

Introduction
I recently worked on a data pipeline project where I had to process JSON files and transform the data into CSV files. Azure Data Factory provides data flow formatters transformations to process the data in the pipeline. In this article, we will discuss Flatten, Parse, and Stringify transformation.
Flatten Transformation
The flatten transformation takes array values inside hierarchical structures such as JSON and converts them into individual rows.
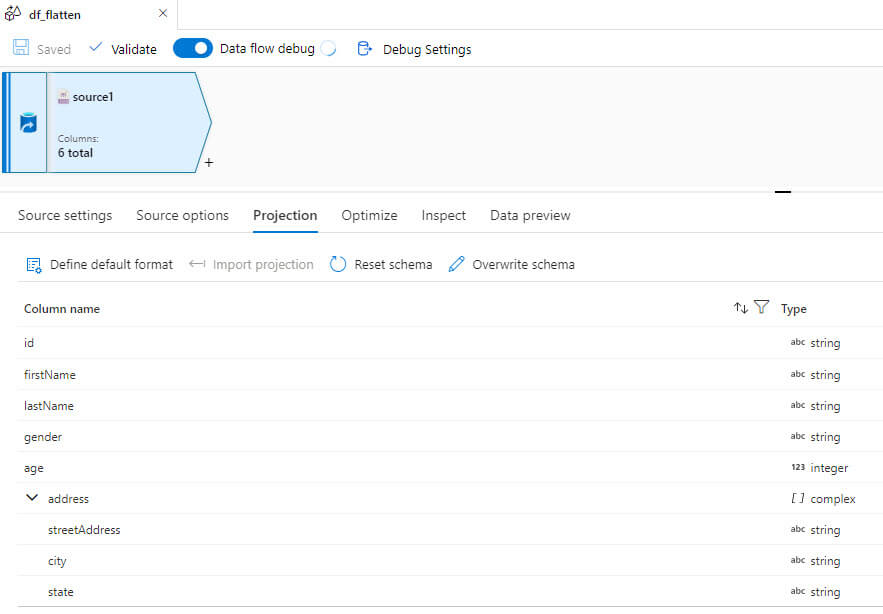
We will use the below JSON file in the pipeline.It contains columns id,firstname,lastname,gender,age,address complex type which has streetAddress,city and state.

