

In Part 1, we looked at a base query from AdventureWorks2012Big and varied column order in non-clustered indexes to determine effect on overall performance. In this session we are going to examine how a re-definition of the clustered index may also achieve performance gains – especially when there may be multiple SELECT queries having a common factor in their WHERE clause.
Consider the following report based queries from AdventureWorks2012Big (as described and modified in Part 1 of this series) with its original indexes (TSQL script attached):
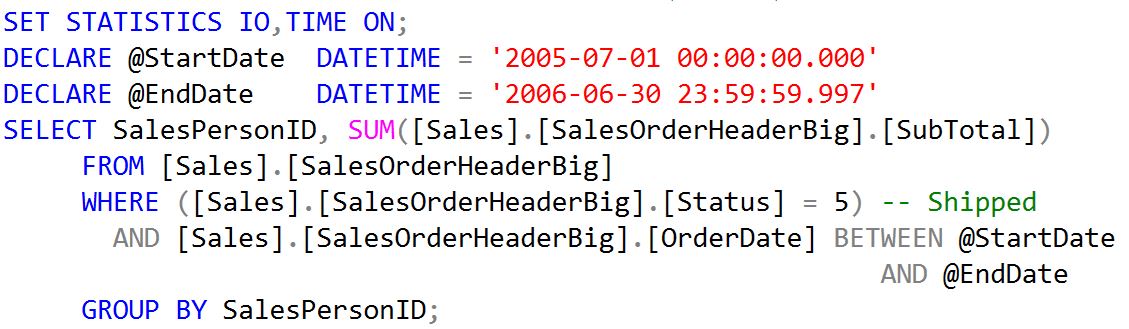
Figure 1: Base Report Query (from Part 1)
and
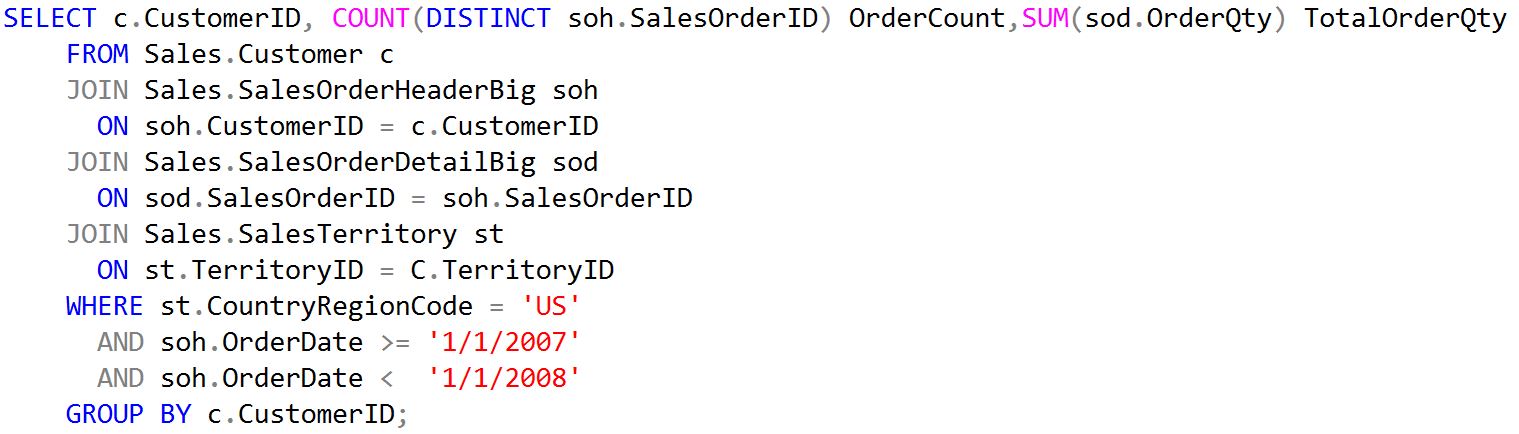 Figure 2: Query 2
Figure 2: Query 2
Running the first query yields this query plan:
 Figure 3: Query 1 Plan, Original Indexes
Figure 3: Query 1 Plan, Original Indexes
with 30,311 logical reads and cpu time of 173ms. The Query Plan is a Clustered Index Scan on SalesOrderHeaderBig where the Primary Key and Clustered Index are defined on SalesOrderID. Query cost is 22.9503. Note the suggested index is
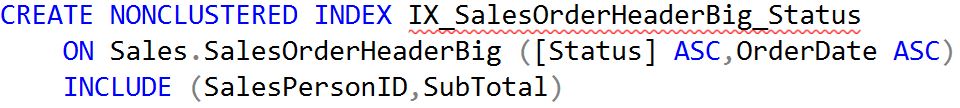
Figure 4: Suggested Index for Query 1
Now, running the 2nd query gives us
 Figure 5: Query 2 Plan, Original Indexes
Figure 5: Query 2 Plan, Original Indexes
with 3655 logical reads (SalesOrderHeaderBig) and cpu = 1328ms. Note there are two nonclustered index operators: IX_SalesOrderHeaderBig_OrderDate and IX_SalesOrderHeaderBig_CustomerID for SalesOrderHeaderBig. Interesting that there is an index seek on OrderDate and an index scan on CustomerID and that the suggested index contains both columns found in the individual index definitions. Normally I would think you would have an index seek followed by a key lookup on the clustered index, but in this case it appears that less resources are used with the index scan on IX_SalesOrderHeaderBig_CustomerID and that the two indexes together contain all the columns needed for the SELECT query. The suggested index is

Figure 6: Suggested Covering Index for Query 2
Both of these queries use OrderDate within the WHERE clause and the second query also used SalesOrderID for the JOIN to the Customer and the SalesOrderDetailBig tables.
If we look at the size of the indexes for Sales.SalesOrderHeaderBig we get
