

Introduction
While working with the Azure Data Factory pipelines we are often required to copy data from a large number of objects, for example, from 1000 tables. In that case, the best approach is to create a table (a control table) where we can store all the object details. We then let the pipeline parameters read those objects and then copy the data. It is a difficult job to implement this type of pipeline manually. Thanks to the ADF metadata-driven copy task, which is a wizard-based tool, it is easy to create a metadata-based pipeline.
Pipeline Development
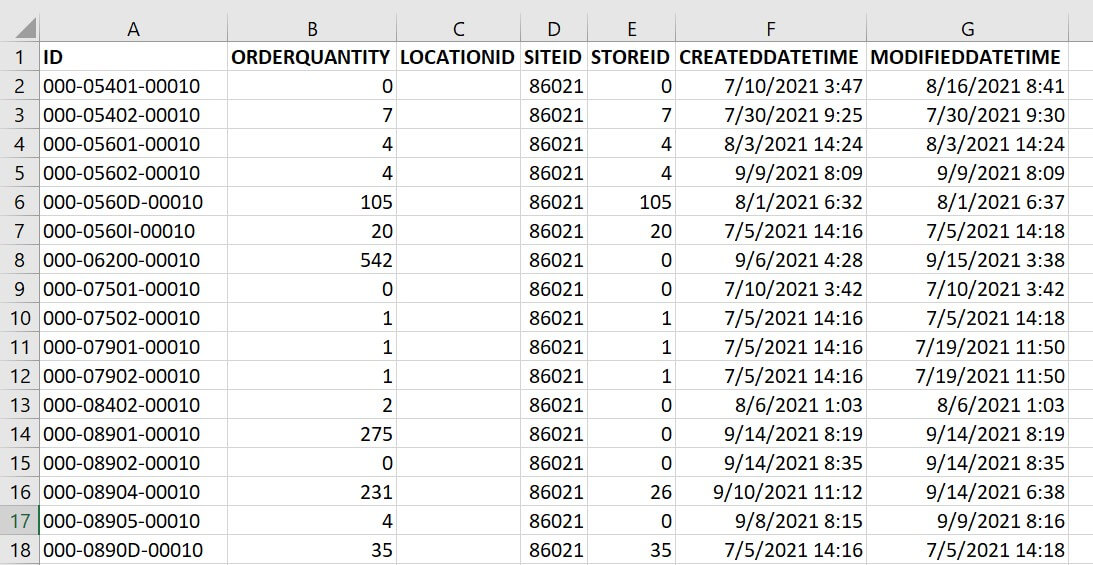
For the demo, we will use a flat file as a source, which is placed in a data lake storage Gen 2 folder. We will use an Azure SQL database table as the sink. The sample source flat-file looks like this image:
Let's go to the ADF authoring page, you will see the ingest option as below. Click on that.

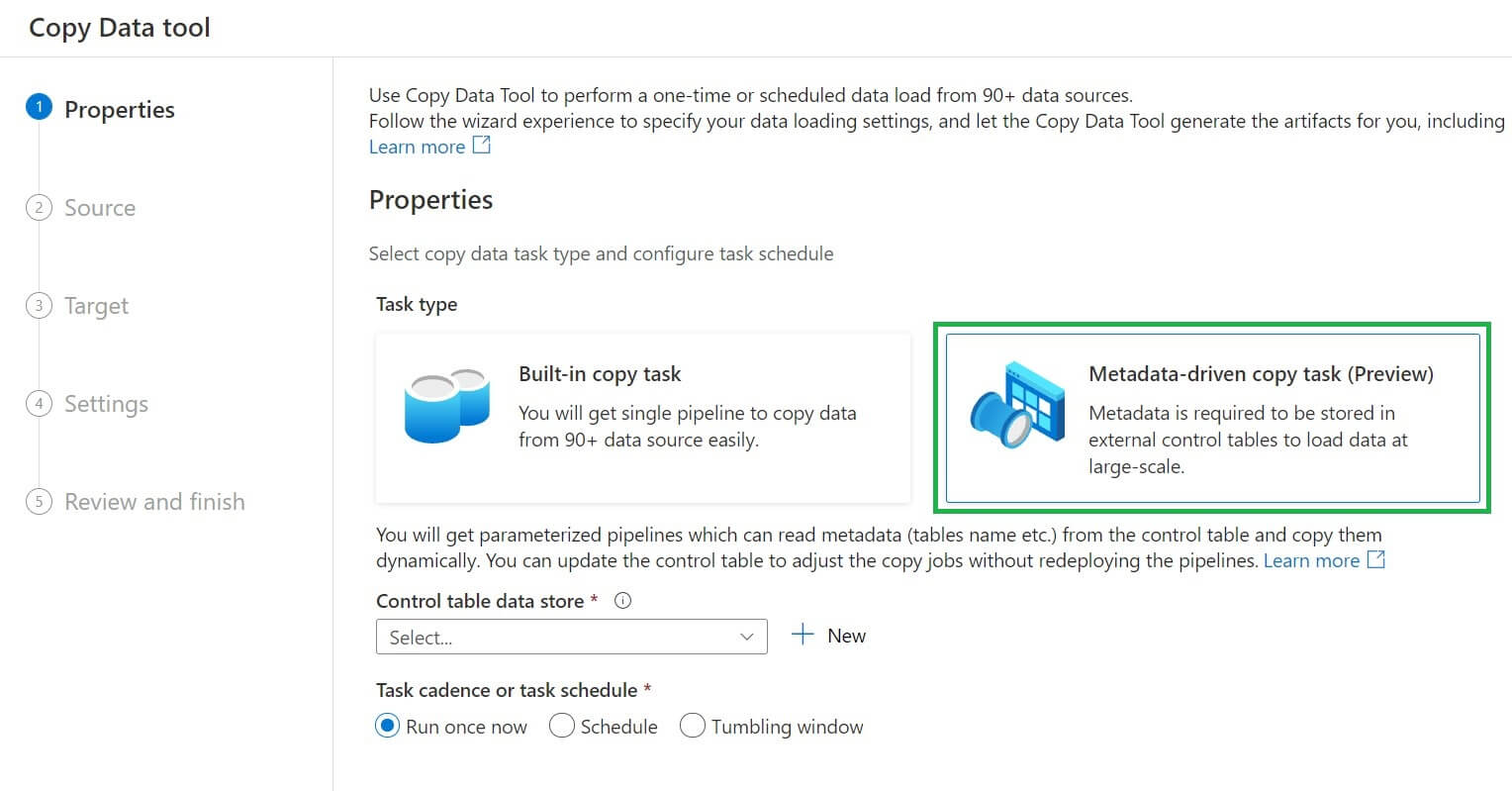
Now I will select the meta-data driven copy task.
