

In a previous article, we looked at how all the objects in a database and store them in separate files. The scripting used a git repository to track the object code, which is something every DBA and database developer should be doing. In this article, we will learn to use the SSMS scripting options to update a specific class of objects to a separate folder, and then learn how to commit changes made to our git repository.
Scripting Separately
When scripting all objects from SSMS, there is no option to store each type of object in a separate folder. We also cannot alter the name of objects, which follow the pattern of [schema].[object].[type]. That's fine, and I can work with the naming, even though I don't love it. However, I would like to separate all my objects into different folders for organization. That will make the files more similar to what I see in Object Explorer.
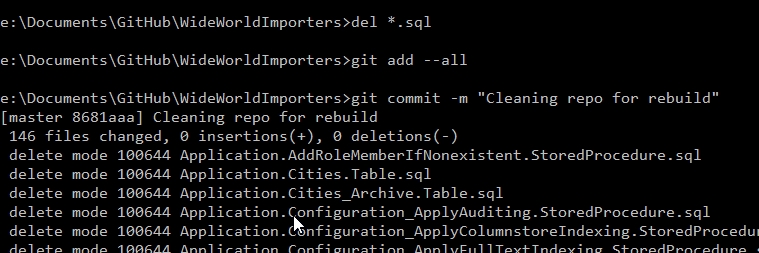
Let's fix our repo a bit. First, I'll delete all the files I have and commit those changes. This gives me these results and an empty repo.
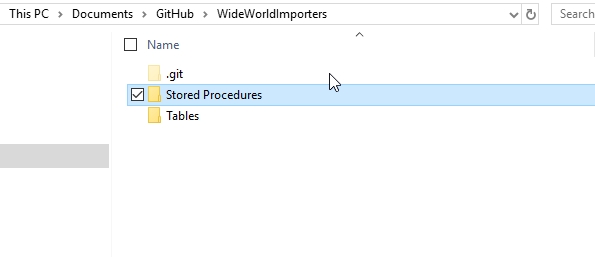
Now I can try and organize my scripting into a better format. I'll re-run the Generate Scripts process from my last article, but this time I'll change a few things. First, I'll add a couple folders to my repo. You could add more for other object types, but this article will stop at tables and procedures.
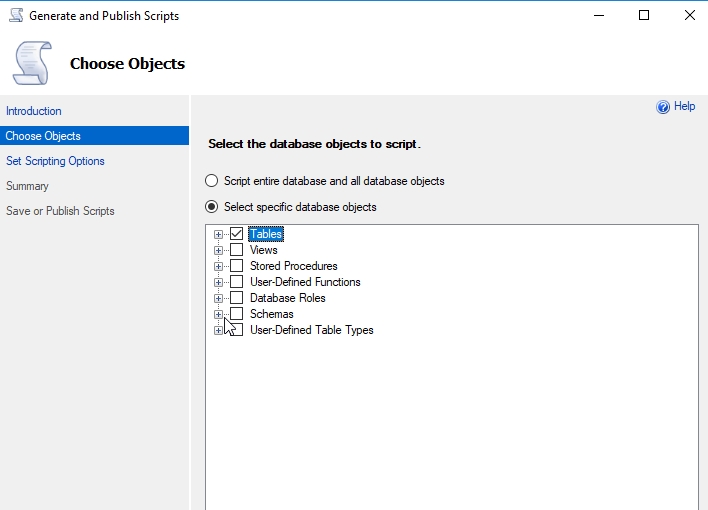
Now, when I run the wizard, I'll select just tables. I c ould expect this to particular tables if I chose, but I'll grab them all.
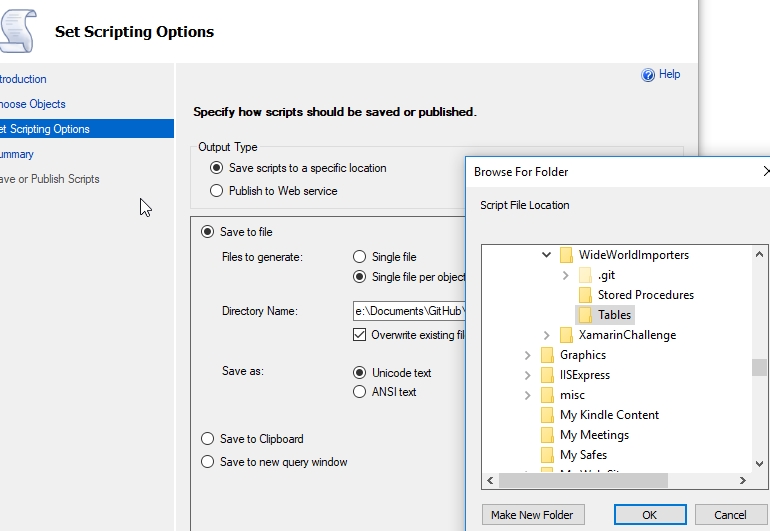
On the scripting options tab, I'll then select the tables location for my scripts. Again, one script file per object.