| Schema | Table | Index | Used in KB | Reserved In KB | Rows |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_rowguid | 51,216 | 51,272 | 1,290,065 |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_SalesOrderNumber | 50,272 | 50,312 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_CustomerID | 26,600 | 26,632 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_OrderDate | 21,928 | 23,112 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_SalesPersonID | 18,136 | 18,184 | 1,290,065 |
| Sales | SalesOrderHeaderBig | PK_SalesOrderHeaderBig_SalesOrderID | 239,080 | 239,240 | 1,290,065 |
| Sales | SalesOrderHeaderBig | Total: | 407,232 | 408,752 | 1,290,065 |
Figure 7: Original Index size for SalesOrderHeaderBig
Now applying the recommended indexes and looking at their sizes:
| Schema | Table | Index | Used in KB | Reserved In KB | Rows |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_rowguid | 51,216 | 51,272 | 1,290,065 |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_SalesOrderNumber | 50,272 | 50,312 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_CustomerID | 26,600 | 26,632 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_OrderDate | 23,168 | 23,944 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_SalesPersonID | 18,136 | 18,184 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_Status | 39,800 | 40,392 | 1,290,065 |
| Sales | SalesOrderHeaderBig | PK_SalesOrderHeaderBig_SalesOrderID | 239,080 | 239,240 | 1,290,065 |
| Sales | SalesOrderHeaderBig | Subtotal: | 448,272 | 449,976 | 1,290,065 |
Figure 8: SalesOrderHeaderBig with suggested covering indexes
IX_SalesOrderHeaderBig_OrderDate gained 2mb with the INCLUDE clause and the new index added another almost 40mb. Now running the same 2 queries again (with the suggested nonclustered index), the first query yields

Figure 9: Query 1 using suggested covering index
with 19* logical reads and cpu = 0ms with a query cost of 0.553303. * - Part 1 was 12 logical reads because data_compression = row was applied then.
Now if we run the second query against the recommended index we get
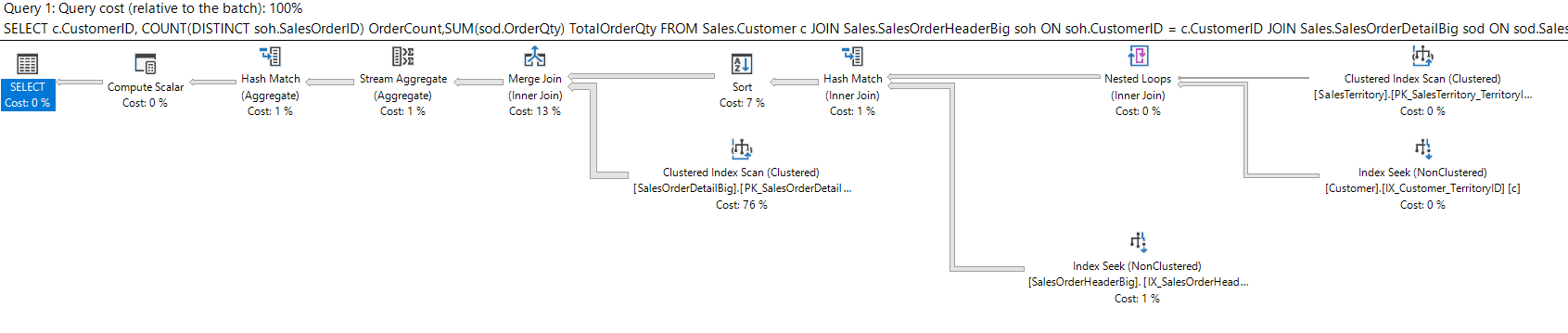 Figure 10: Query 2 With Suggested Covering Index
Figure 10: Query 2 With Suggested Covering Index
with logical reads = 346 and cpu = 640ms for SalesOrderHeaderBig and a total query cost of 80.9818.
