

At times in our life we look back at the road not taken and wonder where it would have taken us. Would a crazy idea that came to us one night but was discarded with the dawn actually have worked?
With the recent republication of Soundex – Experiments with SQLCLR and the feedback received after publication I thought now would be the time to share the crazy idea that lead me to write those three articles.
Genesis of an idea
Back in 2010 I was a DBA and was approached by a solutions architect to discuss how to supply Apache Solr with product data from one of our SQL Server databases. Digging into the requirements revealed an application for which a simplified view can be represented by the diagram that follows.
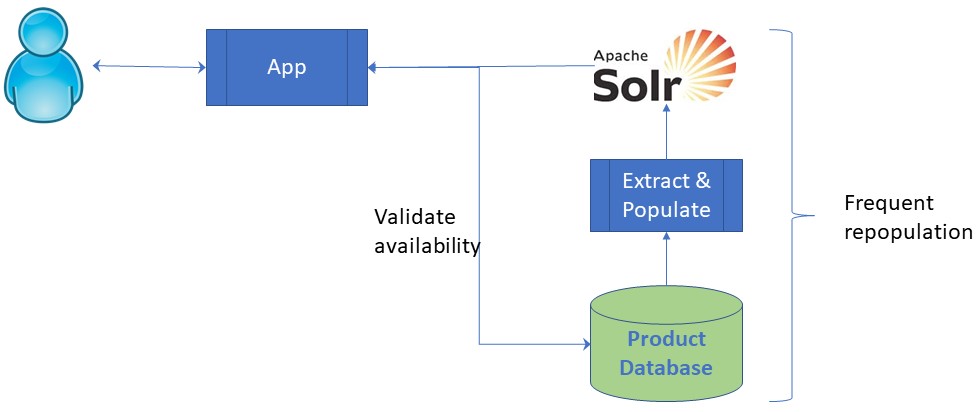
The nature of the products held and speed of change in the product set gave me cause for concern.
- At any one time there were a many ten if not hundreds of thousands of different products
- Products had short lifecycle, sometimes measured in hours with a strict expiry date and time
- Products had limited stock therefore amplifying the effect of rapidly expiration
- Only those items that were in stock and not expired should be shown to the customer
In short, we had a large, fast changing product set requiring frequent repopulation of the Apache Solr index. The application also has to check product availability for those products returned from the search. This had the potential to require hundreds of calls to the database. If a search returned 1,000 products, we would need to validate enough of them to present the shopper with a “page” of valid results.
I thought that SQL Server Full Text Search (MSFTS) would be a much safer solution requiring far less movement of data however the decision taken was to pursue the Apache Solr route. The solution satisfied business requirements but always meant that the database server was under more stress than it should have been.
Why was Apache Solr chosen over SQL Server Full Text Indexing?
At that time both technologies were an unknown quantity within the organisation. The opinion was that if search capability was required then a dedicated search technology should be chosen to support that capability and not an appendage to a database product.
There was also the view that, being open source, Apache Solr was a fast-evolving product whereas MSFTS was a stagnant part of the SQL Server platform.
What was the crazy idea and would it have worked?
I noticed that, even with Apache Solr, the terms the customers were using would not always provide a match to any products. Although the product existed the search would only be successful if the customer spelling matched that used in the product description.
What if I could get MSFTS to index the phonetic encoding of the words used to describe the product? Would I gain “sounds like” capability that could handle misspellings without compromising any of the other features in MSFTS?
In my Soundex – Experiments with SQLCLR article I built a function called LongPhonetic that accepted two arguments.
| # | Argument | Description |
| 1 | Enumeration selecting the phonetic algorithm | 0 = SOUNDEX (default) 1 = Refined SOUNDEX 2 = NYSIIS 3 = Daitch Mokotoff 4 = Metaphone 6 = Cologne Phonetic |
| 2 | String to encode | This can be any length and can be a word, sentence, paragraph of entire document. |
The return value would be a string where all words in the 2nd argument were turned into phonetic tokens. The difference between my implementation of the algorithm and the standard definition was that I did not truncate the phonetic tokens.
My first thought was to generate a shadow of the text columns I wanted to search but quickly discarded that idea for the following reasons:
- Increased storage requirements for the products
- Increased complexity for the application maintaining the products
- Increased complexity in the database
- Obscurity of the database content for developers
The approach I decided upon was to try and use the MSFTS thesaurus facility to store the valid phonetic tokens. If the application submitted a search term then I could use my LongPhonetic() function to generate the phonetic token for that search term and the thesaurus would do the rest of the heavy lifting.
Mind your language
MSFTS thesaurus files are held in the MSSQL/FTData folder within the SQL Server install location on on your server of workstation.

