
Data Mining
Data Mining is a process to discover patterns for a large data set. It is an expert system that uses its historical experience (stored in relational databases or cubes) to predict the future. Let me explain you what you can do with data mining using an example:
Imagine that you own a company named Adventureworks. The company sells and manufactures bikes. You want to predict if a customer will buy or not a bike based in the customer information. How can you accomplish the mission?
The answer is Data Mining. This tool will find the patterns and describe the characteristics of the customers with higher probability to buy the bikes or the lower probability. Microsoft comes with a nice tool included in SQL Server Analysis Services. You do not need to create a cube or an analysis services project. You can work with relational databases directly.
Example
In this sample, we are going to work with the database AdventureworksDW if you do not have it installed you can download it from the http://msftdbprodsamples.codeplex.com/ site.
Once the AdventureworksDW is installed, use a select to verify the existent information in the v_targetmail view:
SELECT * FROM [AdventureWorksDW.[dbo.[vTargetMail
If you review the results you will find a lot of information about the customers like:
- The customer key
- The title
- The age
- Birthdate
- Name
- Lastname
- MaritalStatus
- Suffix
- Gender
- EmailAddress
- YearlyIncome
- TotalChildren
- NumberChildrenAtHome
- EnglishEducation
- SpanishEducation
- FrenchEducation
- EnglishOccupation
- SpanishOccupation
- FrenchOccupation
- HouseOwnerFlag
- NumberCarsOwned
- AddressLine1
- AddressLine2
- Phone
- DateFirstPurchase
- CommuteDistance
- Region
- Age
- BikeBuyer
All this information is important, but it is a lot! How can I find patterns? For example, if a person is married, (the maritalstatus column) it may affect in the decision to buy a bike. The age is important as well, depending on the age the people may want to buy a bike or not. How do you know which column is important? Which characteristic has more impact in the decision to buy a bike?
As you may notice, it is pretty hard to find which attributes affects the decision because there are 32 columns in the table. There are too many combinations, so it is hard to find patterns. If you create a cube with all the information, it will be easier to find patterns, but even with cubes, we may miss some patterns because of the different combinations.
That’s why we use Data Mining. To organize all the columns, analyze them and prioritize them.
Notice that there is a special column named bikebuyer (the last column). This column shows the value of 1 if the customer bought bikes and 0 if he didn’t. This is the value that we want to predict. We want to know if a customer will buy or not bikes based in our experience (in this case the experience is the vtargetmail view.
Getting started
In this example, I will show how to create a Data Mining project using the view vTargetMail.
There are 3 sections here.
1. Create a Data Source
2. Create a Data View
3. Create a Data Mining Project
4. Predict information using the Mining Model
Create a Datasource
First, we are going to select the SQL Server and the connection properties. This is the Data Source.
1. To start a Data Mining project we will use the SQL Server Business Intelligence included with the SQL Server Installation.