It’s well known that covering indexes can really help out a single query, but sometimes it pays to look elsewhere for overall database performance as well as possibly saving disk space.
The original combined Primary Key and Clustered Index was defined as
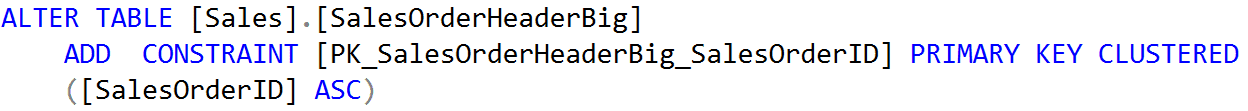
Figure 11: Original Primary Key and Clustered Index
Let’s return SalesOrderHeaderBig back to its original indexes with

Figure 12: Restore Indexes back to Original
Now, suppose we redefine the Primary Key and Clustered Index as separate entities (idea from my Austin Local User SQL Server Group (CACTUSS) presentation (https://cactuss.pass.org/?EventID=12496). This type of definition lets you retain the original table’s Foreign Key references and also may help query performance as discussed below:
 Figure 13: Redefine Clustered Index & Primary Key
Figure 13: Redefine Clustered Index & Primary Key
Note use of UNIQUE in the definition of the Clustered Index. If that wasn’t specified, SQL Server would have inserted an uniquifier as part of the clustered index definition. Separating the clustered index and primary key allows us to not have to re-define any Foreign Keys and also allows less complicated joins.
If we examine index sizes again we get
| Schema | Table | Index | Used in KB | Reserved In KB | Rows |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_rowguid | 43,648 | 44,168 | 1,290,065 |
| Sales | SalesOrderHeaderBig | AK_SalesOrderHeaderBig_SalesOrderNumber | 49,336 | 49,928 | 1,290,065 |
| Sales | SalesOrderHeaderBig | CIX_SalesOrderHeaderBig_OrderDateSalesOrderID | 238,904 | 239,496 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_CustomerID | 28,280 | 28,872 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_OrderDate | 19,312 | 20,104 | 1,290,065 |
| Sales | SalesOrderHeaderBig | IX_SalesOrderHeaderBig_SalesPersonID | 28,168 | 28,232 | 1,290,065 |
| Sales | SalesOrderHeaderBig | PK_SalesOrderHeaderBig_SalesOrderID | 23,152 | 23,752 | 1,290,065 |
| Sales | SalesOrderHeaderBig | Total: | 430,800 | 434,552 | 1,290,065 |
Figure 14: Index Size with revised clustered index and primary key
Since the nonclustered index on OrderDate is not really needed anymore the total size of the table with indexes is almost the same as the original indexes. Now let’s look at performance of the first query
 Figure 15: Query 1 Plan with new Clustered Index and Primary Key
Figure 15: Query 1 Plan with new Clustered Index and Primary Key
with logical reads = 584 and cpu = 16ms. Query plan cost is now 4.29938.
The optimizer is still asking for the covering index as before, but now instead of a Clustered Index Scan we now have a Clustered Index Seek with significant performance over the original Clustered Index – almost a 90% performance improvement. If we were to add the suggested covering index we would see about a 10% increase in storage. If this query is only run a couple times a day, then having the perfect query may not be necessary – especially if storage is costly.
