

In this article, we will discuss how to optimize loading a
sample file into SQL Server using DTS.
There are a number of tasks that you can use to load the data including
the Transform Data Task, the Bulk Insert Task and the Data Driven Query
Task. In this article, we’ll cover
performance differences between all the tasks and how to increase your
performance on some of the slower tasks.
To quantify the data load procedure,
we’re loading a flat file that contains a mailing list with more than 15,000
records and 30 columns. The same concepts
that we discuss in this article would work among any type of data load
generally. The first way we’re
going to load the data from the flat file, is by using the transform data task
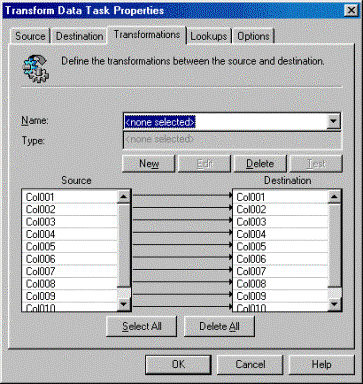
in a simple transformation as shown below:

By default, DTS will automatically map the transformation for
you between each column as shown below. Each column is mapped
based on column name and ordinal position automatically.
Each connecting line represents a COM object that has to be created to transform the
data. There is quite a bit of
overhead to do this and in our case, this is an unnecessary step since
everything maps perfectly.
When loading a lot of data, make sure that you temporarily drop indexes
on the destination table. If you don't drop the
indexes on large tables, you will notice a significant performance degregation. When
loading a small amount of data (50,000 or less is my rule of thumb), you will
not receive a benefit from this.
After running this transformation that we just created we noted the time
of 5 seconds.
Custom scripting (written in VBScript or
JScript usually) will enhance the transformation logic but also slow you down. We ran the same transformation using VBScript and
noticed it took 13 seconds. The
same transformation written in JScript took 19 seconds. The reason for this is DTS is no longer
using the optimized COM objects that it ships with. Instead it uses your uncompiled code
that you create. Any added logic
you place on DTS like this will slow it down. For example, if we place some VBScript
logic in each field to make it upper case then our time of 13 seconds jumps to
24 seconds. If you need to perform
custom logic like this, DTS in SQL Server 2000 ships with a number of predefined
COM objects that can perform this action.
When running the Import/Export Wizard I noticed that no
matter what type of transformation we selected (VBScript or Copy Columns), our
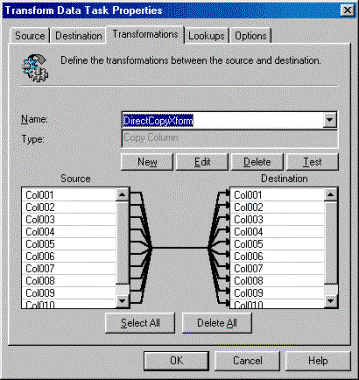
transformation time was almost 50% of the previous transformation. After saving a package and going to the
transformation tab as shown below we can see why. DTS is optimizing itself to use
only one COM object to transform all the data. If you’re writing a package in the
Designer you can do the same thing.
Simply delete all the transformation lines and then create a new
transformation that uses all the source columns as the source and all the
destination columns for the destination.
The result should look like this:
By doing this, our basic transformation now takes 3 seconds
and our VBScript transformation takes 8.
You can also see in the below chart that the Bulk Insert task was our
fastest since no transformations occur in the task. The Bulk Insert task only took DTS 2
seconds to execute. The below chart
covers the results and the time it took for the records to transform among for
all transformations.
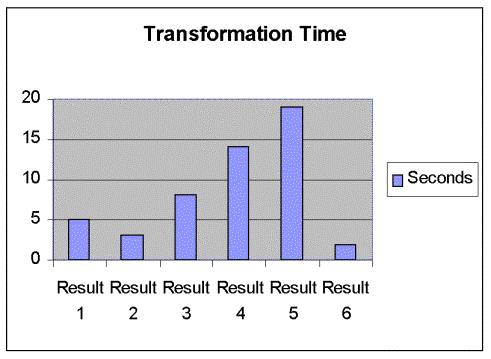
Result 1 | Basic |
Result 2 | Sharing COM Transformation |
Result 3 | Sharing COM Transformation and VB |
Result 4 | VB For Each Transformations |
Result 5 | Jscript for Each Transformation |
Result 6 | Bulk Insert |
As you can see, the Bulk Insert Task is much faster for
loading data. However the
limitations may outweigh any benefits from speed. For example, to use the Bulk Insert
Task, the columns’ schema on the source must exactly match the columns on the
destination other than length. A
great alternative with decent speed is going to be the Transform Data Task when
using one COM object. Other options
like Fast Load under the options tab can further increase performance of your
data load since it bypasses triggers.