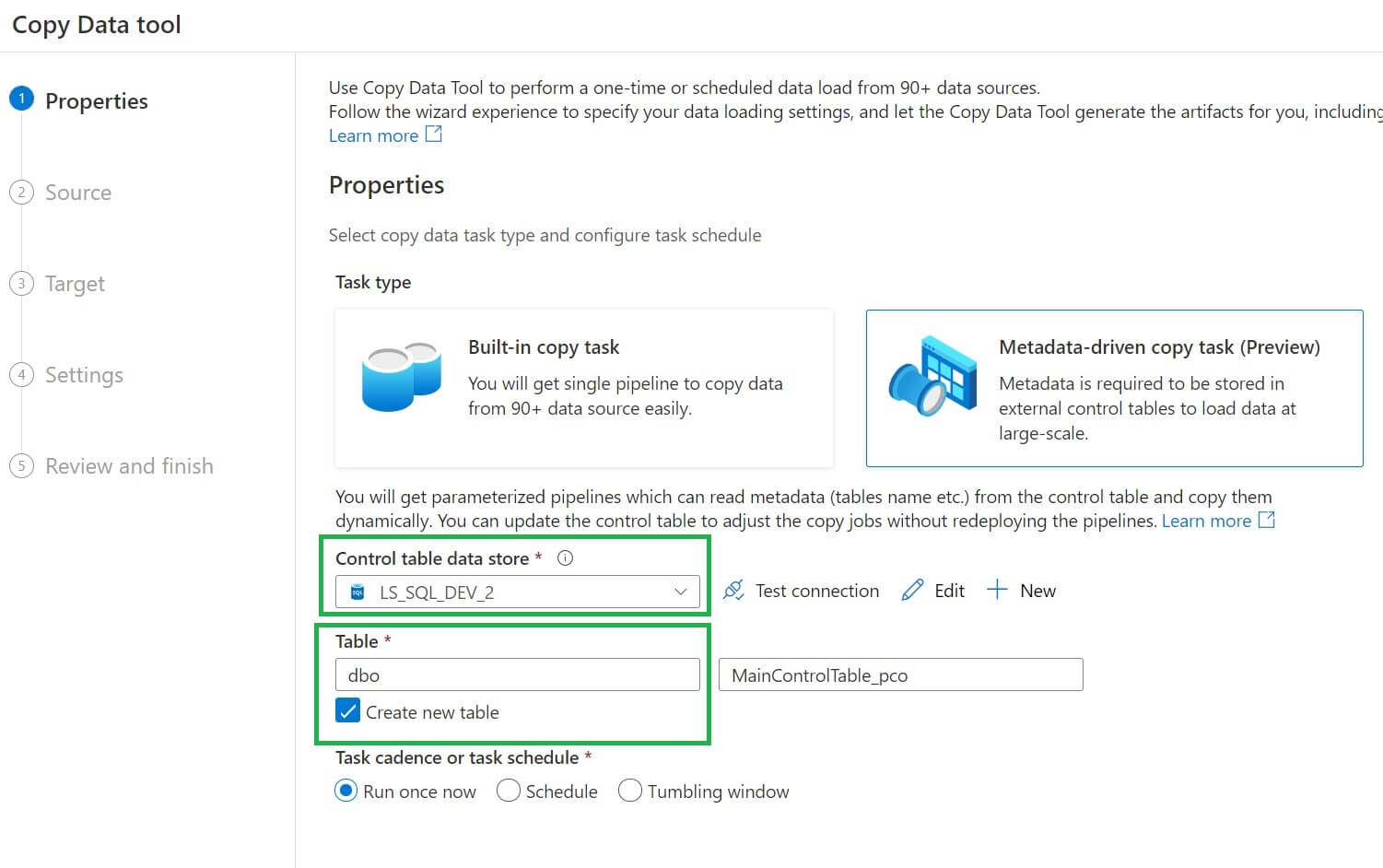
Now, we can view the properties page. Here I will provide the dataset and the control table name, which will be used to store the metadata information.
