

SQL Server 2017 introduced the concept of graph data tables as part of the SQL Server database engine. With SQL Server 2019, there were some enhancements like ‘shortest path’ function and constraints on edge tables that make this feature more usable – although it is far from a full-fledged graph database.
Graph tables are essentially meant to store and query data that has a lot of many to many relationships. In the relational model, we design and query entities or tables. We use keys to access the data in entities. In the graph model, we design and query relationships.
There are a lot of examples of graph data, but there is one that is used a lot and rarely thought of that way – Entity-Relationship diagrams. Most of the metadata that makes up a database can be queried on with DMVs. But it can be difficult and cumbersome when we must dig deeper than the first level into relationships.
Consider the table ‘HumanResources.Employee’, from Adventureworks2017. This table has foreign key relationships with six tables. Some of those tables, in turn, have more relationships. To perform a delete or updating certain columns – it is important to get all those relationships clear and do it in the right order. This is where a graph data model can come in handy. By querying on the metadata stored in graph form, it is easy to see how many levels down the connection goes and what are those connections.
Below are some key questions that can be answered easily by making a graph data model out of an Entity Relationship diagram.
- How many tables connect to a table?
- How many tables does a table connect to?
- What is the path (tables/constraints involved) to get to data in Table B from data in Table A?
To construct such a model - the ‘nouns’ in the questions will make up node tables, and the verbs become the ‘Edge’ tables. There is one significant noun – ‘Table’. Table related information goes into a Node table. The most significant verb is ‘connect.’ In database terminology, this is our foreign key or constraint. Foreign-key related information goes into an Edge table.
The data model is very simple, as below.

Both node and edge tables can be created as below.
USE [AdventureWorks2017] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO --Creating Node Table CREATE TABLE [dbo].[TableNode]( [tablename] [varchar](200) NULL ) AS NODE ON [PRIMARY] GO --Creating Edge Table CREATE TABLE [dbo].[ForeignKeyEdge]( [constraintname] [varchar](500) NULL, [fieldname] [varchar](200) NULL ) AS EDGE ON [PRIMARY] GO
Now, DMV based queries can be used to populate these tables.
--Populating Table Node
INSERT INTO dbo.tablenode
(tablename)
SELECT DISTINCT schema_name(tab.schema_id) + '.' + tab.name as
FROM sys.tables tab
--Populating Foreign Key Edge
INSERT INTO dbo.ForeignKeyEdge
($from_id, $to_id,constraintname,fieldname)
SELECT c.$node_id,d.$node_id,b.fk_constraint_name,column_name
FROM
(SELECT schema_name(tab.schema_id) + '.' + tab.name AS [tablename],
col.column_id,
col.name AS column_name,
case when fk.object_id is not null then '>-' else null end AS rel,
schema_name(pk_tab.schema_id) + '.' + pk_tab.name as primary_table,
pk_col.name AS pk_column_name,
fk_cols.constraint_column_id AS no,
fk.name AS fk_constraint_name
FROM sys.tables tab
INNER JOIN sys.columns col
ON col.object_id = tab.object_id
LEFT JOIN sys.foreign_key_columns fk_cols
ON fk_cols.parent_object_id = tab.object_id
AND fk_cols.parent_column_id = col.column_id
LEFT JOIN sys.foreign_keys fk
ON fk.object_id = fk_cols.constraint_object_id
LEFT JOIN sys.tables pk_tab
ON pk_tab.object_id = fk_cols.referenced_object_id
LEFT JOIN sys.columns pk_col
ON pk_col.column_id = fk_cols.referenced_column_id
AND pk_col.object_id = fk_cols.referenced_object_id
WHERE fk.name is not null
) b
INNER JOIN tablenode c ON B.[tablename] = c.tablename
INNER JOIN tablenode d ON B.[primary_table] = d.tablename
The 'match' clause has to be used to join these two tables. The query returns data as below.
SELECT
fromtable = a.tablename
, b.constraintname
, b.fieldname
, totable = c.tablename
FROM
tablenode AS a, foreignkeyedge AS b, tablenode AS c
WHERE MATCH(a-(b)->c);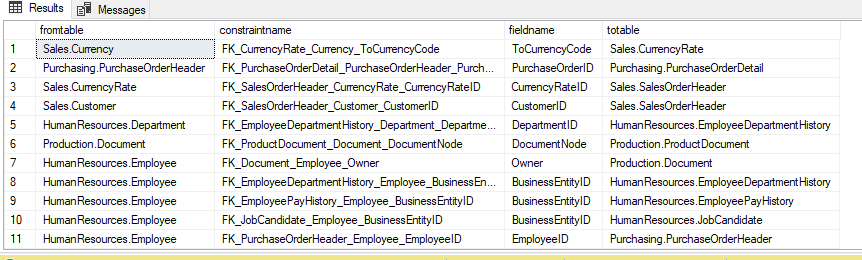
How many tables are directly connected to a table, say, HumanResources.Employee?
SELECT
fromtable = a.tablename
, b.constraintname
, b.fieldname
, totable = c.tablename
FROM
tablenode AS a, foreignkeyedge AS b, tablenode AS c
WHERE MATCH(
a-(b)->c)
AND a.tablename = 'HumanResources.Employee';
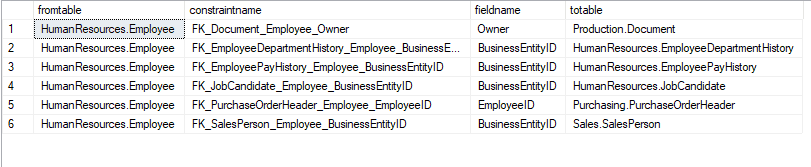
2 How many tables does table HumanResources.Employee directly connect to?
SELECT a.tablename as totable,b.constraintname,b.fieldname,c.tablename as totable FROM tablenode a, foreignkeyedge b, tablenode c WHERE MATCH(a-(b)->c) AND a.tablename = 'HumanResources.Employee'