Thesaurus files are XML file whose name is a 3-letter language code preceded by the letters “ts”. The files for US English and British English are circled in red in the screen shot above as the distinction is important when setting up and configuring full text indexes.
You must establish what the default full-text language is for your server otherwise you won’t know which thesaurus file to edit.
EXEC sp_configure 'show advanced options', 1 ; RECONFIGURE; EXEC sp_configure 'default full-text language';
This will bring back a recordset similar to the one shown below with both config_value and run_value being lcid values.
| Name | minimum | maximum | config_value | run_value |
| default full-text language | 0 | 2147483647 | 1033 | 1033 |
We can see the LCID values for US and British English by running the following query
SELECT langid,lcid,name,alias FROM sys.syslanguages WHERE alias LIKE '%english%'
| langid | lcid | name | alias | Thesaurus file | |
| 0 | 1033 | us_english | English | tsenu.xml | |
| 23 | 2057 | British | British English | tseng.xml |
If I wanted to specify the default full-text language as British English then I would issue the following query.
EXEC sp_configure 'default full-text language',2057 RECONFIGURE;
Alternatively, I could be explicit in the language I wanted to use when creating a full-text index as shown below.
CREATE FULLTEXT INDEX ON dbo.DimProduct(ProductAlternateKey,EnglishProductName,EnglishProductDescription) KEY INDEX [PK_DimProduct_ProductKey] LANGUAGE [British English]
Setting up the experiment
In the AdventureworksDW2014 database I added 12 products representing 4 cycling jerseys in 3 sizes into the dbo.DimProduct table.
INSERT INTO dbo.DimProduct ( ProductAlternateKey, ProductSubcategoryKey, SizeUnitMeasureCode, EnglishProductName, SpanishProductName, FrenchProductName, StandardCost, FinishedGoodsFlag, Color ) VALUES ( 'XXJER1',21,'XL','Fuerteventura Wheelers','','',60.7,1,'MULTI'), ( 'XXJER2',21,'L','Fuerteventura Wheelers','','',60.7,1,'MULTI'), ( 'XXJER3',21,'M','Fuerteventura Wheelers','','',60.7,1,'MULTI') ( 'XXJER4',21,'XL','Caribbean Cycle Club','','',60.7,1,'MULTI'), ( 'XXJER5',21,'L','Caribbean Cycle Club','','',60.7,1,'MULTI'), ( 'XXJER6',21,'M','Caribbean Cycle Club','','',60.7,1,'MULTI') ( 'XXJER7',21,'XL','Llanberis Ascent Club','','',60.7,1,'MULTI'), ( 'XXJER8',21,'L','Llanberis Ascent Club','','',60.7,1,'MULTI'), ( 'XXJER9',21,'M','Llanberis Ascent Club','','',60.7,1,'MULTI') ( 'XXJER10',21,'XL','Loughborough Wheelers','','',60.7,1,'Red'), ( 'XXJER11',21,'L','Loughborough Wheelers','','',60.7,1,'Red'), ( 'XXJER12',21,'M','Loughborough Wheelers','','',60.7,1,'Red') GO
Fuerteventura, Caribbean, Llanberis and Loughborough being place names I know that people struggle to spell.
The next step was to create my full text index on dbo.DimProduct
Exec sp_fulltext_database 'enable' CREATE FULLTEXT CATALOG ft_PhoneticProduct AS DEFAULT; CREATE FULLTEXT INDEX ON dbo.DimProduct(ProductAlternateKey,EnglishProductName) KEY INDEX [PK_DimProduct_ProductKey] LANGUAGE [British English]
Before creating my full-text thesaurus I needed to know the phonetic token for those terms as produced by SELECT dbo.LongPhonetic(4,@SearchTerm)
| SearchTerm | PhoneticCode |
| Ascent | ASNT |
| Caribbean | KRBN |
| Fuerteventura | FRTFNTR |
| Llanberis | LNBRS |
| Loughborough | LFBRF |
| Wheelers | WLRS |
As established earlier, as I was explicit in specifying my full-text index as “British English” the thesaurus file I had to edit was tseng.xml.
The information I needed to edit the thesaurus file is in the Microsoft document “Configure and Manage Thesaurus Files for Full-Text Search”. The document explains the difference between two types of thesaurus entry
| Thesaurus entry | Behaviour |
| Expansion set | Terms I wish to search for in addition to the one submitted |
| Replacement set | Terms I wish to search for instead of the one submitted |
As a basic test I am going to ask for the phonetic term to be replaced by the correctly spelt search term. My tseng.xml file will look like the following.