Running the second query yields:
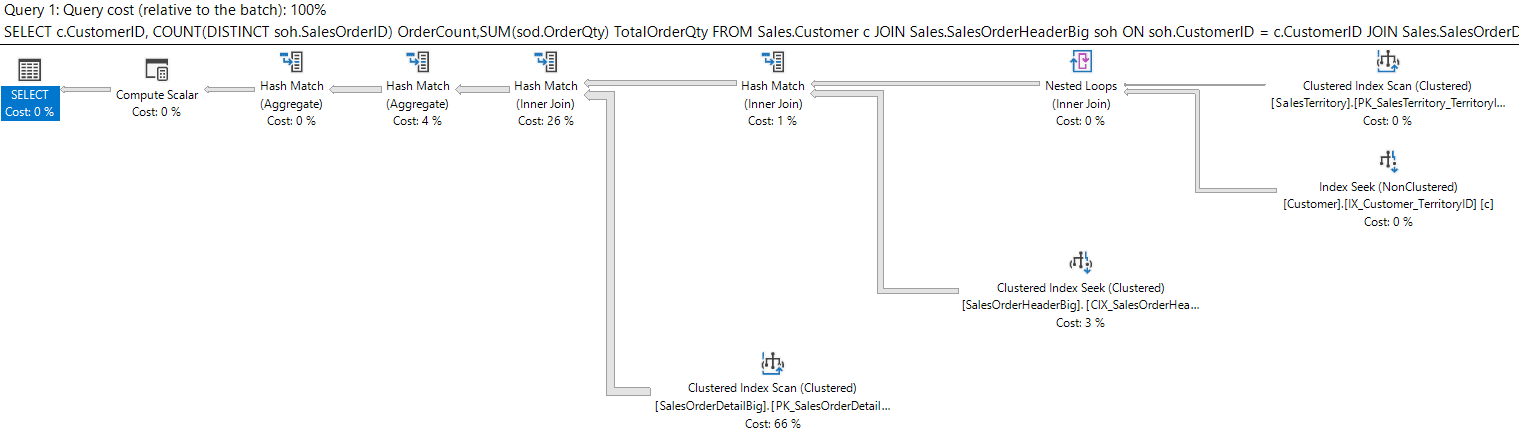 Figure 16: Query 2 with new Clustered Index and Primary Key
Figure 16: Query 2 with new Clustered Index and Primary Key
with now a clustered index seek on CIX_SalesOrderHeaderBig_OrderDateSalesOrderID having a query plan cost of 83.0901, 3595 logical reads, and cpu = 640ms.
Summary
Results of all the above combinations of queries and indexes are summarized in the chart below:
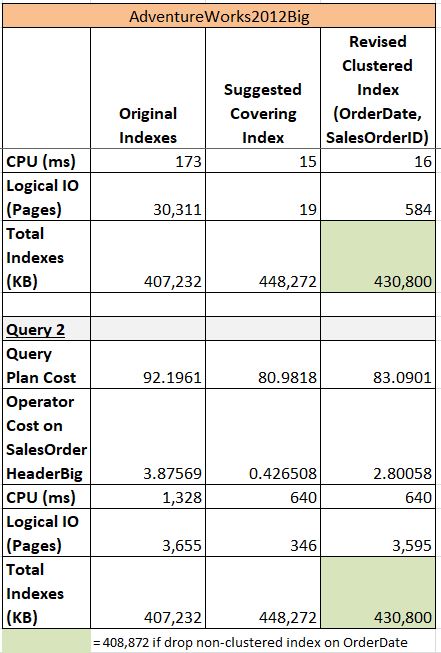
Figure 17: Performance Summary
Obviously the suggested covering nonclustered indexes have the best performance for their specific query. In many cases when I am trying to remove near-duplicate indexes I try to make several indexes (with same first column definition) into a single overall covering index. This requires some testing because making a covering index too large (width) increases the logical IOs (more pages to define this index) and may defeat a performance gain. If you examine closely the modified clustered index data (now based on OrderDate) its performance is nearly as good as the covering index performance. If there are other queries that use OrderDate in their WHERE clause then they also can benefit from the revised clustered index. So, when confronted with a suggested index, try it, but also consider its cost in storage, IO requests, maintenance, and perhaps a revised clustered index might just be better when looking at the big picture. In any case, as Microsoft always says, TEST, TEST, TEST!
Sometime being a good DBA requires a delicate balancing act – do I create the perfect nonclustered index (for a single query), or do I create a large covering index for several queries, or can I still get adequate performance (and less storage space) revising a clustered index. There is no correct answer here, and the decision has to be made in the context of the table in question usage. Please consider this article as a starting point not only for initial table architecture, but also for existing table architecture.
I look forward to discussion on this topic and welcome any and all comments.
Mike
