

One customer had a very specific scenario:
- They had an Always On Availability Group with Windows Server Failover Cluster
- Each node had its own storage, so the witness was not disk-based but network-based
- One node was in the cloud and the other was a physical server
- The network was unstable, confirmed by a monitoring agent which detected the disconnections, even when the provider assured there were no issues
- Some network blips caused the cluster to enter the resolving state, with its associated downtime, until the connectivity was restored between both nodes
- One time, those issues caused the OS to get corrupted, when in one node the cluster service could no longer start, and the other node was unable to remove that one because the cluster was unhealthy
So, they want an availability group which doesn’t rely on the network or the cluster service. They don’t want automatic failovers because the network blips are too short and don’t deserve the downtime. Also, they won’t lose transactions on failover; the IT department can retry all operations that fail and fix records manually when needed. And they want the ability to do maintenance and migrations easily, with as little manual intervention as possible.
This was a perfect case for a distributed clusterless availability group, but there isn’t any documentation regarding that: all documentation indicates it requires the cluster service, otherwise it isn’t supported.
Here are the advantages of clusterless availability groups:
- Reduced complexity: you don’t need to share resources between the instances and don’t need to install additional features, so there are a few possible points of failure.
- No dependency on the network: the cluster technology relies heavily on the network, and when it’s unstable or not 100% reliable, it causes downtimes.
- Less dependencies: because you don’t have to share resources or install additional features, you can go straight to setup and use without special configurations or requirements.
- Less prone to errors: because there are no other components that can fail, there will be less downtimes, and troubleshooting will be more straightforward.
- Less overhead: the cluster technology consumes resources (CPU and network) checking for quorum, heartbeat, node status, resource availability, communication, and synchronization.
- No need for shared storage: so, it works in heterogeneous environments, and you don’t need to spend additional money to set it up.
Also, here are the advantages of distributed availability groups:
- Independence: different physical sites, different OS, different SQL Server versions, different domains, and different cloud providers allow for a more robust disaster recovery solution.
- Automatic seeding: simplifies the initial data synchronization; no need for manual backup and restore.
- Geographic distribution: allow different data centers in different geographic locations.
- Allow poor network bandwidth: network traffic is reduced and simplified.
- Simplified migration: to new hardware, OS, SQL Server version, etc.
But note, as in everything, there are disadvantages you must be aware of:
- Not a high availability solution: there is no checking of the system’s health, so the copies are not synchronous, and it’s not recommended for critical systems or when the transactions cannot be retried.
- This configuration is not supported by Microsoft, and you will certainly notice some errors; however, we expect future updates will make this fully supported because it works.
- Contained availability groups don't work in the secondary datacenter (but will do in SQL Server 2025 using the clause AUTOSEEDING_SYSTEM_DATABASES). The primary datacenter can be a contained availability group, but those master/msdb databases won't synchronize with the secondary datacenter.
For this, I created two read-scale availability groups by following the instructions from Edwin Sarmiento at the following link: https://www.mssqltips.com/sqlservertip/6905/sql-server-read-scale-always-on-availability-groups/
I created the following setup:
Avail. Group SQLPRODAG SQLPREMAG Primary CLOUD1 ONPREMISE1 Secondary CLOUDDR2 ONPREMISEDR2
Then, I created the listener according to his instructions in the following link: https://www.mssqltips.com/sqlservertip/6925/read-scale-always-on-availability-group-to-offloading-reporting/
Note, however, that for the read-only routing list you only need to add the secondary node; that means, for node CLOUD1, the read-only routing list is only CLOUDDR2 and vice versa, not both nodes.