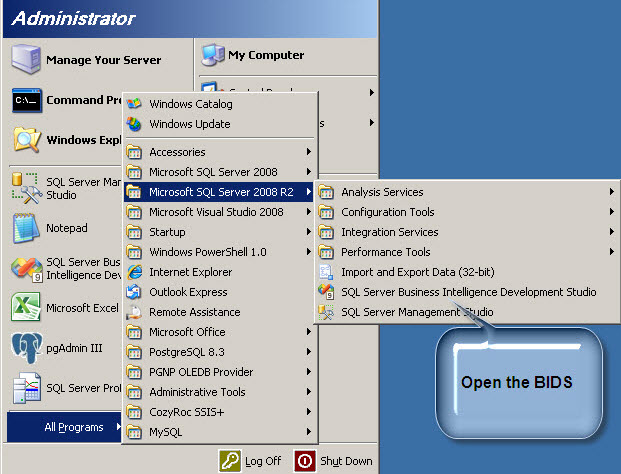
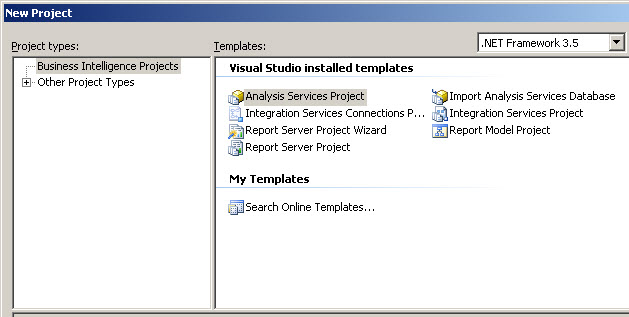
2. Go to File> New Project and select the Analysis Services Project
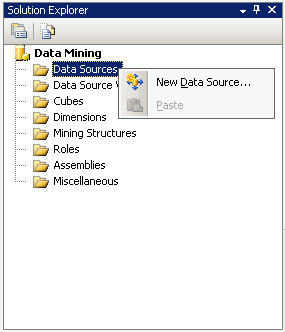
3. In the solution explorer right click the Data Sources and select a New data source.
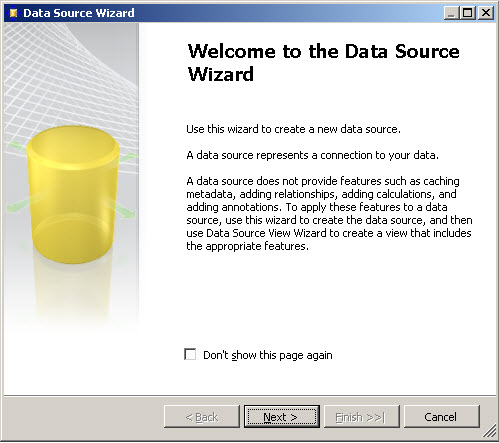
4. In the Data Source Wizard, press next.
5. We are going to create a new Data Connection. Press New.
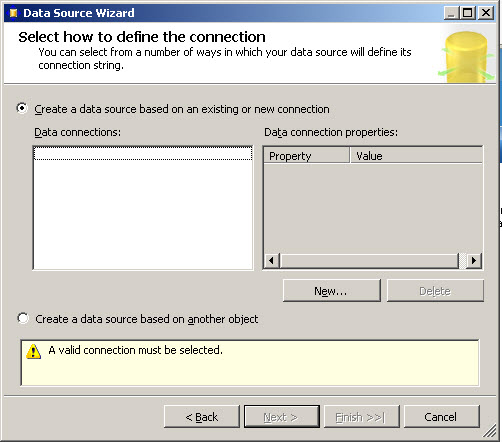
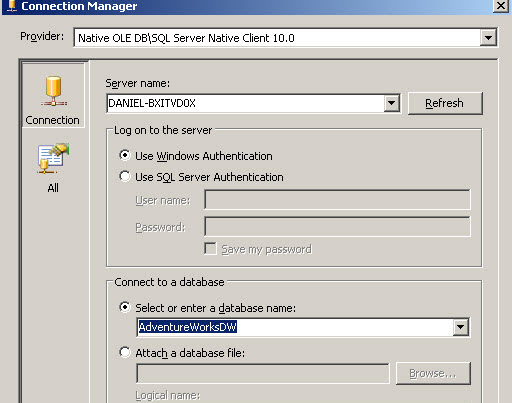
6. In the connection manager specify the SQL Server name and the Database. In this scenario we are going to use the AdverntureworksDW Database.
7. In the Data source wizard, press next
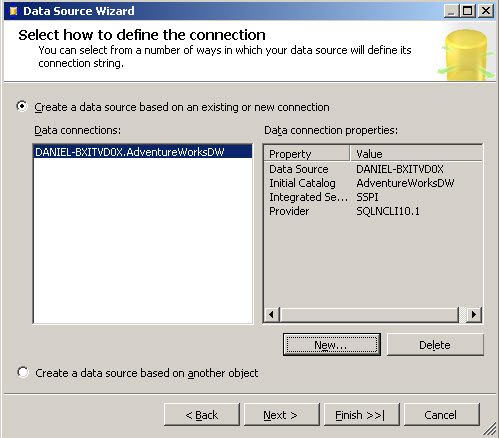
8. Press Next and then Finish.
You have created a Data Source to the AdventureWorksDW Database
Create a Data Source View
Now we are going to add the View vTargetMail in order to add it we are going to use a Data Source View. To resume, a Data Source View let us add the tables and view in the project.
