

We’ve always been told that Bad Page Splits hurt performance, but I have seen no testing results to support this. In this paper, we will discuss a testing sequence that measures IOs and CPU for inserts at the end of an index (good page splits) and another sequence where a row insert is made into an already filled data page (fill factor = 100) that causes what is called a bad page split.
This series of tests is not meant to cover all instances of bad page splits, but to at least indicate a trend of what can happen when bad page splits occur. The magnitudes of these results are not to be used globally but just to indicate trends.
Page Split Discussion
Let’s discuss what constitutes a good page split and a bad page split. Data can be added row by row to a page until it is filled (there is not enough space within the page for another row to be added). When there is not enough space within the page a new page is added to the index. Normally it is the next page in the extent, but if the extent is filled then a new extent (8 pages) is allocated to the index. Fill Factor is not a player here other than it sets aside space for additional rows after an index rebuild.

Figure 1: Index data page
Consider Figure 2 below. This shows an index with a number of pages. If this index is defined with an identity column as index first column, then the leaf level pages would contain the identity values from left to right as they increase.
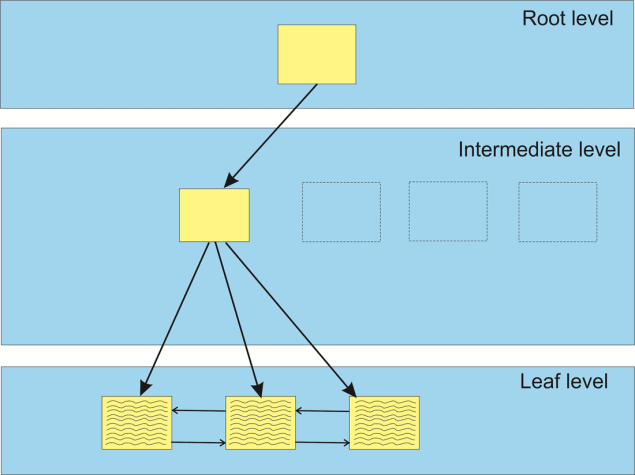
Figure 2: Partial view of B-tree before adding row
If the far-right data page is full the next row inserted has to go to a new page, as shown in Figure 3. SQL Server assigns the next page available in the current extent, and if no pages are available, it then assigns a page in the next available extent.
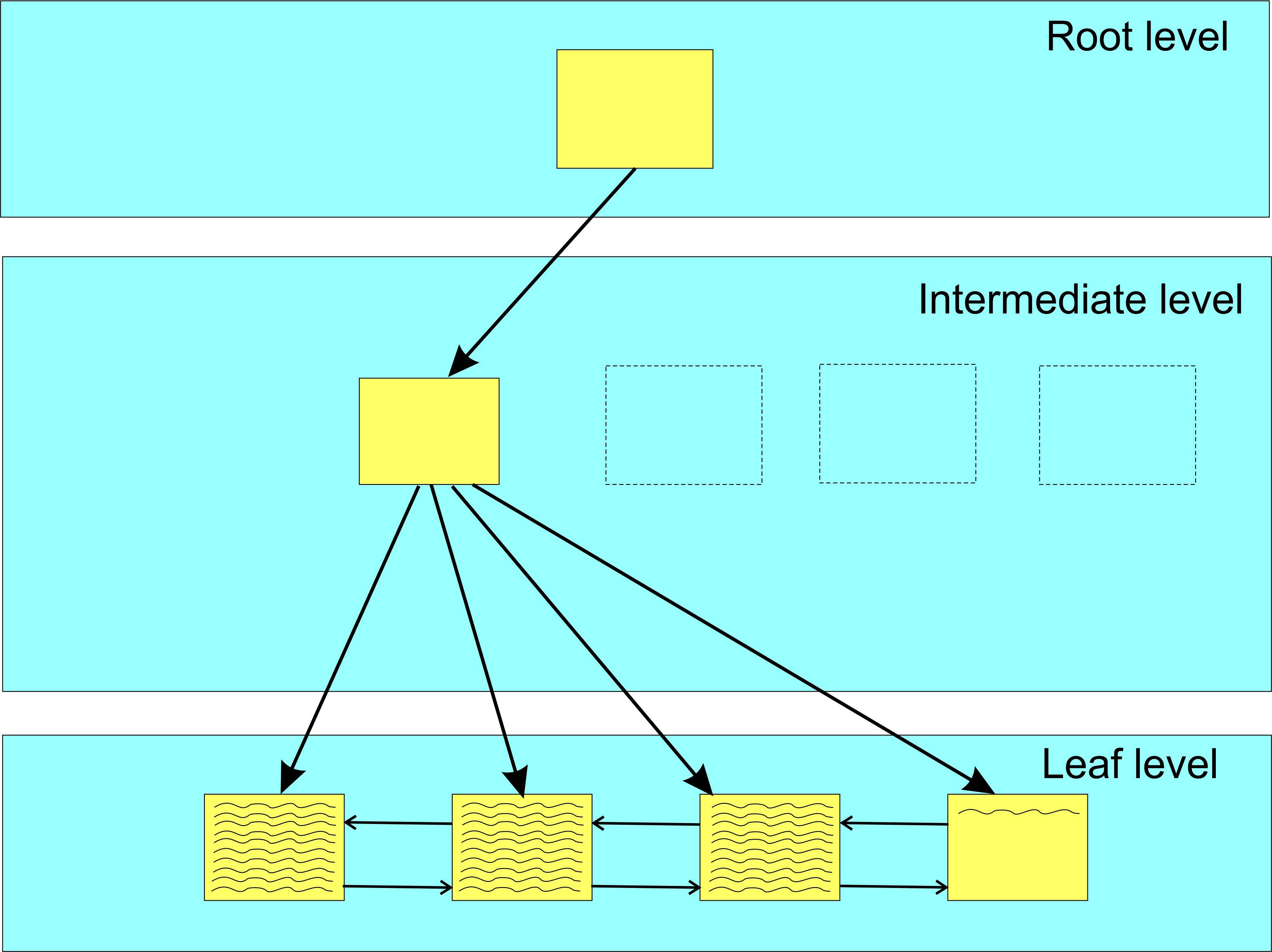
Figure 3: B-tree after adding row to new page
This is called a good page split as all the pages are ordered by their extents.
Now if a row is to be inserted into an index page completely filled a new page must be inserted from another extent to keep the data ordered, as shown in Figure 4. In this instance, half of the old page’s rows are inserted into the new page along with the new row and then pointers between the pages and the b-tree must be re-aligned.
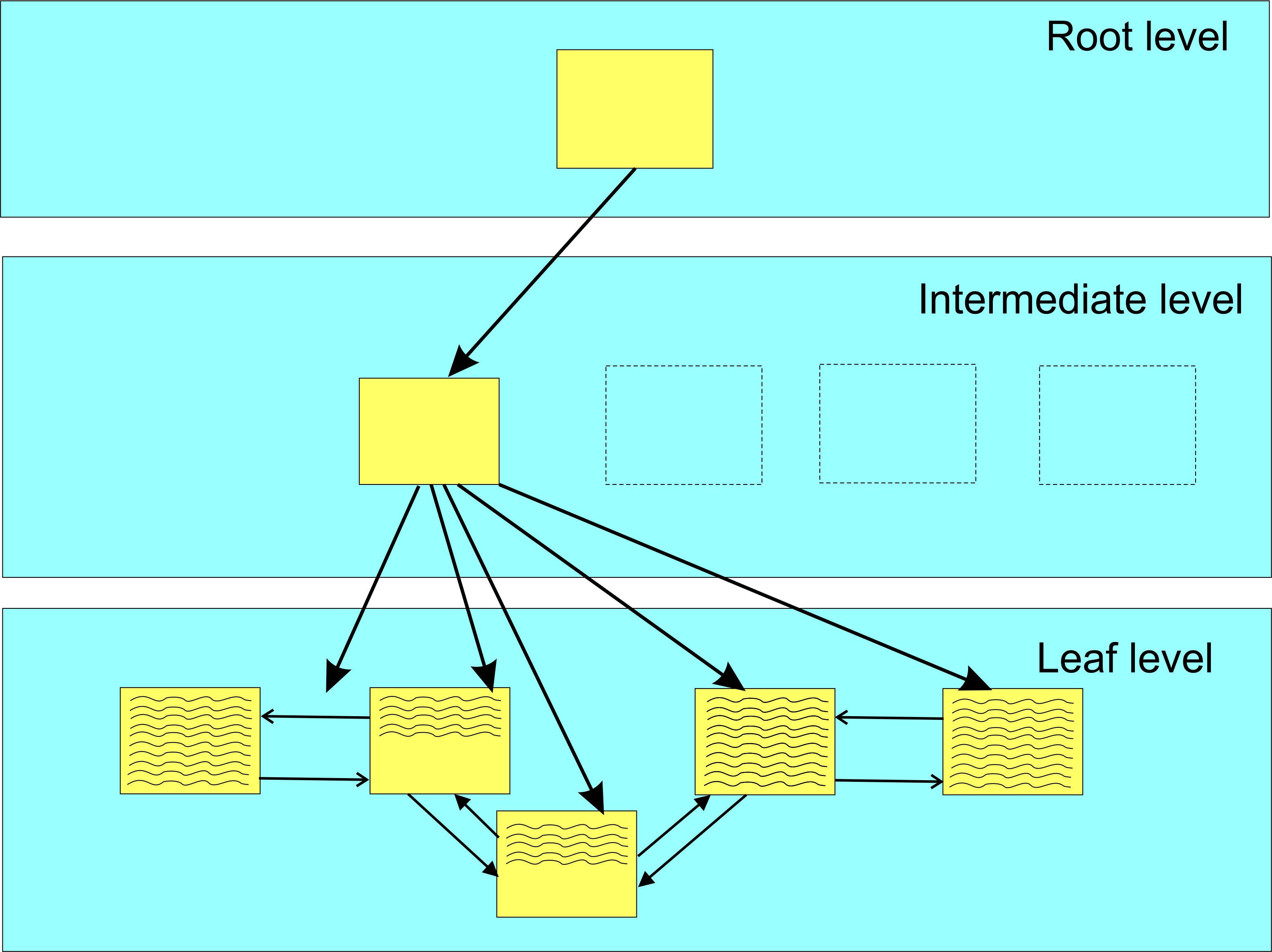
Figure 4: Bad Page Split Example
All this causes additional IOs and all these operations are logged. This is called a bad page split because of the out of sequence index pages as well as the additional IOs and logging. Not only does this cause an immediate performance decrement, but the out of order pages may cause additional IOs in index range seeks and also result in additional disk space because of the half-empty index pages. An index rebuild will cause a re-ordering of the data and eliminates bad page splits.
Testing Methodology
The test described below use a modified version of AdventureWorks2017 that I call AdventureWorks2017big. It is essentially the original database with two additional tables: Sales.SalesOrderHeaderBig and Sales.SalesOrderDetailBig, using a slightly modified script downloaded from Jonathan Kehayias. This increased the size of Sales.SalesOrderHeaderBig from 31,465 rows to 1,290,065 and Sales.SalesOrderDetailBig from 121,317 rows to 4,852,680. This was necessary for the test to give some reasonable statistics IO and Time values.
The database was upgraded to compatibility 15.0 (SQL Server 2019); however, I’ve noticed almost no change in results from SQL2014 to SQL2019.
To isolate these tests I created a new database “Test” and inserted the data from Adventurework2017Big.Sales.SalesOrderDetail into a mirror table (without the nonclustered indexes) Test.dbo.SalesOrderDetail. The script for the testing is attached. Testing was accomplished on a Lenovo ThinkPad P50 with Intel i7-6700HQ, 4 Cores, 64gb ram with 1 TB SSD and 1 TB spinning drive.
My approach was to run two independent tests. The first was to append data (52,747 rows; number derived from test 2) to existing clustered index measuring cpu, IOs, and bad page splits (if any). After extensive testing I learned that the original data insert into dbo.SalesOrderDetailBig needed an index rebuild to stabilize the subsequent measured data insert. Data was collected via DMV queries and DBCC SHOWCONTIG. Bad Page Splits were collected from an extended event as defined by a script from Jonathan Kehayias' Extended Events Blog.
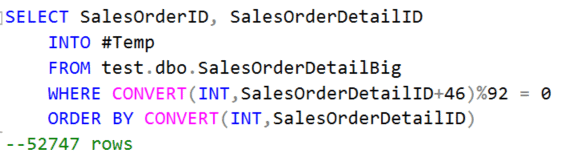
Since the fill factor on dbo.SalesOrderDetail was already 100%, I just needed to insert a new row within every page of data within the clustered index for Test 2. Since there was an average of about 92 data rows/page I used the following query to generate what rows needed to be inserted. To make both insert queries exactly alike and to minimize data manipulation I changed the SalesOrderDetailID column (clustered index column) to varchar(50) and for the inserted row appended the letter ‘A’ to SalesOrderDetailID. This kept the query plans the same between the two tests.
Results
Raw data results listed below:
| Page Count | RowCount | Logical reads SalesOrderDetailBig | CPU | Bad Page Split | Page Allocation Caused By Page Split | ||
| End of Table Insert | Before | 52,984 | 4,852,680 | NULL | |||
| (Test 1) | After Insert | 53,591 | 4,905,427 | 176,764 | 703 | 3 | 172 |
| Mid-Page Insert | Before | 52,984 | 4,852,680 | NULL | |||
| (Test 2) | After Insert | 97,851 | 4,905,427 | 437,417 | 2,453 | 44,868 | 340 |
Figure 5: Test Results
As the results indicate, the amount of rows after the data insert is the same, but the page count is much different (Test 2 has more than 44 thousand additional pages). If I now rebuild the dbo.SalesOrderDetailBig table after test 2 we get 53565 pages (nearly same as Test 1).
Looking at the difference in CPU between the two tests we get:
| Page Split Cost in ms |
| 0.035 |
While 25.6ms is a significant value for a single page split it only applies to this particular scenario. However, its magnitude does give credence that bad page splits may cause performance issues.
Now looking at the difference in Logical IOs for dbo.SalesOrderDetailBig table we get;
| Page Split Cost in IOs |
| 5.8 |
As above, the actual number is only indicative for this scenario, but the fact that almost six pages extra were read for each bad page split can also lead to a performance decrease.
Finally, let’s look at how the increase in pages for test 2 can affect a query. Consider the following query:
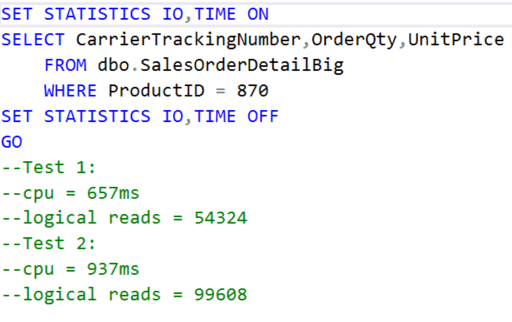
Note the significant increase in cpu and logical reads for test 2. If I rebuilt the clustered index for test 2 the cpu and logical IOs are equivalent.
These tests were conducted on the clustered index with no additional non-clustered indexes. If there had been supporting non-clustered indexes the magnitudes of the cpu and IO for each bad page split may have increased.
Conclusion
Obviously bad page splits not only can cause performance issues during the actual page split (increased IO and cpu), but also upon subsequent queries on that index before it is rebuilt. So, big question is what is the tradeoff for lowering fill factor to minimize page splits vs the growth in index size because of the reduced fill factor? This is not going to be answered here. However, you now should have some insight on the performance effects of bad page splits.
