

In the article, Keeping Fact Tables Online while Loading via Partition Switching1, we discussed that for very large fact tables where each partition is very large, it is not practical to load partitions completely. Hence for these tables, you would want to switch only the partitions which are expected to receive new data to a secondary table, load the new data in the required partitions in the secondary table and switch the partition back to the main table (fig 1). In this article we would discuss how this can be implemented in SSIS.
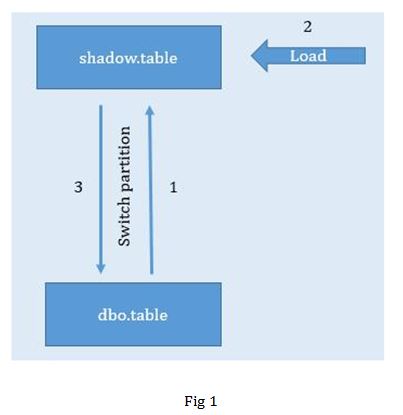
I have created 2 target tables - dbo.TGT_tablename_tbl and shadow.TGT_tablename_tbl in dbo and shadow schema respectively (query attached). dbo.TGT_swap_tbl is the primary fact table used for reporting purposes. Table in shadow schema is empty at the start of the process and has a same structure as the primary table in the dbo schema.
The process in fig 1 was implemented in SSIS as follows:
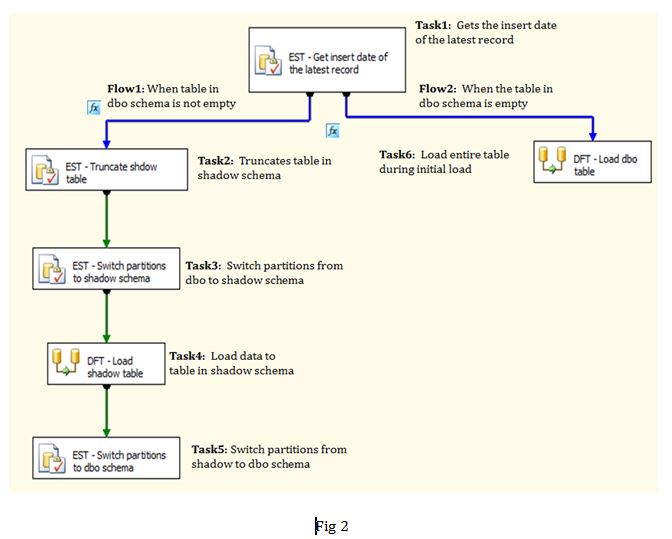
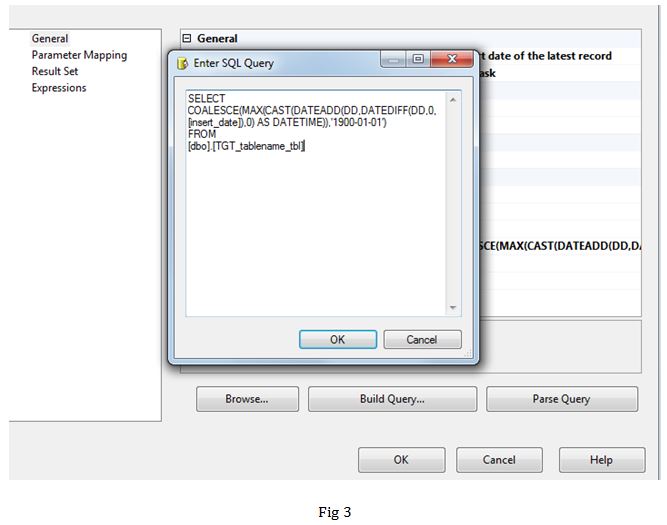
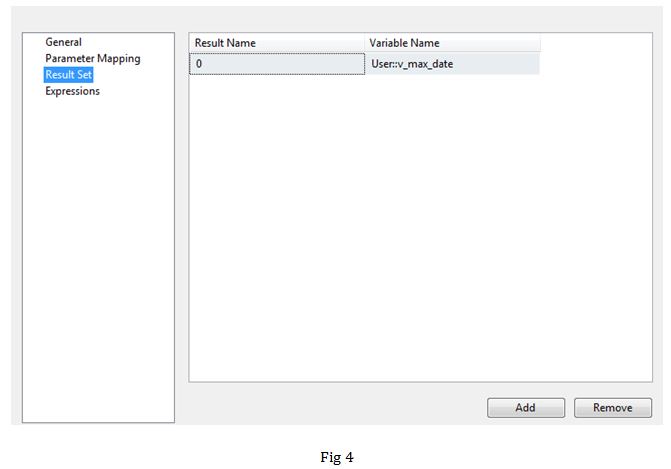
Task1: Here we get the latest insert date from the target table (fig 3). In this example we are assuming that source data does not get updated but only new data is added. We are hence using maximum date from the target table to set variable v_max_date (fig 4) in order to build a query that extracts data post this date.