1. In the Solution Explorer right click in the Data Source View and select New Data Source View.
2. In the Welcome to the Data Source View Wizard,
3. In the Select a Data Source Window select the Data Source created.
4. In the Select Tables and Views, select the vTargetMail and press the > button.
5. In the Completing the Wizard window, press Finish.
We just created a Data View with the view to give experience to our Data Mining Model. The vTargetMail is a view that contains historical data about the customers. Using that experience, our mining model, will predict the future.
Data Mining Model
Now we are going to create the Mining Model using the Data Source and Data Source View created before.
1. In the Solution Explorer, right click in the Mining Structures Folder and select New Mining Structure.
2. In the Welcome to the Data Mining Wizard, press Next.
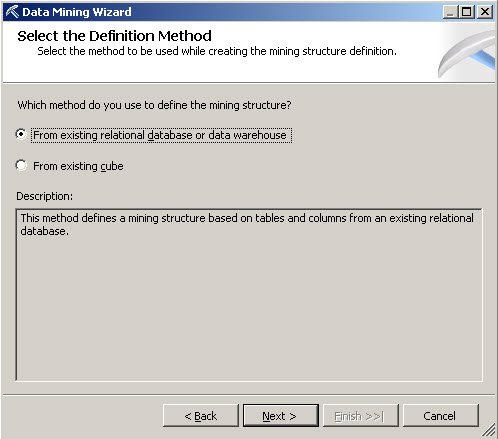
3. In the select the Definition Method, select the option From existing relational database or data warehouse and press Next. As you can see, we can use relational databases, data warehouses or cubes.
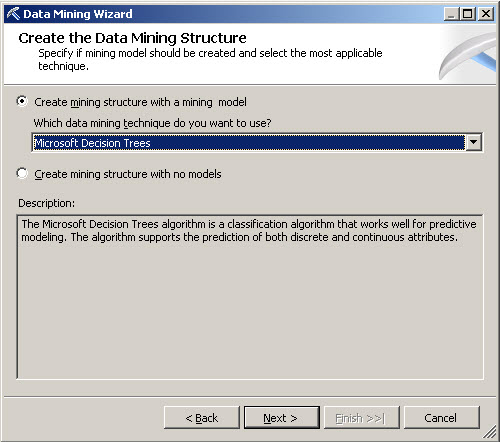
4. In the Create the Data Mining Structure Window, select Create mining structure with a mining model and select the Microsoft Decision Trees and press next. I am going to explain the details in another article about the mining techniques. By the moment let’s say that we are using a Decision Trees algorithm for this example.
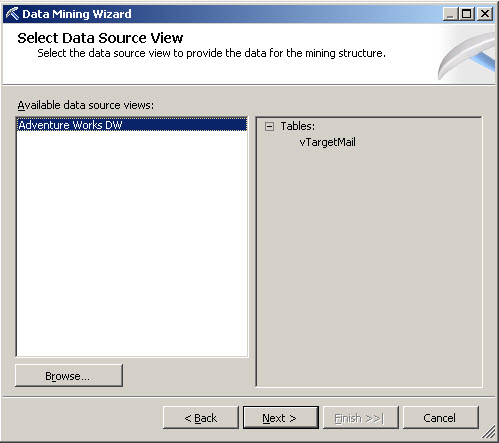
5. In the Select Data Source View, select the Data Source View created and press Next.
6. In the Specify Table Types, select the vTargetMail.
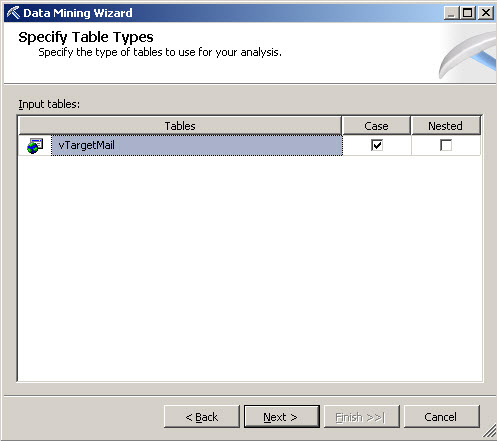
7. In the specify Bike Buyer row in the predict column, select the checkbox and press the button Suggest.
In this option, we are selecting which information we want to predict. In this scenario we want to predict if the person is a bike buyer or not.