There may be multiple foreign keys between tables. Depending on which foreign key we choose, the path connecting two tables can be different and there can be multiple such paths.The ‘shortest path’ function can help find these paths. But the catch with this is that it will only pull the first path it finds. For example, Sales.SalesOrderHeader table has two fields, Bill_ToAddressId and Bill_FromAddressID that are both foreign keys into Person.Address table.
Running a query as below returns one of those results
SELECT STRING_AGG(toTable.TableName+'('+f.fieldname, ')->') WITHIN GROUP (GRAPH PATH) AS [ConnectedViaTable(Field)],
LAST_VALUE(toTable.TableName) WITHIN GROUP (GRAPH PATH) AS ConnectedTo,
COUNT(toTable.TableName) WITHIN GROUP (GRAPH PATH) AS LevelsofConnection
FROM
TableNode AS fromTable,ForeignKeyEdge FOR PATH AS f,TableNode FOR PATH AS toTable
WHERE
MATCH(SHORTEST_PATH((toTable<-(f)-)+fromTable))
AND fromTable.TableName = 'Sales.SalesOrderHeader'
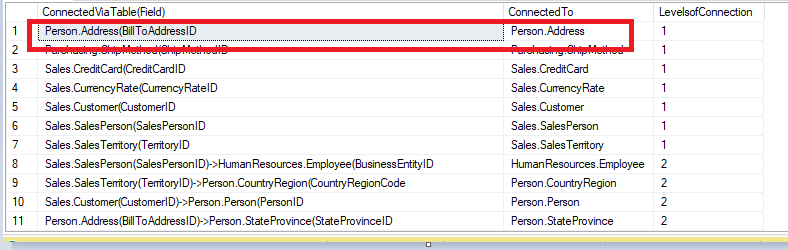
To get more comprehensive results, we need to pull ALL possible connections from one table to another table. In graph theory, this is called ‘Transitive Closure’. SQL Server does not have a built-in function for this, so we have to use CTEs for this purpose.
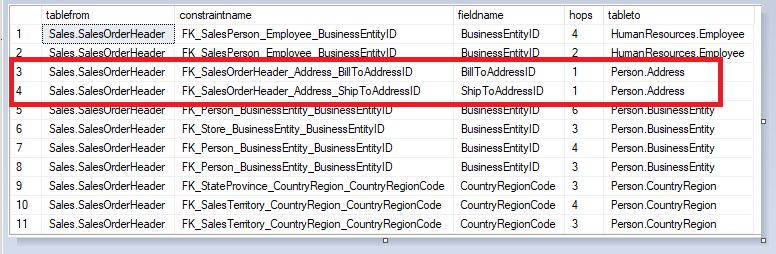
DROP TABLE IF EXISTS #temptable --Pulling all possible connections between node records CREATE TABLE #temptable (tablefrom varchar(100), constraintname varchar(500), fieldname varchar(200), tableto varchar(100)) INSERT INTO #temptable SELECT a.tablename,x.constraintname,x.fieldname, b.tablename FROM tablenode a, [dbo].[ForeignKeyEdge] x, tablenode b WHERE MATCH(a-(x)->b) ORDER BY a.tablename ;WITH ERDCTE AS ( SELECT tablefrom, constraintname,fieldname,1 AS hops,tableto from #temptable UNION ALL SELECT a.tablefrom, b.constraintname,b.fieldname,a.hops+1,b.tableto from erdcte a, #temptable b WHERE a.tableto = b.tablefrom ) SELECT * FROM erdcte WHERE tablefrom = 'sales.salesorderheader'
As below we can see that both foreign keys from Sales.SalesOrderHeader to Person.Address are shown in the results.
While this query shows all possible table-to-table connections, it still does not give detail needed for cascading relationships. This data can be obtained by constructing a graph query specifically with multiple joins. For example, to look at 3 hops involved between Sales.SalesOrderHeader to Person.CountryRegion:
SELECT a.tablename, x.constraintname,x.fieldname, b.tablename, x1.constraintname,x1.fieldname,c.tablename, x2.constraintname,x2.fieldname, d.tablename FROM tablenode a, [dbo].[ForeignKeyEdge] x, tablenode b, [dbo].[ForeignKeyEdge] x1, tablenode c, [dbo].[ForeignKeyEdge] x2, tablenode d WHERE match(a-(x)->b-(x1)->c-(x2)->d) AND a.tablename = 'sales.salesorderheader' AND d.tablename = 'person.countryregion'
We get all the paths that connect these two tables in 3 hops.

If we want connections between Sales.SalesOrderHeader and HumanResources.Employee that is two hops only, we’d have to use two instances of node tables that will show how these two tables are connected.
SELECT a.tablename, x.constraintname,x.fieldname, b.tablename, x1.constraintname,x1.fieldname,c.tablename FROM tablenode a, [dbo].[ForeignKeyEdge] x, tablenode b, [dbo].[ForeignKeyEdge] x1, tablenode c WHERE match(a-(x)->b-(x1)->c) AND a.tablename = 'Sales.Salesorderheader' AND c.tablename = 'HumanResources.Employee'

As of now, there is no way to avoid this kind of query construct with graph tables because match clause does not allow for nulls or left join like conditions – we need to know the exact number of hops involved. But it does give an easy overview of connections involved.
In conclusion, pulling metadata into graph tables can be a convenient way to understand relationships from table to table with a schema and make appropriate decisions for writing queries or design changes.