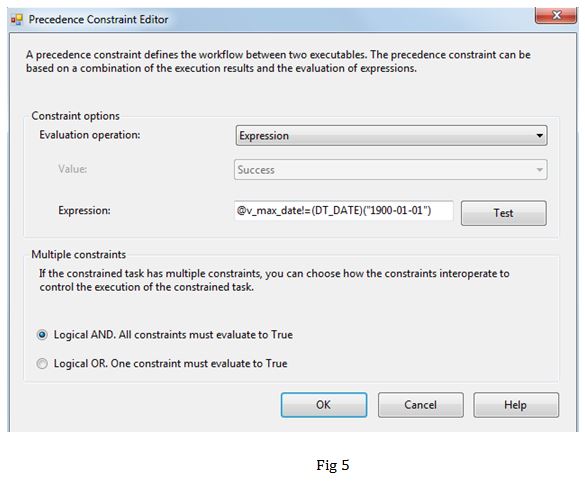
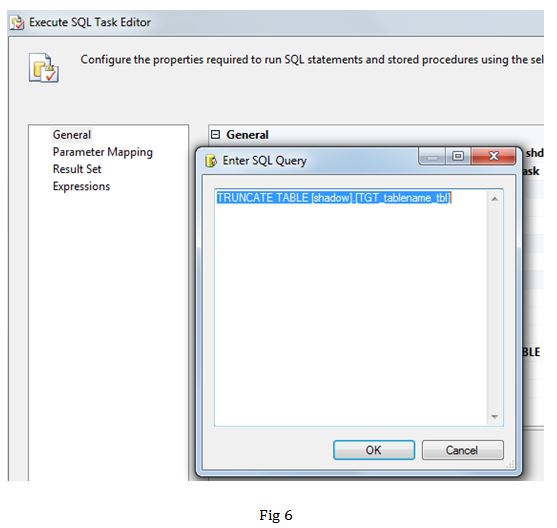
Task2: This Execute SQL Task is executed, when the target table is not empty. The precedence constraint set in Flow 1 evaluates the v_max_date variable (fig 5). In task 2, we are ensuring that the table in shadow schema is empty, by truncating it (fig 6).
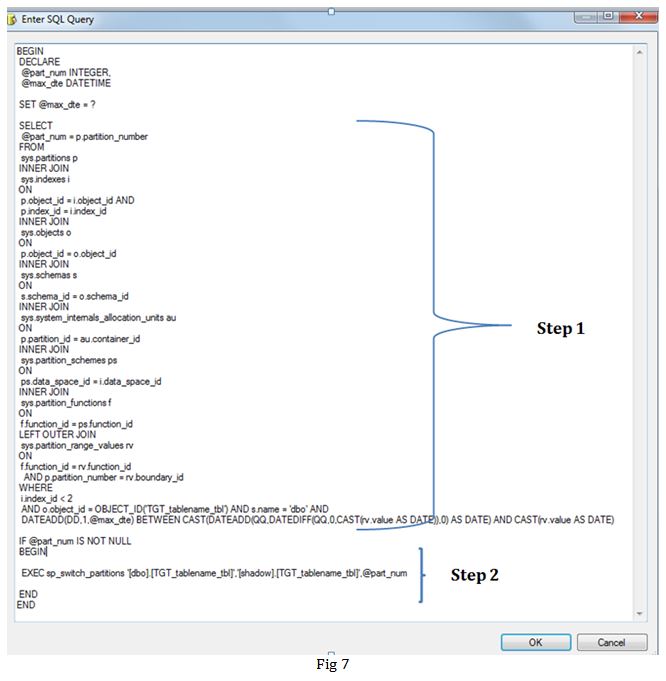
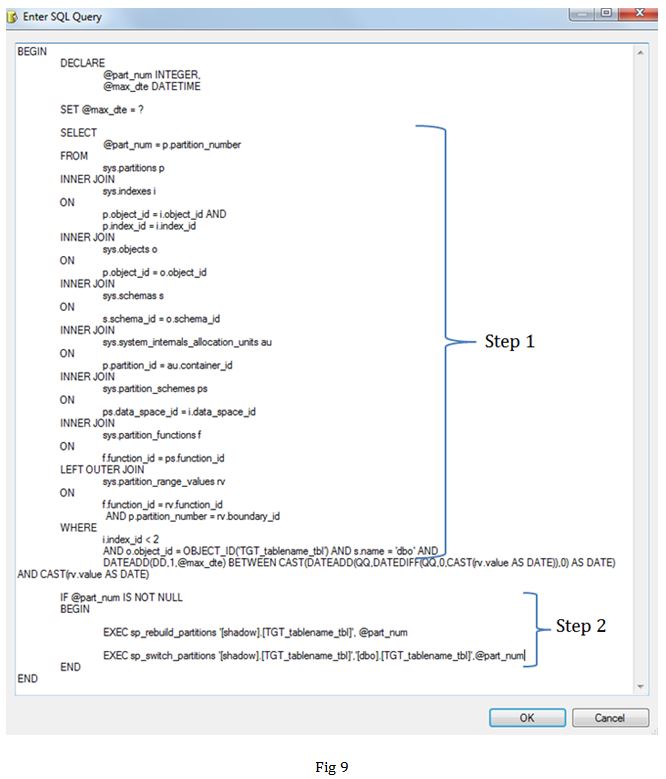
Task 3: In this Execute SQL task, we are switching partition out from dbo schema to shadow schema (step 2). As you can see that in step 1 we are getting the partition number of the partition based on the variable v_max_date. By only pulling in the required partitions in shadow schema, we are only bringing in the data for the partition associated with new rows and keeping historical data intact in the primary table.
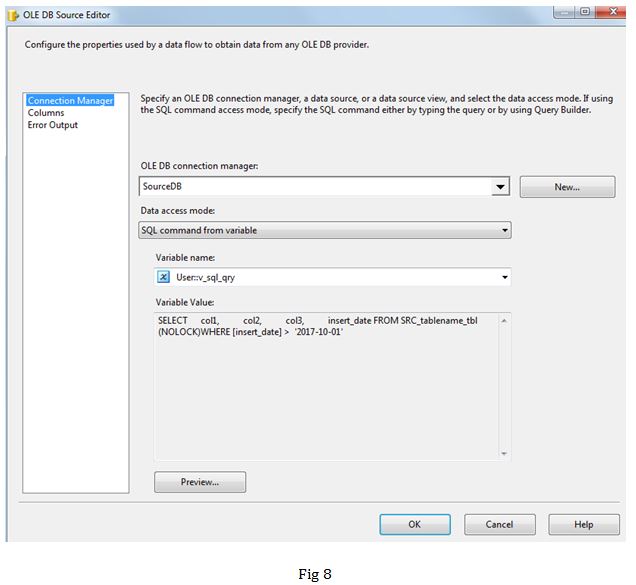
Task 4: In this data flow task, we are pulling the incremental data based on v_max_date and loading it into table in shadow schema. As you can see we are constructing the query dynamically through a v_sql_qry variable based on the value set for the v_max_date variable.
Task 5: Here we are switching partitions that have been loaded from table in shadow schema to dbo schema.
Task 6: This data flow task is executed when the target table in dbo schema is empty. This is specifically used during the initial load.
Conclusion:
In this approach, we are making only the latest partitions unavailable during the load process thereby keeping the primary table available for querying historical data. Once the data has been loaded for existing or new partitions, switching process is initiated which is very fast and restores the primary table to its original state.
References
1. http://www.sqlservercentral.com/articles/SQL+Server/149123/