

While preparing for my SQL Saturday Salt Lake City presentation, Climbing the B-Tree, I ran into one of the “word of mouth” facts that the first column of an index should be highly selective, i.e., it should only point to one or a few rows. This is not always the case and I’ll show you why below.
In the past, I’ve said many, many times that when you define an index that the first column should be highly selective. I’ve continued with statements like Gender is not a good data field because it is not very selective. Either you have a M (male) or F (female) for data. But, let’s look at a very simple case where gender in the first column of an index definition can improve query performance.
Attached is a script (setup and test cases) that illustrates what can happen with and without a covering index and also how a redefinition of the covering index can change query performance. Lines 19-41 setup a dbo.Customer table in TempDB and populates it from the AdventureWorks2017 database.
With the Customer table as defined consider the following query (lines 97-106). I also turned on Include Actual Query Plan (Ctrl-M):
SET STATISTICS IO, TIME ON
GO
SELECT LastName,FirstName,DateAdded
FROM dbo.Customer
WHERE DateAdded >= '6/1/2019'
AND DateAdded < '7/1/2019'
AND Gender = 'F';
GO
SET STATISTICS IO, TIME OFF
GO359 rows are returned. The overall query plan cost is 0.171855 with 217 logical reads and a clustered index scan. The query plan looks like:
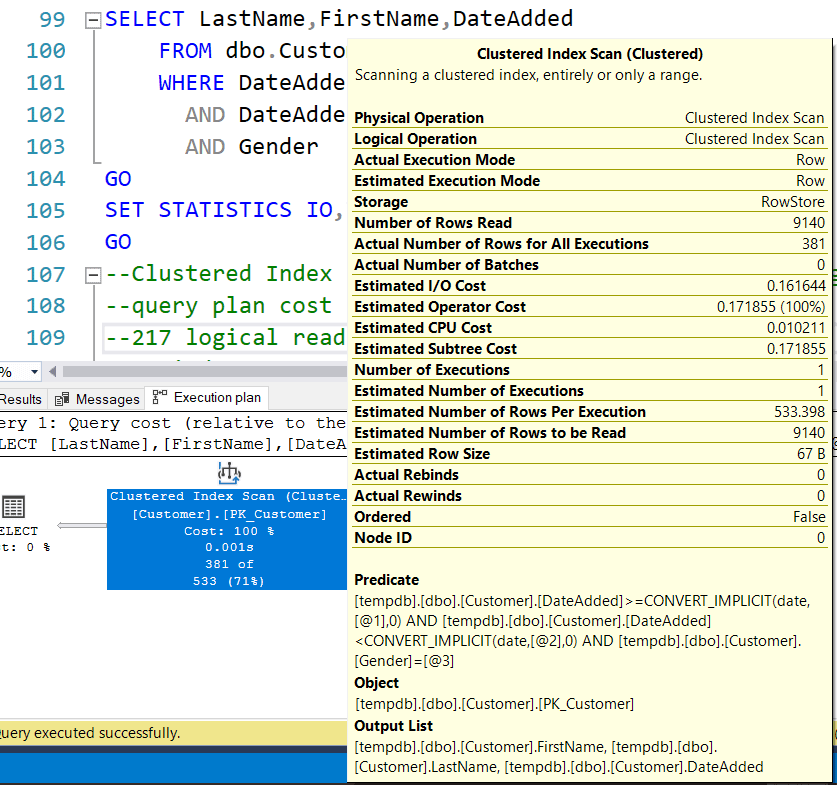
Note the query operator has only a predicate filter based on DateAdded and Gender. No index was recommended.
But looking at the query, we could add a covering index as described below. Note that I selected the date column first (as it is more selective than the Gender column).
CREATE INDEX IX_Customer_DateAddedGender ON dbo.Customer
(DateAdded ASC, Gender ASC)
INCLUDE (LastName,FirstName)
Now if we re-run the same query as above we still get the same result, but with a query cost of 0.005594 and 6 logical reads with a nonclustered index seek. The query plan now looks like
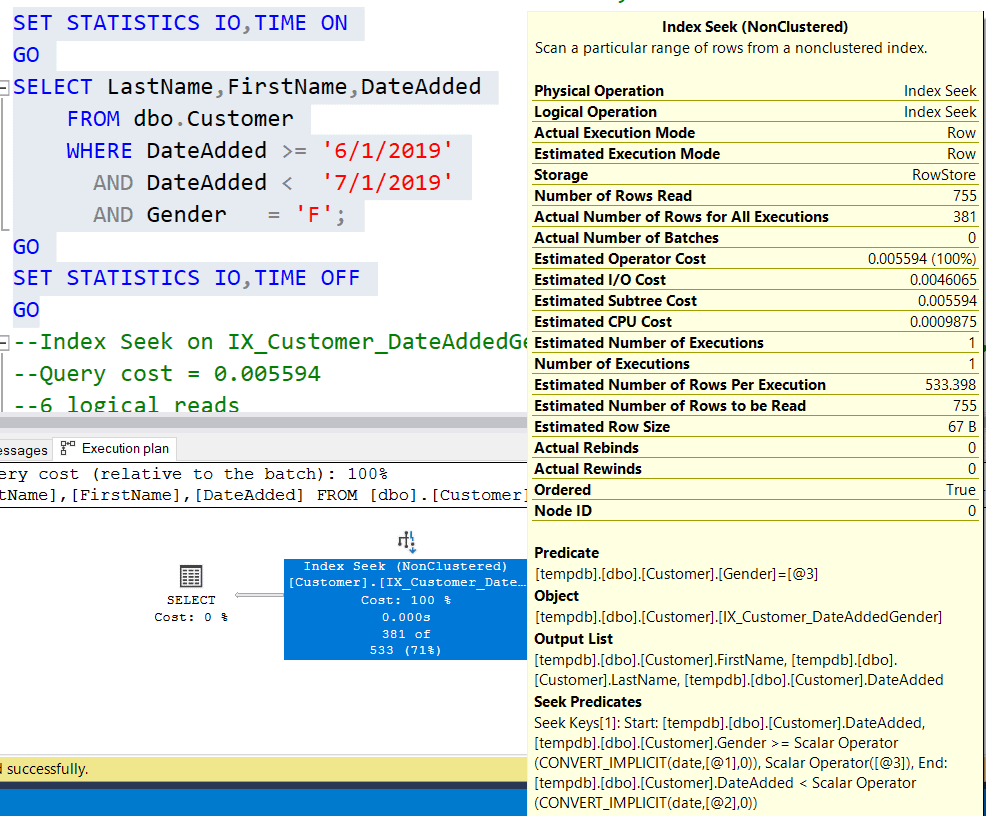
Now we have a Seek Predicate on DateAdded and a Predicate filter on Gender with a much-improved query cost (and less logical reads).