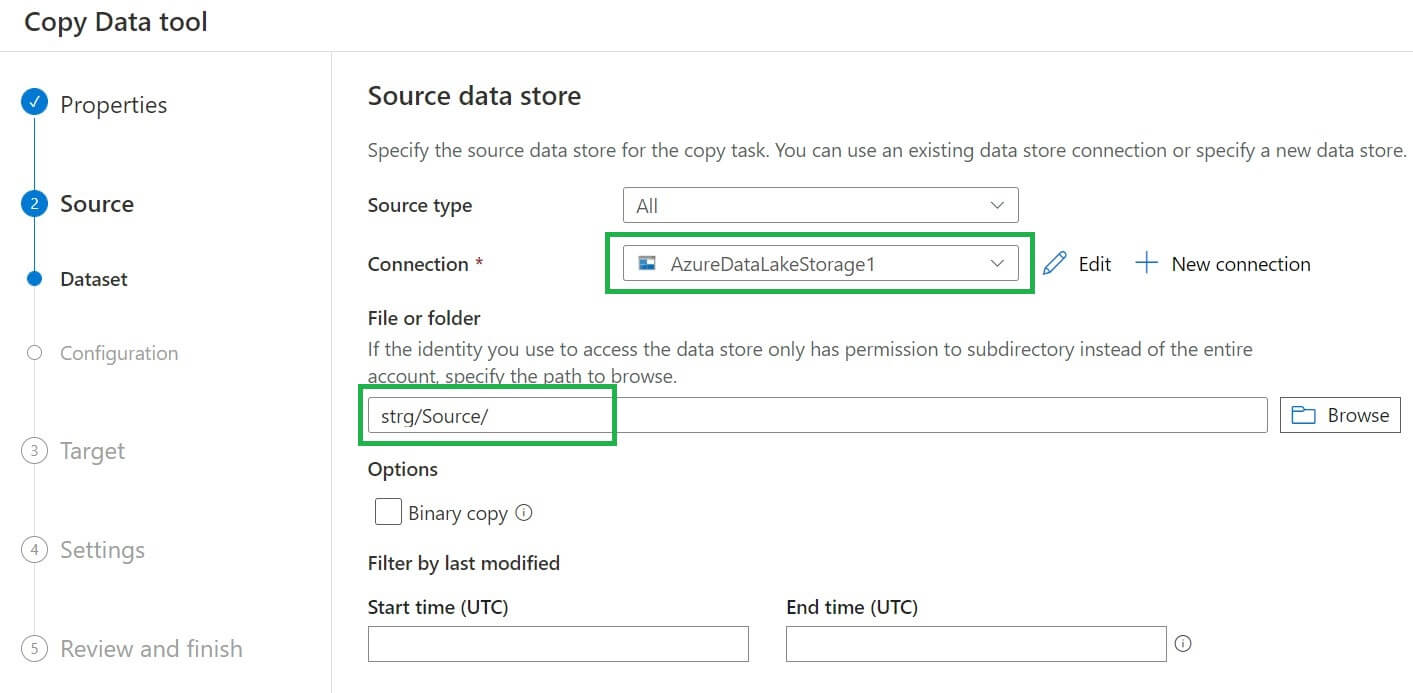
Now we are on the Source data store page. I added the data lake connections and the folder path:
Once the source connection set up, we have to set file format settings by clicking on the detect text format button. All required settings will be automatically populated. We can also preview the source data here:
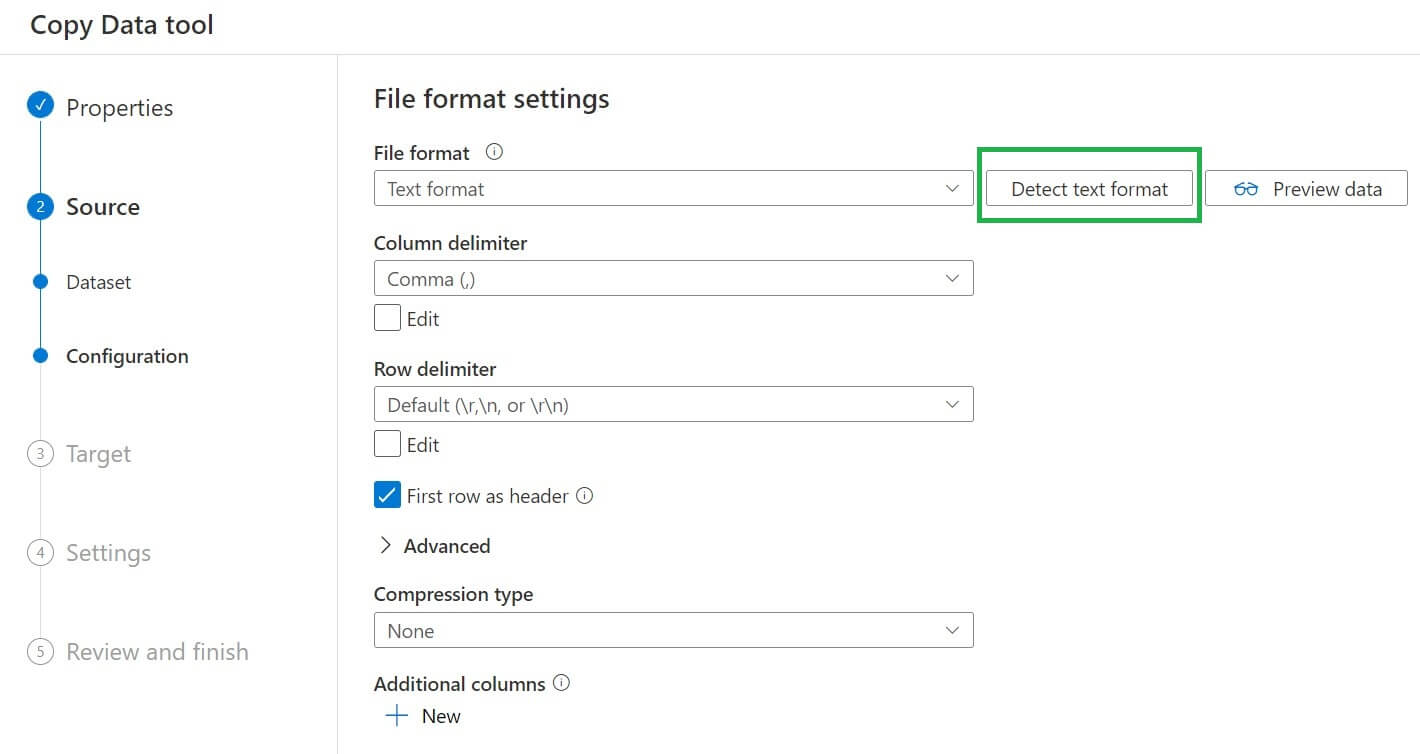
The target page looks like this image below:
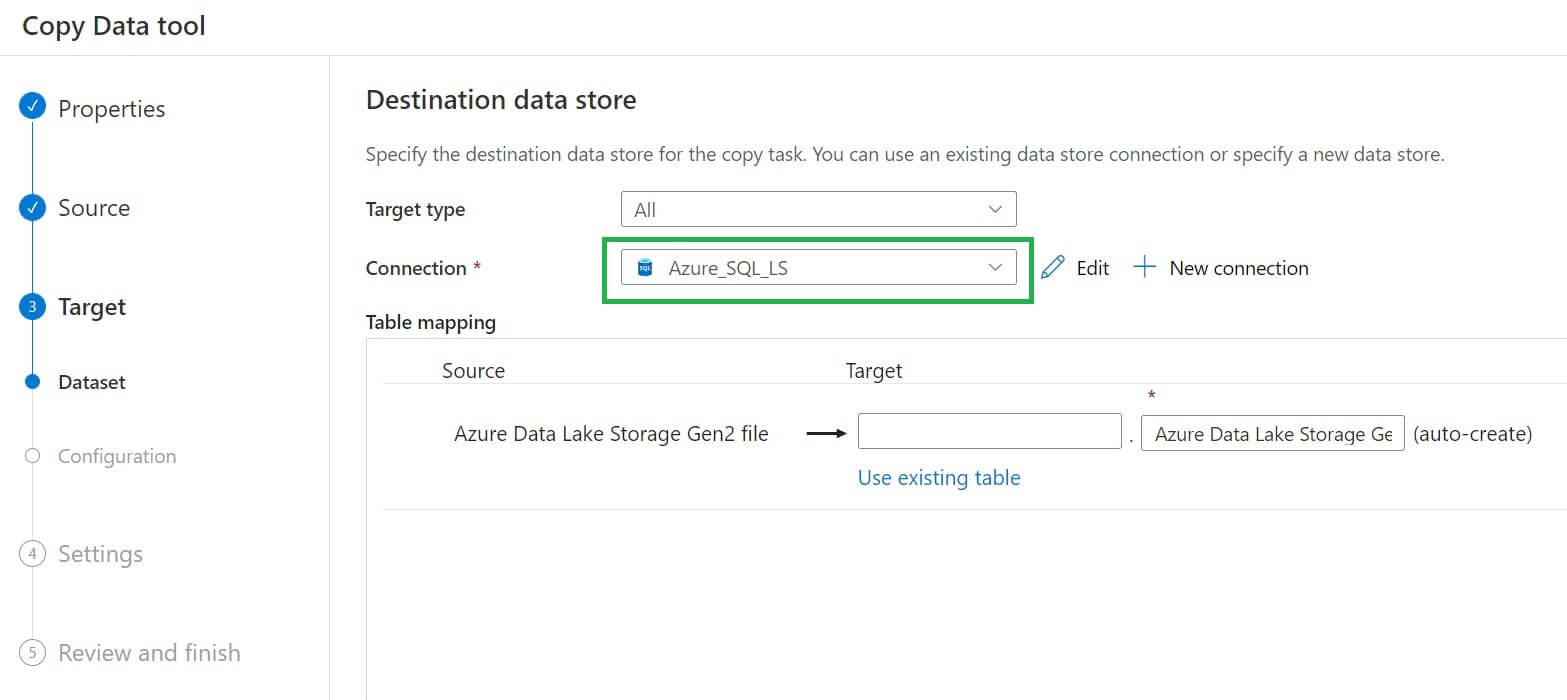
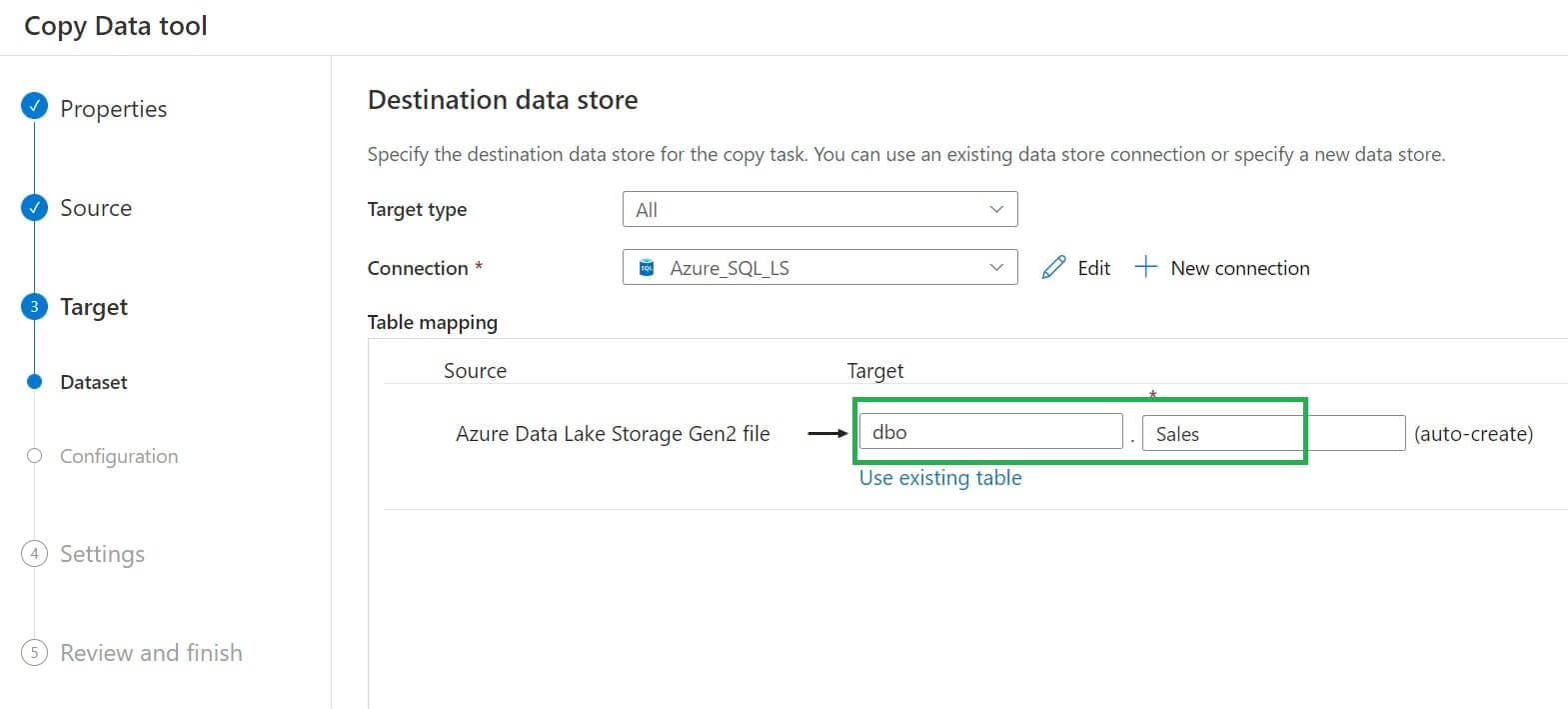
We have to provide the schema name and table name for the destination dataset, which will be auto-created. We can also use an existing table from the destination connection:
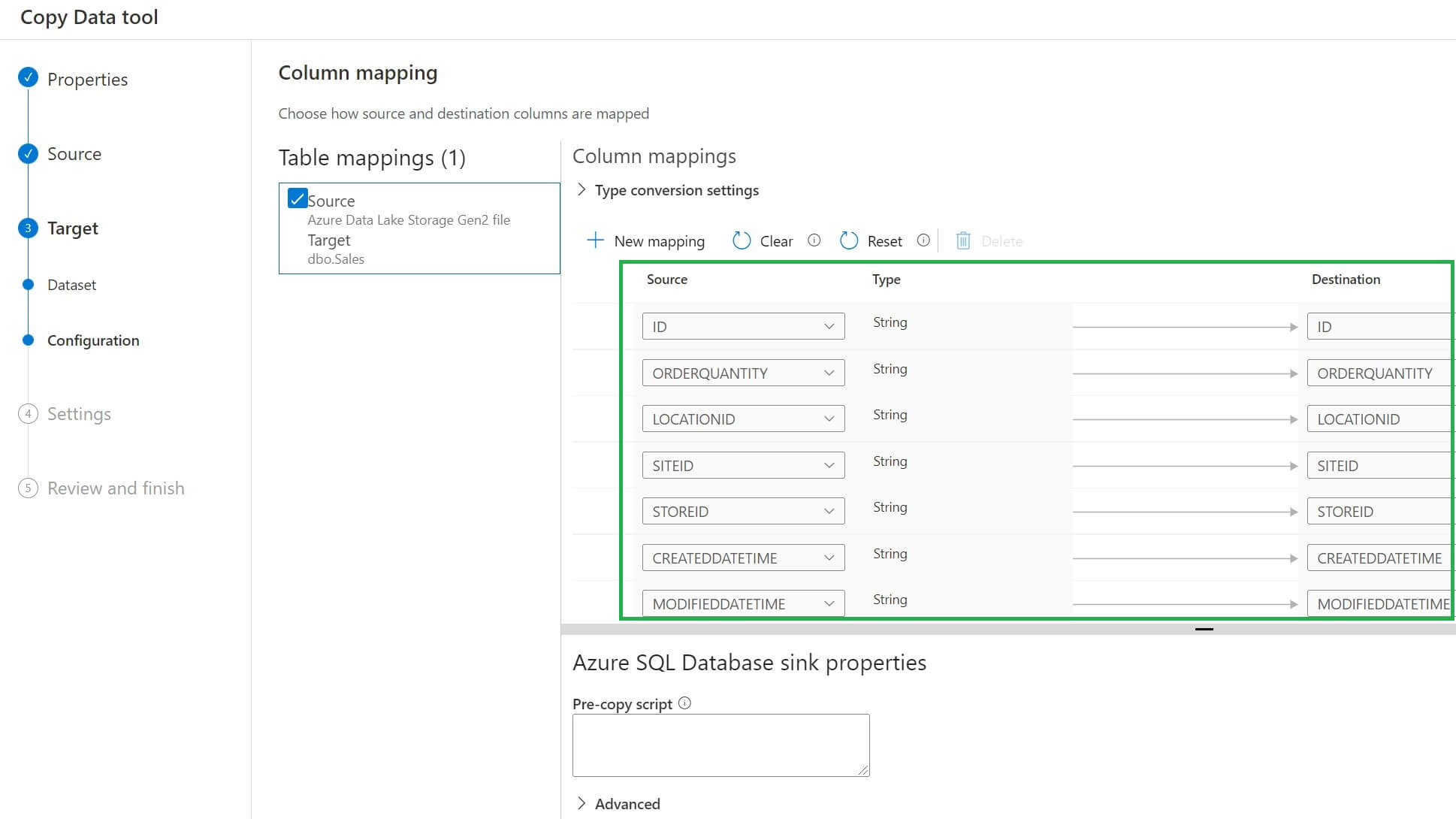
In the mapping page, all source and destination columns will be automatically mapped if they have the same name. If column names are different between source and destination, then we need to manually map the columns:
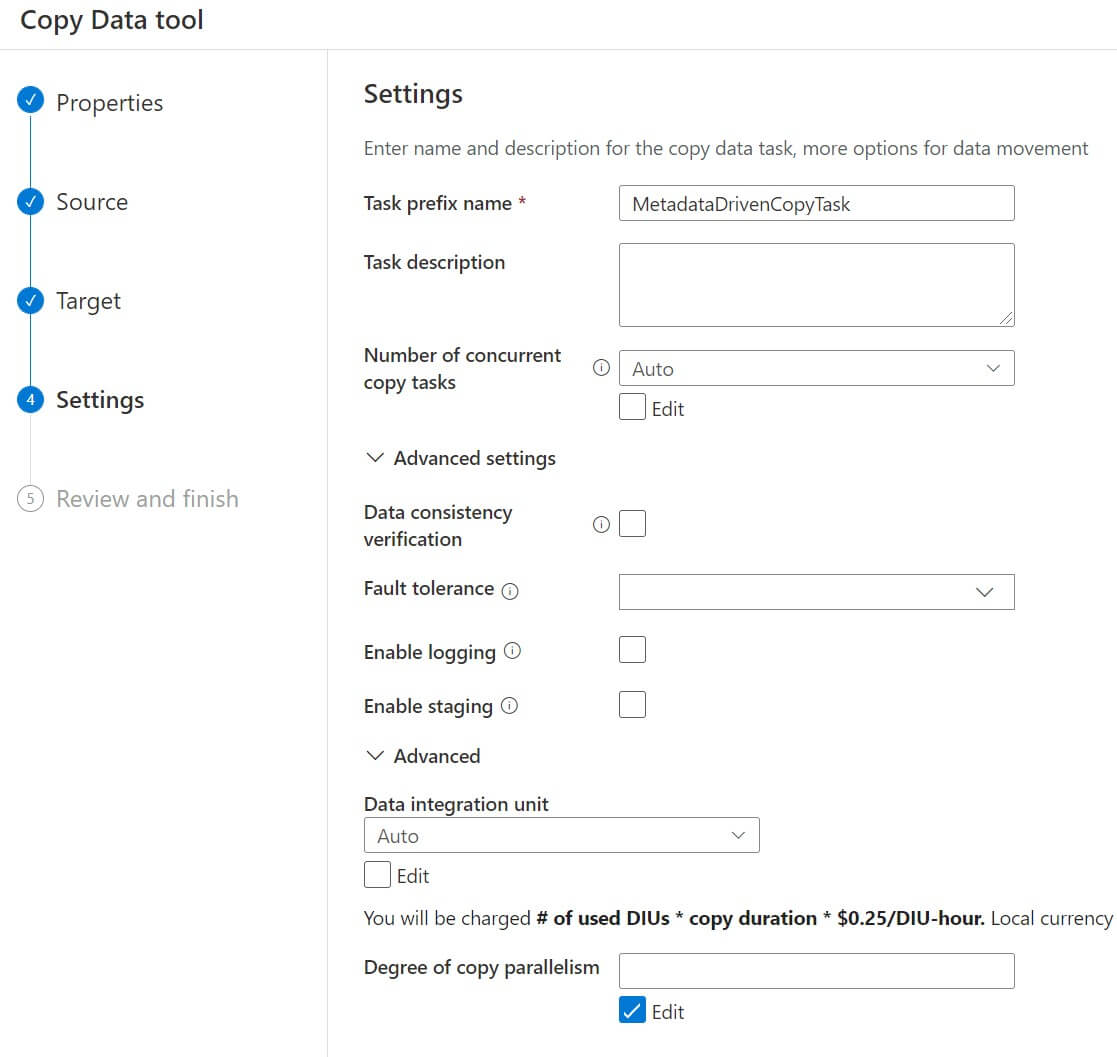
We can rename the copy data task if required. Optionally we can provide task descriptions and other settings options.