The JSON file is available in the data lake folder:
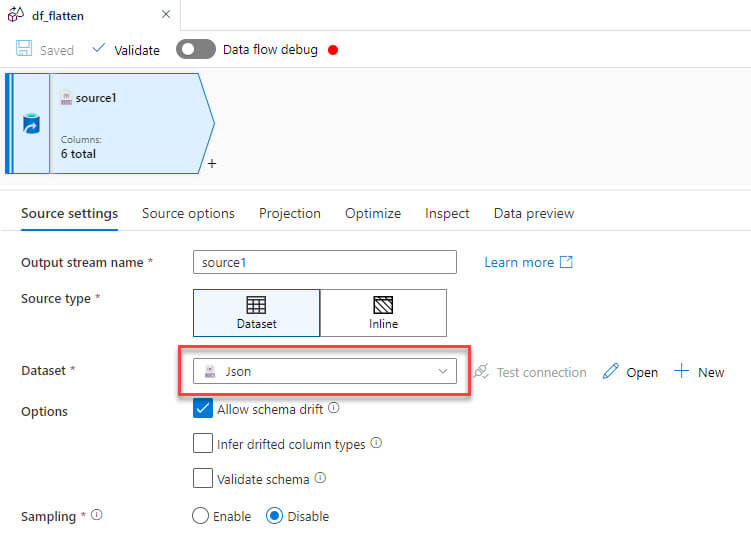
Now I created new dataflow in the Azure Data Factory and added a new JSON source to the file:
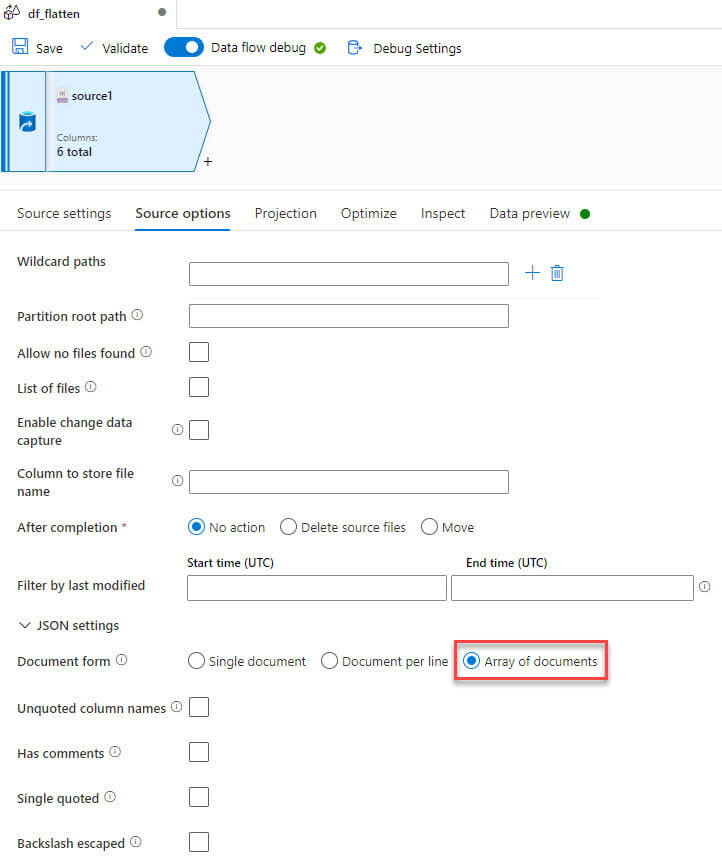
In the source option, under JSON settings, selected Array of documents as the JSON contains array type for address field:
Select the projection to view the available column names and datatype:
You can also preview the source data:
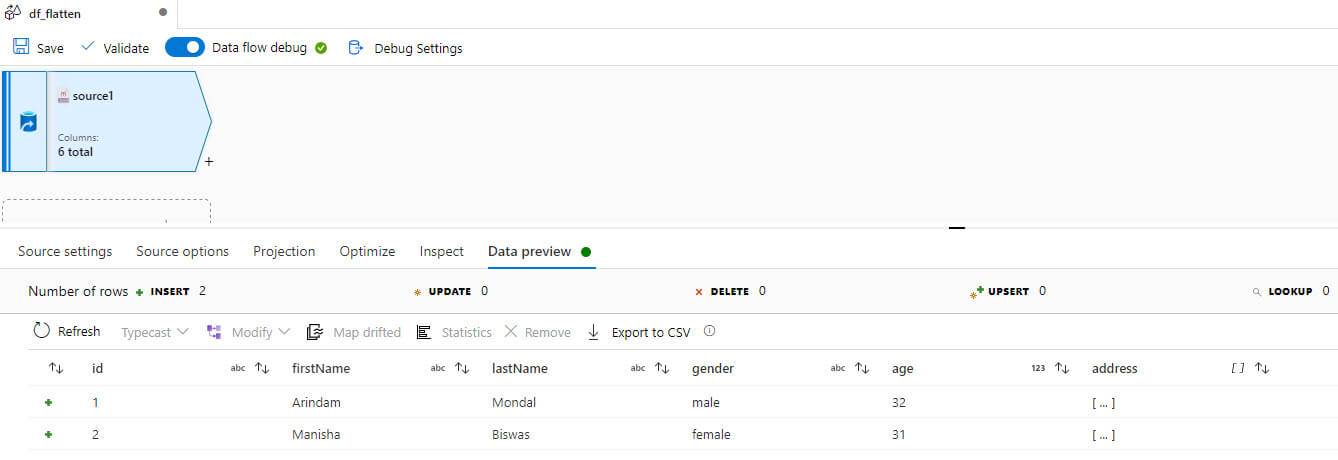
Now added a flatten transformation, selected address in the Unroll by section:
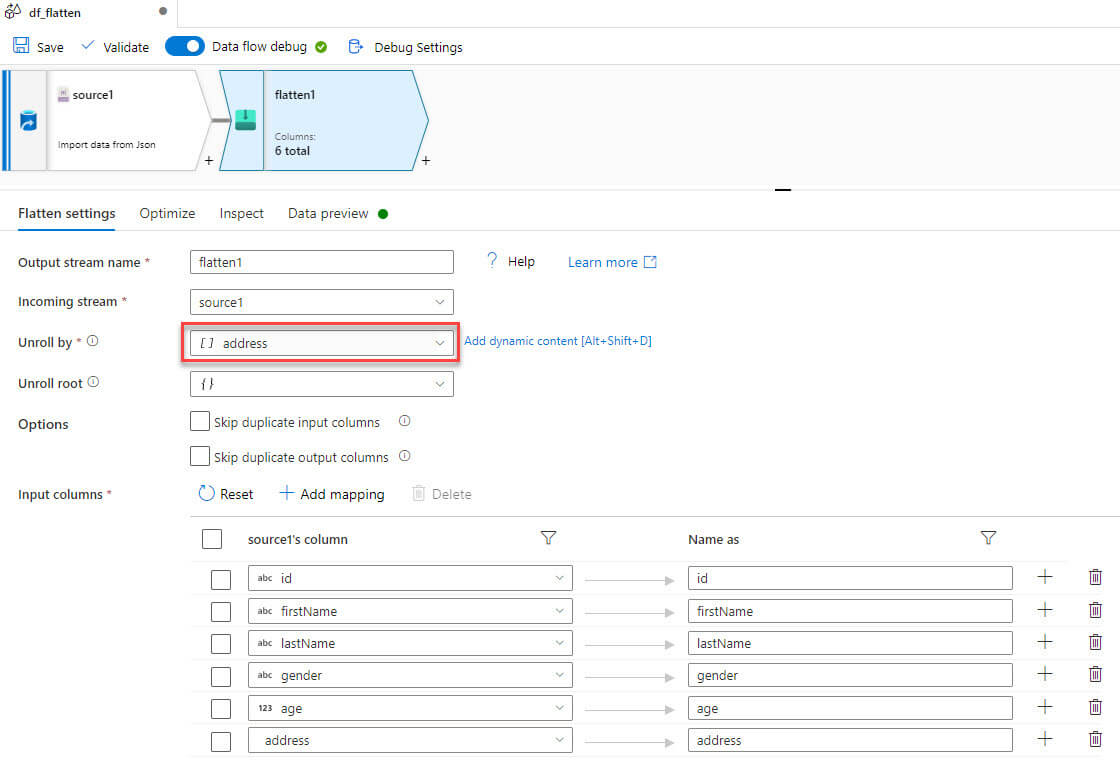
Click on reset schema to add the address columns, which are streetAddress , city, and state:
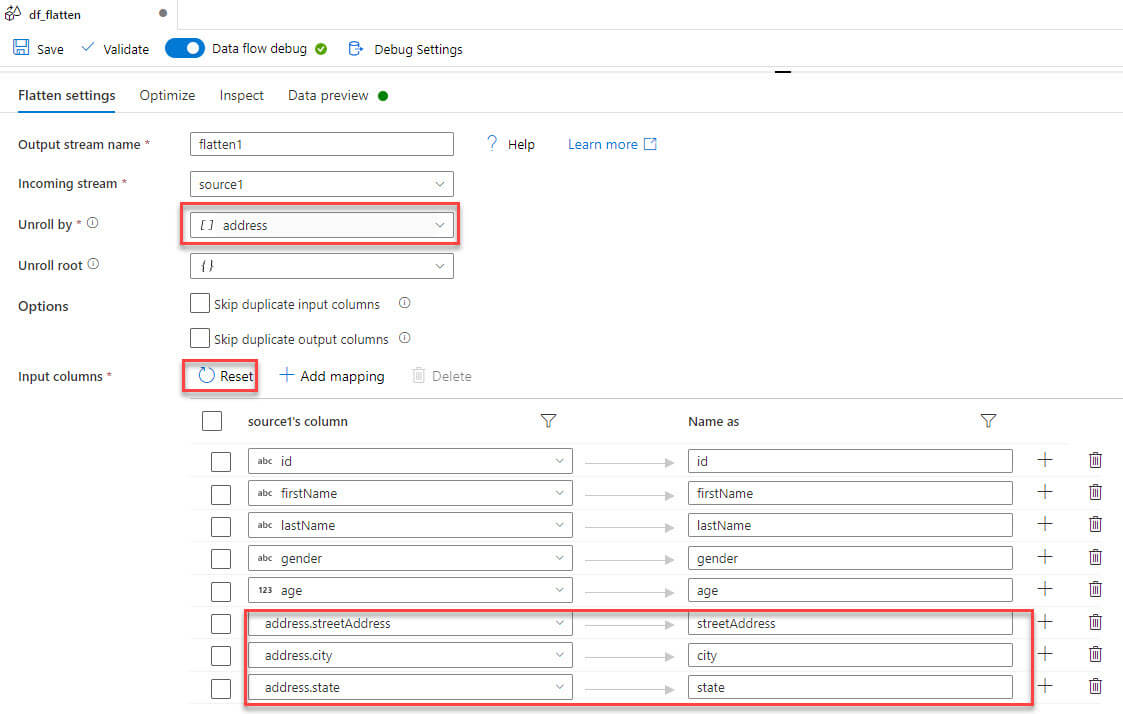
Preview the data in flatten transformation, note that now the streetaddress, city, and state columns are available:

Now added a sink to generate the CSV file in the data lake folder:

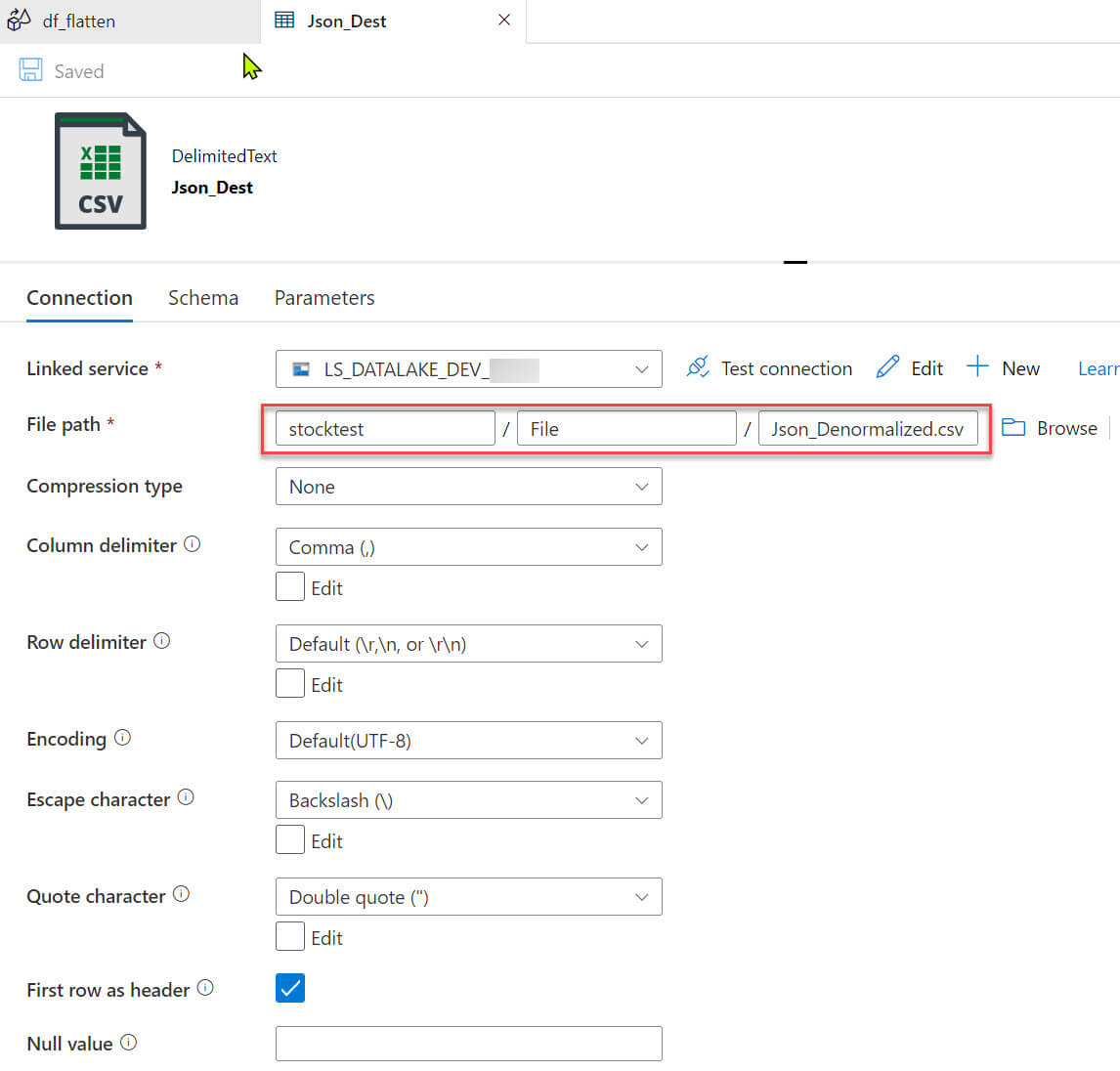
In the sink settings, provided the data lake folder path:
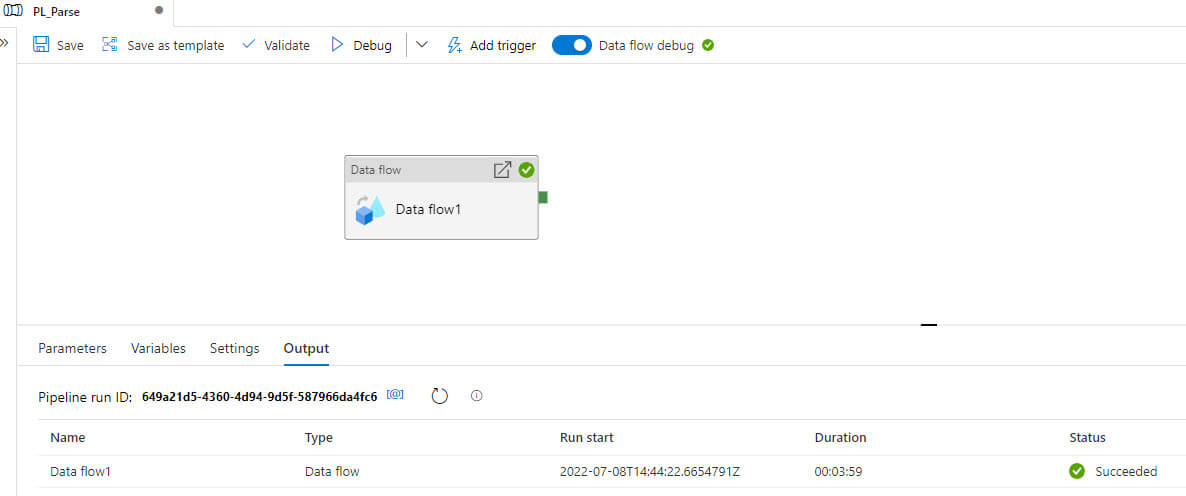
Let's run the pipeline:

The output file is generated now and along with other columns (Id, FirstName, LastName, Gender, and Age), the complex columns, StreetAdress, City, and State, are also available :

Parse
You can parse text data using Parse transformations. Currently, JSON, XML, and delimited text types of embedded documents are supported for Parse transformation.
I used below sample data for the demo. The excel data contains Car_Id,Model,Colour and json_value columns.We will extract locationid and region from the JSON value using Parse transformation:

The file is available in the data lake folder:
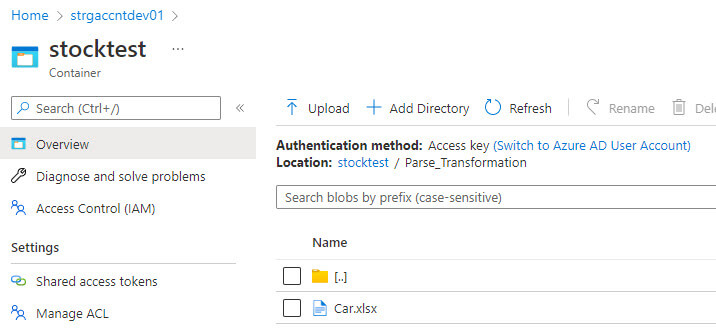
I added a new data flow in the Azure Data Factory and created an excel source data set.
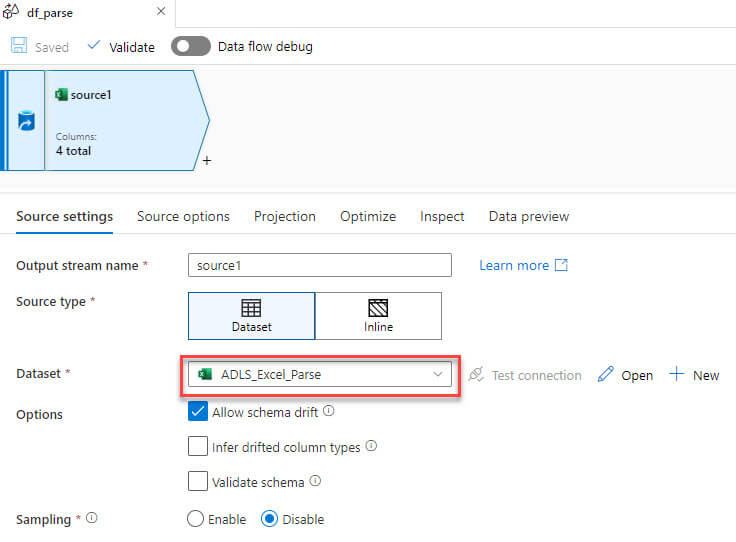
The excel source file path specified to the data lake folder:
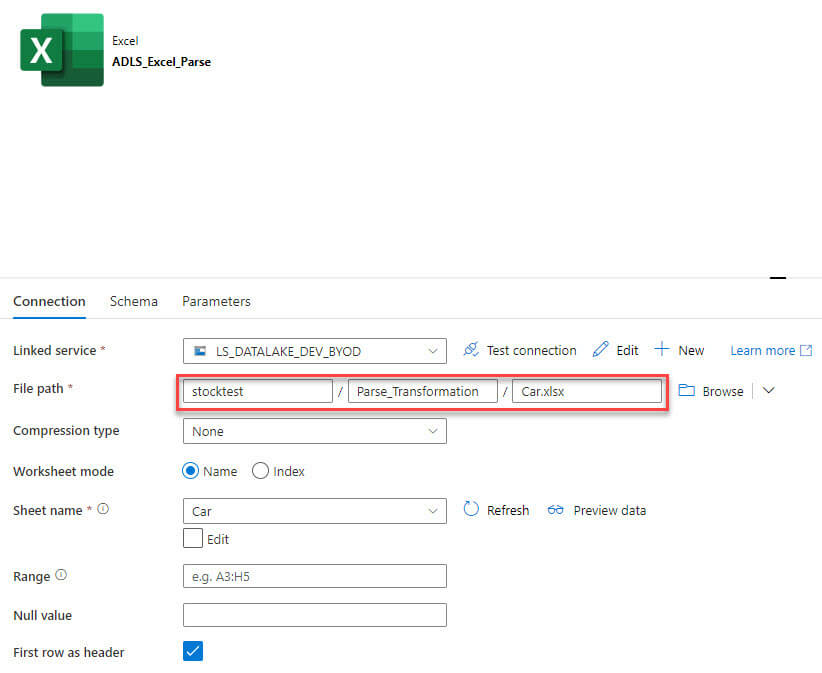
Now, added the parse transformation, selected JSON in the format and added a new column for locationid and region:
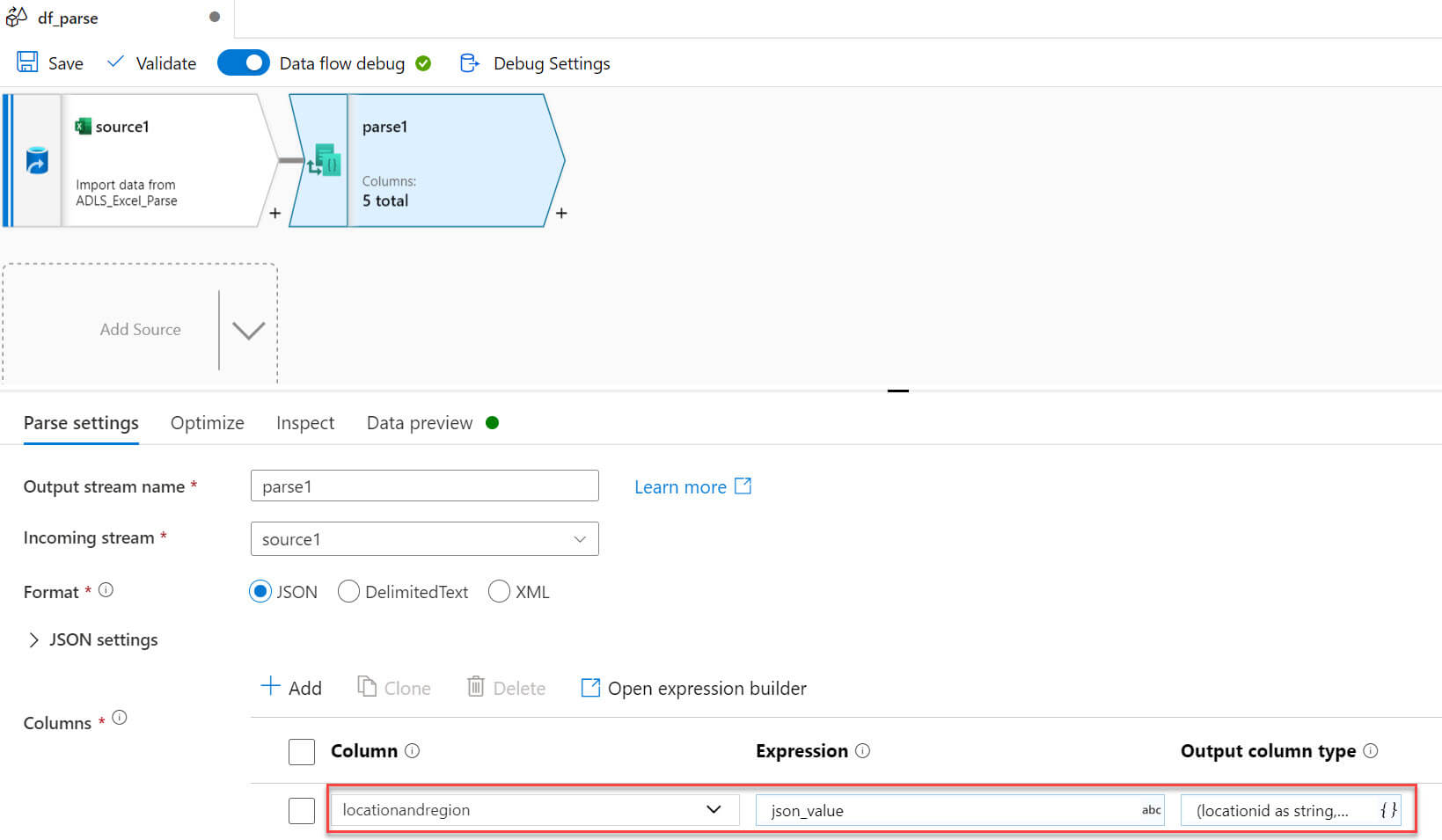
In the Visual expression builder, I selected locationid and region columns and convert both of the columns to string values:

Added a sink to generate the output to a CSV file:

Let's run the pipeline:
Now the output file is available. It has the Car_Id, Model, Colour columns, and the added Locationid and Region columns from the JSON value:

Stringify
If you have a complex data type in the source, use stringify to transform it into a string data type:
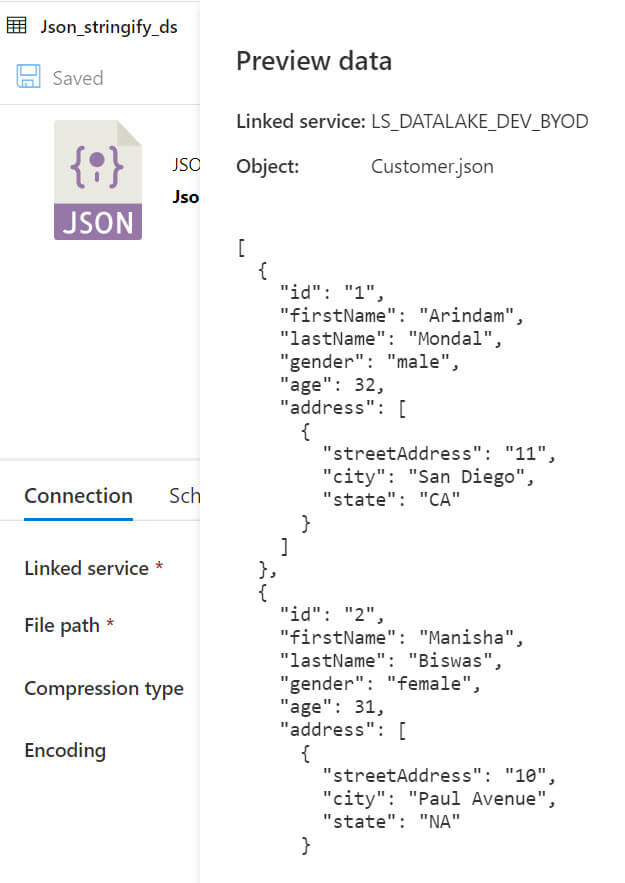
We will use a sample JSON data as below, it contains complex data in the address field:

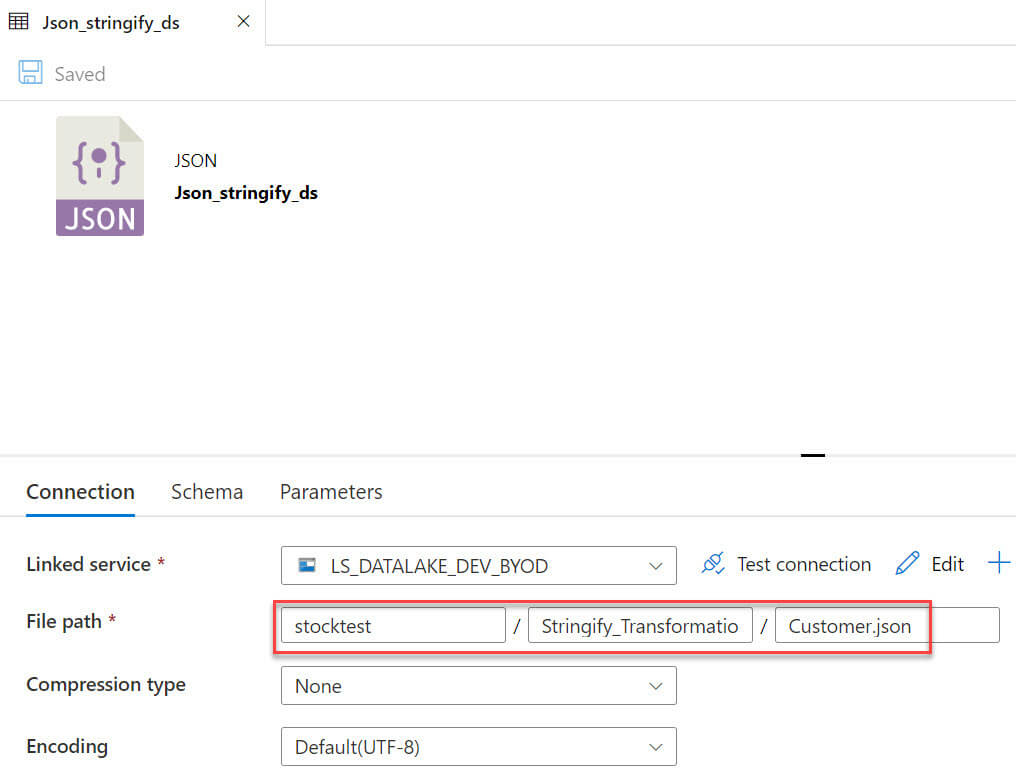