<XML ID="Microsoft Search Thesaurus">
<thesaurus xmlns="x-schema:tsSchema.xml">
<diacritics_sensitive>0</diacritics_sensitive>
<replacement>
<pat>ASNT</pat>
<sub>Ascent</sub>
</replacement>
<replacement>
<pat>KRBN</pat>
<sub>Caribbean</sub>
</replacement>
<replacement>
<pat>FRTFNTR</pat>
<sub>Fuerteventura</sub>
</replacement>
<replacement>
<pat>LNBRS</pat>
<sub>Llanberis</sub>
</replacement>
<replacement>
<pat>LFBRF</pat>
<sub>Loughborough</sub>
</replacement>
<replacement>
<pat> WLRS</pat>
<sub> Wheelers </sub>
</replacement>
</thesaurus>
</XML>Finally, we have to load our edited thesaurus file
EXEC sys.sp_fulltext_load_thesaurus_file 2057;
Trying out the thesaurus
To run my basic tests I created as stored procedure using the script below.
IF EXISTS(SELECT 1 FROM sys.objects WHERE type='P' AND name='SearchProducts') BEGIN
DROP PROC dbo.SearchProducts PRINT 'PROC DROPPED: dbo.SearchProducts' END
GO
CREATE PROCEDURE dbo.SearchProducts @SearchTerm VARCHAR(30) -- The term as the customer would enter it. AS
SET NOCOUNT ON
DECLARE @PhoneticTerm VARCHAR(30) SET @PhoneticTerm=dbo.LongPhonetic(4,@SearchTerm) --calculate the phonetic term --Display only during development, remove this from production code
RAISERROR('Phonetic Term %s for %s',10,1,@PhoneticTerm, @SearchTerm) WITH NOWAIT SELECT ProductKey,P.ProductAlternateKey, P.SizeUnitMeasureCode, P.EnglishProductName, P.StandardCost, P.Color FROM dbo.DimProduct AS P -- FREETEXT clause will use the thesaurus by default WHERE FREETEXT (P.EnglishProductName,@PhoneticTerm) OR FREETEXT(P.EnglishProductName,@SearchTerm) GOWe can now execute our stored procedure without having to worry too much about the spelling of the product names.
EXEC dbo.SearchProducts @SearchTerm = 'furtavintora'
| ProductKey | ProductAlternateKey | SizeUnitMeasureCode | EnglishProductName | StandardCost | Color |
| 607 | XXJER1 | XL | Fuerteventura Wheelers | 60.70 | MULTI |
| 608 | XXJER2 | L | Fuerteventura Wheelers | 60.70 | MULTI |
| 609 | XXJER3 | M | Fuerteventura Wheelers | 60.70 | MULTI |
EXEC dbo.SearchProducts @SearchTerm = 'assent'
| ProductKey | ProductAlternateKey | SizeUnitMeasureCode | EnglishProductName | StandardCost | Color |
| 613 | XXJER7 | XL | Llanberis Ascent Club | 60.70 | MULTI |
| 614 | XXJER8 | L | Llanberis Ascent Club | 60.70 | MULTI |
| 615 | XXJER9 | M | Llanberis Ascent Club | 60.70 | MULTI |
When to use expansions rather than replacements
For an expansion you might want to take a search term and search for one or more alternative terms. An example might be when a customer searches for a cycling jersey in the Canary islands and you mark the expansion as containing Tenerife, Fuerteventura, Gran Canaria, Lanzarotte etc. In effect the thesaurus is used as a crude cross selling tool.
Another example would be as a work around for the limitations of algorithms underpinning the phonetic codes.
If a search returns no records then that search term should be logged to gain insight into the customer need being expressed through their search.
- Potentially a new opportunity for the organization.
- There phonetic algorithm does not cater for the way that the customer spells the product
Taking our Fuerteventura example if the customer searches for:
- “Firtaventora” we get a match as the phonetic code for both is “FRTFNTR”
- “Fwerteventura” we get a miss because the phonetic code is “FWRTFNTR”
Further thoughts
Although my experiment proved that the original idea of using the thesaurus to hold phonetic keys would have worked, I feel that the approach is too limited to be of much practical use. People expect greater sophistication from a search capability with both true thesaurus terms, spelling corrections and proximity terms. There is no way to combine proximity and thesaurus terms in MSFTS
The full-text parser simply cracks the sentence, hyphenated words and numbers with 2 or more digits down into display terms with positions within the document. If does not contain entries and therefore positions for terms that appear in the thesaurus.
In addition to which the full text search syntax is unwieldy and does not provide an enjoyable development experience.
If I were to use this technique then I would be more inclined to have an external process that would provide a distinct list of words from the text against which I wanted to provide a search. I would run that list against a phonetic algorithm to produce my thesaurus entries.
I would have my application calculate the phonetic key and submit that to the full-text search rather than use my SQLCLR function.
For product searches I would not worry about the occassional false positive hit. The false positives are few enough for the customers decide whether the results are of relevance.