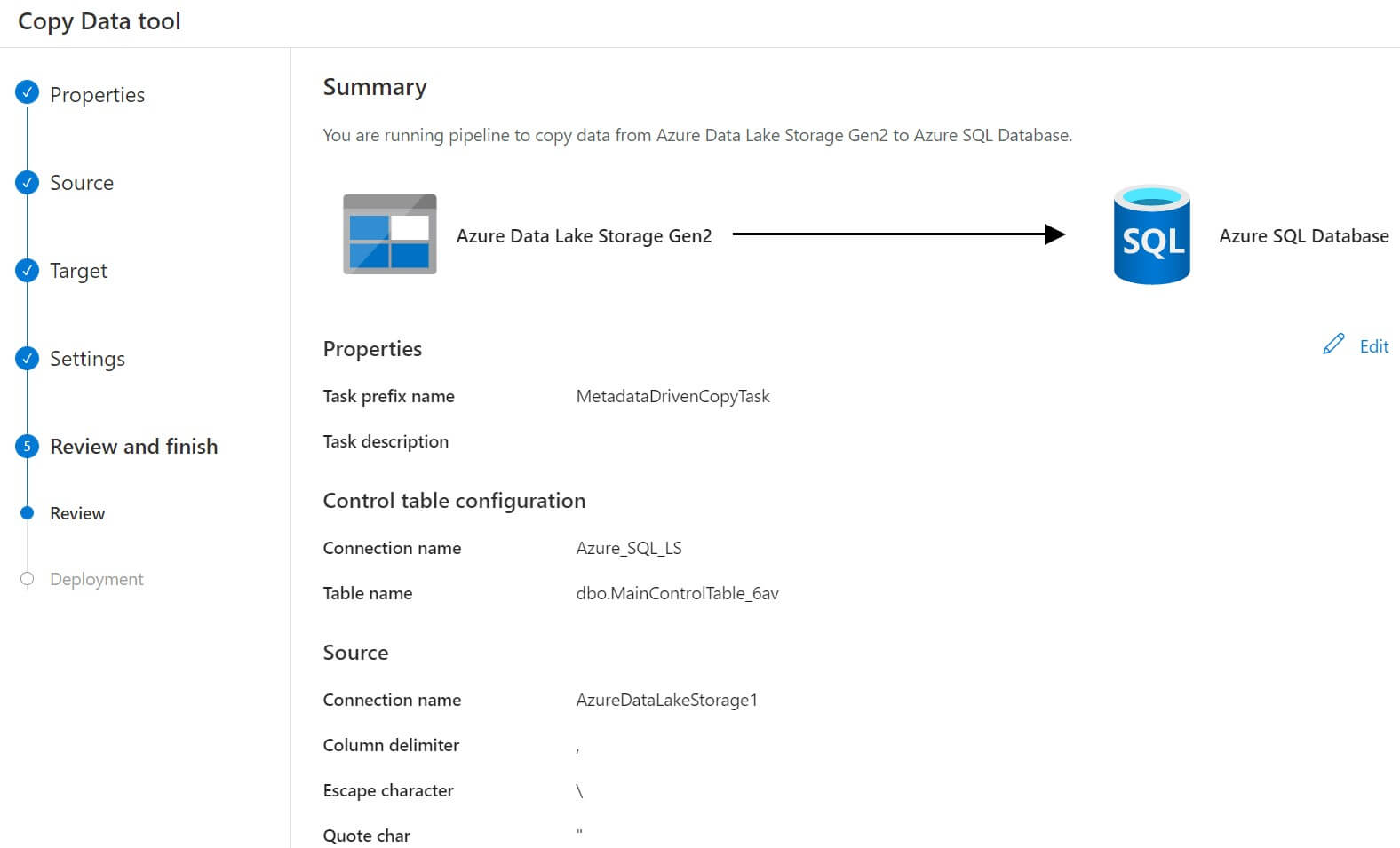
This is the summary page where we can review the source and destination configurations:
Now the deployment process is completed. The datasets and pipelines are created and the control table SQL script is generated. We will download the SQL script to execute it later. Let's click on finish.

