Parse Data from a Field Containing Multiple Values using CROSS APPLY
-
Comments posted to this topic are about the item Parse Data from a Field Containing Multiple Values using CROSS APPLY
-
Nice article, but instead of using a slow multiline table value function, you should better use the well tested and fast inline table value function DelimitedSplit8K (except your lines are longer than 8k or have more than 100 columns or some other unusual stuff (but in this case you could even modify the 8k-function))
God is real, unless declared integer.
-
Hi, Stan!
Quite a not so rare problem - and up from SQL Server 2016/ databases with COMPATIBILITY_LEVEL = 130 there is the STRING_SPLIT() table value function...
...seems it does the trick as well!Regards!
Sebastian -
I kind of have an issue with this statement .
By definition, a flat file can only have one value per field per record. A delimited file, however, can have one or more fields that are further delimited by other delimiter characters.
It is plainly wrong.Flat File and Delimited File are definitions of how the data is stored within the file record.
not how data is stored within record fields.you can as easily have this in CSV as shown in OP
ProductId,ProductName,PartsList
1,Gizmo,463|914|771|281|418
2,Doohickey,422|4533,Gadget,32
3|724|449|882|591|715AND in flat file
ProductId________ProductName__________PartsList_________________
1________________Gizmo________________463|914|771|281|418_______
2________________Doohickey____________422|453___________________
3________________Gadget_______________724|449|882|591|715_______same data in different file type.
the file type does not define data with in.
what defines data with is the origin of the file. as in if a file comes out of an IBM mainframe type machine, it is by definition a flat file. but the data in it may be stacked in such a way that a field may contain a list of delimited values.just want to point out that the assumption is wrong.
PS >> had worked in a place where all data have been shuffled from the AS/400 machine in a flat files and needed a lot of manipulation before it could even be used by any other systems in the place.
PPS>> I had formatted the second table with spaces as a fixed record length flat file, but spaces have been stripped by the site, so I used underscores to indicate space padding
- SFlucke - Monday, October 30, 2017 2:27 AM
Be aware that STRING_SPLIT() has several problems.
1. If you pass it a NULL, it returns no rows... not even a NULL. This is atypical behavior for most string functions.
2. The function does not return the ordinal position of the element being split out. That also means...
3. There is no guarantee of sort order.If none of that is a concern to you then, yes, STRING_SPLIT() is a handy and fast function. I don't ever use it because those 3 shortcomings always matter in the things I do.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - vl1969-734655 - Monday, October 30, 2017 5:54 AM
I agree. A "Flat File" is simply a file that has no hierarchy to it. It may be "Fixed Field" or "Delimited" (typically, CSV) in nature. Of course, a non-flat file or "Hierarchical File" (for lack of a better term) may also be "Fixed Field" or "Delimited" and they don't have to be XML, EDI, or JSON. They could contain an "Adjacency List", "Hierarchical Path", or "Nested Sets" hierarchy, just to name a few.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Stan,
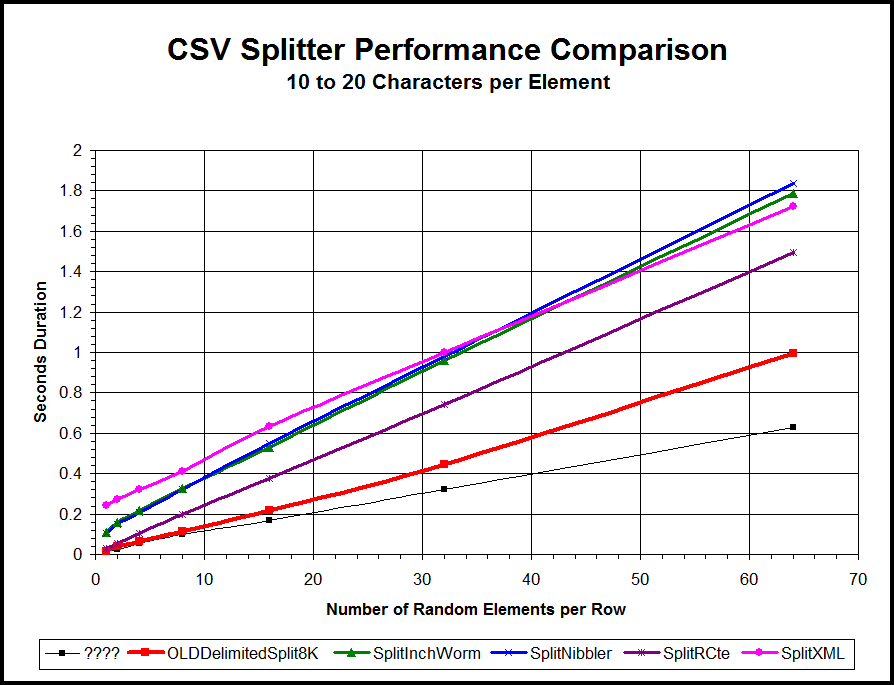
The string splitter that you have use is a "String Nibbler". Because it uses a WHILE loop, it's quite slow even for relatively small stuff. As previously suggested, please see the following article (someone else already posted a link to it) for a comparison between the "Nibbler", "Inch Worm", XML, and other splitters including two of the fastest... a CLR splitter and the DelimitedSplit8K splitter.
http://www.sqlservercentral.com/articles/Tally+Table/72993/
Here's a picture of the results of one of the many performance tests in that article. The Blue Line is the type of splitter that you've used. The Skinny Black line is the "new" DelimitedSplit8K function before and addition 10-20% was shaved off and it works in all versions of SQL Server from 2005 onward.