Now I can let the wizard complete, and I've got all my objects in the Tables folder.
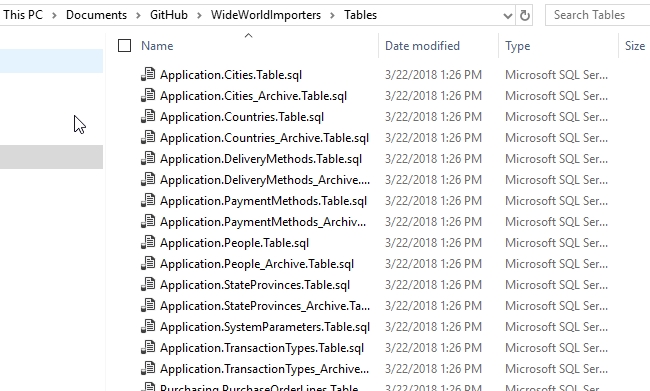
I can repeat this for Stored Procedures, putting them in the [Stored Procedures] folder. I select just procedures and then place them in the appropriate folder. Once I do that, I'll commit these changes.

Now I've got my objects into folders. I could also do this for views, functions, etc. This will organize my repository similar to Object Explorer. The exception will be that I can't separate out the types of functions here into scalar or table-valued. They are all scripted in the same way.
Making Changes
Let's expand this slightly. I'm going to run this code to change one procedure and add a new one. The alter procedure adds a column name to the second item in the column list.
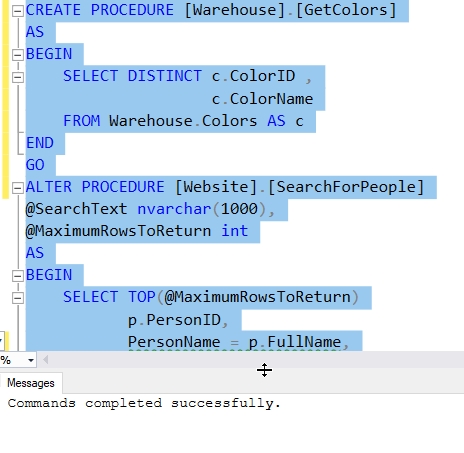
Once I've completed this, I'll rescript my procedures using the procedure above. This will script all of them, and they'll overwrite the files. I'll see all the files with a new datestamp. Trust me, if you try this, the Date Modified will change for all files.
With this complete, I'll now check my git status.
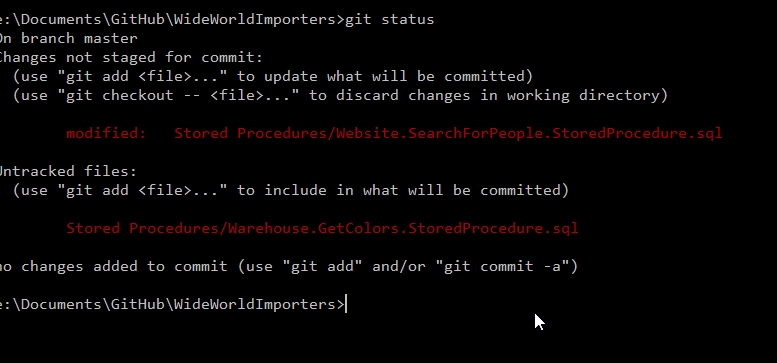
As you can see, only two files are tracked as changed. One new one and one modified. If I stage these (with git add), I'll see them both added, and I can then commit them as changes.
A Cumbersome Process
If you think scripting out all procedures, and running through the process for tables, views, etc., is cumbersome, you're right. This isn't the way I'd like to track the code in my database and keep a VCS up to date. Certainly tools like SQL Source Control, ReadyRoll, etc. make this easier and faster. That's the value they provide and the reason they are a paid dd-on.
However, there are ways to make this process smoother for the developer. In the next article, we'll look at how PowerShell can be used to drive this process and reduce the manual work.

