

The Feature
As of SQL Server 2012, using local disks for TEMPDB on a failover cluster is a fully supported feature. In the light of fast storage solutions (SSD / NVME) directly plugged into the mainboard of a system, this is a big step forward because before that there was no way of providing storage to cluster (SAN) storage that is anywhere near as fast as local storage.
The Problem
There is a caveat: that local disk turns into a non-clustered resource on which your SQL installation depends and the cluster service has no way of knowing the health state of your local disk. If your TEMPDB local disk fails, the SQL Server instance does not shutdown, which makes it practically inoperable complaining TEMPDB’s log is not found, and no failover is initiated!
Yes! We were as astounded as you probably are now. Being the curious nerdy types we are, we decided to find the underlying cause of this as we both were sure this is not the way SQL should behave.
What We Expected
SQL Server shutting down because of local disk failure is not an issue since we are using a failover cluster. The instance fails over and comes up on the other node where there is another local disk without problems.
Furthermore, you expect SQL server to initiate a failover in a cluster configuration if TEMPDB can no longer function due to a disk error, regardless of where that TEMPDB is located. RAID 0 configurations or even a single local disk on a blade (preferably SSD) offers good TEMPDB performance but is inadvisable in this scenario in the light that SQL server does not detect TEMPDB’s absence as a critical failure.
The Failure
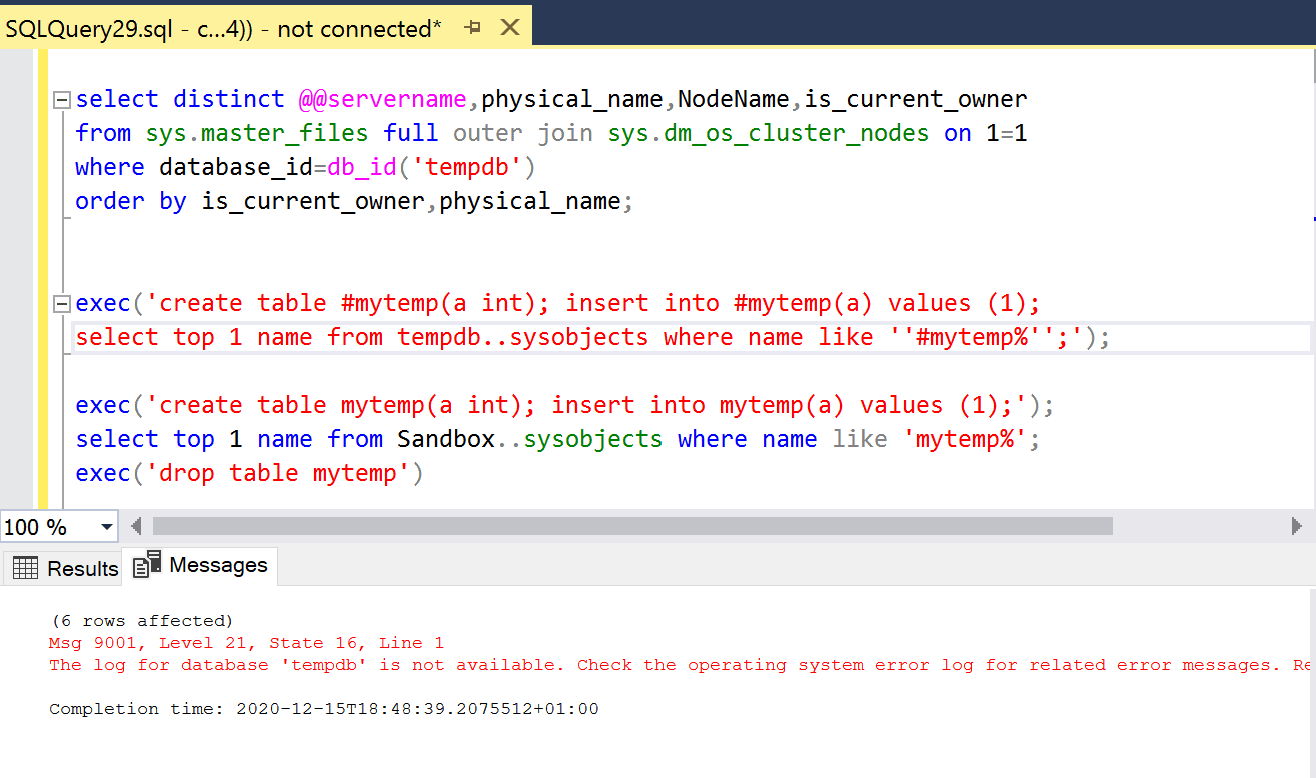
This is the we observed; When removing the disk where the TEMPDB resides we saw that SQL Server did not shut down. Instead, it complained with a "Msg 9001" that the log for database TEMPDB was not available. You can see this error below.

The primary node kept complaining until a manual failover was initiated.
After the second node took up the workload, we wondered, why was this happening. We started to check the hardware config (which looked fine), checked articles by trusted peers (confirming this was no strange setup), and reached out to fellow DBAs, who were just a surprised as we were.
Microsoft to the rescue
We raised a ticket with Microsoft in the belief that this must be a bug of some sort. The Microsoft technician that took the call initially also fell into disbelief. After internally escalating this, he confirmed that this is intended behaviour with this reasoning: “Because all the other databases are still available and query-able as long as you don’t use TEMPDB.”
"works as intended!"
So, despite the SQL Server instance being hardly usable, the SQL instance will not shut down, the cluster service will not see the local disk failing and since the SQL instance process keeps running, the cluster will not initiate a failover.
The behaviour we expected was this: if a SQL instance is part of an AG or classic cluster and for some reason ends up without a working TEMPDB and/or TEMPDB log, that SQL instance cannot be trusted at all to finish all running queries to a normal end, which in turn means the app's functionality is impaired to such an extent that the app itself cannot be trusted. In our opinion, this is far worse than the alternative of an immediate failover and rollback on the surviving node.
However, in all fairness to Microsoft, this behaviour MIGHT make sense if the SQL Server instance was a standalone server. In that setup, if the TEMPDB disk fails, there could be some cases where some functionality might still be usable. For instance a logging server or a web session status server. But in the light of a High Availability setup, why wouldn't you just failover?
We think it might be better, for clarity’s sake, that the SQL instance initiates a shutdown if the TEMPDB becomes unusable, or at the very least add a trace flag that gives us the choice to initiate a shutdown if the TEMPDB becomes unusable.
For the curious DBA's; this is how you can replicate this problem
Let’s show this behaviour of SQL Server in an example.
Case 1: a cluster does not failover
For this example, we spun up two Hyper-V guests forming a cluster with a SQL clustered resource on cl1.
TEMPDB is placed on a local disk T: on both nodes, in this case, a USB-C connected storage device.
Initially, the query returns the following result set:
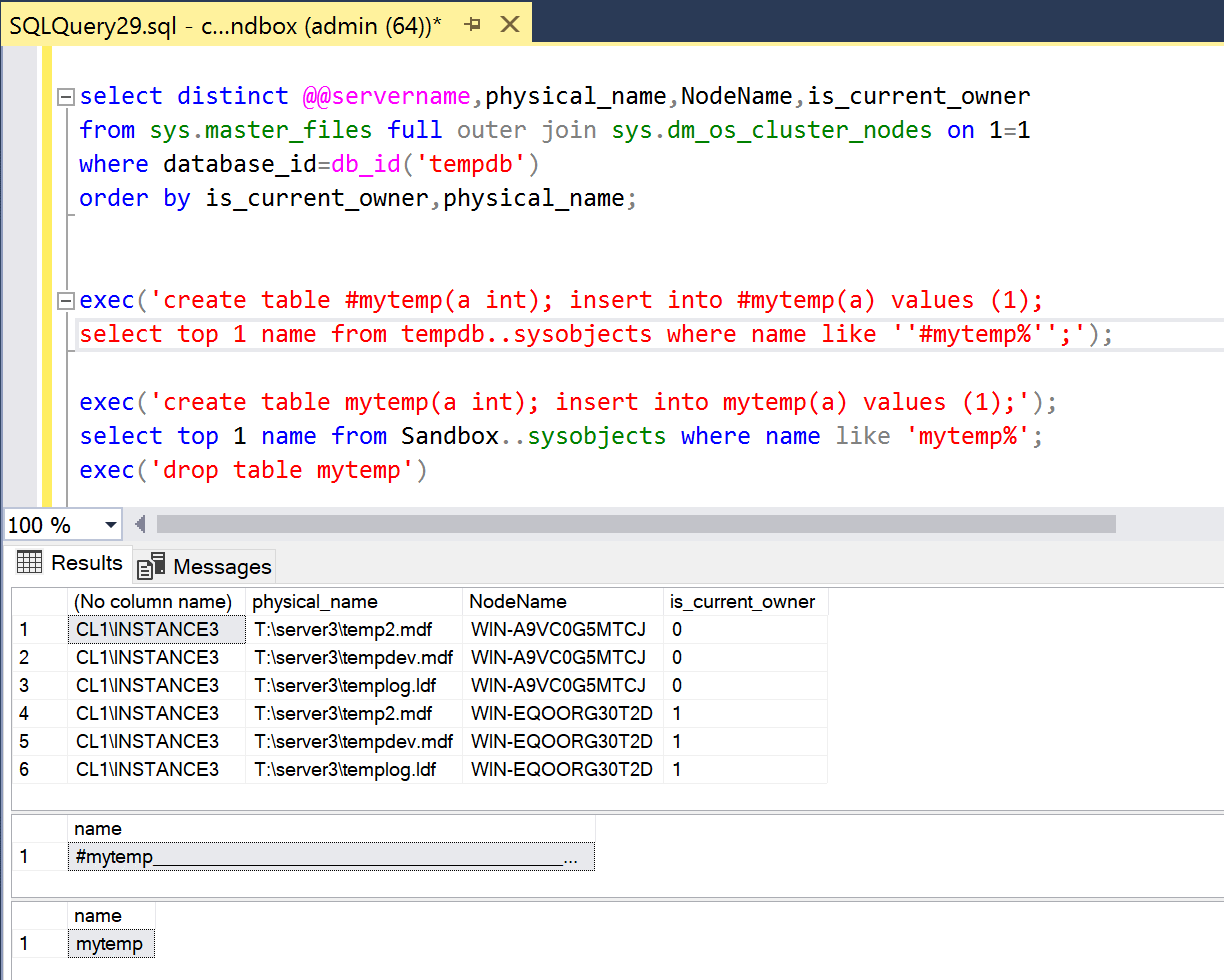
Next, we surprise SQL by removing the T: disk by disconnecting the USB cable for node T2D.
The query now results in:
The first query statement still returns it’s 6 rows, proving that the SQL server is still operational. Even the statements that create tables in the Sandbox database still execute correctly:
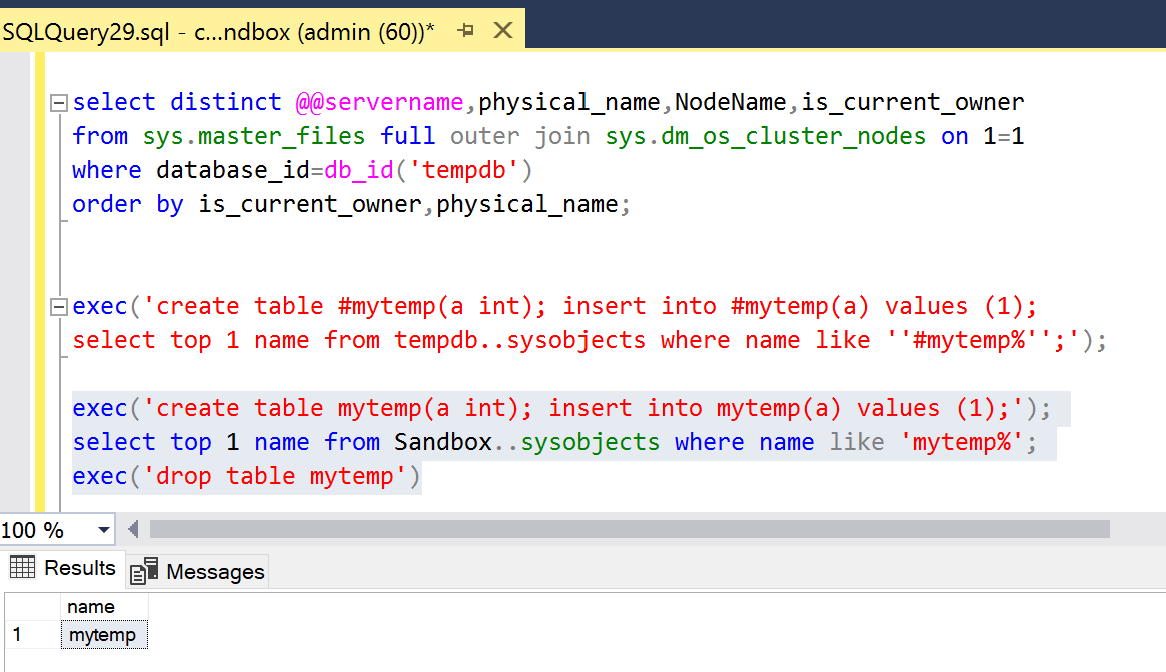
But any other statement using TEMPDB either explicitly or implicitly will fail. As you may know, table variables are created in TEMPDB, which is shown in the following statement.
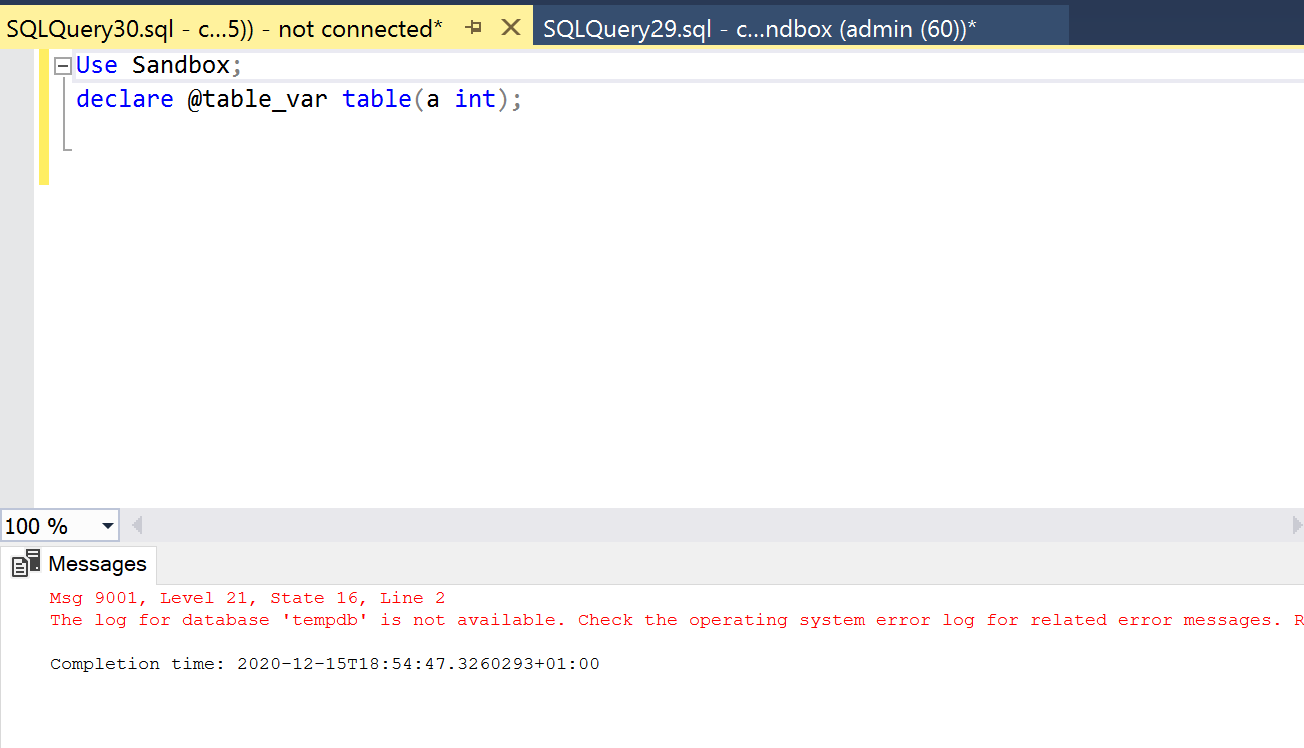
And most important, since the T: disk is not watched by the cluster service and the SQL instance does not shut down because of the missing TEMPDB, there is no failover to the healthy node.
This has consequences for HA setups for SQL cluster. A few considerations:
- Place TEMPDB on cluster storage resource
- If TEMPDB is on local storage, make sure HA is implemented on the storage layer e.g., RAID1 or RAID10. (Sorry about those SSD/NVME extensions which will become twice as expensive). This still does not failover the SQL Server in case of resource failure, but the risk of failure is much smaller
- If TEMPDB is on CIFS/SMB make sure network access is also highly redundant
- Do not think Always On does not face the same issues. Similar issues may arise with Always On implementations. Since TEMPDB cannot be part of the database health check in the availability group, a failing TEMPDB will not be a reason for a failover to any secondary
Case 2: implications for Always On
We have our same two nodes, but this time with local SQL instances with TEMPDB on the T: disk, and two availability groups, AVG1 and AVG2, with lnr1 and lnr2 as respective listeners.
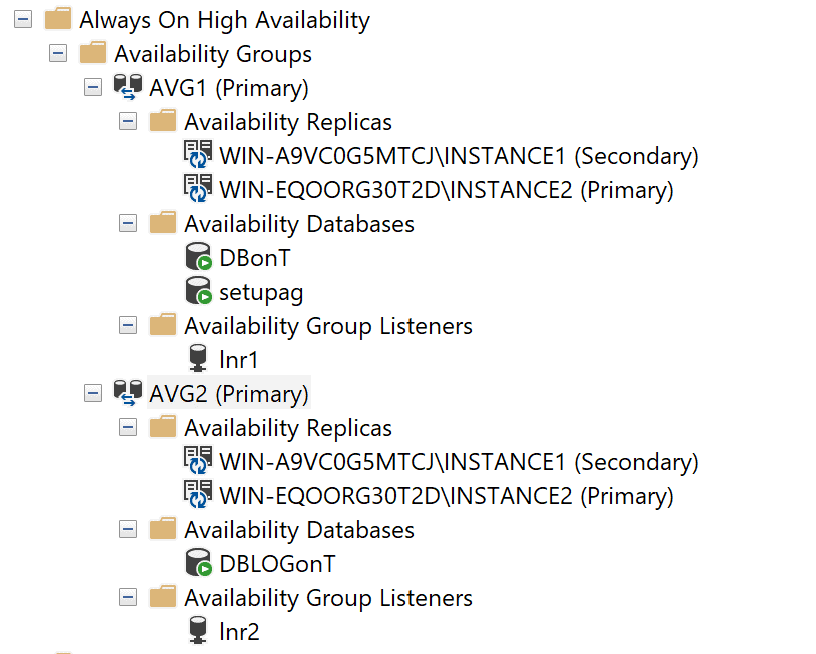
DBonT has an MDF file on our T: drive, DBLOGonT has a log file on our T: drive. For both availability groups database level health check and synchronous commit is enabled. Again, we create a couple of queries of which the results are as follows for respectively lnr1 and lnr2 connections:
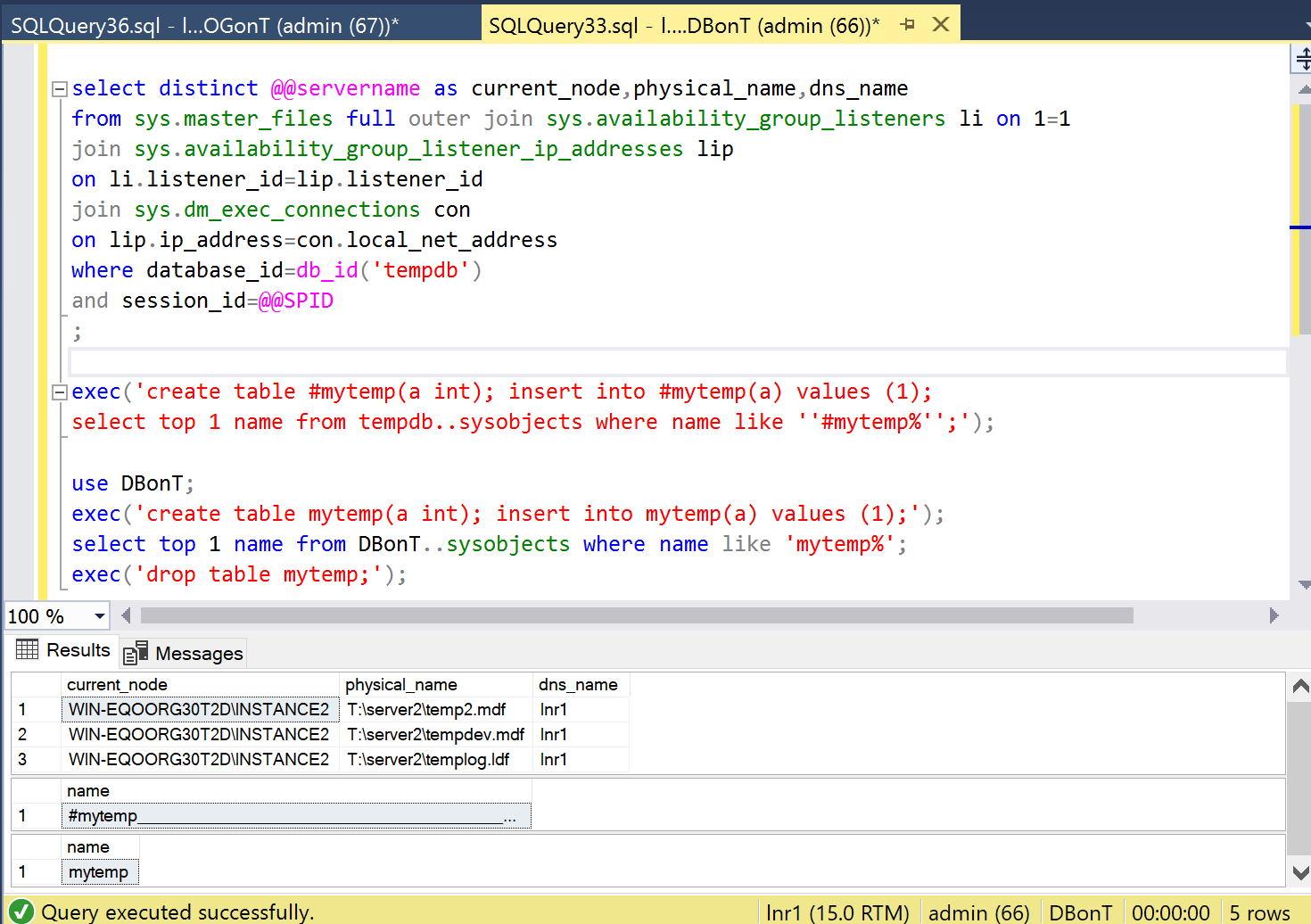
Let us remove that T: disk again and see what SQL server does with the Availability Groups. The first statement on lnr1 gives a result set despite T: disk being not available. By now this is expected because this is the same behavior we saw in the clustered situation.