A good fellow by the name of Eirikur Eiriksson more recently modified it for use in 2012 and later and it doubled the speed. Here's the link for that code.
Shifting gears, I can't comment on the SSIS part of it but it does look like you took some good pains to write it. Thanks for taking the time to put it all together.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
First of all, I would hope never to receive data of this type in a single file like this. The data should be supplied in two files: One containing ProductID and ProductName, and a second with ProductID and partNumber - and really there should be a third one for PartNumber and partName.
However - if I did have to deal with data in such a format I would do this:
1) Load file using comma delimiters into a stage table.
2) export the parts list column into a file (with bcp or my custom .net exportr utility)
3) import the parts list into a second table having sufficient columns using pipe delimiter
4) Insert the parts list into a relational format by converting the columns into XML then shredding it
or with selects: select prodID, col1 union all select prodID, col2 where col2 is not NULL union all select prodID col3 where col3 is not NULL union all.... etc
5) insert the first two columns of the stage table into the Product table.The probability of survival is inversely proportional to the angle of arrival.
-
I had to deal with data containing a field with multiple values. It wasn't my choice. I managed to solve the problem. I just shared it in case it might help someone else.
-
just so it is here if some one needs it.
here some other options you can use
hope it helps someone in need.I found this function here on SQL Central. and modified a little to make it more flexible.
using this function
the processing call can be like
INSERT INTO dbo.Products (ProductId,PartNumber)
SELECT ProductId, a.item FROM dbo.StagingTable as t
CROSS APPLY [dbo].[fn_Split2](t.PartsList,'|') a
ORDER BY CAST(T.ProductId AS INT)
GOCompleatly omitting the need for Temp Table
the fn_Split returns table with 2 columns
"ItemNumber" an record Id and "Item" the value of split operation.
/*curtesy of Jeff Moden, 2011/05/02
Tally OH! An Improved SQL 8K “CSV Splitter” Function
"http://www.sqlservercentral.com/articles/Tally+Table/72993/"
-- changed @pString to be VARCHAR(MAX) instead of (8000)
-- change Final Substring to use DATALENGTH(@pString) and not hardcoded 8000
*/CREATE FUNCTION [dbo].[fn_Split2]
--===== Define I/O parameters
(@pString VARCHAR(MAX), @pDelimiter CHAR(1) = ',')
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
--===== "Inline" CTE Driven "Tally Table" produces values from 0 up to 10,000...-- enough to cover VARCHAR(8000)
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), --10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS (--==== This provides the "zero base" and limits the number of rows right up front
-- for both a performance gain and prevention of accidental "overruns"
-- if more raws are needed Add enouther select i.e. E5 and adjust this blockl to select from e5 instead of e4.
SELECT 0 UNION ALL
SELECT TOP (DATALENGTH(ISNULL(@pString,1))) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (--==== This returns N+1 (starting position of each "element" just once for each delimiter)
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@pString,t.N,1) = @pDelimiter OR t.N = 0)
)
--===== Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found.
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY s.N1),
Item = SUBSTRING(@pString,s.N1,ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,DATALENGTH(@pString)))
FROM cteStart s
;PS>> the OP function also can be called without the need for temptable
- Stan Kulp-439977 - Monday, October 30, 2017 1:29 PM
Absolutely understood. The function that I posted about will help you accomplish that task more quickly.
To be sure.... thank you again for taking the time to write an extensive article on what you did to solve a problem. My hat's off to you, good Sir.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - vl1969-734655 - Monday, October 30, 2017 5:54 AM
Or XL7 data, or X12 data or...
But, hey, you should've used commas instead of | for your value separators. I just love how people *still* default to comma-separated value text files. I'd rather get Excel files (protip: epplus.dll or npoi.dll make that excercise much easier). - corey lawson - Monday, October 30, 2017 8:04 PM
corey, first of all, not every projects uses .NET or excel.
second it is not always up to you what you get in the data file. BTW the data table I have in my post comes straight from OP blog.
so "|" was there. also it does not matter what you use, you pick the delimiter that works for you.
I usually try to pick delimiter that is not very common in a normal data. I do not like to work with comma separated files or tab separated files or even semicolon separated files ,because all this characters can and do exist within normal dataset.as for working with Excel, it works when/if you have the option to load the proper libraries on the machine you run thing from.
when you need to do some automation you can not always control how things will be used.
I have some Powershell projects where I need to run scripts manually and they wold only run under from my PC
the scripts are on the network, permissions are set to proper users and such. the target machines should have everything the script needs, yet it errors out with non-descript error on everything but my PC. - corey lawson - Monday, October 30, 2017 8:04 PM
Heh... I wouldn't wish what most people call "CSV" on my worst enemy. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I totally with you on this one 🙂 , even though I did my own share of crazy file manipulations.

Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply