

Microsoft Fabric allows the developers to create delta tables in the Lakehouse. However, the automation of copying, updating, and deleting of data files in the Lakehouse might not be possible. How can we empower the end users to make these changes manually?
Business Problem
Today, we are going to cover two newer tools from Microsoft that are in preview. First, the OneLake explorer allows users to access files in the Lakehouse just like they were in Windows Explorer. Second, the Data Wrangler extension for Visual Studio Code allows users to read, modify, and write parquet files.
One Lake Explorer
The OneLake file explorer can be downloaded from this URL. Once you downloaded the installation program, please execute the program. Click the install button to start the process.

Once the program is installed, it will ask you to log into Microsoft Fabric using the credentials you want to associate with the OneLake explorer. In my case, I will be using the john@craftydba.com account.

Of course, I have to enter in the correct password. However, I will not tell you what mine is!

Multi factor authentication is enforced by the Microsoft Azure Subscription. At this time, I have to grab my Android phone and enter the number shown below into the Microsoft Authenticator application. If you have not used the application before, here is a Microsoft web page to learn more about installation.

Since I work with multiple accounts every day, I do not want this account associated with everything. Therefore, I am going to have the OneLake Explorer application only associated with the john@craftydba.com, which is a Microsoft Entra ID as known as Azure Active Directory user.

The image below shows the “One Lake – Microsoft (preview)” folder showing up in our Windows Explorer. The most important part of using this tool is to synchronize the data between our laptop and Microsoft Fabric. This can be easily done with a right click action.

Please note that the Explorer is pointing to the Adventure Works Lakehouse we created last time.
Load the New Lakehouse
The first dataset that we are going to work with today is the S&P 500 stocks files for the years 2013 to 2017. I downloaded this data from Yahoo financials a long time ago. The dataset has been used to demonstrate how to use PolyBase and Azure SQL Warehouse.

The above image shows the creation of the new Lakehouse, named lh_snp_500, and the image below shows it contains no files and/or tables. It is important to know that the Lakehouse does not support special characters. I tend to stick with alpha-numeric names and underscores.

If we refresh the One Lake Explorer, the new Lakehouse will show up. Now, please navigate to the Files directory.

We are going to re-use the Spark Notebook that creates bronze and silver tables for a given directory. Therefore, please create the following nested sub-directories: RAW, STOCKS, and S&P2013.