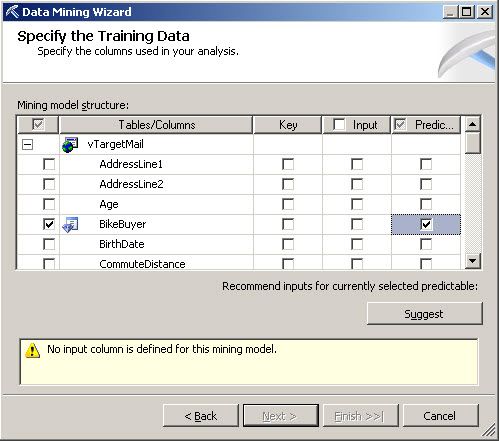
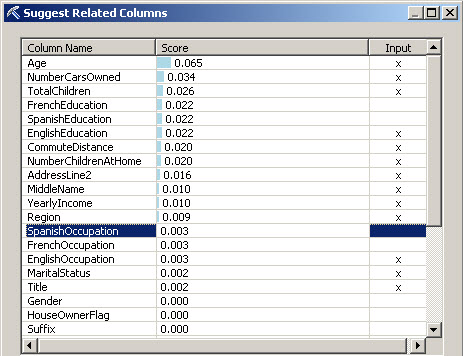
8. In the Input column mark with an x all the Column Names with the Score different than 0. What we are doing is to choose which columns are relevant in the decision to buy a bike.
9. In the left column, select the first name, last name and email (this is going to be used do drill throw the information) and press Next.
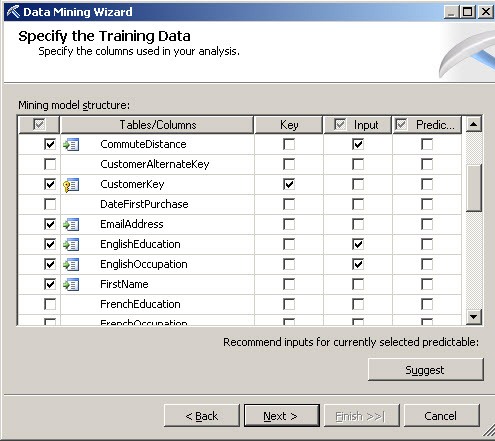
10. In the Specify Columns Content and Data Type, press Detect and press Next.
I am going to explain Content Types and Data Types in future articles. By the moment, lets say that we are detecting the Data Types.
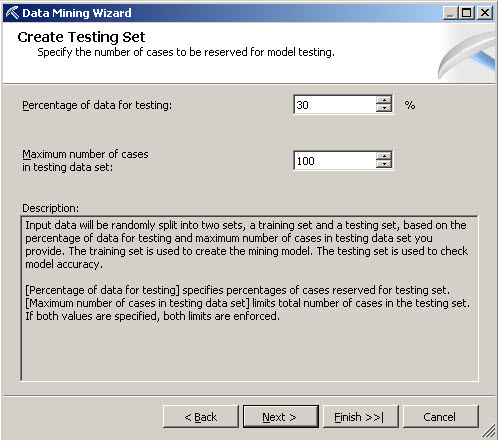
11. In the Create Testing Set, set 100 Maximum number of cases in testing data set and press Next.
This window is used to test the data. I will explain more details in later articles.
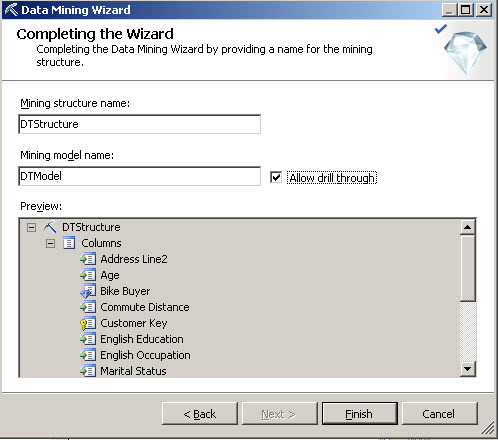
12. In the Completing the Wizard Window, write the Mining Structure name and Mining model name and check the Allow drill through and press Finish.