But we know the optimizer can take advantage of row searches in ascending or descending order. Let's redefine the covering index as shown below:
DROP INDEX IX_Customer_DateAddedGender ON dbo.Customer
CREATE INDEX IX_Customer_GenderDateAdded ON dbo.Customer
(Gender ASC, DateAdded ASC)
INCLUDE (LastName,FirstName)
And re-running the original query with this new index we get a query cost of 0.0053502 (slightly lower than the previous query), 4 logical reads, and a new nonclustered index seek. If we look at the query plan:
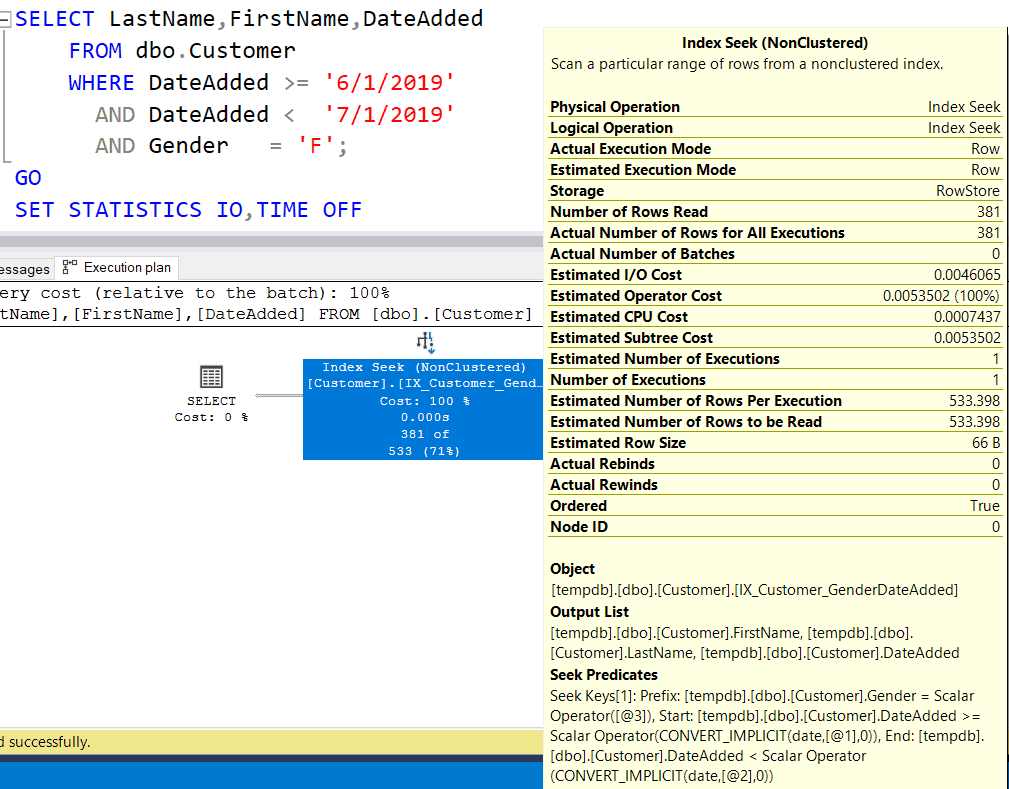
We now have both Gender and DateAdded in the Seek Predicate which most likely caused the slightly lower query cost.
If you think about the third query it has Gender has the first column and DateAdded as the second. In the Seek Predicate, all the Female rows are grouped together and the DateAdded column is in ascending sequence. Obviously this makes it easier for the query optimizer to go straight to the applicable rows with only one pass rather than two and in the original nonclustered index based on (DateAdded, Gender).
Summary
The above case is a very trivial example, but highly indicative of how column definition can affect query performance. The Customer table in this example is slightly less than 10,000 rows. A much bigger table with the proper indexes might make a bigger performance difference in a production environment. I hope this article gives you cause to think and thinking will hopefully get us through this pandemic.