Please jump to the end of the article to get the zip file that has the data and code files. Please copy over the CSV files for the year 2013 into the appropriate directory.
Initial Table Creation
There were two changes that I made to the nb-delimited-full-load Spark notebook. First, I added support for unlimited nested folders. This is important if we want to capture the folder name (leaf level) and file name. Before, we hard coded the indexing to match the folder nesting. The reverse, split, and split_part Spark functions convert the full path string into an array which is manipulated to return the file name and folder name.
#
# F3 - create bronze table (all files)
#
# spark sql - assume 1 level nesting on dir
stmt = f"""
create table bronze_{var_table}_full as
select
*,
current_timestamp() as _load_date,
reverse(split(input_file_name(), '/'))[1] as _folder_name,
split_part(reverse(split(input_file_name(), '/'))[0], '?', 1) as _file_name
from
tmp_{var_table}_full
"""
# create table
ret = spark.sql(stmt)
# debugging
print(f"execute spark sql - \n {stmt}")Second, we are not keeping an audit trail for the stock data. Thus, the bronze and silver tables match exactly. To accomplish this logic, we just need to remove the where clause from common table expression. This clause was selecting the folders that had the maximum date by ASCII sorting. Better yet, we can just use a simple select statement as seen below.
#
# F4 - create silver table (lastest file)
#
# spark sql
stmt = f"""
create table silver_{var_table}_full as
select *
from bronze_{var_table}_full
"""
# create table
ret = spark.sql(stmt)
# debugging
print(f"execute spark sql - \n {stmt}")
The new notebook is named nb-delimited-full-no-history. There are 125,216 rows of data in the delta tables. These tables are built from the 508 CSV files in the directory named 2013. How do we know if this data is accurate?
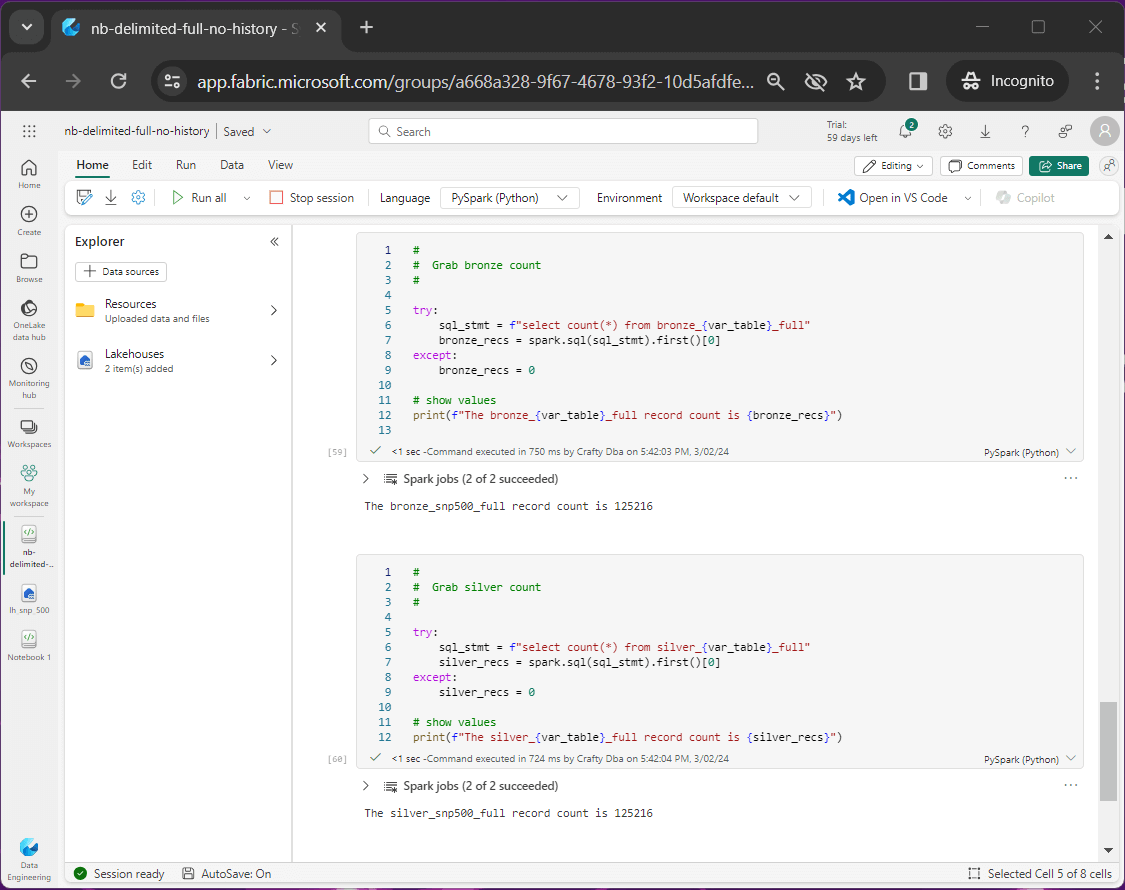
Managing CSV Files
The user will have to know how to insert, update and delete files from the storage of the Lakehouse. We are going to cover those actions shortly. However, it is always good to profile your data. Any issues with the files can be corrected immediately. The delta tables can be torn down and rebuilt from source files anytime you want.

The image above shows the completion of creating five directories for each year we captured stock data. Behind the scenes, each folder has been loaded with files representing the five hundred plus companies. The image below shows the completion of rebuilding the delta tables. Right now, we have 625,833 rows of data from loading 2,533 files into our delta tables.

The following images use the SQL analytics endpoint to query the delta tables. If we group by the string representing the year, we should only have 5 years. However, that is not the case.
The first two rows in the image below represent bad data. The null values are from unwanted text files that were placed into the raw directories by mistake. These files were used with PolyBase sample code but can be removed. The one row from 2012 is a dividend that has the wrong year.

The union of the good and bad text files has resulted in bad rows. This data integrity issue can be solved by just deleting the bad files.

The dividend on 12-31-2012 has no valuable data. Thus, we can edit the correct file and delete the row. This is an update action to the file.

I left these same issues in the sample data files I gave you. Just use the OneLake explorer to find the files with a *.txt extension and delete them.

The DFS stock from 2013 has a bad row of data. Use notepad++ to edit the file and remove the data on line 257.

If we re-execute the Apache Spark notebook, we will rebuild the bronze and silver delta tables. Right now, the total number of records is 635,816.

To double check our data integrity, run the grouping by year query as seen below. The sum of the yearly totals matched the grand total show previously.

Caution, I did notice that the synchronization of files from the desktop to the OneLake does take time. If you run the Spark notebook right away, you might not capture all the files into the delta table.
Weak vs Strong File Types
The comma separated values (CSV) file format is considered weak in nature do to the following facts:
- viewable in text editor
- header is optional
- data types are inferred
- no support for compression
- partitioning is not supported
There is a place for CSV files since they can be opened and manipulated by Microsoft Excel. This makes the format attractive to business users.
The delta file format is based upon Apache Parquet files with the addition of logging. The parquet file format is considered strong in nature since it has solved all issues associated with weak files. How can we insert, update and delete records from the OneLake if a parquet file format is used?
New Delta Table
The second dataset that we are going to work with today is the titanic passenger list. The automation of steps is important when a company has hundreds of files and/or tables. However, all steps can be done via the Microsoft Fabric graphical user interface.

The above image shows the parquet file being placed onto the One Lake Explorer folder. The image below shows that a delta table can be created from the parquet file by right clicking in the Lakehouse explorer.

The last step is to preview the data. In the final section of this article, we will learn how to read, update, and write parquet files.

Visual Studio Code
Microsoft has the Data Wrangler extension (plugin) for Visual Studio Code that can be used to profile and clean up data files. Any file type supported by pandas seems fine. The image below shows details on the extension.

The following are required software installations for this to work properly.
- Visual Studio Code
- Anaconda Python
- Microsoft Data Wrangler
The image below shows the data that has been loaded into a panda DataFrame.

We noticed that Mr. James Moran had a missing age. Our research department has found a long-lost record stating James’s age to be 25. How can we update this row?

The at() method of a Pandas DataFrame allows the user to update the in memory copy given a row index value of 5 and column name of ‘Age’.

We must write out a file to persist the change. I could have overwritten the original file but decided to save lineage.

Please synch the OneLake Explorer with the Microsoft Fabric Lakehouse. The above and below images show the two new files.

Please manually drop the delta tabl, named bronze_titanic_full, and rebuild with the parquet file, named titanic2.parquet.

In a nutshell, working with parquet files is a lot harder to do than CSV files. However, features like column names, data types, and compression make this file format very attractive.
Summary
Today, we covered two new tools from Microsoft. First, the OneLake explorer allows users to access files in the Lakehouse via the windows explorer. Second, the Data Wrangler extension for Visual Studio Code allows users to read, modify and write parquet files.
Adoption by the end users is very important when it comes to data lakes. If no one from your organization uses Microsoft One Lake, why build it? Many business users still use Microsoft Excel. With a little training, they can managed files in the lake using the new explorer. The ADF and/or Spark jobs that build the delta tables can be set to run periodically during working hours. This will empower the end users to manage the information in the lake and have it refresh automatically.
What we have not talked about is reporting. The ultimate goal is to have the stock data flow into a Power BI report. Again, this is a made-up use case. However, thousands of lines of data is not useful for an end user. But a report showing how Microsoft’s stock has increased over the last 5 years is.
Enclosed is the zip file with the data files and Spark notebooks.