13. Now click in the Mining Model Viewer and you will receive a Windows message to deploy the project. Press the yes button.
14. We will have a Message to process the model. Press Yes.
15. In the Process Mining Model, press Process
16. In tree Process Progress, once it has finished successfully, press close.
17. Click in the Mining Model Viewer. The following Desition Tree should be displayed.
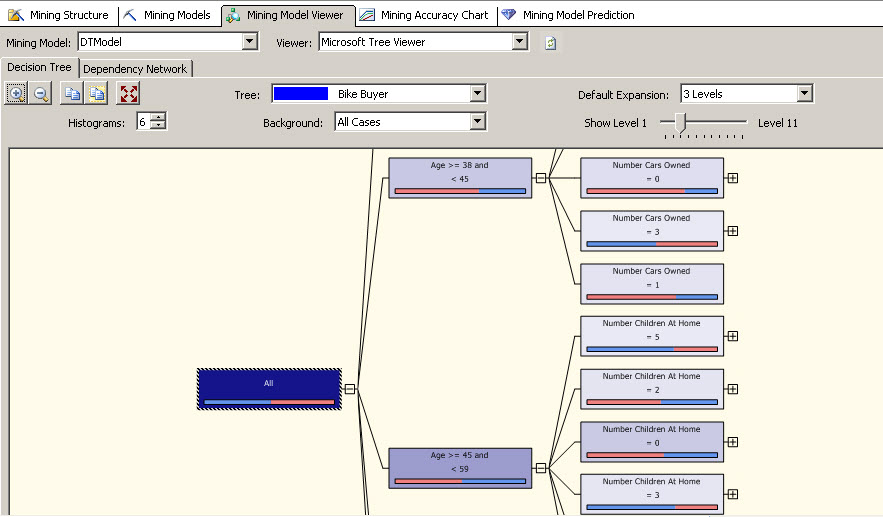
We just created a Data Mining project using Decision Trees. It is ready to test. Our final task is to use it. I will create some queries to predict if a user will buy or not a bike using the Data Mining.
Predict the future
Now that we have our Data Mining, let’s ask to our Oracle if a customer with specific characteristics will buy or not our bikes. We will create 2 queries.
The first query will ask our oracle if a 45 years old customer with a Commute Distance of 5-10 miles with High School education will buy a bike. The second query will ask our oracle if a 65 years old customer with a Commute Distance of 1-2 miles with missing education will by a bike.
