

Fact tables are often the largest tables in any data warehouse environments as they capture data at the lowest grain required for downstream reporting or analytics purposes. As these tables often hold terabytes or petabytes of data, loading them is often very tricky as the process consumes significant memory and CPU cycles, which degrades the performance of ad-hoc queries being run on them in parallel.
In order to circumvent this issue, most of the data loads into the fact table are scheduled to run overnight or during times when there are few users accessing the data. However, often there are times when either the fact loads take overly long to complete or some glitch causes the fact load to fail, leaving the data in an inconsistent state. This might have a significant impact on the business users who are heavily dependent on the data warehouse for BAU (Business As Usual) reporting. While a restore of the database based on an incremental daily backup might restore the database to its original state, it would also overwrite the data for other loads that were able to finish successfully. It is thus imperative to ensure that the fact tables are always available for consumption during working hours and hence have a minimal downtime or loading window in order to impact the downstream applications.
In our environment, we had 3 types of fact tables based on their size:
- Small (<1,000,000 rows)
- Medium to Large (1,000,000 – 100,000,000 rows) – Tables were partitioned with each partition containing not more than 10 M rows
- Very Large (100,000,000 + rows) - Tables were partitioned with each partition containing more than 10 M rows
In order to ensure that there was minimum downtime or minimum loading window, we used following three approaches:
Schema Swapping
This approach was used for smaller fact tables that were loaded from scratch every time. In this approach, we utilized 3 schemas – dbo (default), swap and shadow. An empty copy of the table was created in the shadow schema. The table in the dbo schema was the one being used by downstream applications. We loaded the table in the shadow schema first. Once the table was loaded, we transferred the table from the dbo schema to the swap schema. This was followed by swapping the table from the shadow schema to the dbo schema. Finally, we swapped the table from the swap schema to the shadow schema and truncated the table in the shadow schema (refer fig 1).
The benefit of using this approach was that the data in the dbo table was available during the data load process. Once the table in the shadow schema was loaded, schema swap was initiated by running the following queries:
ALTER SCHEMA swap TRANSFER dbo.table; ALTER SCHEMA dbo TRANSFER shadow.table; ALTER SCHEMA shadow TRANSFER swap.table;
Schema swapping is apparently a very quick process as it just requires a metadata change in relation to the table being swapped across schemas. Hence the fact table was offline for a very short time thereby minimally impacting the downstream process.
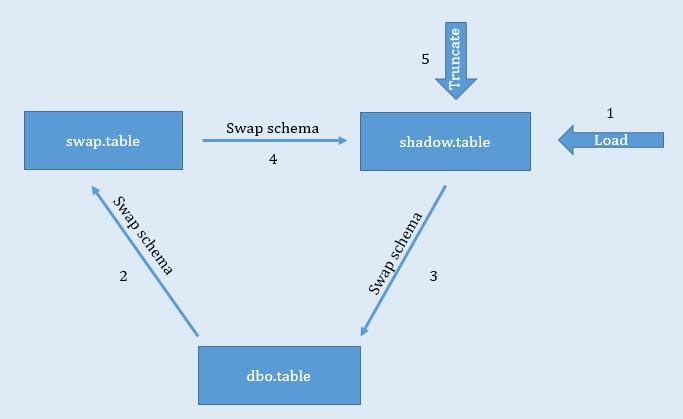
Fig 1
Note: In the case of tables containing columnstore indexes, truncate can be replaced with delete. However, the index will have to be disabled before DML operations and then enabled at the end.
Partition Switching – Complete partition reload
This was applied for fairly large fact tables which were loaded incrementally. Similar to the first approach, an empty copy of the table was created in the shadow and swap schemas. Prior to load, partitions were identified that needed to be updated. Once these partitions were identified, data pertaining to only those partitions was loaded in the table in the shadow schema. Once the data was loaded, the respective partitions were switched from the dbo schema to the swap schema followed by switching from the shadow schema to the dbo schema. Finally, data in the swap table was truncated (refer fig 2).
Same as the first approach, data in the table located in the dbo schema was available during the load process. Once the data was loaded into the shadow schema table, partition switching ensured that the data was available in the table located in the dbo schema within a very short time. This is because partition switching is a very light operation as it just requires a metadata change for the partitions being switched. Thus partition switching approach ensured that there was minimal downtime during the load process.
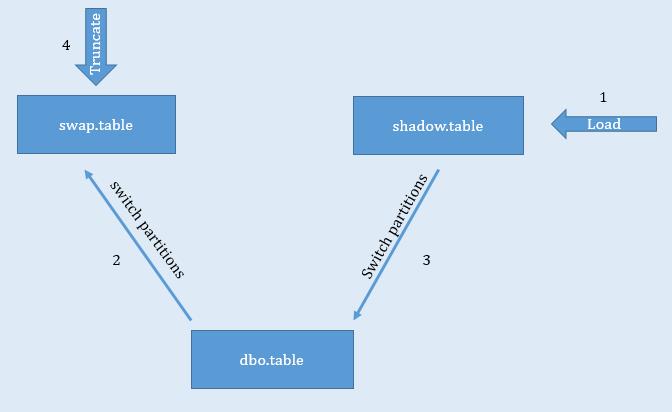
Fig 2
Note: In a case of tables containing columnstore indexes, truncate can be replaced with delete. However, the index will have to be disabled before DML operations and then enabled at the end.
Partition Switching – Incremental Partition Load
This approach was employed for very large fact tables where each partition was sufficiently large. Hence partition reload was not an option for such tables. In this approach, empty copy of the table was created in the shadow schema. Prior to load, partitions were identified which needed to be updated with additional rows. Once these partitions were identified, they were switched from the table in the dbo schema to the shadow schema. Incremental data was then loaded into the table in the shadow schema followed by the switching back of the partitions from the shadow schema to the dbo schema (fig 3).
In this approach, it is apparent that the window during which the table might be offline is comparatively large. However as only new data is being loaded based on the data populated in the table in the shadow schema, the process is comparatively fast and hence the offline window comparatively shorter.
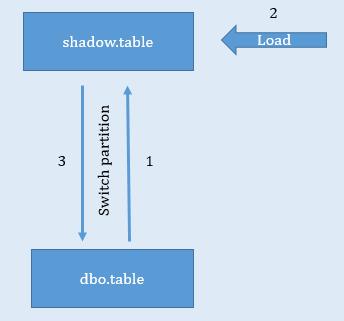
Fig 3
Note: Columnstore indexes will have to be disabled before DML operations and then enabled at the end.