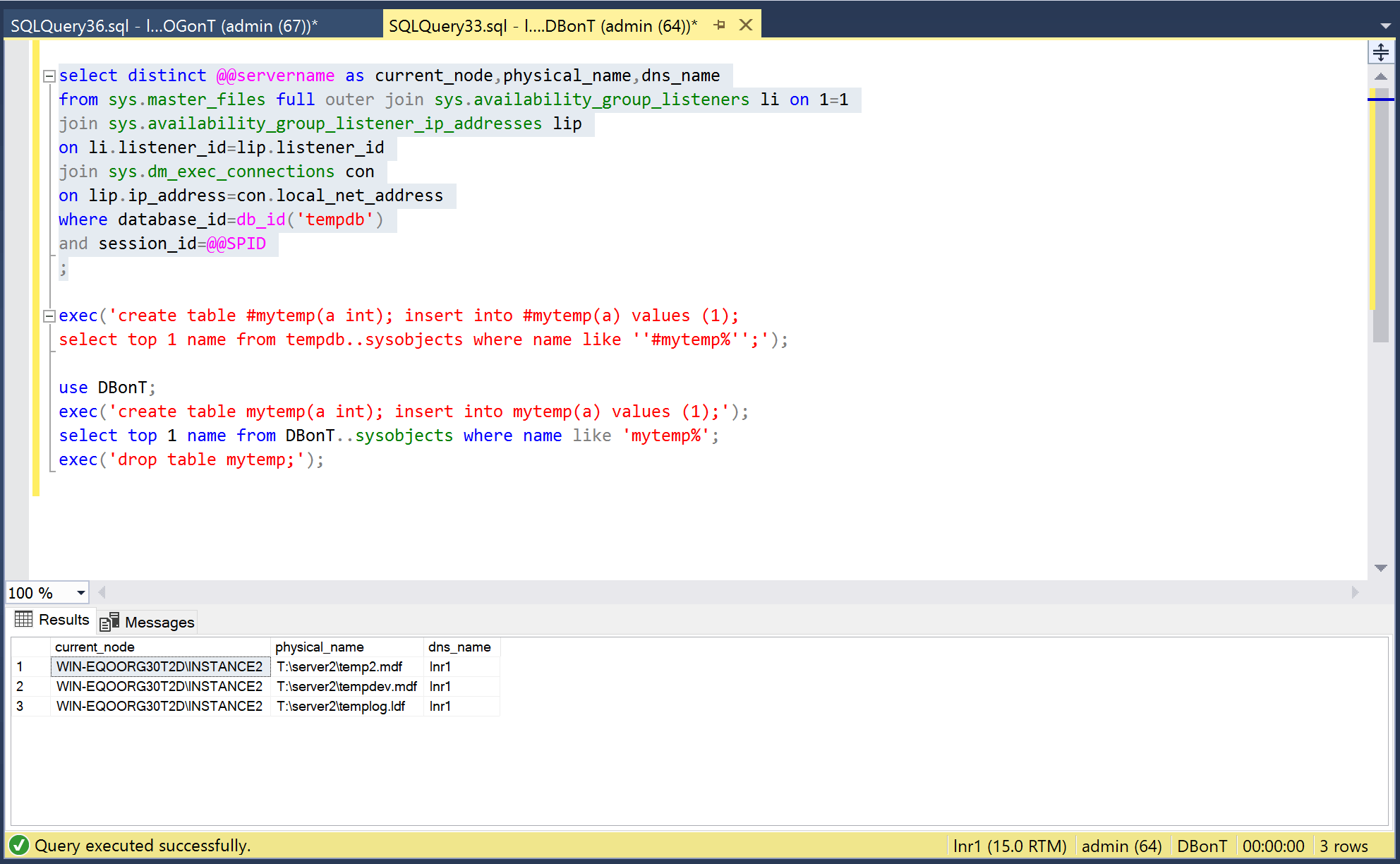
Creation of the temporary table gives the expected error:

The third statement executes successfully:
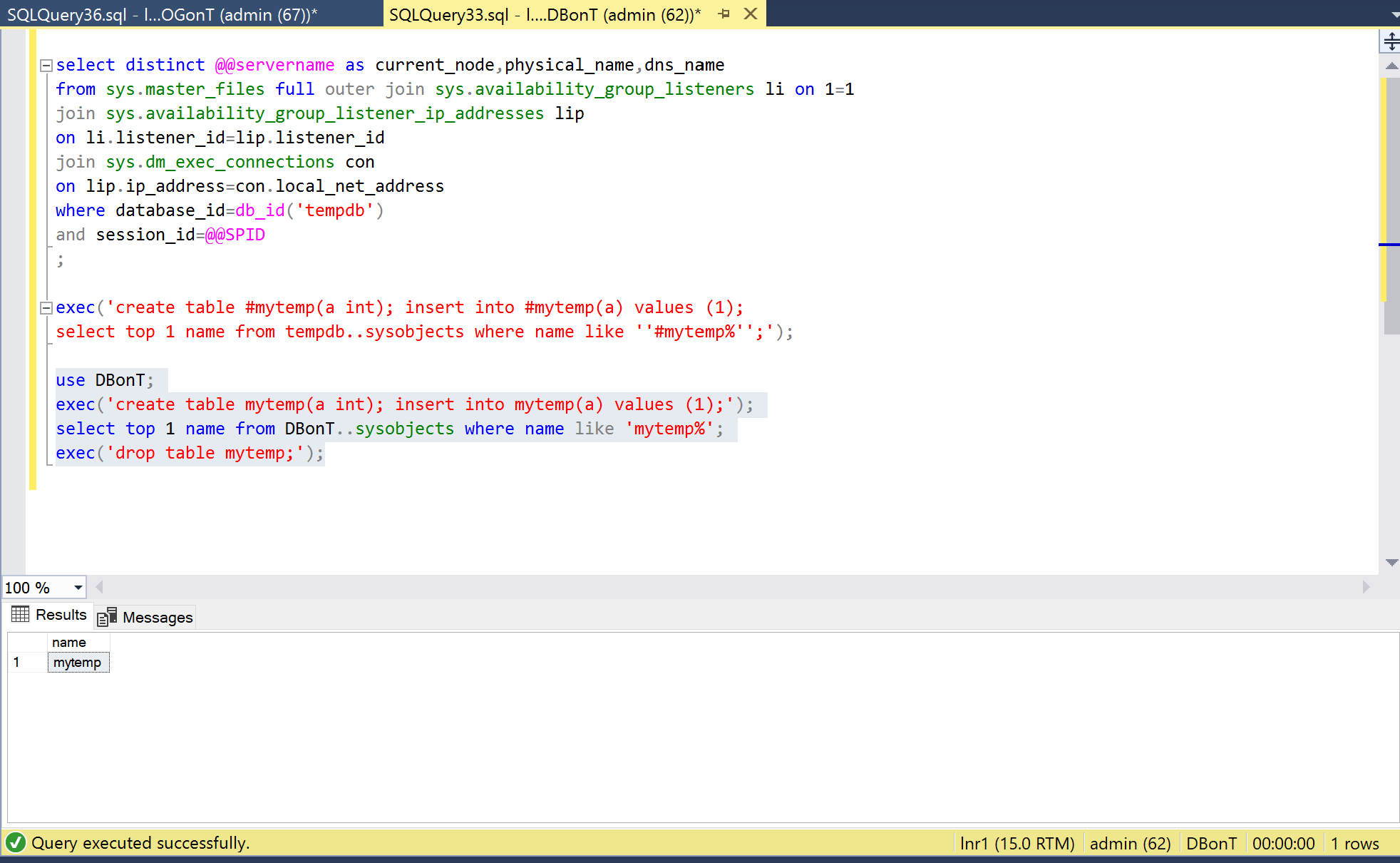
Hold on! Didn’t we have our MDF file on that T: disk? Let’s force a write to disk to check this:
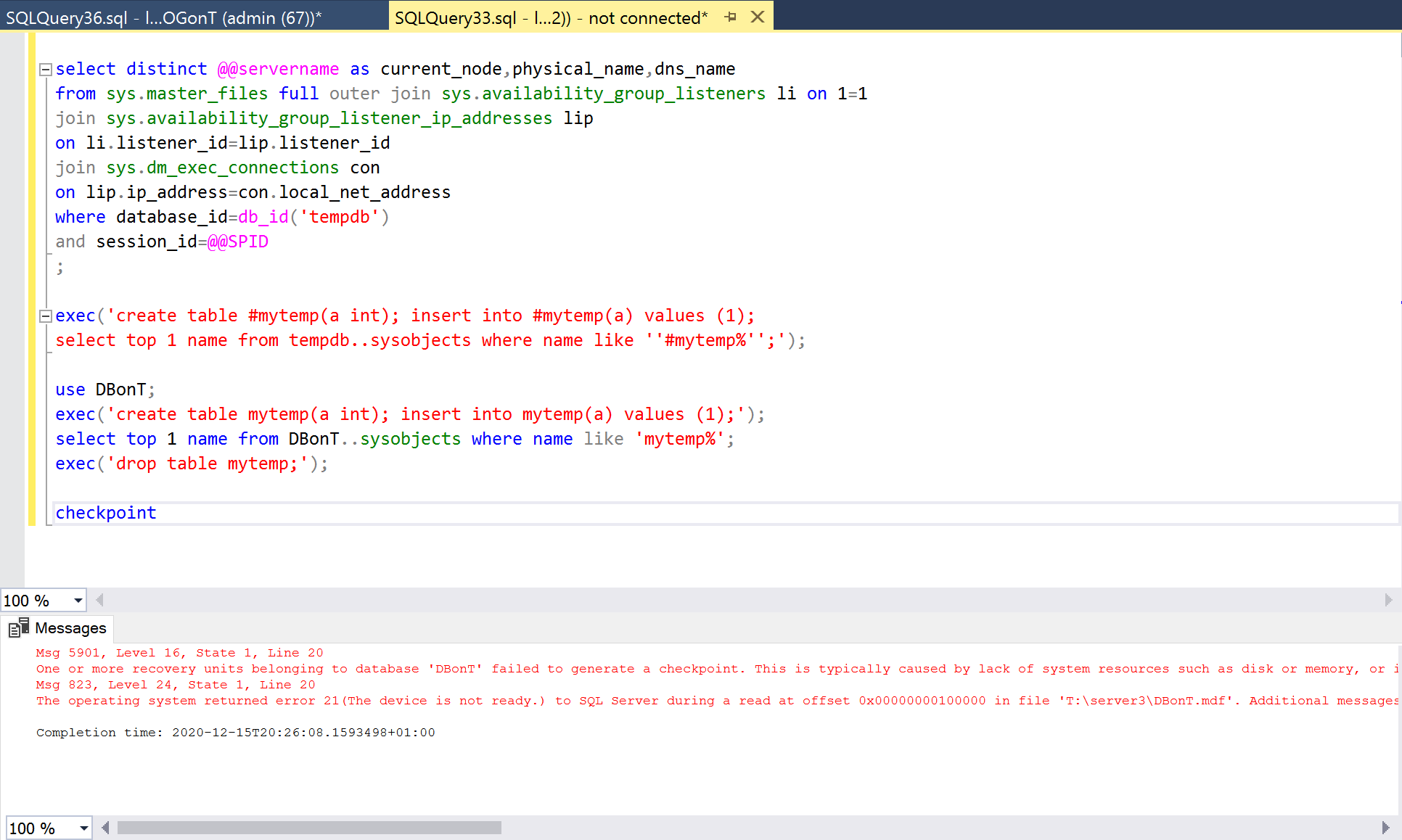
So, any transaction on the DBonT database still succeeds. Probably because there is still a transaction log and a secondary to persist the info. Must check this for validity, but failover to other replica gives any transaction committed, so it seems. Yes, a failover is necessary despite having database level health check enabled. This behavior is documented in Microsoft’s online SQL Server documentation. Losing a datafile will not trigger the database health check failure.
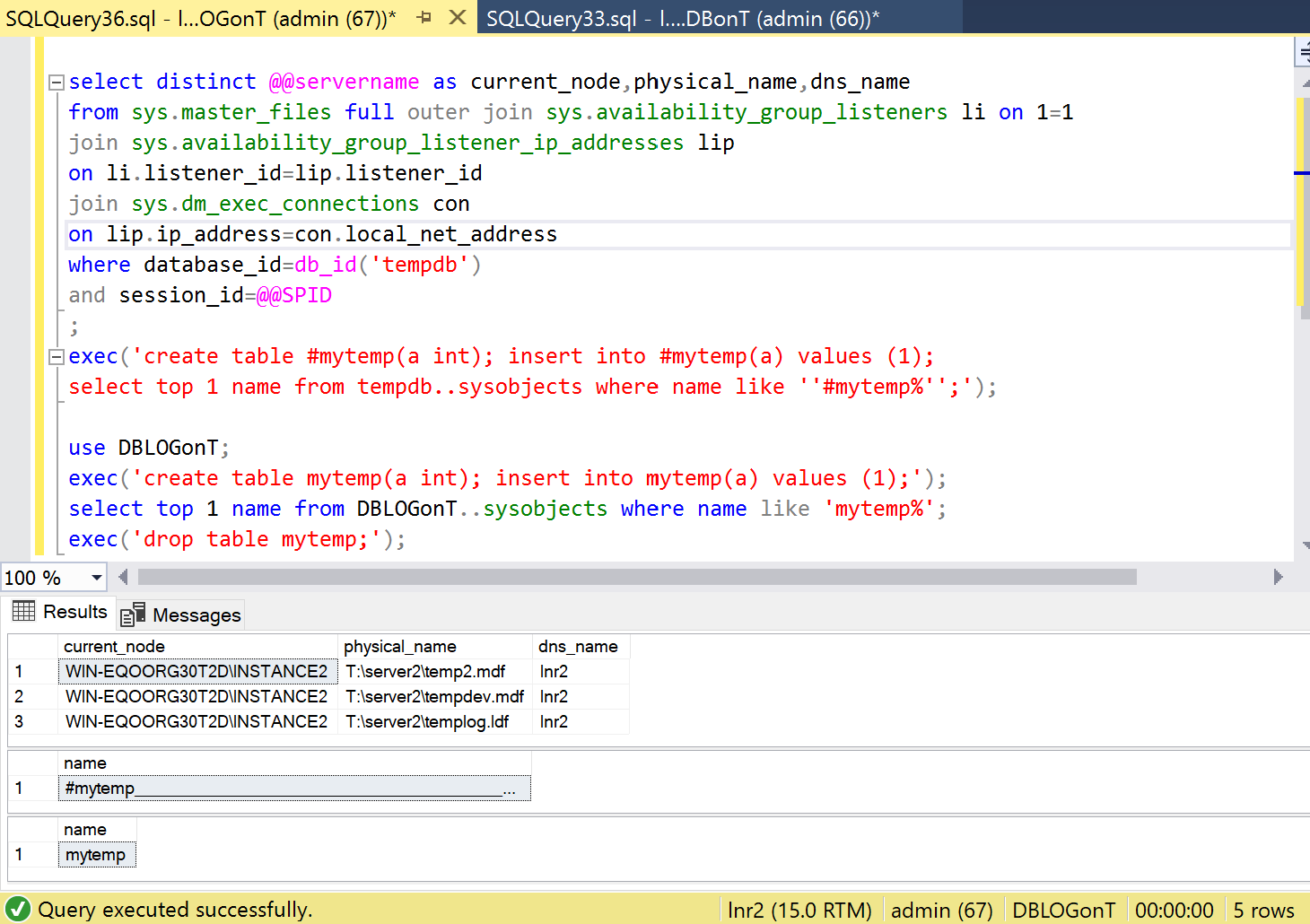
What does trigger the health check failure is transaction log problems with the database. Let’s check lnr2 where we have a user database with its transaction log file on the now removed T: disk.