Now I have the following setup:
Avail. Group SQLPRODAG SQLPREMAG Primary CLOUD1 ONPREMISE1 Secondary CLOUDDR2 ONPREMISEDR2 Listener SQLPROD SQLPREM
And finally, let’s use another of his tips as basis, but there are several differences: https://www.mssqltips.com/sqlservertip/6987/distributed-availability-groups-for-sql-server-disaster-recovery/
First, let’s make sure SQLPREMAG contains only one node, so remove ONPREMISEDR2 from it. On the node OPREMISEDR2, remove all remaining Availability Group objects. Also, remove the database used in the initial setup from ONPREMISE1, leaving no databases at all.
Now, in the primary node of SQLPROD, let’s create the distributed availability group:
CREATE AVAILABILITY GROUP [DIST_SQLPROD] WITH (DISTRIBUTED) AVAILABILITY GROUP ON 'SQLPRODAG' WITH ( LISTENER_URL = 'TCP://SQLPROD.testdomain.com:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC), 'SQLPREMAG' WITH ( LISTENER_URL = 'TCP://SQLPREM.testdomain.com:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC);
And in the primary node of SQLPREM, let’s join the distributed availability group:
ALTER AVAILABILITY GROUP [DIST_SQLPROD] JOIN AVAILABILITY GROUP ON 'SQLPRODAG' WITH ( LISTENER_URL = 'TCP://SQLPROD.testdomain.com:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC), 'SQLPREMAG' WITH ( LISTENER_URL = 'TCP://SQLPREM.testdomain.com:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC);
Once done, you will see the distributed availability group in SQLPROD:
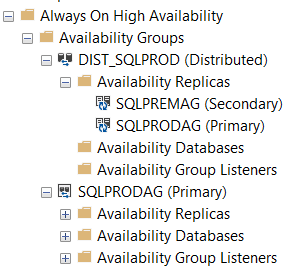
And in SQLPREM:
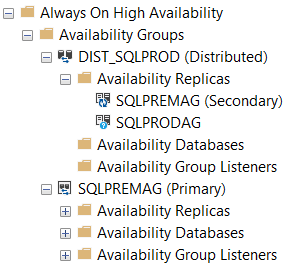
You will notice the databases start to synchronize in SQLPREM. However, after the synchronization finishes, the distributed availability group will still show as unhealthy:
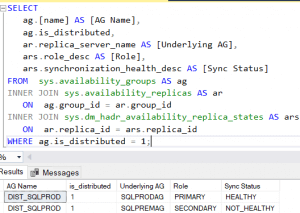
So, here are some things you need to be aware of:
- The time to synchronize will be a lot more. Adding one node to SQLPROD lasted only a couple hours to synchronize 2 TB of data, but adding SQLPREM lasted around 10 hours.
- If you don’t remove all databases from the secondary DC, it won’t allow you to create the distributed availability group.
- If you don’t remove the secondary node from SQLPREM, it will cause several synchronization errors and most likely won’t succeed in 12 hours.
- If the synchronization takes longer than 12 hours, it is not going to synchronize the remaining databases, which means this won’t be suitable for your environment.
- In the primary node of the primary DC you will still see the error: Failed to update Replica status due to exception 35222.
Even though, the databases are being replicated to the secondary DC.
Now you can add back the secondary node (and any other node) to the SQLPREMAG availability group running this command in ONPREMISE1, without needing additional bandwidth because everything is seeded from this primary node:
ALTER AVAILABILITY GROUP [SQLPREMAG] ADD REPLICA ON 'ONPREMISEDR2' WITH ( ENDPOINT_URL = 'TCP://ONPREMISEDR2.testdomain.com:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)); ALTER AVAILABILITY GROUP [SQLPREMAG] MODIFY REPLICA ON N'ONPREMISE1' WITH (SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL));
After this, still in the primary node ONPREMISE1, expand the "Availability Replicas", select "ONPREMISEDR2", right click it, select "Join to Availability Group", connect to the server, and click "OK".
Finally, in the secondary node "ONPREMISEDR2" run this command:
ALTER AVAILABILITY GROUP [SQLPREMAG] GRANT CREATE ANY DATABASE;
And with this setup, you can test failover between instances and between datacenters.

