

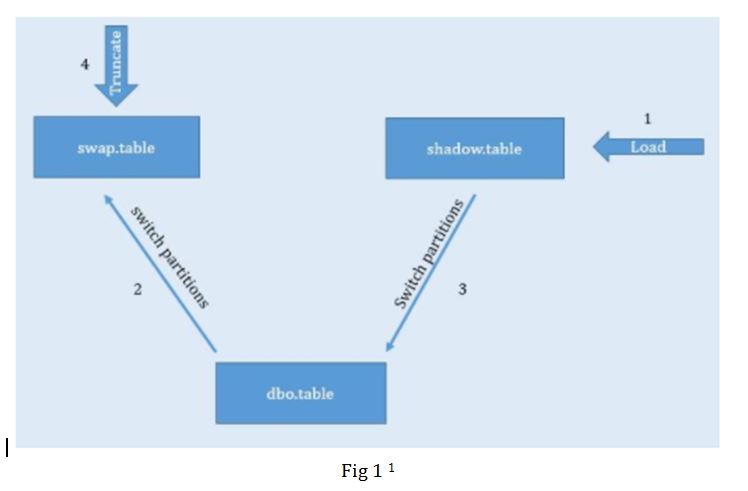
This is a follow up article from Keeping Fact Tables Online while Loading via Partition Switching, where I had discussed different ways of keeping fact tables online. In the second approach discussed in the article (Fig 1), I suggested that partition switching could be used to keep the data in the primary table (in dbo schema) online while data was being loaded into a secondary table (in shadow schema) in the background. In this article, we look at the specific approach in more detail.
In my example, I have created 3 tables as shown above – dbo.TGT_tablename_tbl, swap.TGT_tablename_tbl and shadow.TGT_tablename_tbl. The tables in the dbo and shadow schema are partitioned on a date field which is part of a clustered index on each of the tables. Each of the clusters is configured to hold quarterly data. Query for the partition function and partition scheme is attached.