Let's add new dataflow to the azure data factory and then add a new JSON source:
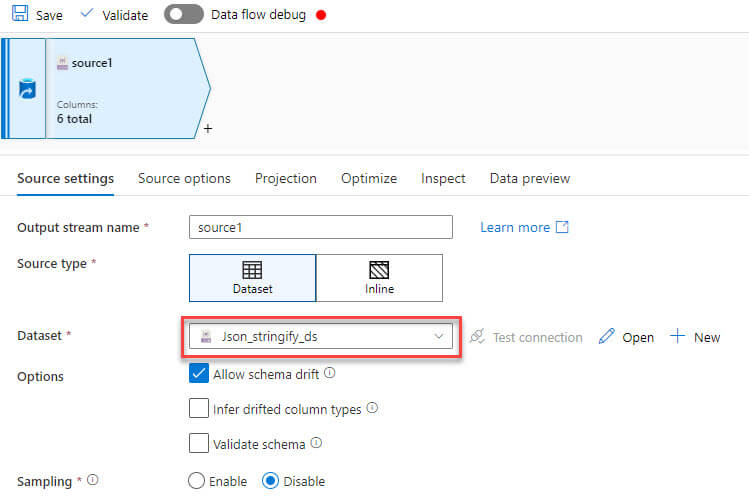
The JSON source file path specified to the data lake folder:
We can preview the JSON data:
Now, added the stringify transformation, in the columns option added address field:
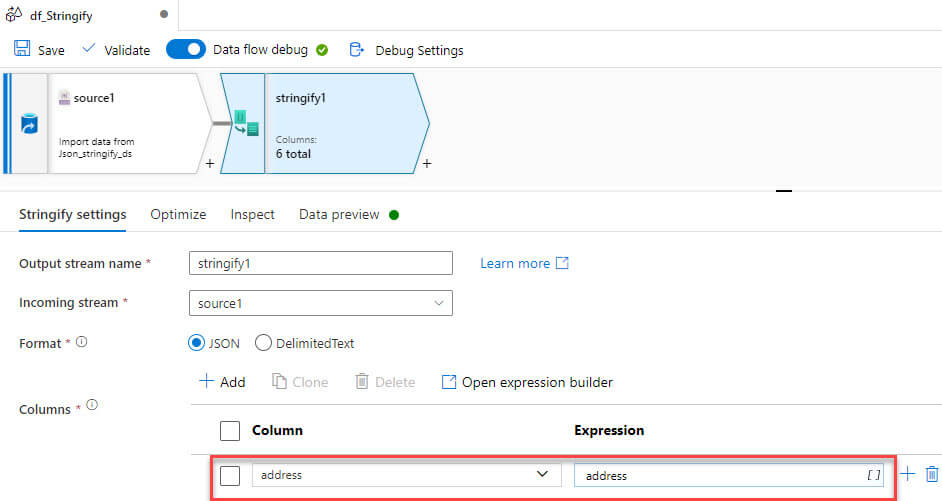
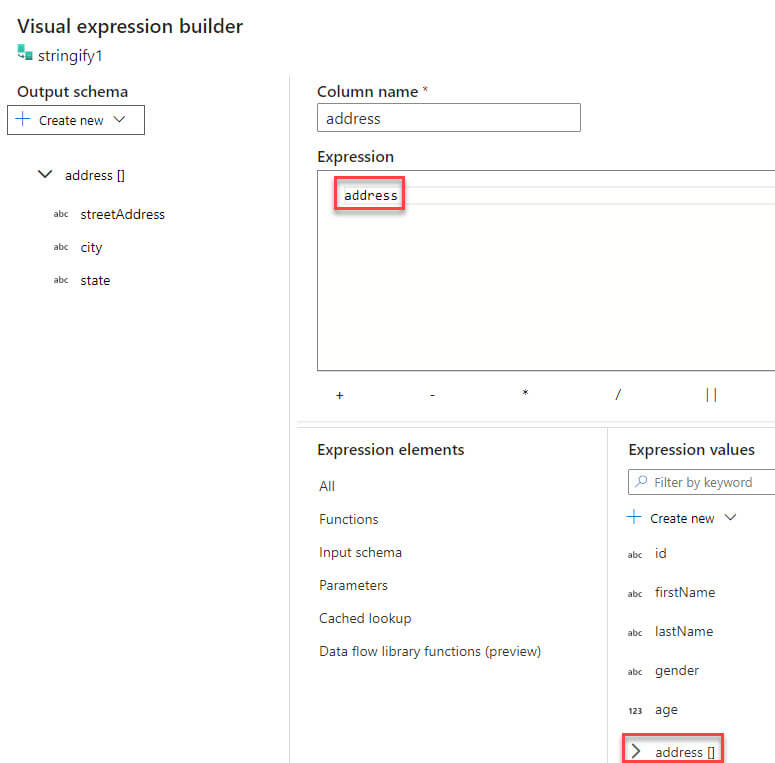
We need to select a complex field in the expression builder:
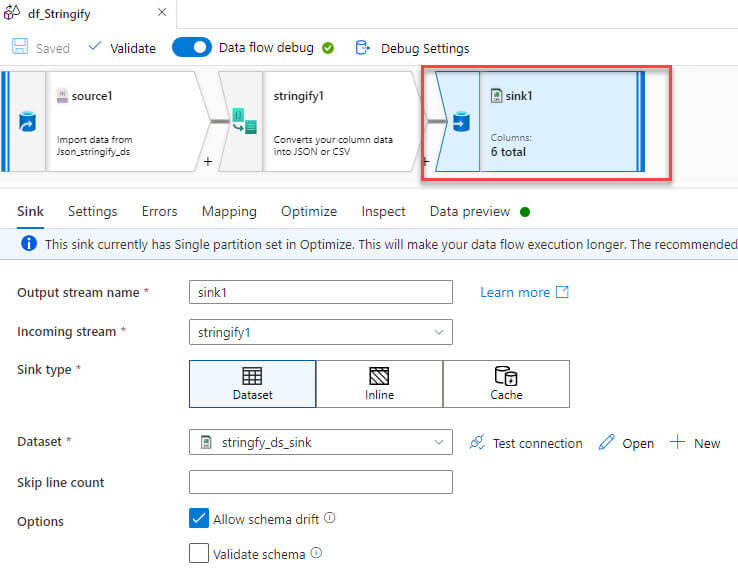
Now added a sink to generate the output data in a CSV file:
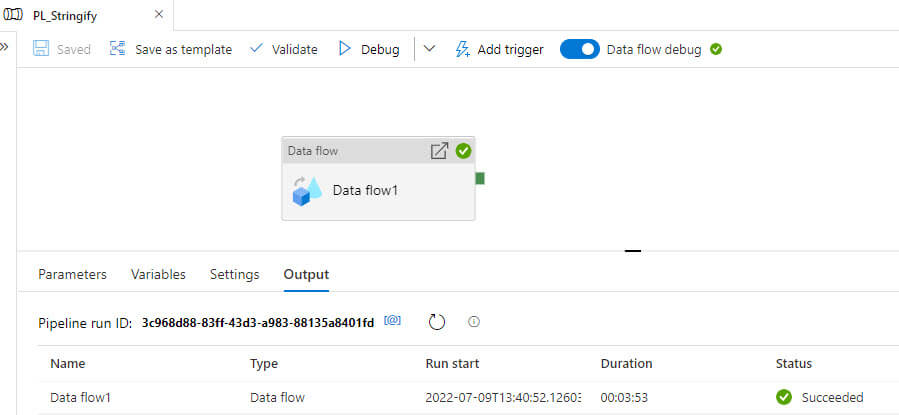
Let's run the pipeline:
The output file is generated now and the address column is converted from complex JSON to string value:

Conclusion
In this article, we discussed data flow formatters Flatten, Parse, and Stringify. These transformations are useful if you want to transform your string data in the pipeline.