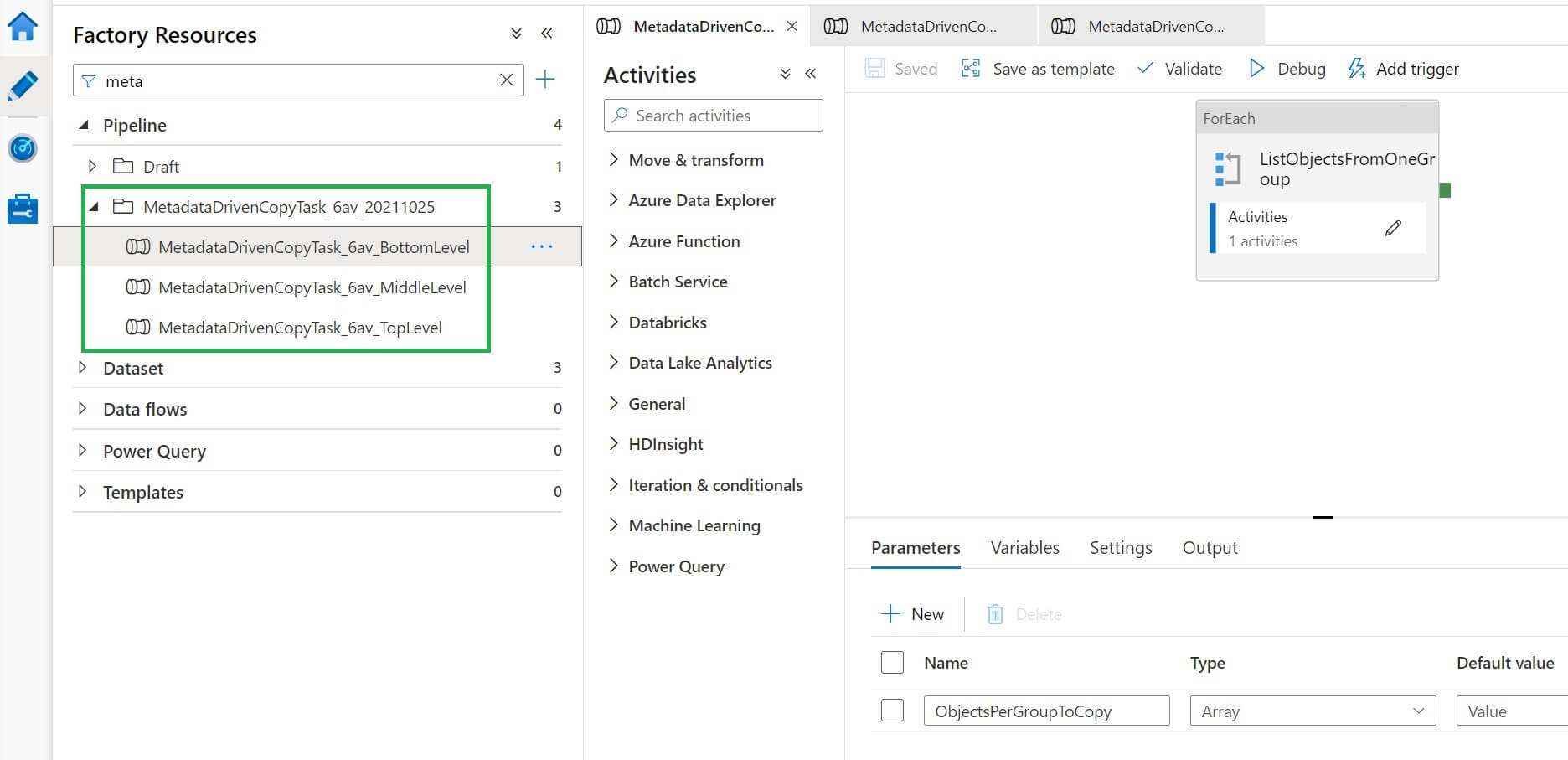
Now, three pipelines are created under the pipeline section. We can see them below:
We will copy the SQL script previously downloaded to SSMS, then execute the script. This will create the control table, where all the metadata will be stored.