I have used the following steps to achieve the incremental load:
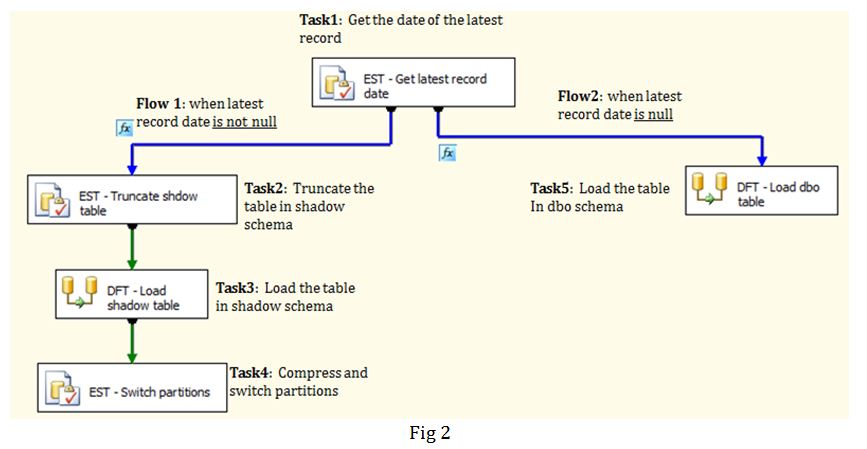
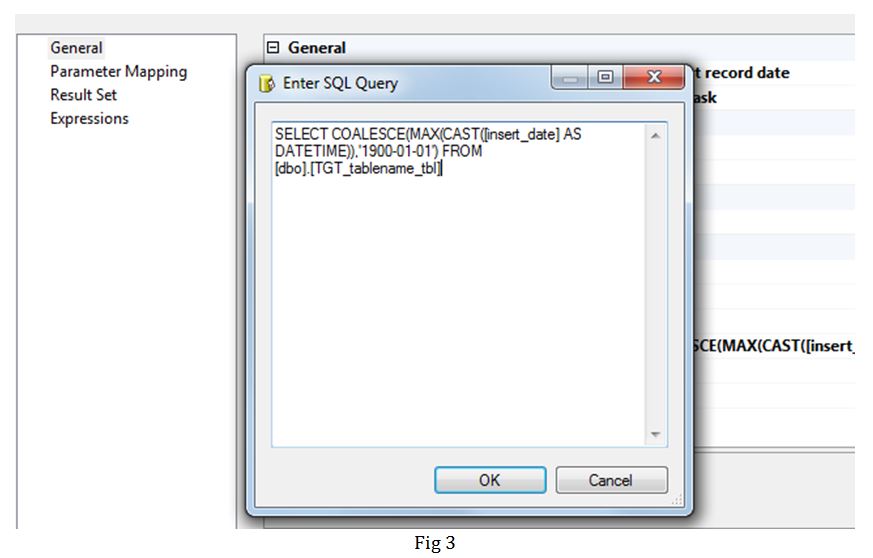
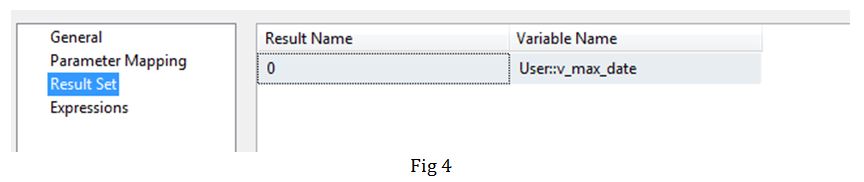
Task 1: In this step, we get the insert date of the latest record using an Execute SQL Task (Fig 3). Here we are defaulting the value to 1900-01-01 in place of NULL. This value is then passed on to a variable v_max_date in the Result Set section (Fig 4).
If the source table is empty, tasks 2 – 4 are run else tasks 5 is executed. Flow 1 and Flow 2 contain expressions to evaluate whether the variable v_max_date is equal to 1900-01-01 or not. Fig 5 gives an example of the expression used in the Precedence Constraint Editor.

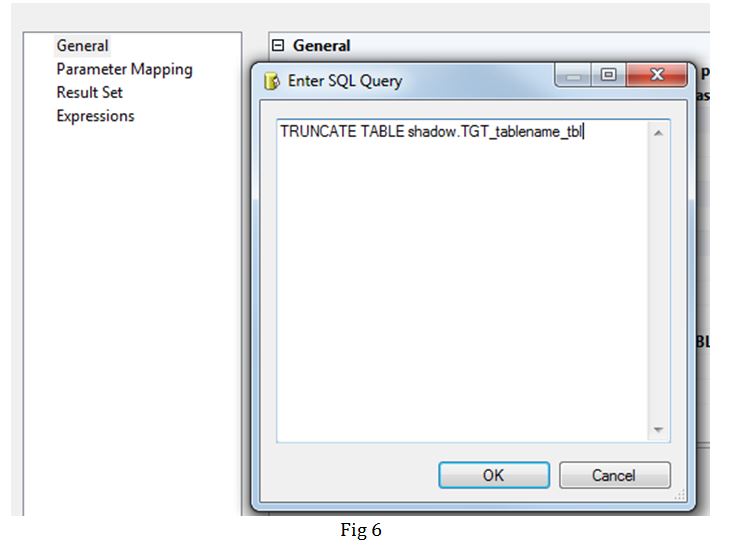
Task 2: Execute SQL Task has been used to truncate the secondary partitioned table.