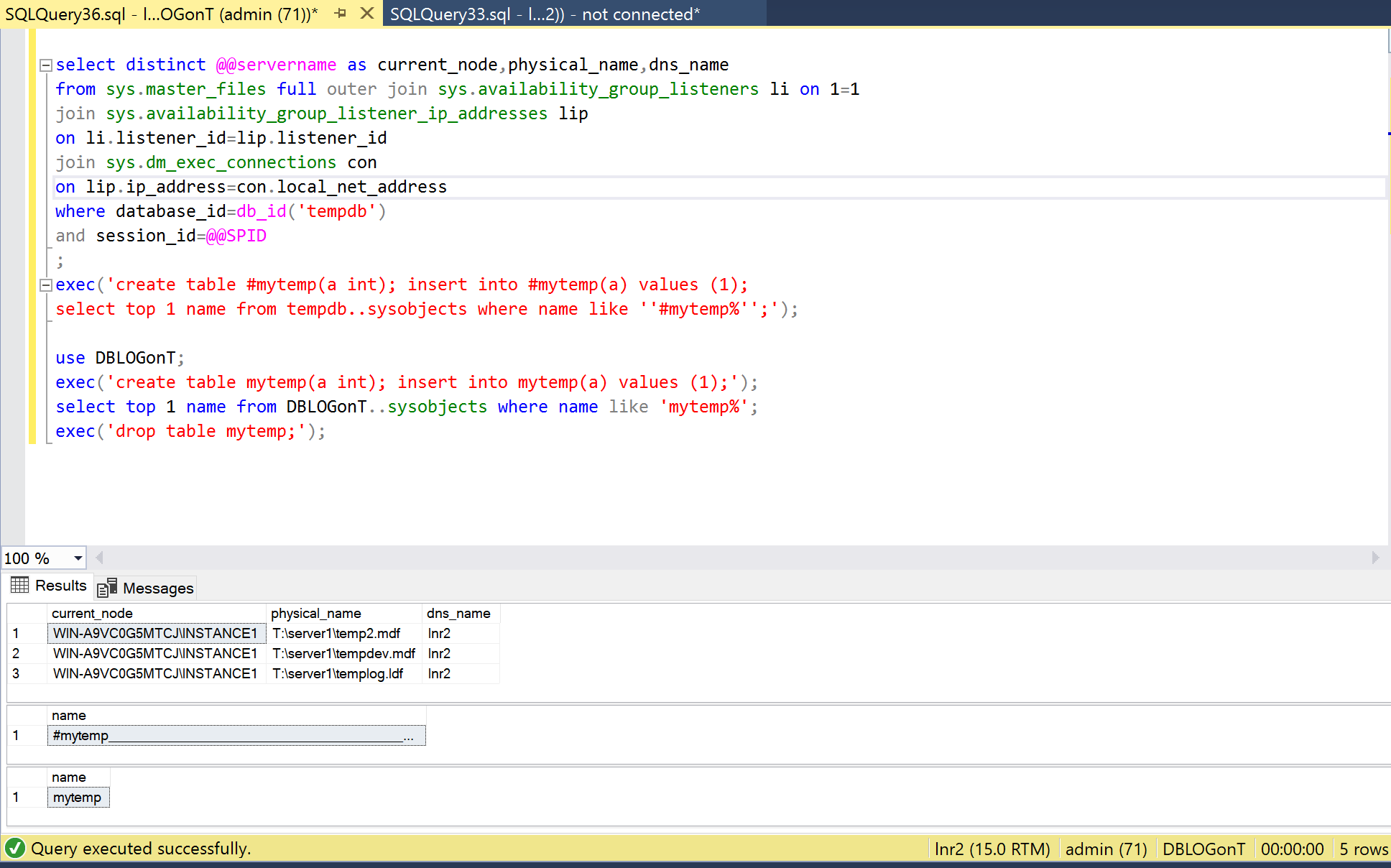
And indeed, as we can see, that listener and thus the availability group AVG2 has failed over the other replica with the healthy T: disk.
Conclusion
Should you still place your TEMPDB on local disk?
It depends. This could still be valid but make sure you use redundant storage hardware on the local machine because the cluster service is not aware of the health state of that local storage. But if performance is not your primary concern then you should opt for clustered storage, and SQL will failover as we expect it to do.
For the more experienced DBA's, there are some alternative ways to get your SQL instance to failover:
- Creating an external PowerShell that checks the health of the disk, by watching for the wretched 9001 message (which is not a fatal failure for SQL), and initiate a failover of the SQL resource by the PowerShell script.
- If you use SQL Always On, you could create a health probe for SQL by using database level health check and the transaction log of user databases on the same local disk the TEMPDB is on. This might turn out into an equivalent of quilted patchwork if you have a lot of local disks to watch. For the masochist DBA’s there might even be a possibility for monitoring via Always On on dedicated node-local instances that initiate a failover for the clustered SQL resource.
We hope this article will save you some headaches, and help you to keep your instances ready to failover!
Researched and written by T. Pelkmans & T. Ekelmans
Twan ^ Theo 🙂