1. First of all we need to move to the Mining Model Prediction Tab. Click there.
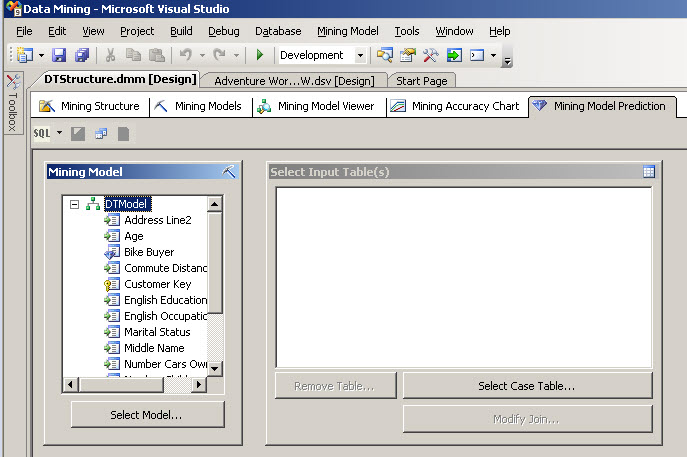
2. In the Mining Model Window, click in the select Model Button
3. In the Select Model Window, expand the Data Mining>DTStructure and select the DTModle and click OK.
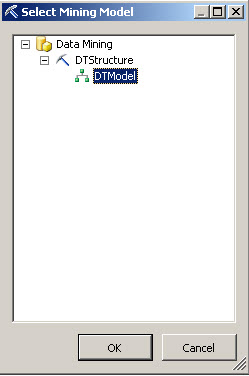
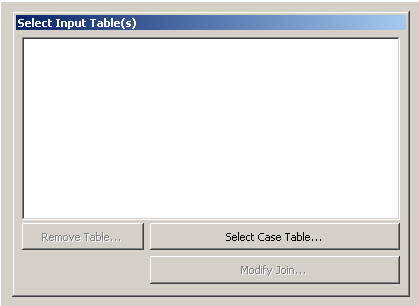
4. In the Select Input Table, click the Select Case Table
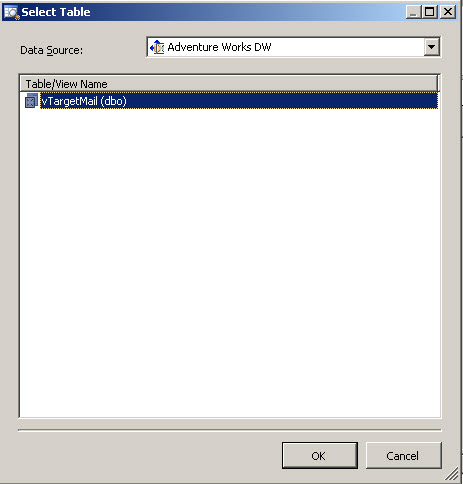
5. In the Select Table Window, select the vTargetMail and press OK
6. Right click in the Select Input Table and select the Singleton Query
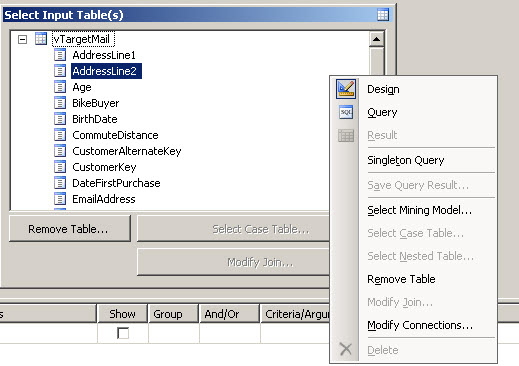
7. In the Singleton Query specify the following information:
Age 45: Commnute Distance 5-10 Miles, English Education: High School, English Ocupation: Professional, Marital Status: S, Numerber of Cars Ownerd: 5, Number of children at home: 3. In this step we are specifying the customer characteristics.

8. In the source Combobox, Select the DTModel mining model
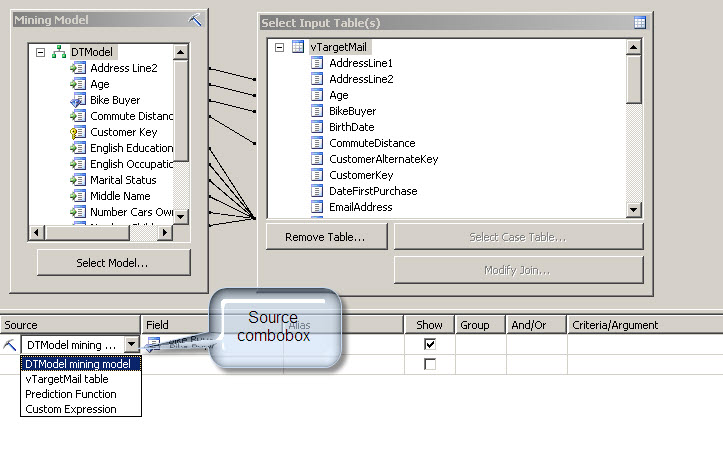
9. In the second row of the source column, click in the combobox and select the Prediction Function
10. In the second row of the field column, select the PredictHistogram
11. In the Criteria Argument column write: [DTModel].[Bike Buyer]
What we are doing is to specify the probability of this user to buy a bike using the PredictHistogram.