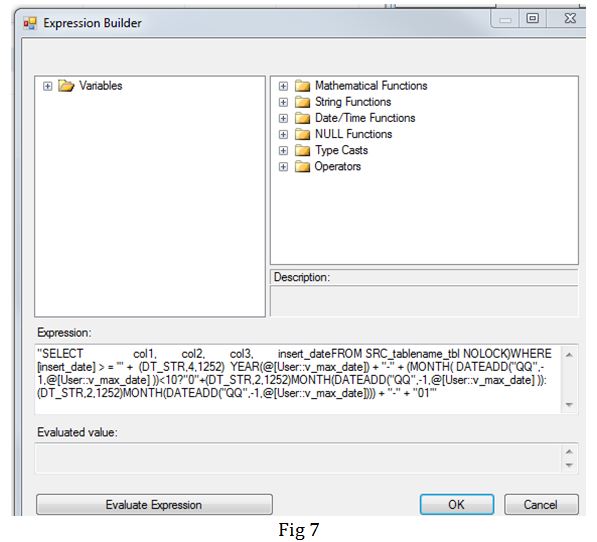
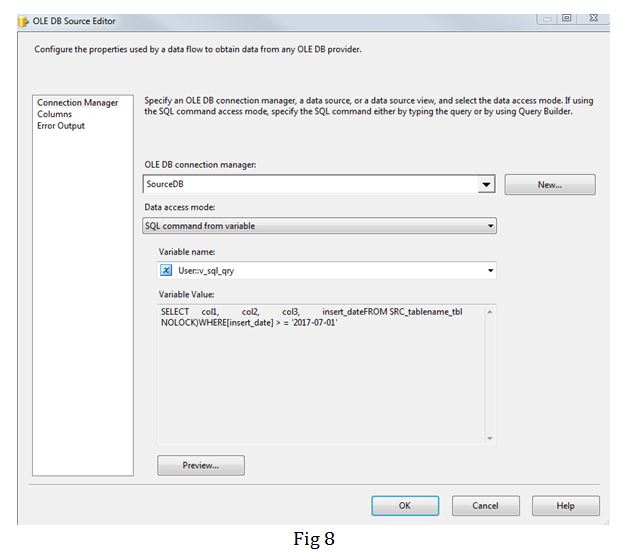
Task 3: I use the v_max_date variable to dynamically construct a SQL query (Fig 7) in a variable v_sql_query which is used in the OLE DB Source (Fig 8) in the data flow task. In the query I am only pulling in data for the latest and the previous quarters as I am confident that data prior to previous quarter is stable.
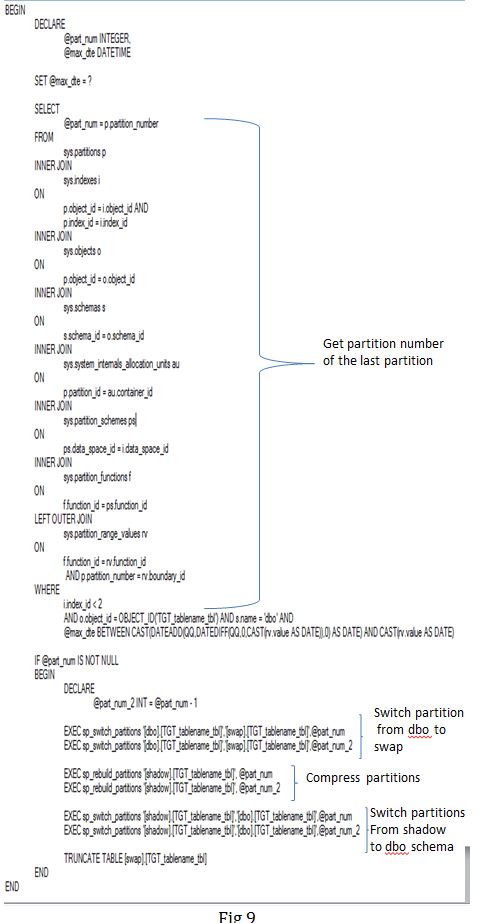
Task 4: In this task, I am using v_max_date variable to get the partition number from sys.partitions. The partition number is being used to switch partitions from dbo to swap schema and from further from shadow to dbo. This is as per the steps 2 and 3 mentioned in Fig 1 where I have used a stored procedure to accept the tablenames and partition number to perform the partition switching operation (query attached). We are also rebuilding the partitions and compressing them using row level compression using another stored procedure (query attached). Finally the table in swap schema is truncated.
Task 5: This task is executed when the target table is empty and hence will be executed during the initial load. Unlike task 3 where data is loaded in table in shadow schema, in task 5 the data from the source is loaded into the target table in the dbo schema.
Conclusion
We can see here that partitioning can help us achieve incremental load while keeping the primary table online. This is achieved by conducting the load process in the background followed by very fast partition switching process.