Let's run the pipeline:
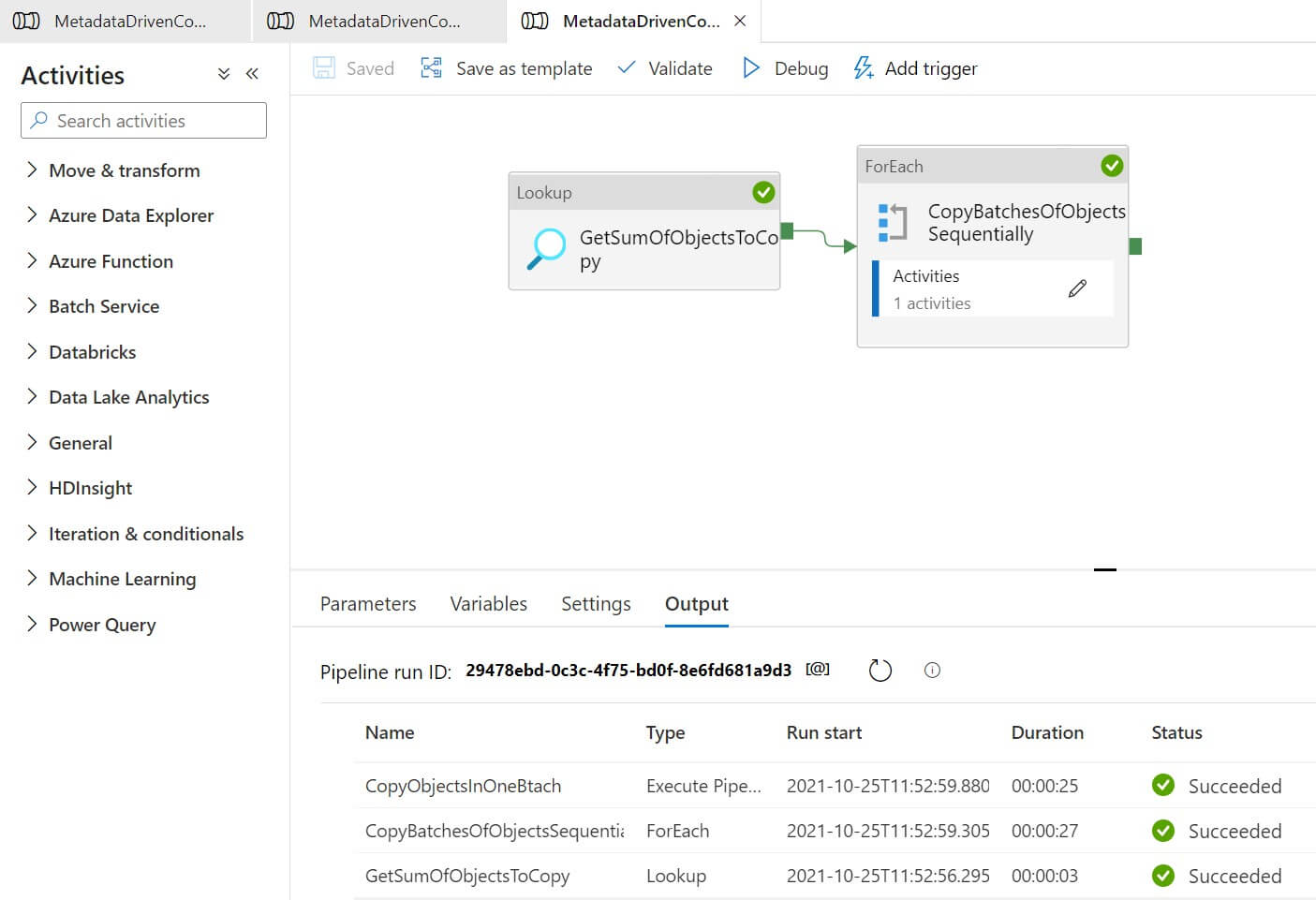
The destination table is created and data populated in the table:
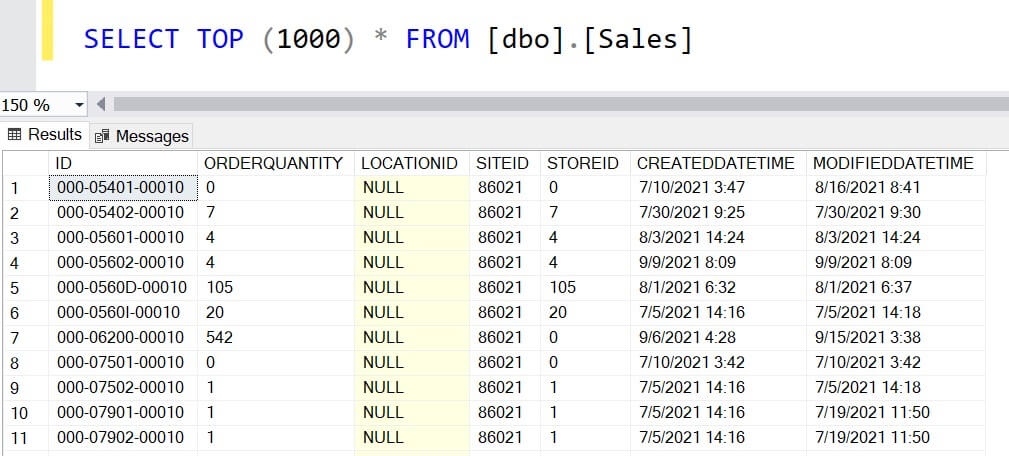
Now if we want to copy data from another object using this pipeline, we just need to add the objects to the control table. The pipeline will read the details of the object from the control table.
Limitations
There are a few limitations in meta-data driven pipeline developments:
- Currently, copy data tools for meta-data-driven pipeline does not support copying data incrementally from files. We can create our own custom pipeline to achieve that.
- IR name, database type, file format type cannot be parameterized in Azure Data Factory.
- The SQL script generated by the copy data tool for the control table uses OPENJSON. If we are using a SQL Server to create the control table, it must be SQL Server 2016 or higher versions that support the OPENJSON functions.
Conclusion
In this article, we discussed how to use metadata-driven copy tasks for creating a metadata-driven pipeline to copy a large number of objects easily.