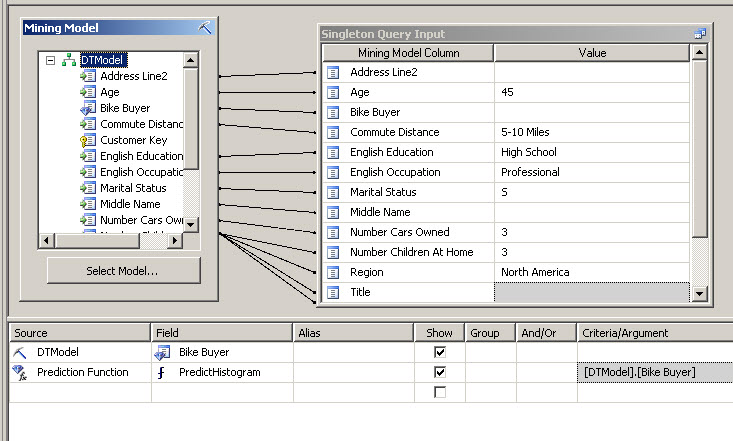
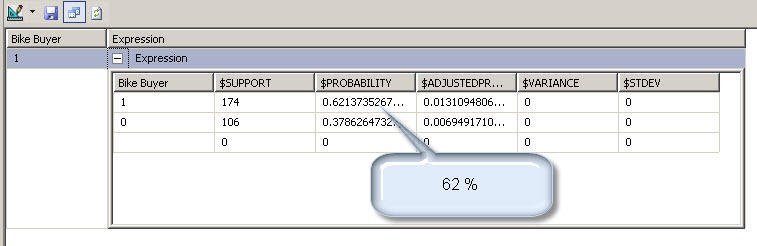
12. Now, click on the switch icon and select Result to verify the results of the query.
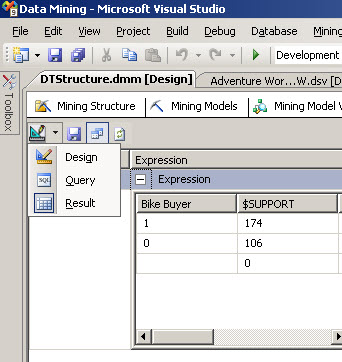
13. If you watch the results you will find than the probability to buy a bike is 0.6213. It means 62 %. So now we have our oracle ready to predict the future!
14. Finally, we are going to ask if another user with the following characteristics will buy a bike:
Age 65: Commnute Distance 1-2 Miles, English Education: Missing, English Ocupation: Clerical, Marital Status: S, Numerber of Cars Ownerd: 1, Number of children at home: 0. In this step we are specifying the customer characteristics.
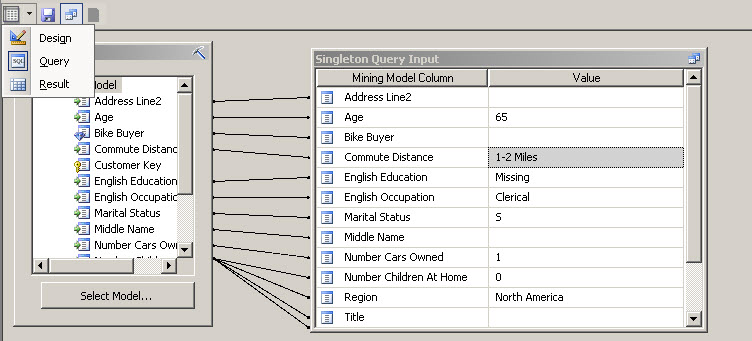
15. Once this is done, let’s select the switch icon and select the Result.

The probability to buy for a customer with these characteristics is 57 %.
Summary
In this article we described how to predict the future using the Data Mining. There are many different scenarios to apply Data Mining. In this example we used a Decision Tree algorithm to predict the future.
We used a View to feed our Mining Model and then we asked the model if 2 customers will buy or bikes. The first one has a probability of 65 % and the second one 57 %.
Now that you have your mining model ready. You can ask him the future.
Good luck.
References
http://nocreceenlosarboles.blogspot.com/2011/11/al-oraculo-de-delfos-no-le-dejan-votar.html
http://msdn.microsoft.com/en-us/library/ms167167(v=sql.105).aspx